 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Decision Making: Problems, Methods, and Opportunities
Mar 07, 2023Foundation models pretrained on diverse data at scale have demonstrated extraordinary capabilities in a wide range of vision and language tasks. When such models are deployed in real world environments, they inevitably interface with other entities and agents. For example, language models are often used to interact with human beings through dialogue, and visual perception models are used to autonomously navigate neighborhood streets. In response to these developments, new paradigms are emerging for training foundation models to interact with other agents and perform long-term reasoning. These paradigms leverage the existence of ever-larger datasets curated for multimodal, multitask, and generalist interaction. Research at the intersection of foundation models and decision making holds tremendous promise for creating powerful new systems that can interact effectively across a diverse range of applications such as dialogue, autonomous driving, healthcare, education, and robotics. In this manuscript, we examine the scope of foundation models for decision making, and provide conceptual tools and technical background for understanding the problem space and exploring new research directions. We review recent approaches that ground foundation models in practical decision making applications through a variety of methods such as prompting, conditional generative modeling, planning, optimal control, and reinforcement learning, and discuss common challenges and open problems in the field.
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Feb 14, 2023



We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 (Chung et al., 2022). Through careful ablation studies on the Flan Collection of tasks and methods, we tease apart the effect of design decisions which enable Flan-T5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks, motivating instruction-tuned models as more computationally-efficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available at https://github.com/google-research/FLAN/tree/main/flan/v2.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
Inverse scaling can become U-shaped
Nov 14, 2022Although scaling language models improves performance on a range of tasks, there are apparently some scenarios where scaling hurts performance. For instance, the Inverse Scaling Prize Round 1 (McKensie et al., 2022) identified four "inverse scaling" tasks, for which performance gets worse for larger models. These tasks were evaluated on models of up to 280B parameters, trained up to 500 zettaFLOPs of compute. This paper takes a closer look at these four tasks. We evaluate models of up to 540B parameters, trained on five times more compute than those evaluated in the Inverse Scaling Prize. With this increased range of model sizes and training compute, two out of the four tasks exhibit what we call "U-shaped scaling" -- performance decreases up to a certain model size, and then increases again up to the largest model evaluated. One hypothesis is that U-shaped scaling occurs when a task comprises a "true task" and a "distractor task". Medium-size models can do the distractor task, which hurts performance, while only large-enough models can ignore the distractor task and do the true task. The existence of U-shaped scaling implies that inverse scaling may not hold for larger models. Second, we evaluate the inverse scaling tasks using chain-of-thought (CoT) prompting, in addition to basic prompting without CoT. With CoT prompting, all four tasks show either U-shaped scaling or positive scaling, achieving perfect solve rates on two tasks and several sub-tasks. This suggests that the term "inverse scaling task" is under-specified -- a given task may be inverse scaling for one prompt but positive or U-shaped scaling for a different prompt.
Transcending Scaling Laws with 0.1% Extra Compute
Oct 20, 2022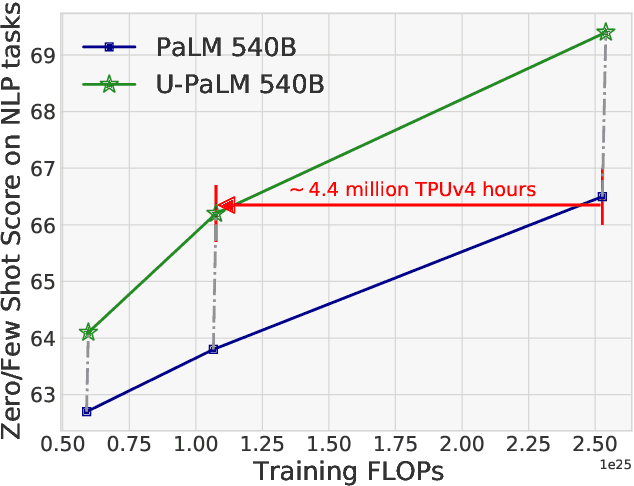
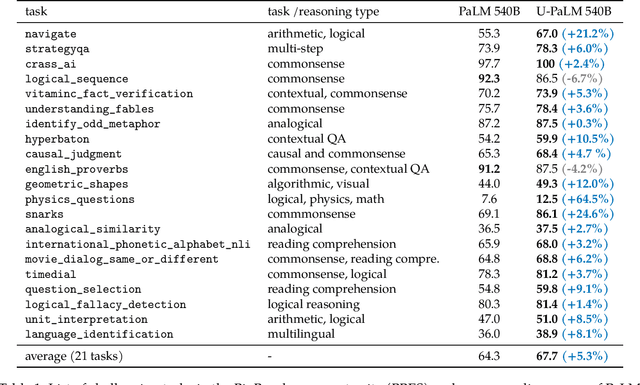
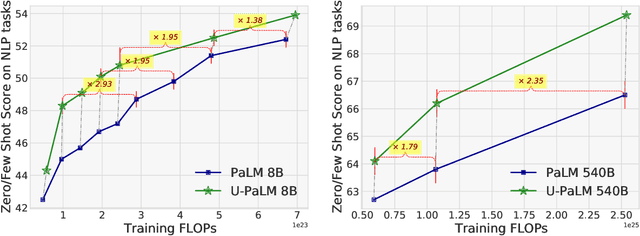
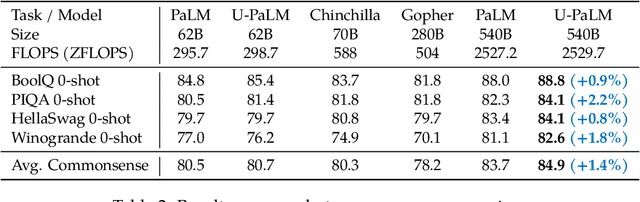
Scaling language models improves performance but comes with significant computational costs. This paper proposes UL2R, a method that substantially improves existing language models and their scaling curves with a relatively tiny amount of extra compute. The key idea is to continue training a state-of-the-art large language model (e.g., PaLM) on a few more steps with UL2's mixture-of-denoiser objective. We show that, with almost negligible extra computational costs and no new sources of data, we are able to substantially improve the scaling properties of large language models on downstream metrics. In this paper, we continue training PaLM with UL2R, introducing a new set of models at 8B, 62B, and 540B scale which we call U-PaLM. Impressively, at 540B scale, we show an approximately 2x computational savings rate where U-PaLM achieves the same performance as the final PaLM 540B model at around half its computational budget (i.e., saving $\sim$4.4 million TPUv4 hours). We further show that this improved scaling curve leads to 'emergent abilities' on challenging BIG-Bench tasks -- for instance, U-PaLM does much better than PaLM on some tasks or demonstrates better quality at much smaller scale (62B as opposed to 540B). Overall, we show that U-PaLM outperforms PaLM on many few-shot setups, i.e., English NLP tasks (e.g., commonsense reasoning, question answering), reasoning tasks with chain-of-thought (e.g., GSM8K), multilingual tasks (MGSM, TydiQA), MMLU and challenging BIG-Bench tasks. Finally, we provide qualitative examples showing the new capabilities of U-PaLM for single and multi-span infilling.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022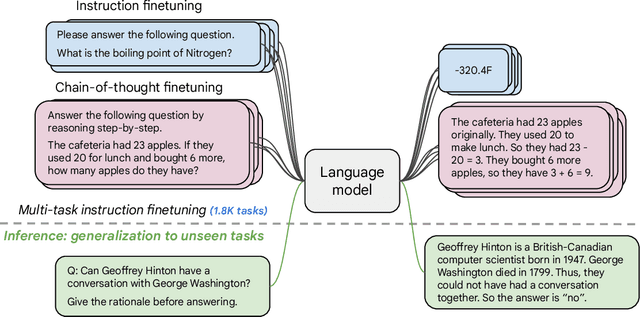

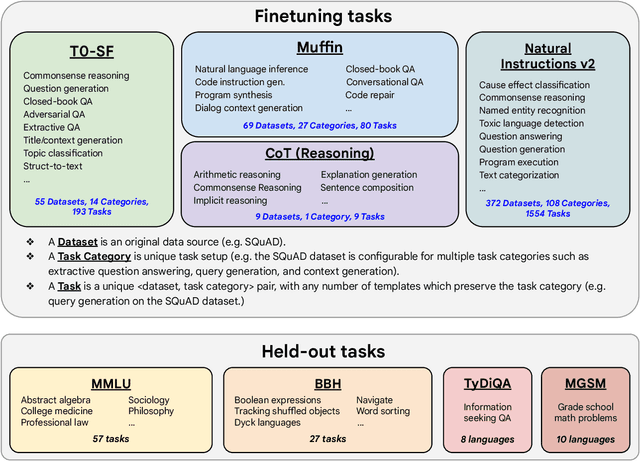

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Oct 17, 2022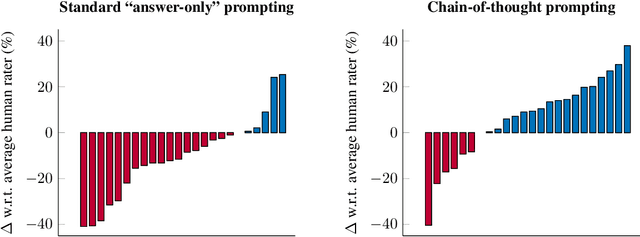

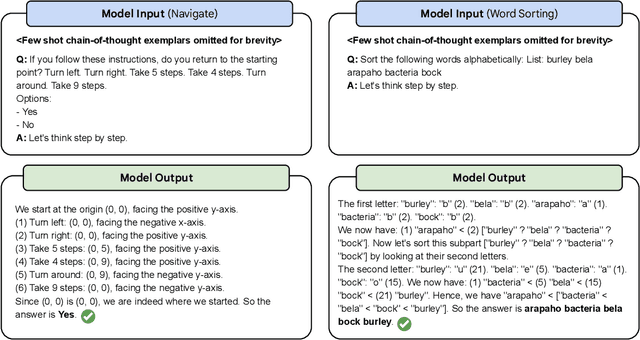
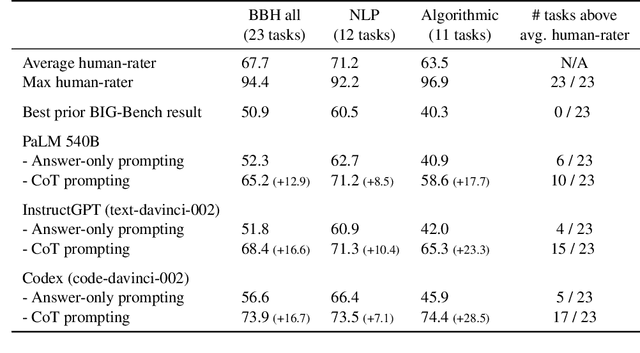
BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models. Language models have already made good progress on this benchmark, with the best model in the BIG-Bench paper outperforming average reported human-rater results on 65% of the BIG-Bench tasks via few-shot prompting. But on what tasks do language models fall short of average human-rater performance, and are those tasks actually unsolvable by current language models? In this work, we focus on a suite of 23 challenging BIG-Bench tasks which we call BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. We find that applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average human-rater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks. Since many tasks in BBH require multi-step reasoning, few-shot prompting without CoT, as done in the BIG-Bench evaluations (Srivastava et al., 2022), substantially underestimates the best performance and capabilities of language models, which is better captured via CoT prompting. As further analysis, we explore the interaction between CoT and model scale on BBH, finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.
Mind's Eye: Grounded Language Model Reasoning through Simulation
Oct 11, 2022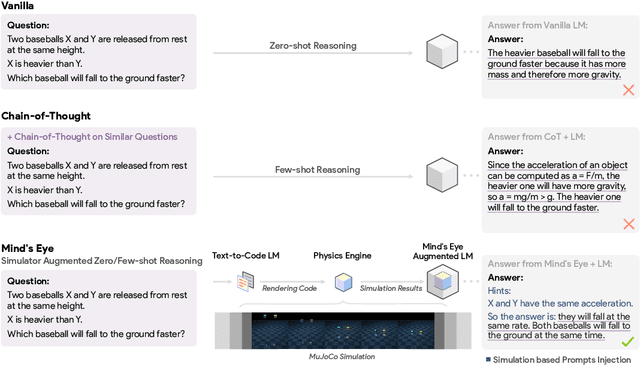


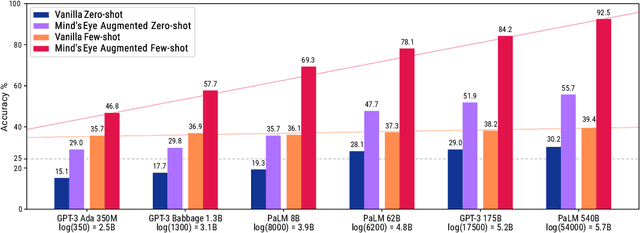
Successful and effective communication between humans and AI relies on a shared experience of the world. By training solely on written text, current language models (LMs) miss the grounded experience of humans in the real-world -- their failure to relate language to the physical world causes knowledge to be misrepresented and obvious mistakes in their reasoning. We present Mind's Eye, a paradigm to ground language model reasoning in the physical world. Given a physical reasoning question, we use a computational physics engine (DeepMind's MuJoCo) to simulate the possible outcomes, and then use the simulation results as part of the input, which enables language models to perform reasoning. Experiments on 39 tasks in a physics alignment benchmark demonstrate that Mind's Eye can improve reasoning ability by a large margin (27.9% zero-shot, and 46.0% few-shot absolute accuracy improvement on average). Smaller language models armed with Mind's Eye can obtain similar performance to models that are 100x larger. Finally, we confirm the robustness of Mind's Eye through ablation studies.
Language Models are Multilingual Chain-of-Thought Reasoners
Oct 06, 2022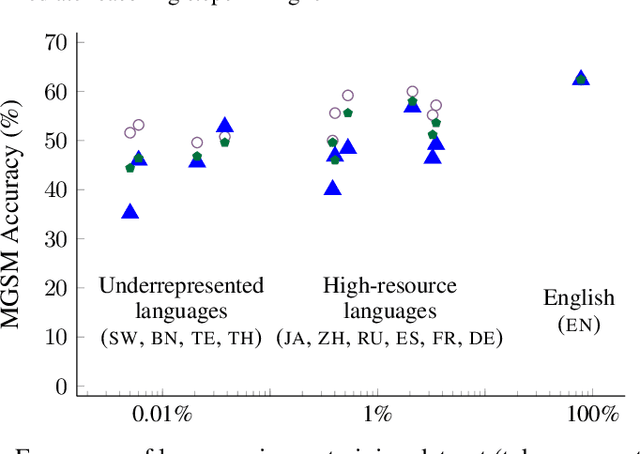

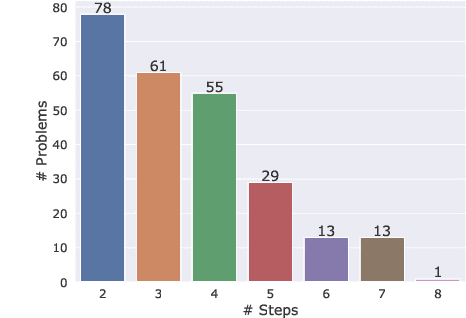

We evaluate the reasoning abilities of large language models in multilingual settings. We introduce the Multilingual Grade School Math (MGSM) benchmark, by manually translating 250 grade-school math problems from the GSM8K dataset (Cobbe et al., 2021) into ten typologically diverse languages. We find that the ability to solve MGSM problems via chain-of-thought prompting emerges with increasing model scale, and that models have strikingly strong multilingual reasoning abilities, even in underrepresented languages such as Bengali and Swahili. Finally, we show that the multilingual reasoning abilities of language models extend to other tasks such as commonsense reasoning and word-in-context semantic judgment. The MGSM benchmark is publicly available at https://github.com/google-research/url-nlp.
Rationale-Augmented Ensembles in Language Models
Jul 02, 2022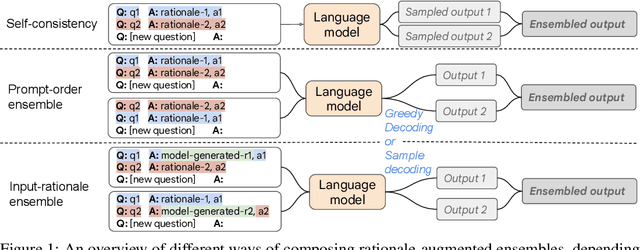

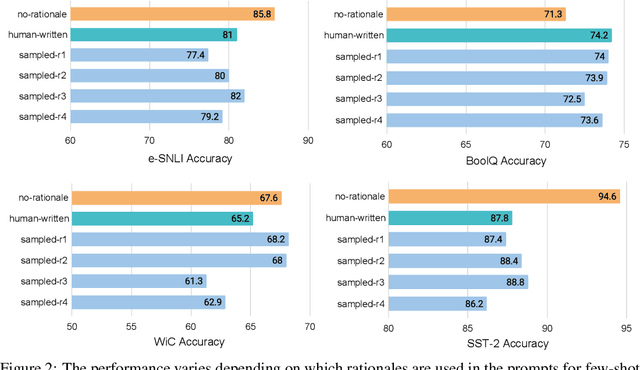

Recent research has shown that rationales, or step-by-step chains of thought, can be used to improve performance in multi-step reasoning tasks. We reconsider rationale-augmented prompting for few-shot in-context learning, where (input -> output) prompts are expanded to (input, rationale -> output) prompts. For rationale-augmented prompting we demonstrate how existing approaches, which rely on manual prompt engineering, are subject to sub-optimal rationales that may harm performance. To mitigate this brittleness, we propose a unified framework of rationale-augmented ensembles, where we identify rationale sampling in the output space as the key component to robustly improve performance. This framework is general and can easily be extended to common natural language processing tasks, even those that do not traditionally leverage intermediate steps, such as question answering, word sense disambiguation, and sentiment analysis. We demonstrate that rationale-augmented ensembles achieve more accurate and interpretable results than existing prompting approaches--including standard prompting without rationales and rationale-based chain-of-thought prompting--while simultaneously improving interpretability of model predictions through the associated rationales.