 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Based Knowledge Transfer Under State-Action Dimension Mismatch
Jun 12, 2020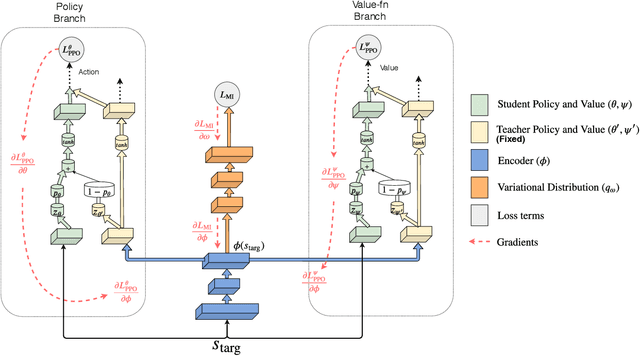
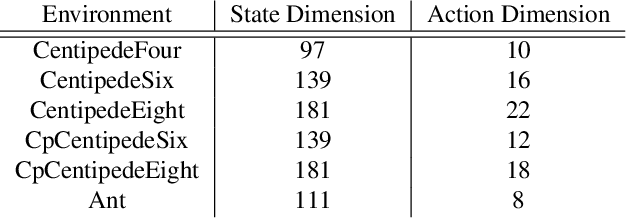

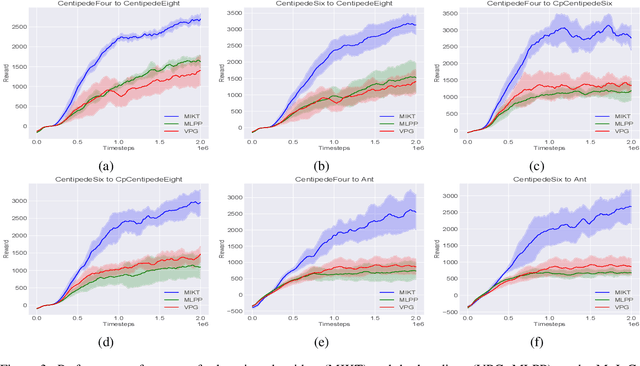
Deep reinforcement learning (RL) algorithms have achieved great success on a wide variety of sequential decision-making tasks. However, many of these algorithms suffer from high sample complexity when learning from scratch using environmental rewards, due to issues such as credit-assignment and high-variance gradients, among others. Transfer learning, in which knowledge gained on a source task is applied to more efficiently learn a different but related target task, is a promising approach to improve the sample complexity in RL. Prior work has considered using pre-trained teacher policies to enhance the learning of the student policy, albeit with the constraint that the teacher and the student MDPs share the state-space or the action-space. In this paper, we propose a new framework for transfer learning where the teacher and the student can have arbitrarily different state- and action-spaces. To handle this mismatch, we produce embeddings which can systematically extract knowledge from the teacher policy and value networks, and blend it into the student networks. To train the embeddings, we use a task-aligned loss and show that the representations could be enriched further by adding a mutual information loss. Using a set of challenging simulated robotic locomotion tasks involving many-legged centipedes, we demonstrate successful transfer learning in situations when the teacher and student have different state- and action-spaces.
DASNet: Dual attentive fully convolutional siamese networks for change detection of high resolution satellite images
Mar 07, 2020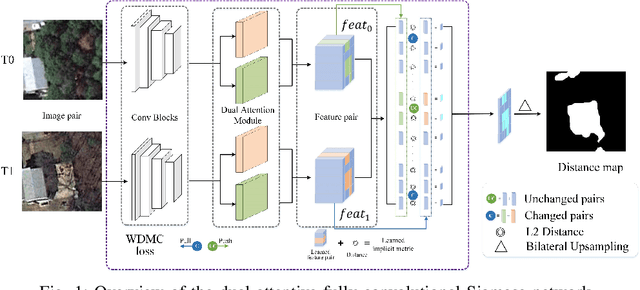
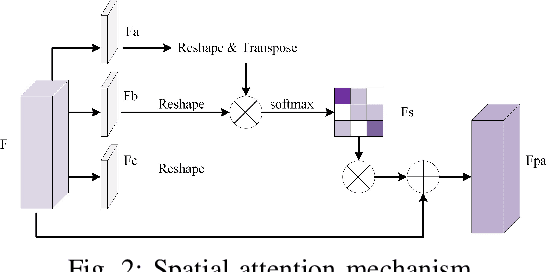
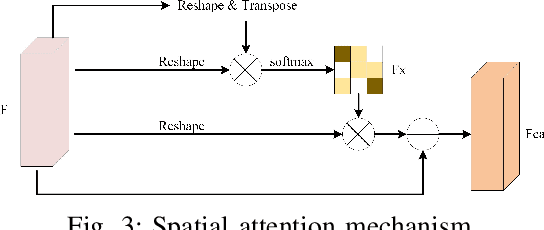

Change detection is a basic task of remote sensing image processing. The research objective is to identity the change information of interest and filter out the irrelevant change information as interference factors. Recently, the rise of deep learning has provided new tools for change detection, which have yielded impressive results. However, the available methods focus mainly on the difference information between multitemporal remote sensing images and lack robustness to pseudo-change information. To overcome the lack of resistance of current methods to pseudo-changes, in this paper, we propose a new method, namely, dual attentive fully convolutional Siamese networks (DASNet) for change detection in high-resolution images. Through the dual-attention mechanism, long-range dependencies are captured to obtain more discriminant feature representations to enhance the recognition performance of the model. Moreover, the imbalanced sample is a serious problem in change detection, i.e. unchanged samples are much more than changed samples, which is one of the main reasons resulting in pseudo-changes. We put forward the weighted double margin contrastive loss to address this problem by punishing the attention to unchanged feature pairs and increase attention to changed feature pairs. The experimental results of our method on the change detection dataset (CDD) and the building change detection dataset (BCDD) demonstrate that compared with other baseline methods, the proposed method realizes maximum improvements of 2.1\% and 3.6\%, respectively, in the F1 score. Our Pytorch implementation is available at https://github.com/lehaifeng/DASNet.
Stein Variational Inference for Discrete Distributions
Mar 01, 2020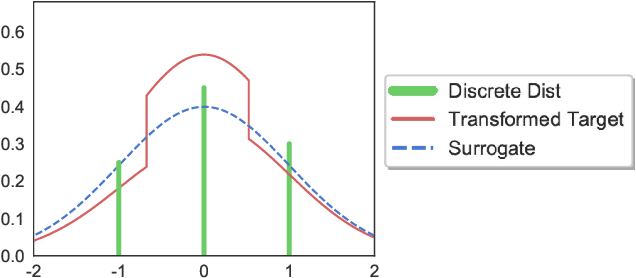
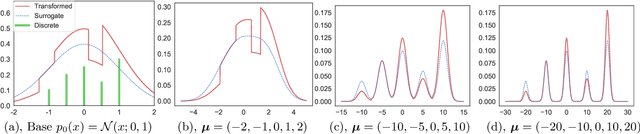
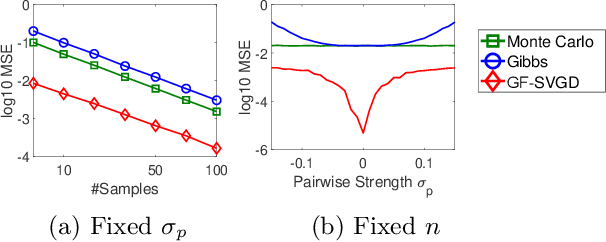
Gradient-based approximate inference methods, such as Stein variational gradient descent (SVGD), provide simple and general-purpose inference engines for differentiable continuous distributions. However, existing forms of SVGD cannot be directly applied to discrete distributions. In this work, we fill this gap by proposing a simple yet general framework that transforms discrete distributions to equivalent piecewise continuous distributions, on which the gradient-free SVGD is applied to perform efficient approximate inference. The empirical results show that our method outperforms traditional algorithms such as Gibbs sampling and discontinuous Hamiltonian Monte Carlo on various challenging benchmarks of discrete graphical models. We demonstrate that our method provides a promising tool for learning ensembles of binarized neural network (BNN), outperforming other widely used ensemble methods on learning binarized AlexNet on CIFAR-10 dataset. In addition, such transform can be straightforwardly employed in gradient-free kernelized Stein discrepancy to perform goodness-of-fit (GOF) test on discrete distributions. Our proposed method outperforms existing GOF test methods for intractable discrete distributions.
State-only Imitation with Transition Dynamics Mismatch
Feb 27, 2020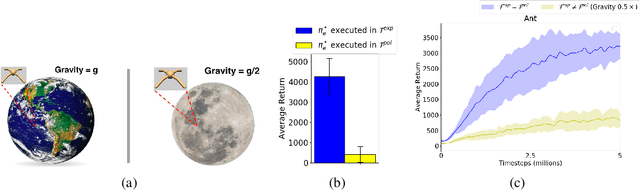


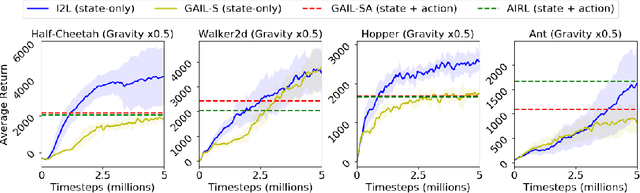
Imitation Learning (IL) is a popular paradigm for training agents to achieve complicated goals by leveraging expert behavior, rather than dealing with the hardships of designing a correct reward function. With the environment modeled as a Markov Decision Process (MDP), most of the existing IL algorithms are contingent on the availability of expert demonstrations in the same MDP as the one in which a new imitator policy is to be learned. This is uncharacteristic of many real-life scenarios where discrepancies between the expert and the imitator MDPs are common, especially in the transition dynamics function. Furthermore, obtaining expert actions may be costly or infeasible, making the recent trend towards state-only IL (where expert demonstrations constitute only states or observations) ever so promising. Building on recent adversarial imitation approaches that are motivated by the idea of divergence minimization, we present a new state-only IL algorithm in this paper. It divides the overall optimization objective into two subproblems by introducing an indirection step and solves the subproblems iteratively. We show that our algorithm is particularly effective when there is a transition dynamics mismatch between the expert and imitator MDPs, while the baseline IL methods suffer from performance degradation. To analyze this, we construct several interesting MDPs by modifying the configuration parameters for the MuJoCo locomotion tasks from OpenAI Gym.
Disentangling Controllable Object through Video Prediction Improves Visual Reinforcement Learning
Feb 21, 2020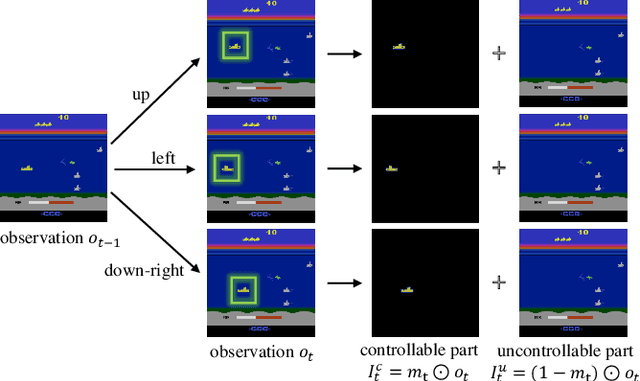
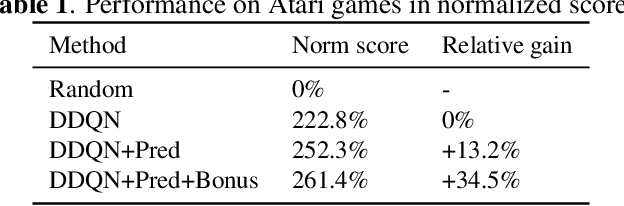
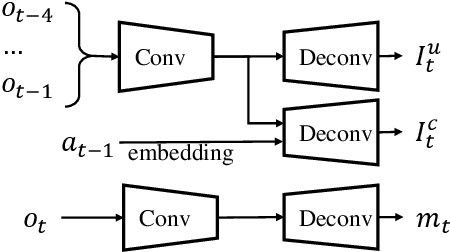
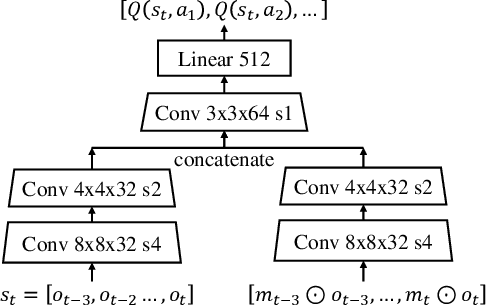
In many vision-based reinforcement learning (RL) problems, the agent controls a movable object in its visual field, e.g., the player's avatar in video games and the robotic arm in visual grasping and manipulation. Leveraging action-conditioned video prediction, we propose an end-to-end learning framework to disentangle the controllable object from the observation signal. The disentangled representation is shown to be useful for RL as additional observation channels to the agent. Experiments on a set of Atari games with the popular Double DQN algorithm demonstrate improved sample efficiency and game performance (from 222.8% to 261.4% measured in normalized game scores, with prediction bonus reward).
Convolution Neural Network Architecture Learning for Remote Sensing Scene Classification
Jan 27, 2020
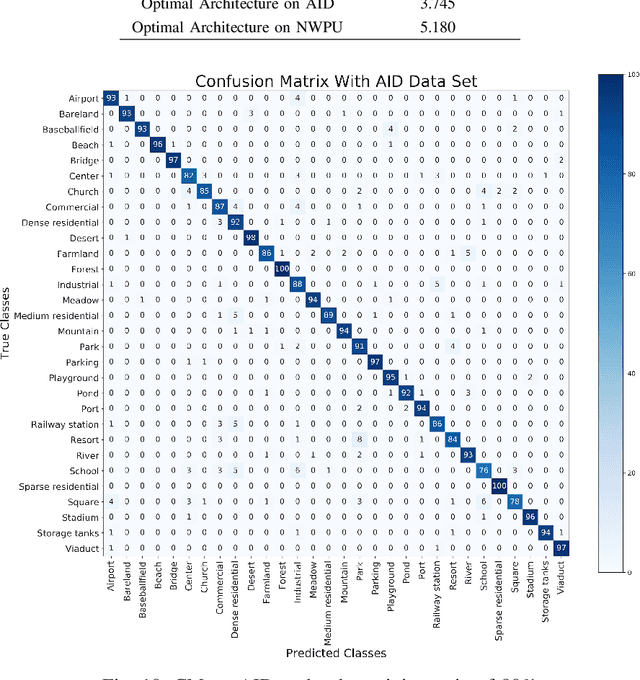
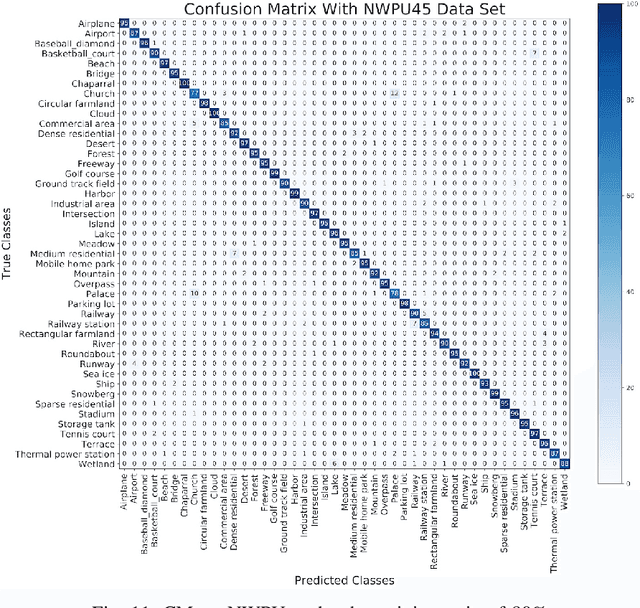
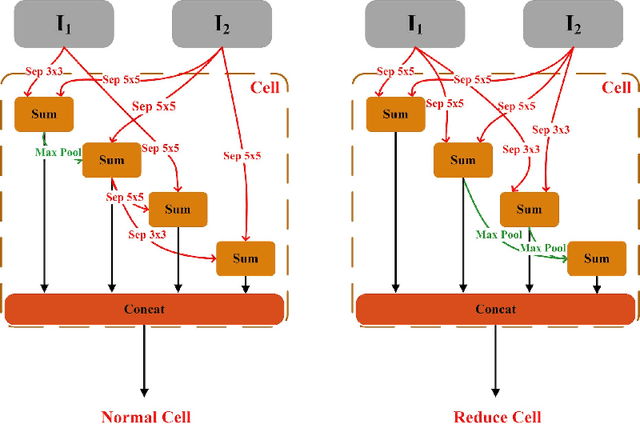
Remote sensing image scene classification is a fundamental but challenging task in understanding remote sensing images. Recently, deep learning-based methods, especially convolutional neural network-based (CNN-based) methods have shown enormous potential to understand remote sensing images. CNN-based methods meet with success by utilizing features learned from data rather than features designed manually. The feature-learning procedure of CNN largely depends on the architecture of CNN. However, most of the architectures of CNN used for remote sensing scene classification are still designed by hand which demands a considerable amount of architecture engineering skills and domain knowledge, and it may not play CNN's maximum potential on a special dataset. In this paper, we proposed an automatically architecture learning procedure for remote sensing scene classification. We designed a parameters space in which every set of parameters represents a certain architecture of CNN (i.e., some parameters represent the type of operators used in the architecture such as convolution, pooling, no connection or identity, and the others represent the way how these operators connect). To discover the optimal set of parameters for a given dataset, we introduced a learning strategy which can allow efficient search in the architecture space by means of gradient descent. An architecture generator finally maps the set of parameters into the CNN used in our experiments.
cube2net: Efficient Query-Specific Network Construction with Data Cube Organization
Jan 18, 2020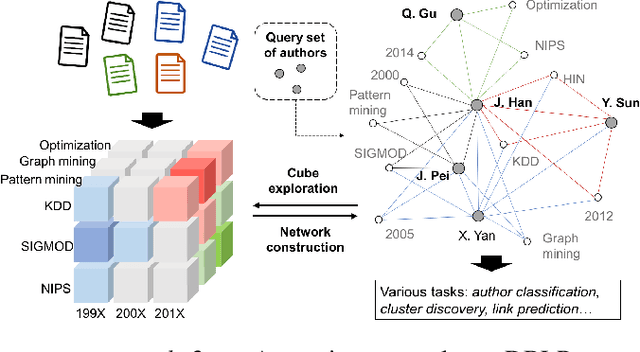
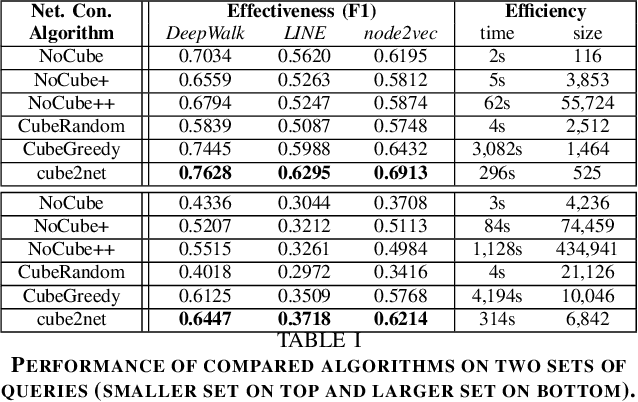
Networks are widely used to model objects with interactions and have enabled various downstream applications. However, in the real world, network mining is often done on particular query sets of objects, which does not require the construction and computation of networks including all objects in the datasets. In this work, for the first time, we propose to address the problem of query-specific network construction, to break the efficiency bottlenecks of existing network mining algorithms and facilitate various downstream tasks. To deal with real-world massive networks with complex attributes, we propose to leverage the well-developed data cube technology to organize network objects w.r.t. their essential attributes. An efficient reinforcement learning algorithm is then developed to automatically explore the data cube structures and construct the optimal query-specific networks. With extensive experiments of two classic network mining tasks on different real-world large datasets, we show that our proposed cube2net pipeline is general, and much more effective and efficient in query-specific network construction, compared with other methods without the leverage of data cube or reinforcement learning.
DeepMask: an algorithm for cloud and cloud shadow detection in optical satellite remote sensing images using deep residual network
Nov 09, 2019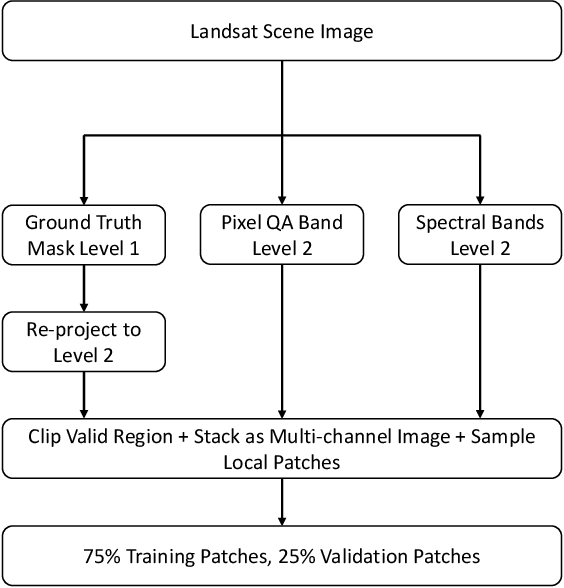
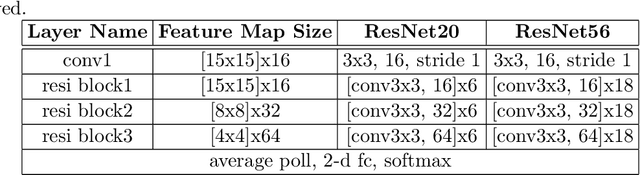
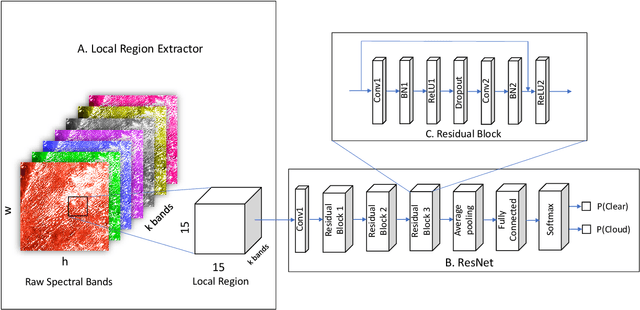
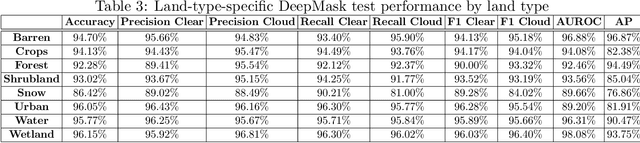
Detecting and masking cloud and cloud shadow from satellite remote sensing images is a pervasive problem in the remote sensing community. Accurate and efficient detection of cloud and cloud shadow is an essential step to harness the value of remotely sensed data for almost all downstream analysis. DeepMask, a new algorithm for cloud and cloud shadow detection in optical satellite remote sensing imagery, is proposed in this study. DeepMask utilizes ResNet, a deep convolutional neural network, for pixel-level cloud mask generation. The algorithm is trained and evaluated on the Landsat 8 Cloud Cover Assessment Validation Dataset distributed across 8 different land types. Compared with CFMask, the most widely used cloud detection algorithm, land-type-specific DeepMask models achieve higher accuracy across all land types. The average accuracy is 93.56%, compared with 85.36% from CFMask. DeepMask also achieves 91.02% accuracy on all-land-type dataset. Compared with other CNN-based cloud mask algorithms, DeepMask benefits from the parsimonious architecture and the residual connection of ResNet. It is compatible with input of any size and shape. DeepMask still maintains high performance when using only red, green, blue, and NIR bands, indicating its potential to be applied to other satellite platforms that only have limited optical bands.
$\sqrt{n}$-Regret for Learning in Markov Decision Processes with Function Approximation and Low Bellman Rank
Sep 08, 2019In this paper, we consider the problem of online learning of Markov decision processes (MDPs) with very large state spaces. Under the assumptions of realizable function approximation and low Bellman ranks, we develop an online learning algorithm that learns the optimal value function while at the same time achieving very low cumulative regret during the learning process. Our learning algorithm, Adaptive Value-function Elimination (AVE), is inspired by the policy elimination algorithm proposed in (Jiang et al., 2017), known as OLIVE. One of our key technical contributions in AVE is to formulate the elimination steps in OLIVE as contextual bandit problems. This technique enables us to apply the active elimination and expert weighting methods from (Dudik et al., 2011), instead of the random action exploration scheme used in the original OLIVE algorithm, for more efficient exploration and better control of the regret incurred in each policy elimination step. To the best of our knowledge, this is the first $\sqrt{n}$-regret result for reinforcement learning in stochastic MDPs with general value function approximation.
HeteSpaceyWalk: A Heterogeneous Spacey Random Walk for Heterogeneous Information Network Embedding
Sep 07, 2019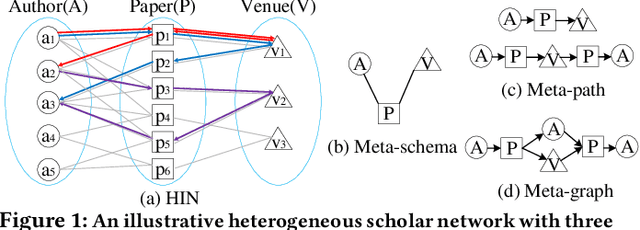
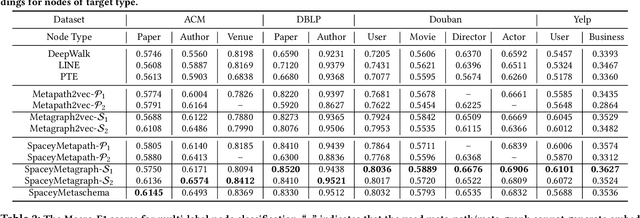
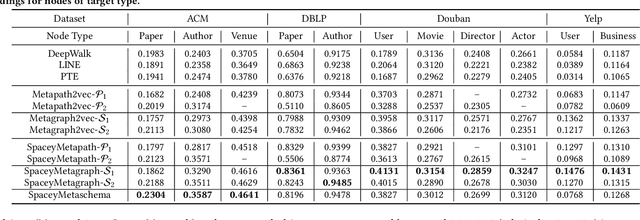
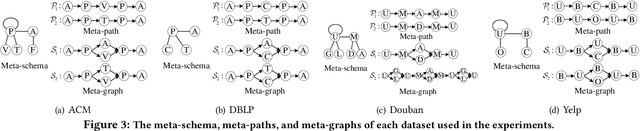
Heterogeneous information network (HIN) embedding has gained increasing interests recently. However, the current way of random-walk based HIN embedding methods have paid few attention to the higher-order Markov chain nature of meta-path guided random walks, especially to the stationarity issue. In this paper, we systematically formalize the meta-path guided random walk as a higher-order Markov chain process, and present a heterogeneous personalized spacey random walk to efficiently and effectively attain the expected stationary distribution among nodes. Then we propose a generalized scalable framework to leverage the heterogeneous personalized spacey random walk to learn embeddings for multiple types of nodes in an HIN guided by a meta-path, a meta-graph, and a meta-schema respectively. We conduct extensive experiments in several heterogeneous networks and demonstrate that our methods substantially outperform the existing state-of-the-art network embedding algorithms.