 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPNAS: Neural Architecture Search for Deep Learning with Differential Privacy
Oct 19, 2021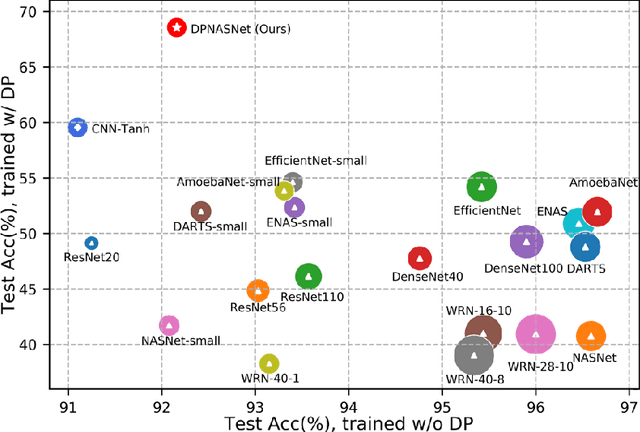
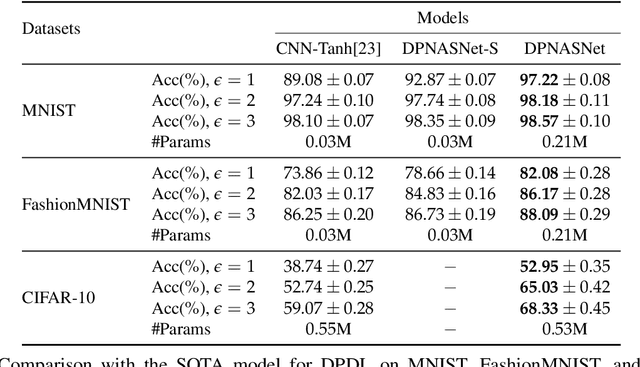
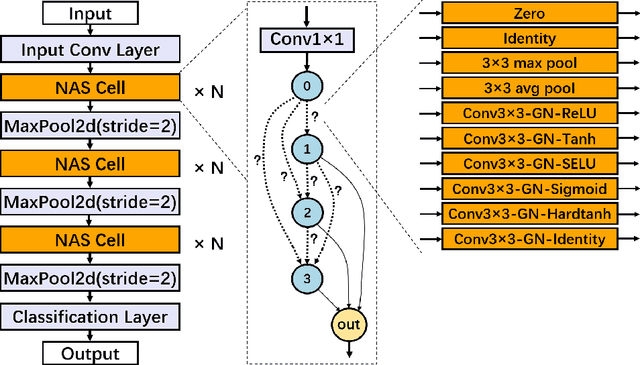
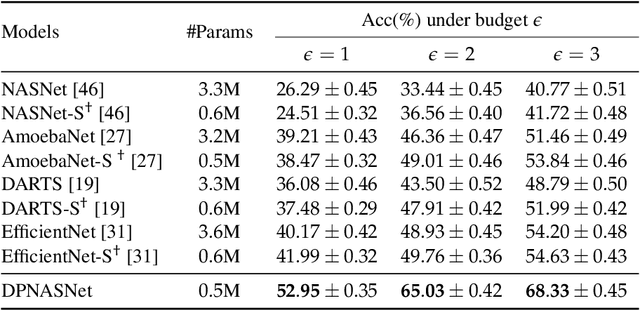
Training deep neural networks (DNNs) for meaningful differential privacy (DP) guarantees severely degrades model utility. In this paper, we demonstrate that the architecture of DNNs has a significant impact on model utility in the context of private deep learning, whereas its effect is largely unexplored in previous studies. In light of this missing, we propose the very first framework that employs neural architecture search to automatic model design for private deep learning, dubbed as DPNAS. To integrate private learning with architecture search, we delicately design a novel search space and propose a DP-aware method for training candidate models. We empirically certify the effectiveness of the proposed framework. The searched model DPNASNet achieves state-of-the-art privacy/utility trade-offs, e.g., for the privacy budget of $(\epsilon, \delta)=(3, 1\times10^{-5})$, our model obtains test accuracy of $98.57\%$ on MNIST, $88.09\%$ on FashionMNIST, and $68.33\%$ on CIFAR-10. Furthermore, by studying the generated architectures, we provide several intriguing findings of designing private-learning-friendly DNNs, which can shed new light on model design for deep learning with differential privacy.
Towards Mixed-Precision Quantization of Neural Networks via Constrained Optimization
Oct 13, 2021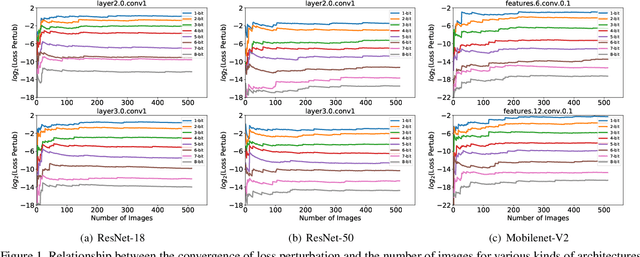
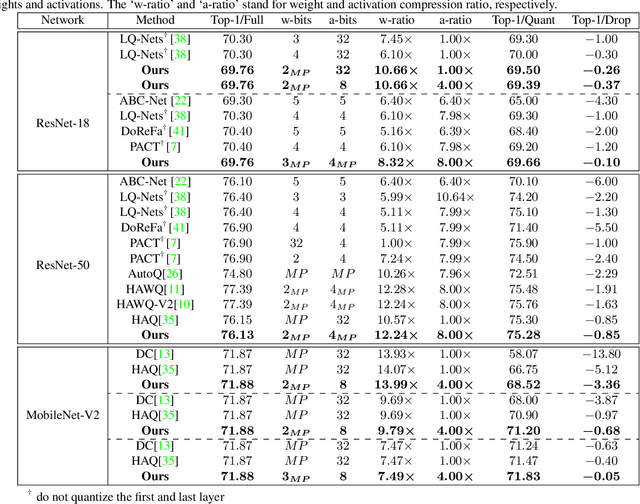
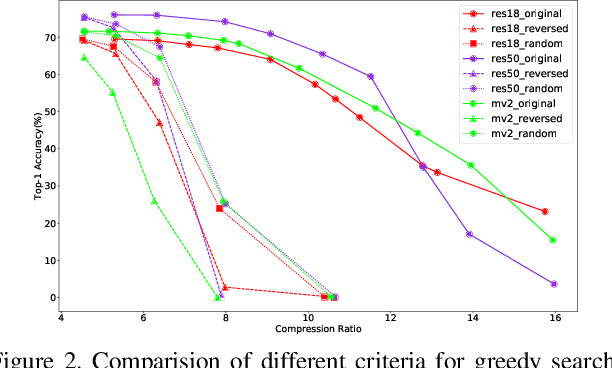
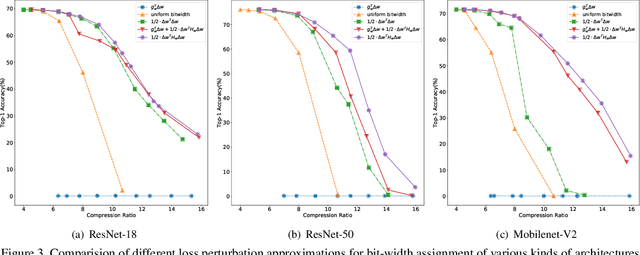
Quantization is a widely used technique to compress and accelerate deep neural networks. However, conventional quantization methods use the same bit-width for all (or most of) the layers, which often suffer significant accuracy degradation in the ultra-low precision regime and ignore the fact that emergent hardware accelerators begin to support mixed-precision computation. Consequently, we present a novel and principled framework to solve the mixed-precision quantization problem in this paper. Briefly speaking, we first formulate the mixed-precision quantization as a discrete constrained optimization problem. Then, to make the optimization tractable, we approximate the objective function with second-order Taylor expansion and propose an efficient approach to compute its Hessian matrix. Finally, based on the above simplification, we show that the original problem can be reformulated as a Multiple-Choice Knapsack Problem (MCKP) and propose a greedy search algorithm to solve it efficiently. Compared with existing mixed-precision quantization works, our method is derived in a principled way and much more computationally efficient. Moreover, extensive experiments conducted on the ImageNet dataset and various kinds of network architectures also demonstrate its superiority over existing uniform and mixed-precision quantization approaches.
Improving Binary Neural Networks through Fully Utilizing Latent Weights
Oct 12, 2021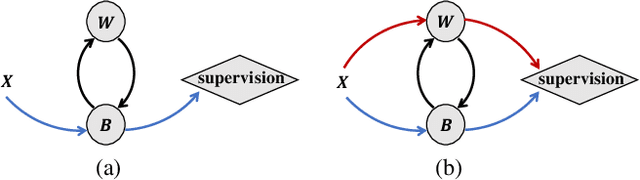

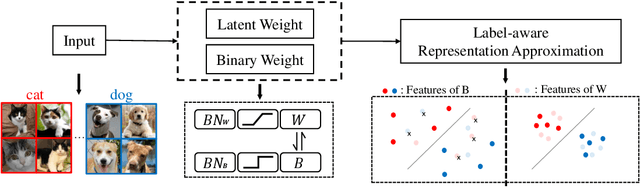
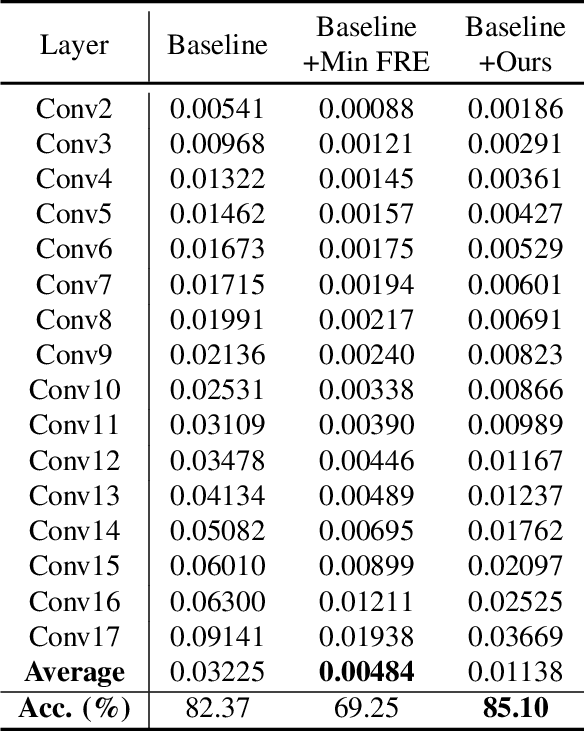
Binary Neural Networks (BNNs) rely on a real-valued auxiliary variable W to help binary training. However, pioneering binary works only use W to accumulate gradient updates during backward propagation, which can not fully exploit its power and may hinder novel advances in BNNs. In this work, we explore the role of W in training besides acting as a latent variable. Notably, we propose to add W into the computation graph, making it perform as a real-valued feature extractor to aid the binary training. We make different attempts on how to utilize the real-valued weights and propose a specialized supervision. Visualization experiments qualitatively verify the effectiveness of our approach in making it easier to distinguish between different categories. Quantitative experiments show that our approach outperforms current state-of-the-arts, further closing the performance gap between floating-point networks and BNNs. Evaluation on ImageNet with ResNet-18 (Top-1 63.4%), ResNet-34 (Top-1 67.0%) achieves new state-of-the-art.
Architecture Aware Latency Constrained Sparse Neural Networks
Sep 01, 2021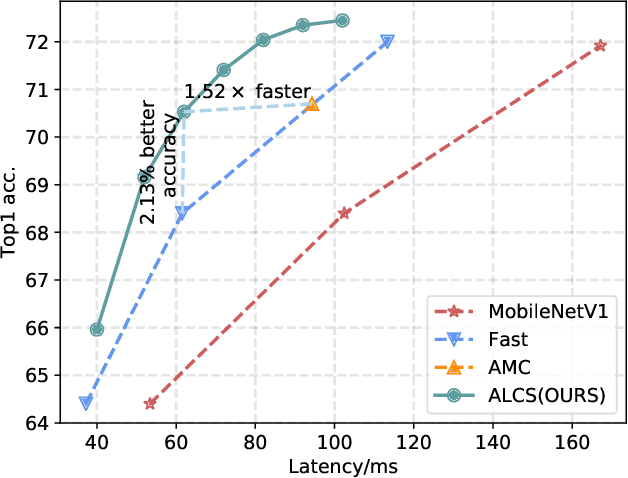
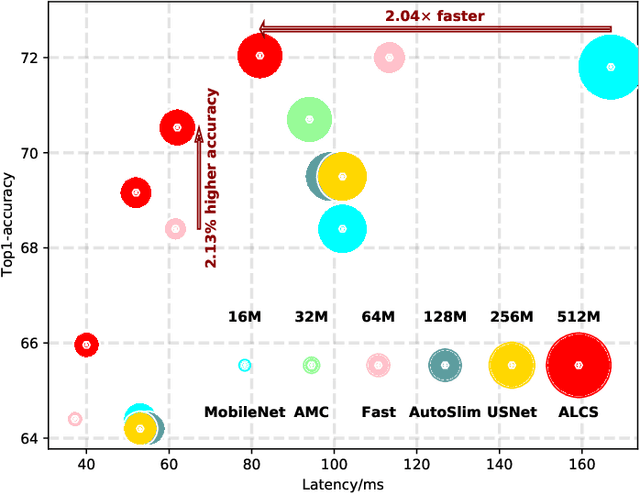
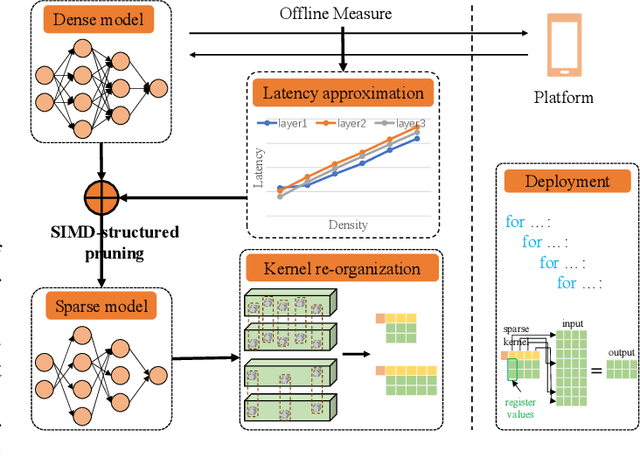
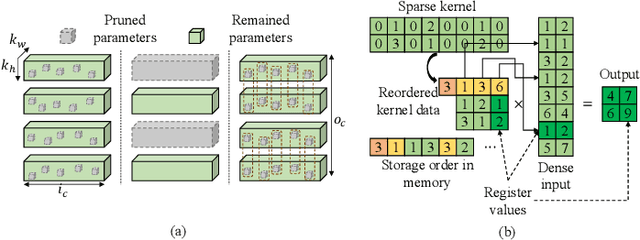
Acceleration of deep neural networks to meet a specific latency constraint is essential for their deployment on mobile devices. In this paper, we design an architecture aware latency constrained sparse (ALCS) framework to prune and accelerate CNN models. Taking modern mobile computation architectures into consideration, we propose Single Instruction Multiple Data (SIMD)-structured pruning, along with a novel sparse convolution algorithm for efficient computation. Besides, we propose to estimate the run time of sparse models with piece-wise linear interpolation. The whole latency constrained pruning task is formulated as a constrained optimization problem that can be efficiently solved with Alternating Direction Method of Multipliers (ADMM). Extensive experiments show that our system-algorithm co-design framework can achieve much better Pareto frontier among network accuracy and latency on resource-constrained mobile devices.
IntraLoss: Further Margin via Gradient-Enhancing Term for Deep Face Recognition
Jul 07, 2021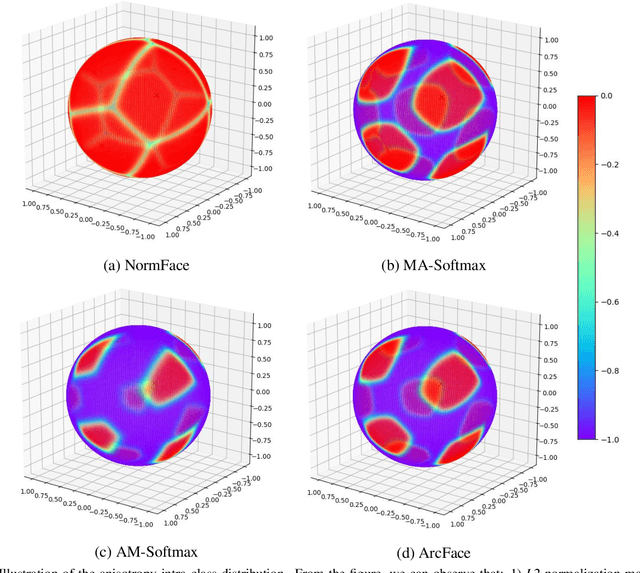
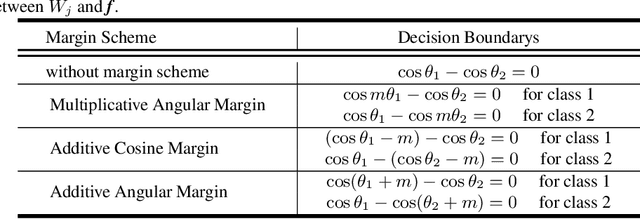
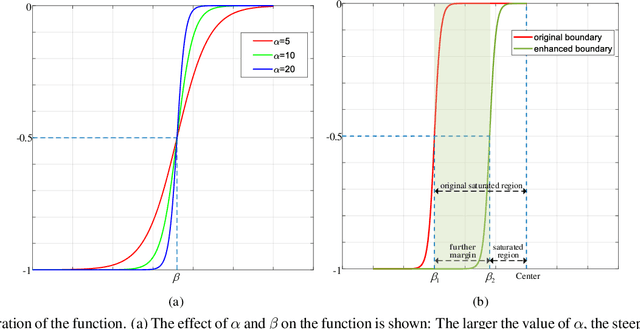

Existing classification-based face recognition methods have achieved remarkable progress, introducing large margin into hypersphere manifold to learn discriminative facial representations. However, the feature distribution is ignored. Poor feature distribution will wipe out the performance improvement brought about by margin scheme. Recent studies focus on the unbalanced inter-class distribution and form a equidistributed feature representations by penalizing the angle between identity and its nearest neighbor. But the problem is more than that, we also found the anisotropy of intra-class distribution. In this paper, we propose the `gradient-enhancing term' that concentrates on the distribution characteristics within the class. This method, named IntraLoss, explicitly performs gradient enhancement in the anisotropic region so that the intra-class distribution continues to shrink, resulting in isotropic and more compact intra-class distribution and further margin between identities. The experimental results on LFW, YTF and CFP-FP show that our outperforms state-of-the-art methods by gradient enhancement, demonstrating the superiority of our method. In addition, our method has intuitive geometric interpretation and can be easily combined with existing methods to solve the previously ignored problems.
Brain Age Estimation From MRI Using Cascade Networks with Ranking Loss
Jun 06, 2021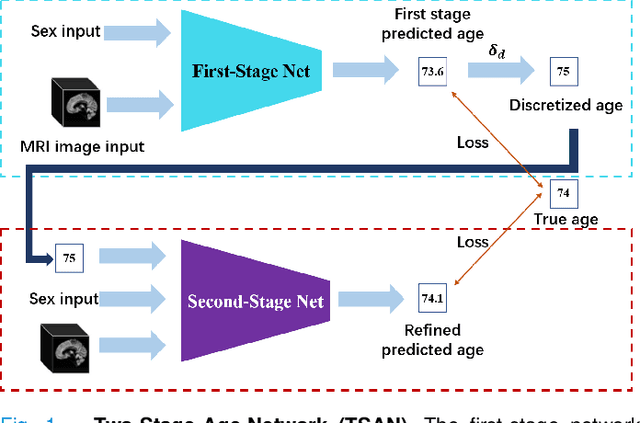
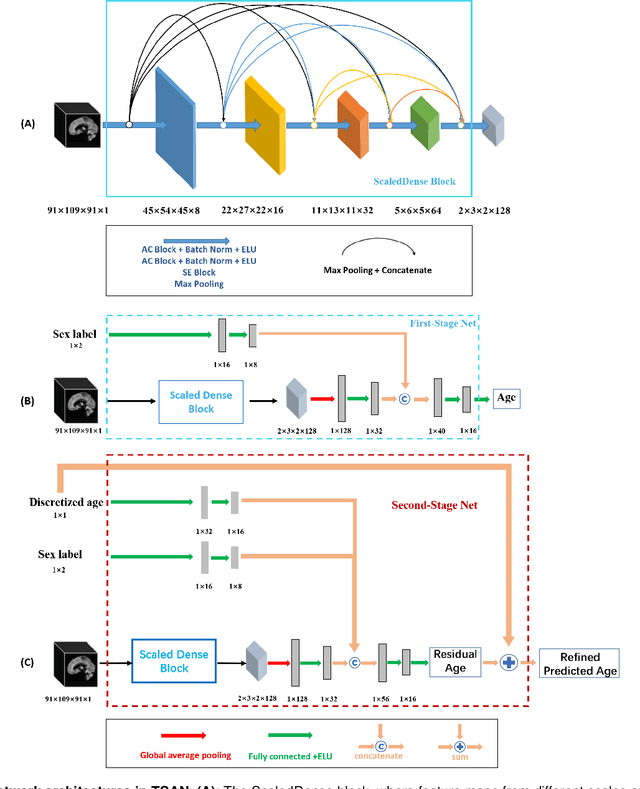
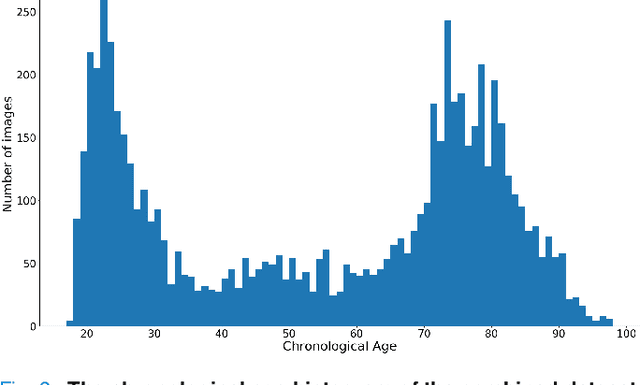
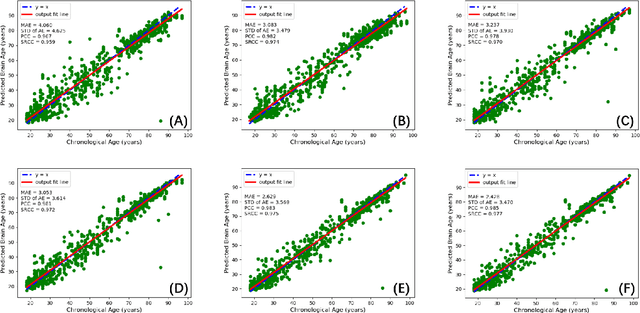
Chronological age of healthy people is able to be predicted accurately using deep neural networks from neuroimaging data, and the predicted brain age could serve as a biomarker for detecting aging-related diseases. In this paper, a novel 3D convolutional network, called two-stage-age-network (TSAN), is proposed to estimate brain age from T1-weighted MRI data. Compared with existing methods, TSAN has the following improvements. First, TSAN uses a two-stage cascade network architecture, where the first-stage network estimates a rough brain age, then the second-stage network estimates the brain age more accurately from the discretized brain age by the first-stage network. Second, to our knowledge, TSAN is the first work to apply novel ranking losses in brain age estimation, together with the traditional mean square error (MSE) loss. Third, densely connected paths are used to combine feature maps with different scales. The experiments with $6586$ MRIs showed that TSAN could provide accurate brain age estimation, yielding mean absolute error (MAE) of $2.428$ and Pearson's correlation coefficient (PCC) of $0.985$, between the estimated and chronological ages. Furthermore, using the brain age gap between brain age and chronological age as a biomarker, Alzheimer's disease (AD) and Mild Cognitive Impairment (MCI) can be distinguished from healthy control (HC) subjects by support vector machine (SVM). Classification AUC in AD/HC and MCI/HC was $0.904$ and $0.823$, respectively. It showed that brain age gap is an effective biomarker associated with risk of dementia, and has potential for early-stage dementia risk screening. The codes and trained models have been released on GitHub: https://github.com/Milan-BUAA/TSAN-brain-age-estimation.
HIH: Towards More Accurate Face Alignment via Heatmap in Heatmap
Apr 07, 2021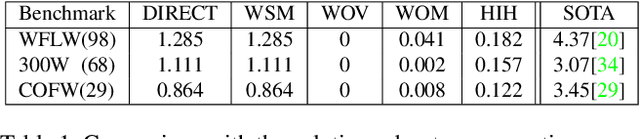
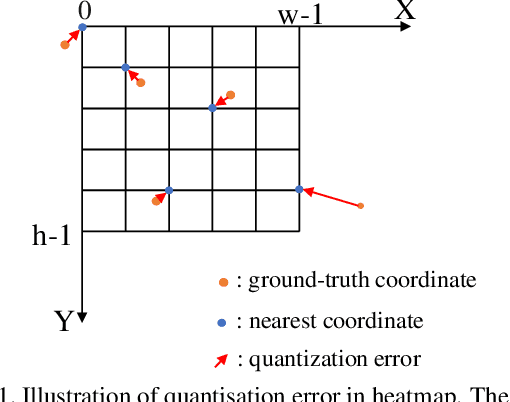

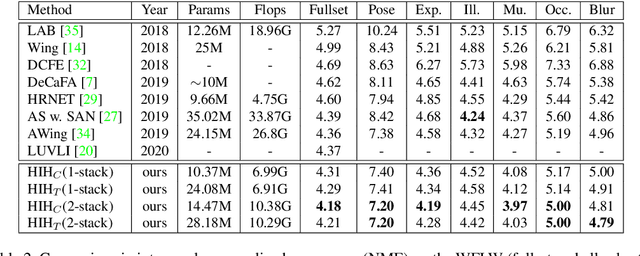
Recently, heatmap regression models have become the mainstream in locating facial landmarks. To keep computation affordable and reduce memory usage, the whole procedure involves downsampling from the raw image to the output heatmap. However, how much impact will the quantization error introduced by downsampling bring? The problem is hardly systematically investigated among previous works. This work fills the blank and we are the first to quantitatively analyze the negative gain. The statistical results show the NME generated by quantization error is even larger than 1/3 of the SOTA item, which is a serious obstacle for making a new breakthrough in face alignment. To compensate the impact of quantization effect, we propose a novel method, called Heatmap In Heatmap(HIH), which leverages two categories of heatmaps as label representation to encode coordinate. And in HIH, the range of one heatmap represents a pixel of the other category of heatmap. Also, we even combine the face alignment with solutions of other fields to make a comparison. Extensive experiments on various benchmarks show the feasibility of HIH and the superior performance than other solutions. Moreover, the mean error reaches to 4.18 on WFLW, which exceeds SOTA a lot. Our source code are made publicly available at supplementary material.
AdaSGN: Adapting Joint Number and Model Size for Efficient Skeleton-Based Action Recognition
Mar 22, 2021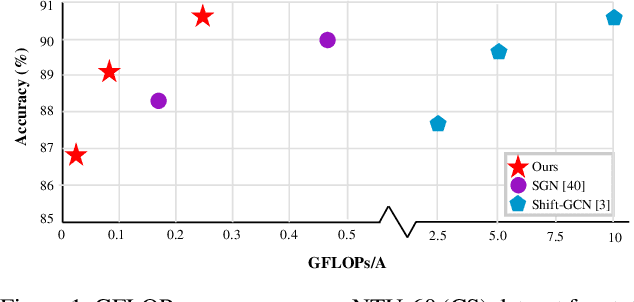
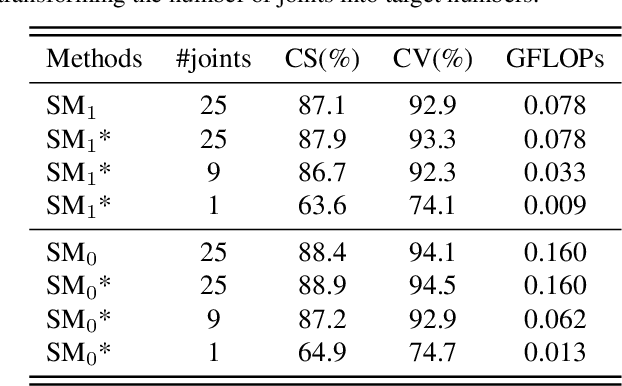
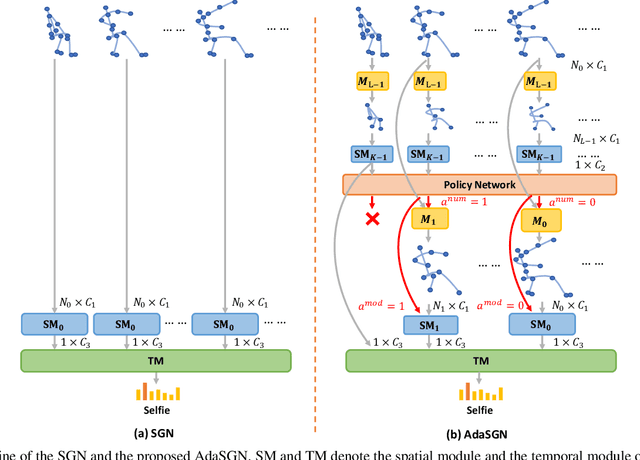
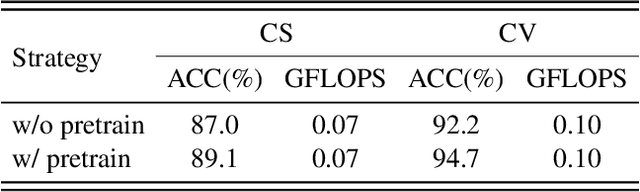
Existing methods for skeleton-based action recognition mainly focus on improving the recognition accuracy, whereas the efficiency of the model is rarely considered. Recently, there are some works trying to speed up the skeleton modeling by designing light-weight modules. However, in addition to the model size, the amount of the data involved in the calculation is also an important factor for the running speed, especially for the skeleton data where most of the joints are redundant or non-informative to identify a specific skeleton. Besides, previous works usually employ one fix-sized model for all the samples regardless of the difficulty of recognition, which wastes computations for easy samples. To address these limitations, a novel approach, called AdaSGN, is proposed in this paper, which can reduce the computational cost of the inference process by adaptively controlling the input number of the joints of the skeleton on-the-fly. Moreover, it can also adaptively select the optimal model size for each sample to achieve a better trade-off between accuracy and efficiency. We conduct extensive experiments on three challenging datasets, namely, NTU-60, NTU-120 and SHREC, to verify the superiority of the proposed approach, where AdaSGN achieves comparable or even higher performance with much lower GFLOPs compared with the baseline method.
You Only Look One-level Feature
Mar 17, 2021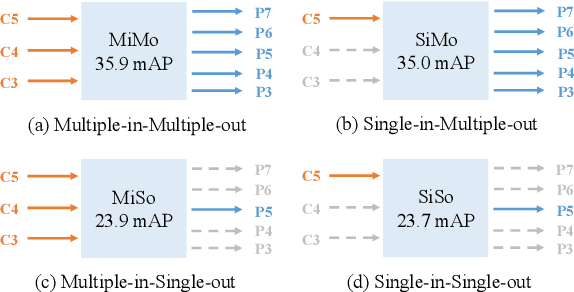
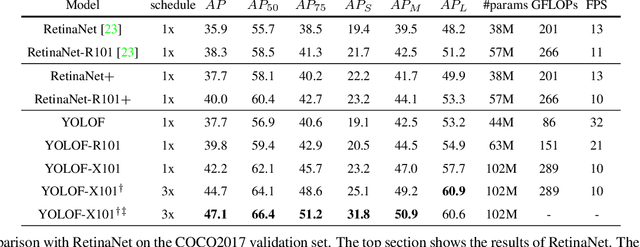

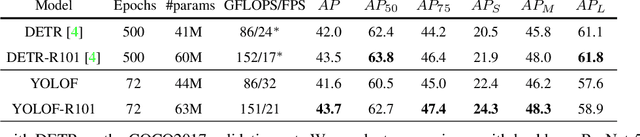
This paper revisits feature pyramids networks (FPN) for one-stage detectors and points out that the success of FPN is due to its divide-and-conquer solution to the optimization problem in object detection rather than multi-scale feature fusion. From the perspective of optimization, we introduce an alternative way to address the problem instead of adopting the complex feature pyramids - {\em utilizing only one-level feature for detection}. Based on the simple and efficient solution, we present You Only Look One-level Feature (YOLOF). In our method, two key components, Dilated Encoder and Uniform Matching, are proposed and bring considerable improvements. Extensive experiments on the COCO benchmark prove the effectiveness of the proposed model. Our YOLOF achieves comparable results with its feature pyramids counterpart RetinaNet while being $2.5\times$ faster. Without transformer layers, YOLOF can match the performance of DETR in a single-level feature manner with $7\times$ less training epochs. With an image size of $608\times608$, YOLOF achieves 44.3 mAP running at 60 fps on 2080Ti, which is $13\%$ faster than YOLOv4. Code is available at \url{https://github.com/megvii-model/YOLOF}.
Hardware Acceleration of Fully Quantized BERT for Efficient Natural Language Processing
Mar 04, 2021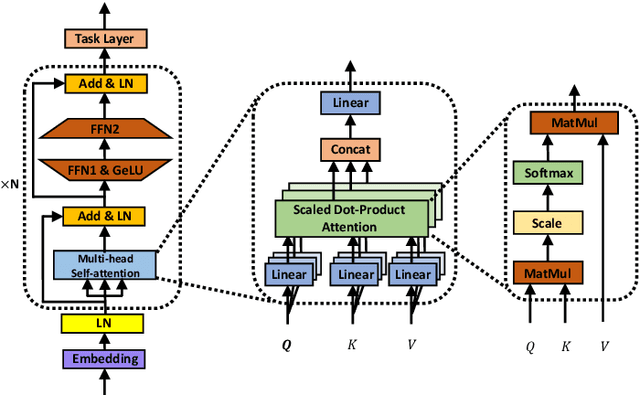
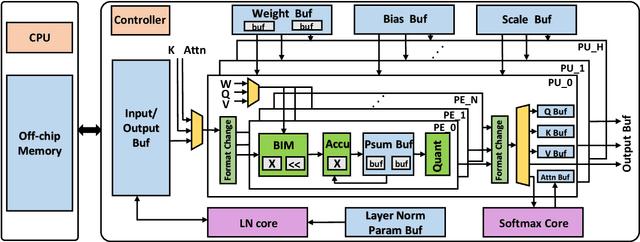
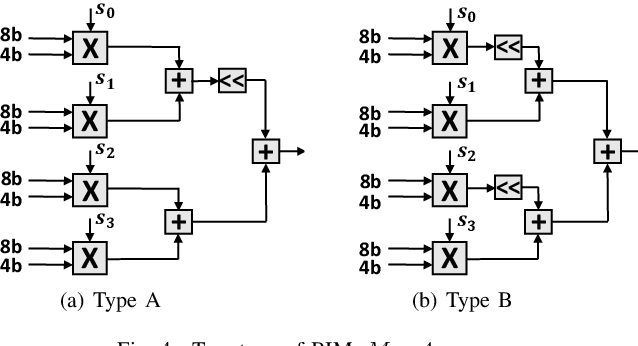
BERT is the most recent Transformer-based model that achieves state-of-the-art performance in various NLP tasks. In this paper, we investigate the hardware acceleration of BERT on FPGA for edge computing. To tackle the issue of huge computational complexity and memory footprint, we propose to fully quantize the BERT (FQ-BERT), including weights, activations, softmax, layer normalization, and all the intermediate results. Experiments demonstrate that the FQ-BERT can achieve 7.94x compression for weights with negligible performance loss. We then propose an accelerator tailored for the FQ-BERT and evaluate on Xilinx ZCU102 and ZCU111 FPGA. It can achieve a performance-per-watt of 3.18 fps/W, which is 28.91x and 12.72x over Intel(R) Core(TM) i7-8700 CPU and NVIDIA K80 GPU, respectively.