 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Code Fix Suggestions for Accessibility Issues in Mobile Apps
Aug 07, 2024Accessibility is crucial for inclusive app usability, yet developers often struggle to identify and fix app accessibility issues due to a lack of awareness, expertise, and inadequate tools. Current accessibility testing tools can identify accessibility issues but may not always provide guidance on how to address them. We introduce FixAlly, an automated tool designed to suggest source code fixes for accessibility issues detected by automated accessibility scanners. FixAlly employs a multi-agent LLM architecture to generate fix strategies, localize issues within the source code, and propose code modification suggestions to fix the accessibility issue. Our empirical study demonstrates FixAlly's capability in suggesting fixes that resolve issues found by accessibility scanners -- with an effectiveness of 77% in generating plausible fix suggestions -- and our survey of 12 iOS developers finds they would be willing to accept 69.4% of evaluated fix suggestions.
UICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback
Jun 11, 2024



Large language models (LLMs) struggle to consistently generate UI code that compiles and produces visually relevant designs. Existing approaches to improve generation rely on expensive human feedback or distilling a proprietary model. In this paper, we explore the use of automated feedback (compilers and multi-modal models) to guide LLMs to generate high-quality UI code. Our method starts with an existing LLM and iteratively produces improved models by self-generating a large synthetic dataset using an original model, applying automated tools to aggressively filter, score, and de-duplicate the data into a refined higher quality dataset. The original LLM is improved by finetuning on this refined dataset. We applied our approach to several open-source LLMs and compared the resulting performance to baseline models with both automated metrics and human preferences. Our evaluation shows the resulting models outperform all other downloadable baselines and approach the performance of larger proprietary models.
BISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks
Apr 12, 2024



Novices frequently engage with machine learning tutorials in computational notebooks and have been adopting code generation technologies based on large language models (LLMs). However, they encounter difficulties in understanding and working with code produced by LLMs. To mitigate these challenges, we introduce a novel workflow into computational notebooks that augments LLM-based code generation with an additional ephemeral UI step, offering users UI-based scaffolds as an intermediate stage between user prompts and code generation. We present this workflow in BISCUIT, an extension for JupyterLab that provides users with ephemeral UIs generated by LLMs based on the context of their code and intentions, scaffolding users to understand, guide, and explore with LLM-generated code. Through a user study where 10 novices used BISCUIT for machine learning tutorials, we discover that BISCUIT offers user semantic representation of code to aid their understanding, reduces the complexity of prompt engineering, and creates a playground for users to explore different variables and iterate on their ideas. We discuss the implications of our findings for UI-centric interactive paradigm in code generation LLMs.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022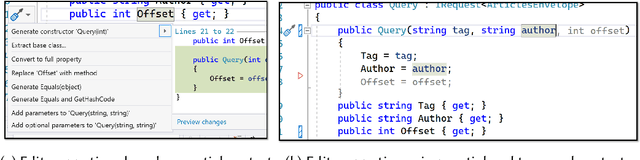
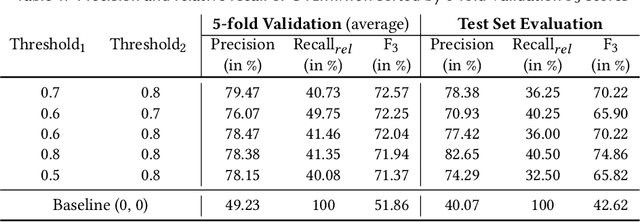


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.
Symphony: Composing Interactive Interfaces for Machine Learning
Feb 18, 2022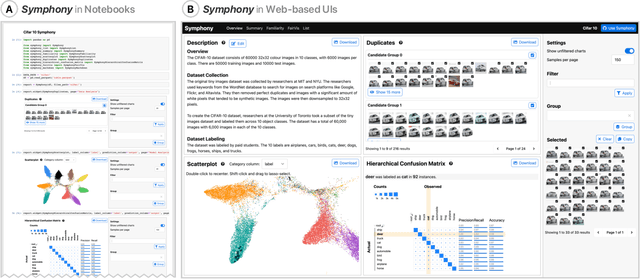
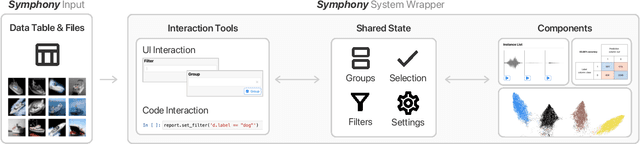
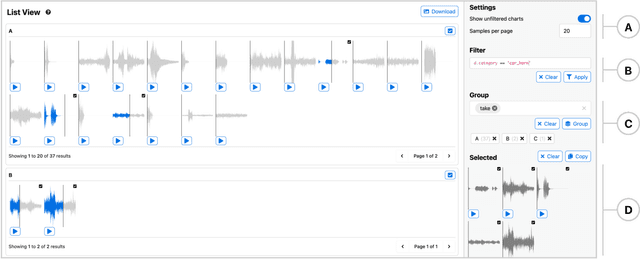
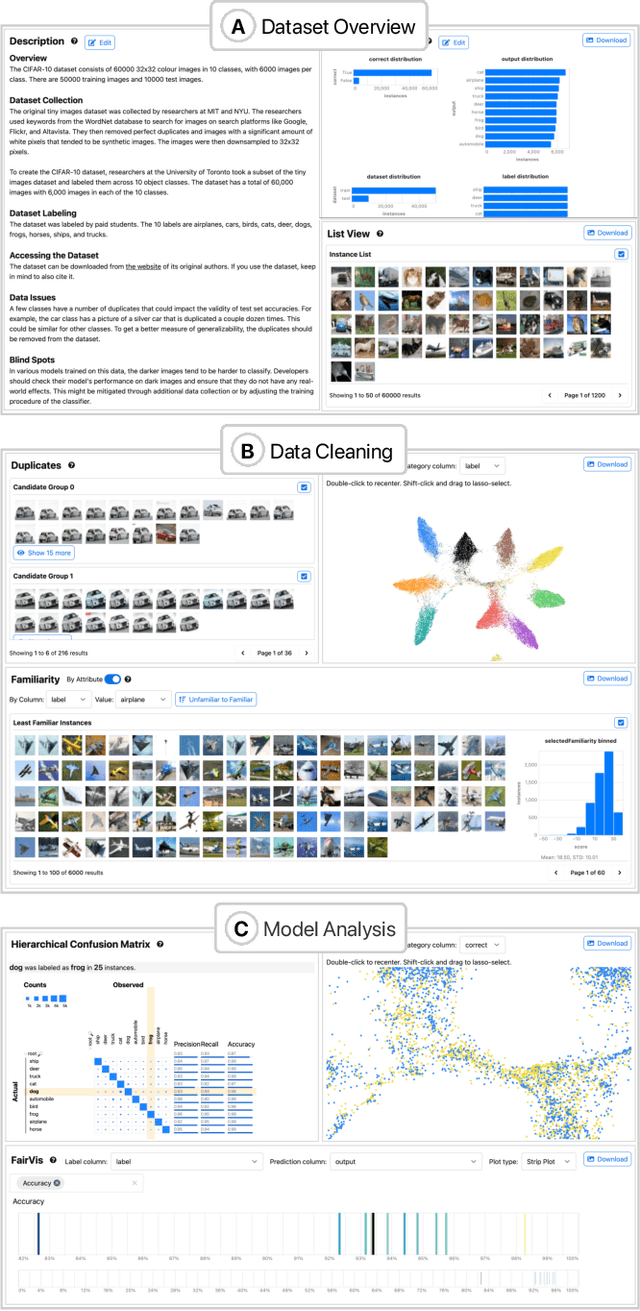
Interfaces for machine learning (ML), information and visualizations about models or data, can help practitioners build robust and responsible ML systems. Despite their benefits, recent studies of ML teams and our interviews with practitioners (n=9) showed that ML interfaces have limited adoption in practice. While existing ML interfaces are effective for specific tasks, they are not designed to be reused, explored, and shared by multiple stakeholders in cross-functional teams. To enable analysis and communication between different ML practitioners, we designed and implemented Symphony, a framework for composing interactive ML interfaces with task-specific, data-driven components that can be used across platforms such as computational notebooks and web dashboards. We developed Symphony through participatory design sessions with 10 teams (n=31), and discuss our findings from deploying Symphony to 3 production ML projects at Apple. Symphony helped ML practitioners discover previously unknown issues like data duplicates and blind spots in models while enabling them to share insights with other stakeholders.