 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020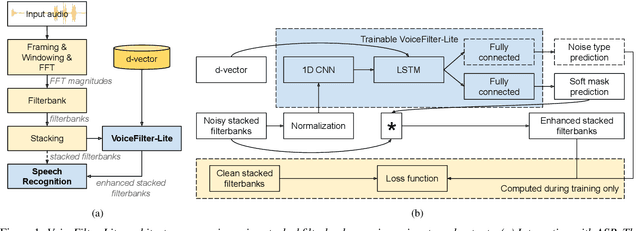

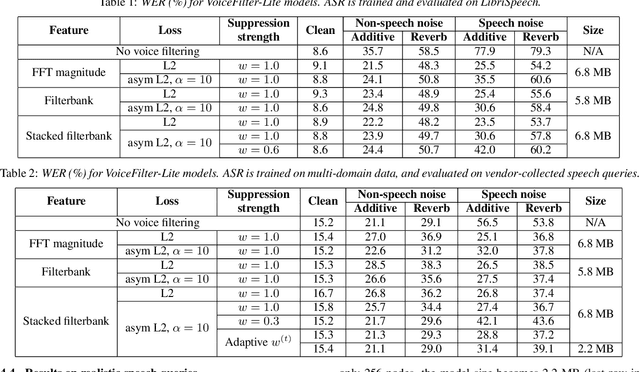
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.
Training Keyword Spotting Models on Non-IID Data with Federated Learning
Jun 04, 2020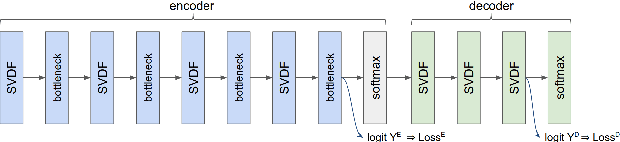
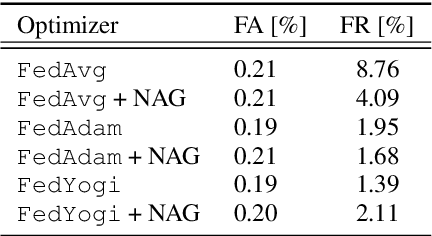

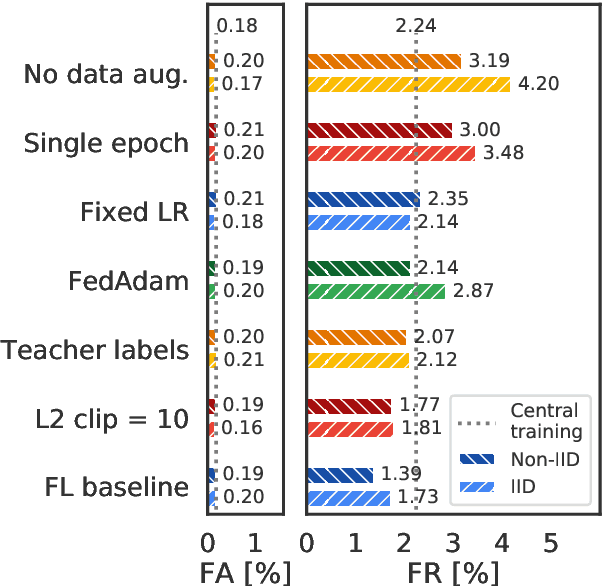
We demonstrate that a production-quality keyword-spotting model can be trained on-device using federated learning and achieve comparable false accept and false reject rates to a centrally-trained model. To overcome the algorithmic constraints associated with fitting on-device data (which are inherently non-independent and identically distributed), we conduct thorough empirical studies of optimization algorithms and hyperparameter configurations using large-scale federated simulations. To overcome resource constraints, we replace memory intensive MTR data augmentation with SpecAugment, which reduces the false reject rate by 56%. Finally, to label examples (given the zero visibility into on-device data), we explore teacher-student training.
Signal Combination for Language Identification
Nov 04, 2019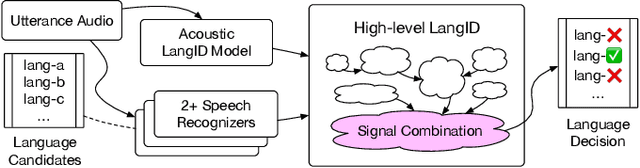

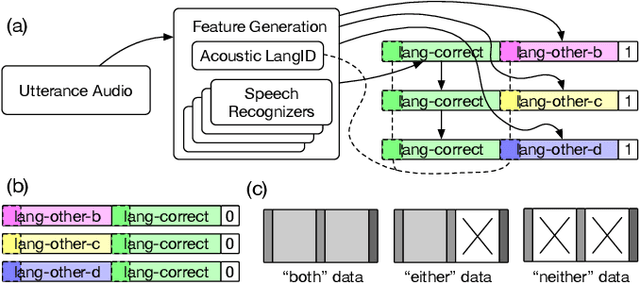
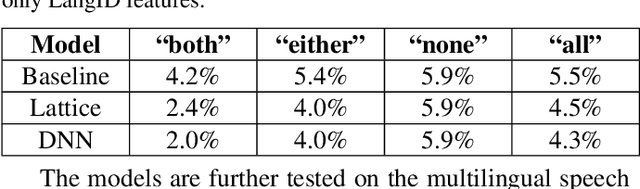
Google's multilingual speech recognition system combines low-level acoustic signals with language-specific recognizer signals to better predict the language of an utterance. This paper presents our experience with different signal combination methods to improve overall language identification accuracy. We compare the performance of a lattice-based ensemble model and a deep neural network model to combine signals from recognizers with that of a baseline that only uses low-level acoustic signals. Experimental results show that the deep neural network model outperforms the lattice-based ensemble model, and it reduced the error rate from 5.5% in the baseline to 4.3%, which is a 21.8% relative reduction.
Personal VAD: Speaker-Conditioned Voice Activity Detection
Aug 12, 2019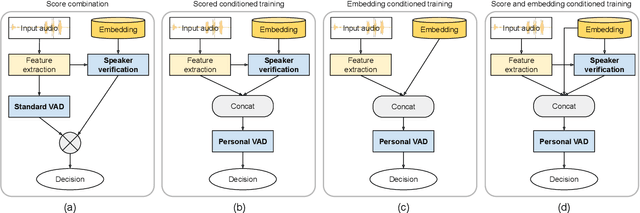

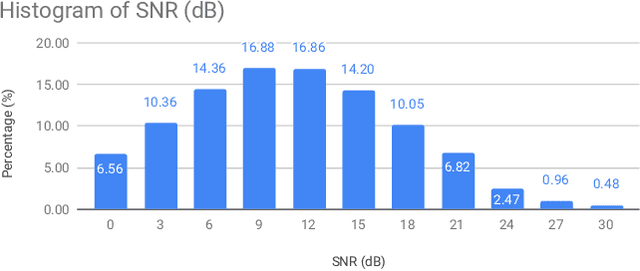
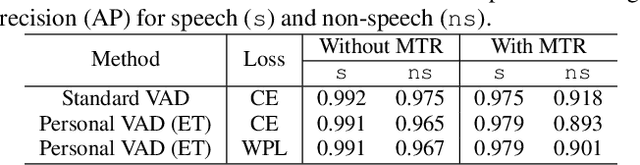
In this paper, we propose "personal VAD", a system to detect the voice activity of a target speaker at the frame level. This system is useful for gating the inputs to a streaming speech recognition system, such that it only triggers for the target user, which helps reduce the computational cost and battery consumption. We achieve this by training a VAD-alike neural network that is conditioned on the target speaker embedding or the speaker verification score. For every frame, personal VAD outputs the scores for three classes: non-speech, target speaker speech, and non-target speaker speech. With our optimal setup, we are able to train a 130KB model that outperforms a baseline system where individually trained standard VAD and speaker recognition network are combined to perform the same task.
Tuplemax Loss for Language Identification
Nov 29, 2018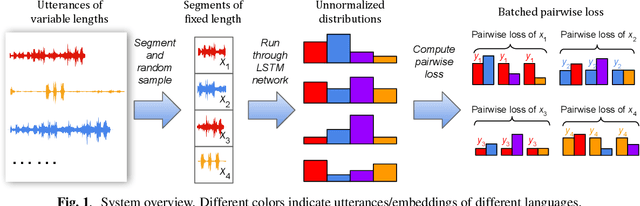

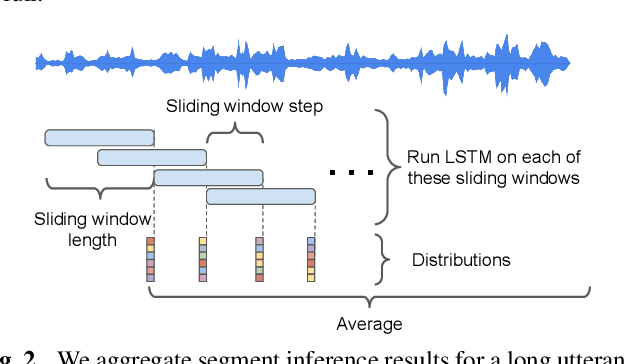
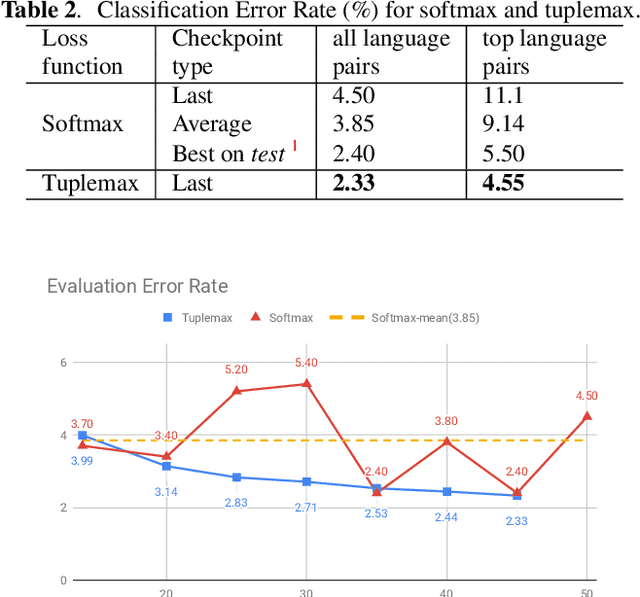
In many scenarios of a language identification task, the user will specify a small set of languages which he/she can speak instead of a large set of all possible languages. We want to model such prior knowledge into the way we train our neural networks, by replacing the commonly used softmax loss function with a novel loss function named tuplemax loss. As a matter of fact, a typical language identification system launched in North America has about 95% users who could speak no more than two languages. Using the tuplemax loss, our system achieved a 2.33% error rate, which is a relative 39.4% improvement over the 3.85% error rate of standard softmax loss method.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Nov 05, 2018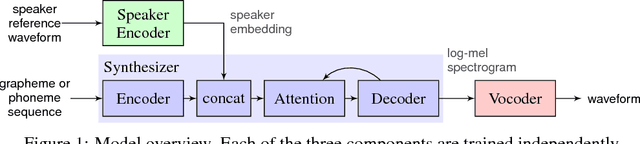

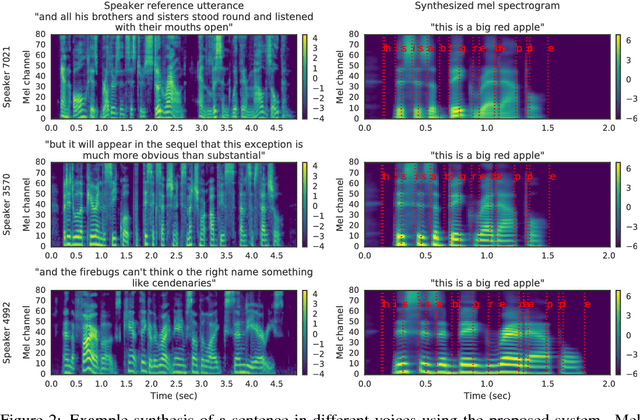
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech from thousands of speakers without transcripts, to generate a fixed-dimensional embedding vector from seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2, which generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder that converts the mel spectrogram into a sequence of time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Oct 27, 2018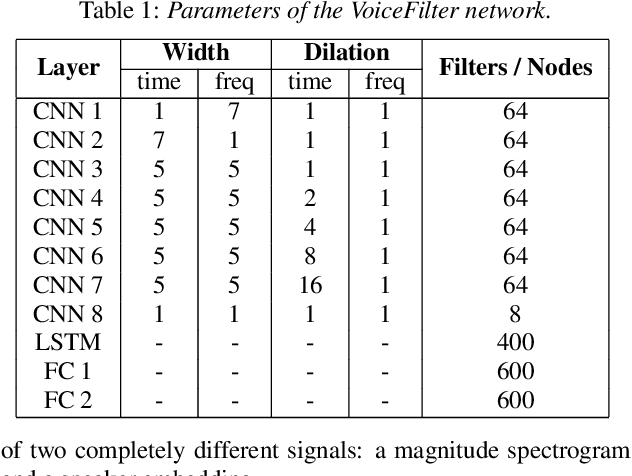
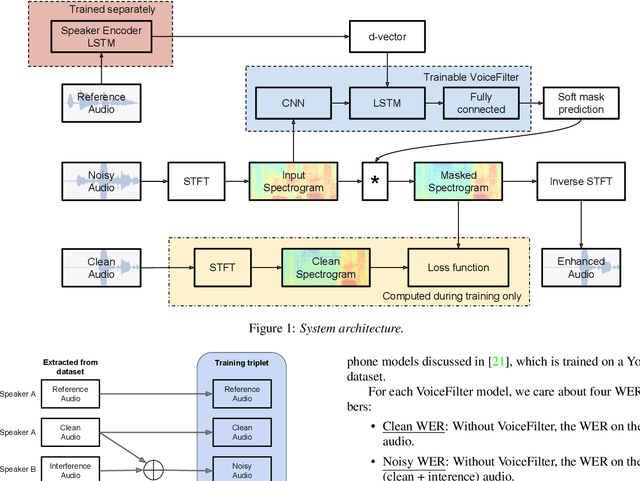
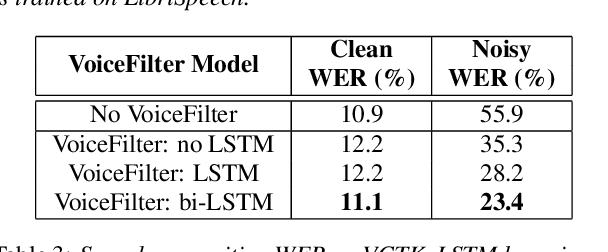
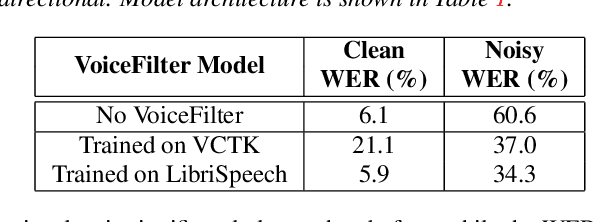
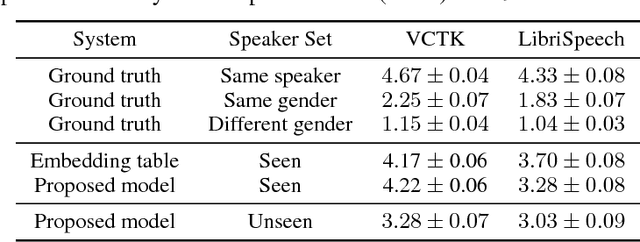
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
Generalized End-to-End Loss for Speaker Verification
Jan 31, 2018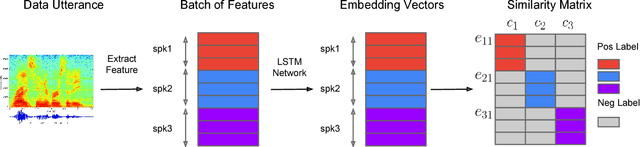
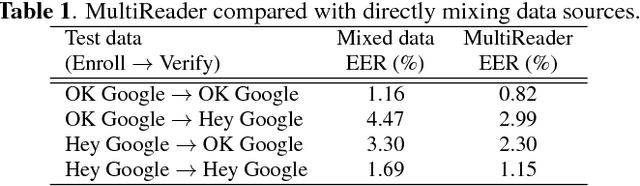
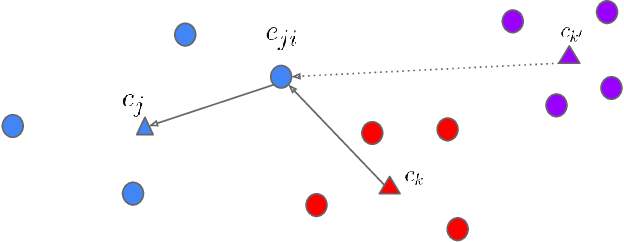
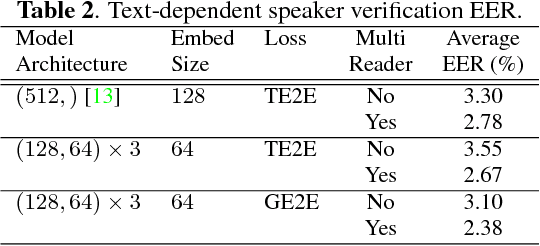
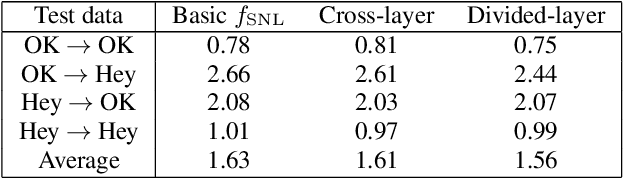
In this paper, we propose a new loss function called generalized end-to-end (GE2E) loss, which makes the training of speaker verification models more efficient than our previous tuple-based end-to-end (TE2E) loss function. Unlike TE2E, the GE2E loss function updates the network in a way that emphasizes examples that are difficult to verify at each step of the training process. Additionally, the GE2E loss does not require an initial stage of example selection. With these properties, our model with the new loss function decreases speaker verification EER by more than 10%, while reducing the training time by 60% at the same time. We also introduce the MultiReader technique, which allows us to do domain adaptation - training a more accurate model that supports multiple keywords (i.e. "OK Google" and "Hey Google") as well as multiple dialects.
Attention-Based Models for Text-Dependent Speaker Verification
Jan 31, 2018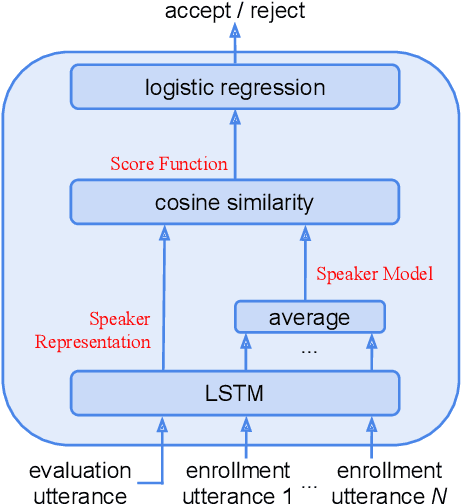
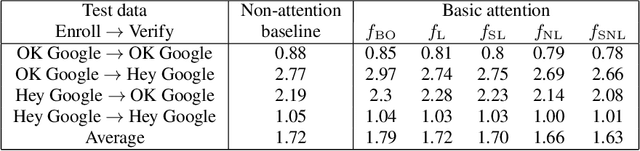
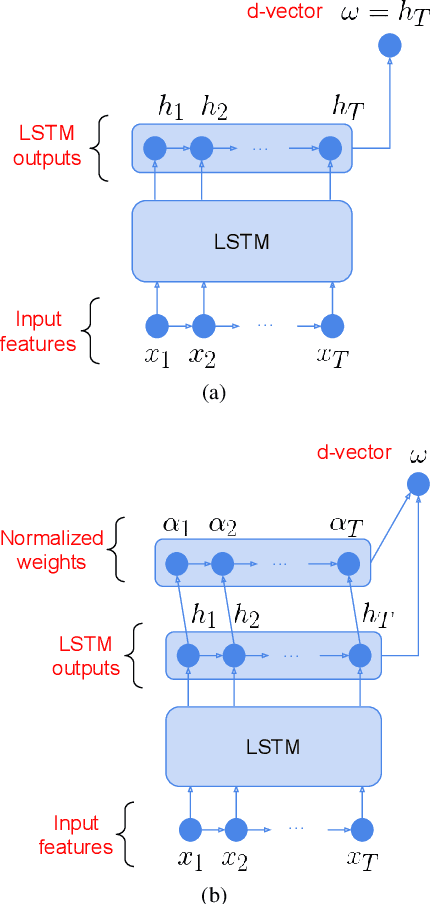
Attention-based models have recently shown great performance on a range of tasks, such as speech recognition, machine translation, and image captioning due to their ability to summarize relevant information that expands through the entire length of an input sequence. In this paper, we analyze the usage of attention mechanisms to the problem of sequence summarization in our end-to-end text-dependent speaker recognition system. We explore different topologies and their variants of the attention layer, and compare different pooling methods on the attention weights. Ultimately, we show that attention-based models can improves the Equal Error Rate (EER) of our speaker verification system by relatively 14% compared to our non-attention LSTM baseline model.
Speaker Diarization with LSTM
Jan 31, 2018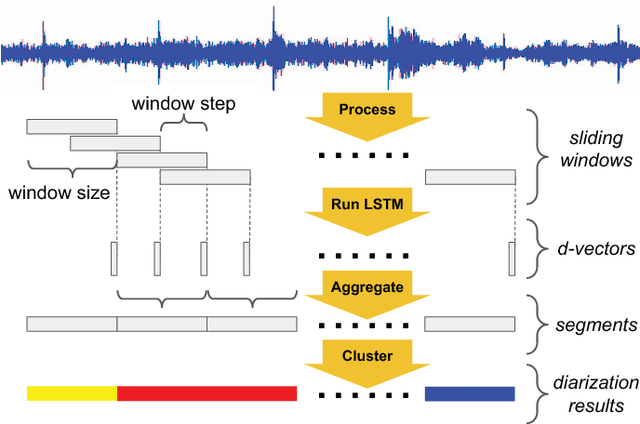
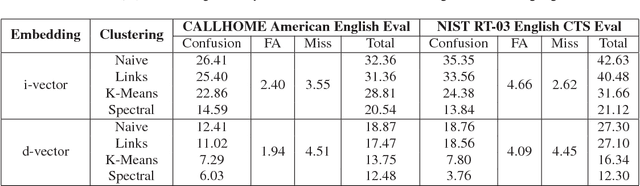

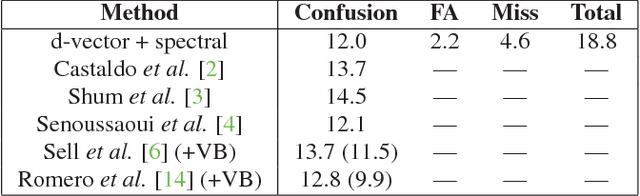
For many years, i-vector based audio embedding techniques were the dominant approach for speaker verification and speaker diarization applications. However, mirroring the rise of deep learning in various domains, neural network based audio embeddings, also known as d-vectors, have consistently demonstrated superior speaker verification performance. In this paper, we build on the success of d-vector based speaker verification systems to develop a new d-vector based approach to speaker diarization. Specifically, we combine LSTM-based d-vector audio embeddings with recent work in non-parametric clustering to obtain a state-of-the-art speaker diarization system. Our system is evaluated on three standard public datasets, suggesting that d-vector based diarization systems offer significant advantages over traditional i-vector based systems. We achieved a 12.0% diarization error rate on NIST SRE 2000 CALLHOME, while our model is trained with out-of-domain data from voice search logs.