 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Classical Algorithms for Graph Neural Networks
Oct 24, 2025Neural networks excel at processing unstructured data but often fail to generalise out-of-distribution, whereas classical algorithms guarantee correctness but lack flexibility. We explore whether pretraining Graph Neural Networks (GNNs) on classical algorithms can improve their performance on molecular property prediction tasks from the Open Graph Benchmark: ogbg-molhiv (HIV inhibition) and ogbg-molclintox (clinical toxicity). GNNs trained on 24 classical algorithms from the CLRS Algorithmic Reasoning Benchmark are used to initialise and freeze selected layers of a second GNN for molecular prediction. Compared to a randomly initialised baseline, the pretrained models achieve consistent wins or ties, with the Segments Intersect algorithm pretraining yielding a 6% absolute gain on ogbg-molhiv and Dijkstra pretraining achieving a 3% gain on ogbg-molclintox. These results demonstrate embedding classical algorithmic priors into GNNs provides useful inductive biases, boosting performance on complex, real-world graph data.
Facilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
ADMN: A Layer-Wise Adaptive Multimodal Network for Dynamic Input Noise and Compute Resources
Feb 11, 2025Multimodal deep learning systems are deployed in dynamic scenarios due to the robustness afforded by multiple sensing modalities. Nevertheless, they struggle with varying compute resource availability (due to multi-tenancy, device heterogeneity, etc.) and fluctuating quality of inputs (from sensor feed corruption, environmental noise, etc.). Current multimodal systems employ static resource provisioning and cannot easily adapt when compute resources change over time. Additionally, their reliance on processing sensor data with fixed feature extractors is ill-equipped to handle variations in modality quality. Consequently, uninformative modalities, such as those with high noise, needlessly consume resources better allocated towards other modalities. We propose ADMN, a layer-wise Adaptive Depth Multimodal Network capable of tackling both challenges - it adjusts the total number of active layers across all modalities to meet compute resource constraints, and continually reallocates layers across input modalities according to their modality quality. Our evaluations showcase ADMN can match the accuracy of state-of-the-art networks while reducing up to 75% of their floating-point operations.
MMBind: Unleashing the Potential of Distributed and Heterogeneous Data for Multimodal Learning in IoT
Nov 18, 2024



Multimodal sensing systems are increasingly prevalent in various real-world applications. Most existing multimodal learning approaches heavily rely on training with a large amount of complete multimodal data. However, such a setting is impractical in real-world IoT sensing applications where data is typically collected by distributed nodes with heterogeneous data modalities, and is also rarely labeled. In this paper, we propose MMBind, a new framework for multimodal learning on distributed and heterogeneous IoT data. The key idea of MMBind is to construct a pseudo-paired multimodal dataset for model training by binding data from disparate sources and incomplete modalities through a sufficiently descriptive shared modality. We demonstrate that data of different modalities observing similar events, even captured at different times and locations, can be effectively used for multimodal training. Moreover, we propose an adaptive multimodal learning architecture capable of training models with heterogeneous modality combinations, coupled with a weighted contrastive learning approach to handle domain shifts among disparate data. Evaluations on ten real-world multimodal datasets highlight that MMBind outperforms state-of-the-art baselines under varying data incompleteness and domain shift, and holds promise for advancing multimodal foundation model training in IoT applications.
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Jun 12, 2024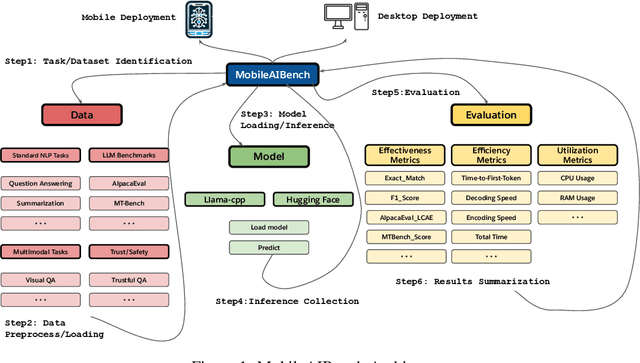



The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
UICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback
Jun 11, 2024Large language models (LLMs) struggle to consistently generate UI code that compiles and produces visually relevant designs. Existing approaches to improve generation rely on expensive human feedback or distilling a proprietary model. In this paper, we explore the use of automated feedback (compilers and multi-modal models) to guide LLMs to generate high-quality UI code. Our method starts with an existing LLM and iteratively produces improved models by self-generating a large synthetic dataset using an original model, applying automated tools to aggressively filter, score, and de-duplicate the data into a refined higher quality dataset. The original LLM is improved by finetuning on this refined dataset. We applied our approach to several open-source LLMs and compared the resulting performance to baseline models with both automated metrics and human preferences. Our evaluation shows the resulting models outperform all other downloadable baselines and approach the performance of larger proprietary models.
FlexLoc: Conditional Neural Networks for Zero-Shot Sensor Perspective Invariance in Object Localization with Distributed Multimodal Sensors
Jun 10, 2024



Localization is a critical technology for various applications ranging from navigation and surveillance to assisted living. Localization systems typically fuse information from sensors viewing the scene from different perspectives to estimate the target location while also employing multiple modalities for enhanced robustness and accuracy. Recently, such systems have employed end-to-end deep neural models trained on large datasets due to their superior performance and ability to handle data from diverse sensor modalities. However, such neural models are often trained on data collected from a particular set of sensor poses (i.e., locations and orientations). During real-world deployments, slight deviations from these sensor poses can result in extreme inaccuracies. To address this challenge, we introduce FlexLoc, which employs conditional neural networks to inject node perspective information to adapt the localization pipeline. Specifically, a small subset of model weights are derived from node poses at run time, enabling accurate generalization to unseen perspectives with minimal additional overhead. Our evaluations on a multimodal, multiview indoor tracking dataset showcase that FlexLoc improves the localization accuracy by almost 50% in the zero-shot case (no calibration data available) compared to the baselines. The source code of FlexLoc is available at https://github.com/nesl/FlexLoc.
Efficacy of ByteT5 in Multilingual Translation of Biblical Texts for Underrepresented Languages
May 22, 2024

This study presents the development and evaluation of a ByteT5-based multilingual translation model tailored for translating the Bible into underrepresented languages. Utilizing the comprehensive Johns Hopkins University Bible Corpus, we trained the model to capture the intricate nuances of character-based and morphologically rich languages. Our results, measured by the BLEU score and supplemented with sample translations, suggest the model can improve accessibility to sacred texts. It effectively handles the distinctive biblical lexicon and structure, thus bridging the linguistic divide. The study also discusses the model's limitations and suggests pathways for future enhancements, focusing on expanding access to sacred literature across linguistic boundaries.
UIClip: A Data-driven Model for Assessing User Interface Design
Apr 18, 2024User interface (UI) design is a difficult yet important task for ensuring the usability, accessibility, and aesthetic qualities of applications. In our paper, we develop a machine-learned model, UIClip, for assessing the design quality and visual relevance of a UI given its screenshot and natural language description. To train UIClip, we used a combination of automated crawling, synthetic augmentation, and human ratings to construct a large-scale dataset of UIs, collated by description and ranked by design quality. Through training on the dataset, UIClip implicitly learns properties of good and bad designs by i) assigning a numerical score that represents a UI design's relevance and quality and ii) providing design suggestions. In an evaluation that compared the outputs of UIClip and other baselines to UIs rated by 12 human designers, we found that UIClip achieved the highest agreement with ground-truth rankings. Finally, we present three example applications that demonstrate how UIClip can facilitate downstream applications that rely on instantaneous assessment of UI design quality: i) UI code generation, ii) UI design tips generation, and iii) quality-aware UI example search.
AgentLite: A Lightweight Library for Building and Advancing Task-Oriented LLM Agent System
Feb 23, 2024



The booming success of LLMs initiates rapid development in LLM agents. Though the foundation of an LLM agent is the generative model, it is critical to devise the optimal reasoning strategies and agent architectures. Accordingly, LLM agent research advances from the simple chain-of-thought prompting to more complex ReAct and Reflection reasoning strategy; agent architecture also evolves from single agent generation to multi-agent conversation, as well as multi-LLM multi-agent group chat. However, with the existing intricate frameworks and libraries, creating and evaluating new reasoning strategies and agent architectures has become a complex challenge, which hinders research investigation into LLM agents. Thus, we open-source a new AI agent library, AgentLite, which simplifies this process by offering a lightweight, user-friendly platform for innovating LLM agent reasoning, architectures, and applications with ease. AgentLite is a task-oriented framework designed to enhance the ability of agents to break down tasks and facilitate the development of multi-agent systems. Furthermore, we introduce multiple practical applications developed with AgentLite to demonstrate its convenience and flexibility. Get started now at: \url{https://github.com/SalesforceAIResearch/AgentLite}.