 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program)
Apr 02, 2020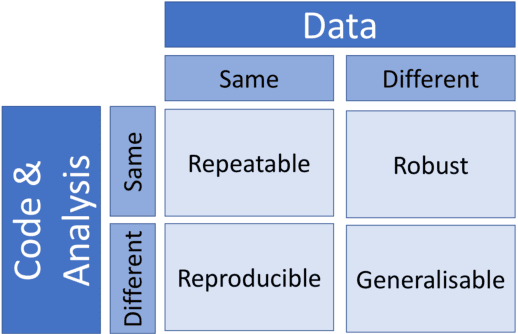
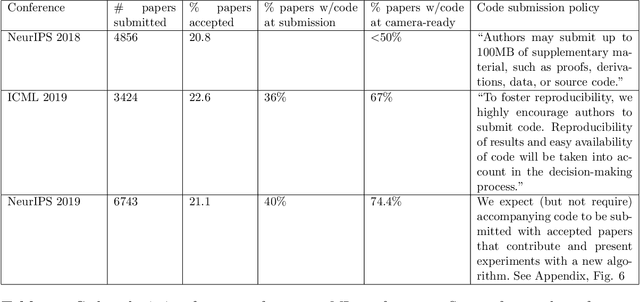
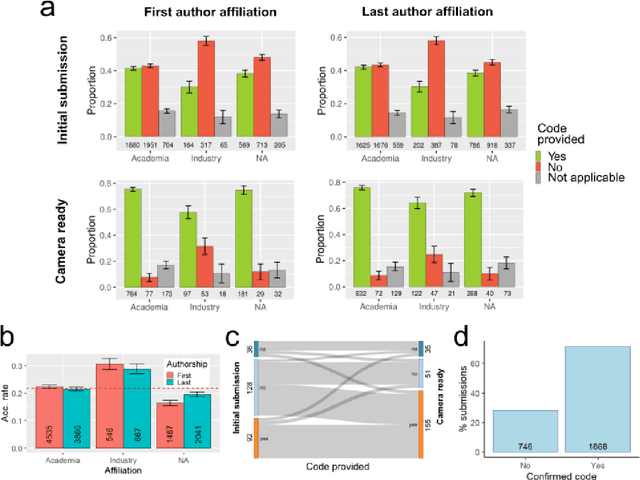
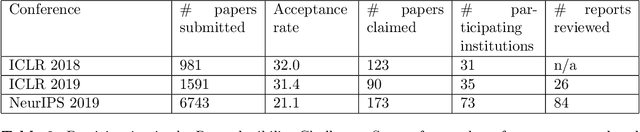
One of the challenges in machine learning research is to ensure that presented and published results are sound and reliable. Reproducibility, that is obtaining similar results as presented in a paper or talk, using the same code and data (when available), is a necessary step to verify the reliability of research findings. Reproducibility is also an important step to promote open and accessible research, thereby allowing the scientific community to quickly integrate new findings and convert ideas to practice. Reproducibility also promotes the use of robust experimental workflows, which potentially reduce unintentional errors. In 2019, the Neural Information Processing Systems (NeurIPS) conference, the premier international conference for research in machine learning, introduced a reproducibility program, designed to improve the standards across the community for how we conduct, communicate, and evaluate machine learning research. The program contained three components: a code submission policy, a community-wide reproducibility challenge, and the inclusion of the Machine Learning Reproducibility checklist as part of the paper submission process. In this paper, we describe each of these components, how it was deployed, as well as what we were able to learn from this initiative.
On-the-Fly Adaptation of Source Code Models using Meta-Learning
Mar 26, 2020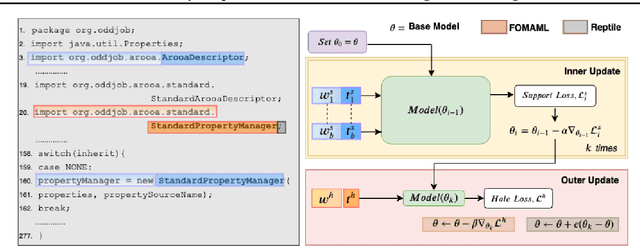

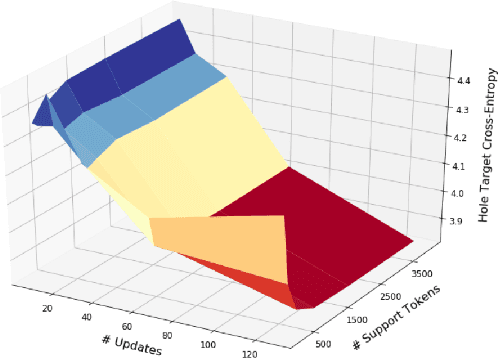
The ability to adapt to unseen, local contexts is an important challenge that successful models of source code must overcome. One of the most popular approaches for the adaptation of such models is dynamic evaluation. With dynamic evaluation, when running a model on an unseen file, the model is updated immediately after having observed each token in that file. In this work, we propose instead to frame the problem of context adaptation as a meta-learning problem. We aim to train a base source code model that is best able to learn from information in a file to deliver improved predictions of missing tokens. Unlike dynamic evaluation, this formulation allows us to select more targeted information (support tokens) for adaptation, that is both before and after a target hole in a file. We consider an evaluation setting that we call line-level maintenance, designed to reflect the downstream task of code auto-completion in an IDE. Leveraging recent developments in meta-learning such as first-order MAML and Reptile, we demonstrate improved performance in experiments on a large scale Java GitHub corpus, compared to other adaptation baselines including dynamic evaluation. Moreover, our analysis shows that, compared to a non-adaptive baseline, our approach improves performance on identifiers and literals by 44\% and 15\%, respectively. Our implementation can be found at: https://github.com/shrivastavadisha/meta_learn_source_code
Your GAN is Secretly an Energy-based Model and You Should use Discriminator Driven Latent Sampling
Mar 24, 2020
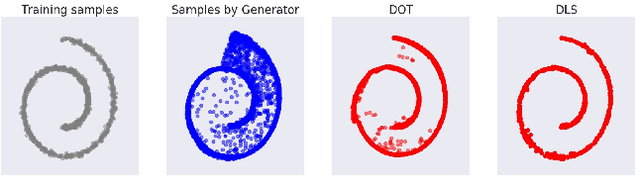
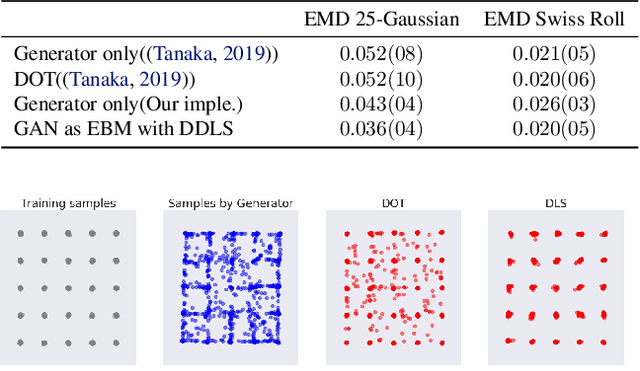

We show that the sum of the implicit generator log-density $\log p_g$ of a GAN with the logit score of the discriminator defines an energy function which yields the true data density when the generator is imperfect but the discriminator is optimal, thus making it possible to improve on the typical generator (with implicit density $p_g$). To make that practical, we show that sampling from this modified density can be achieved by sampling in latent space according to an energy-based model induced by the sum of the latent prior log-density and the discriminator output score. This can be achieved by running a Langevin MCMC in latent space and then applying the generator function, which we call Discriminator Driven Latent Sampling~(DDLS). We show that DDLS is highly efficient compared to previous methods which work in the high-dimensional pixel space and can be applied to improve on previously trained GANs of many types. We evaluate DDLS on both synthetic and real-world datasets qualitatively and quantitatively. On CIFAR-10, DDLS substantially improves the Inception Score of an off-the-shelf pre-trained SN-GAN~\citep{sngan} from $8.22$ to $9.09$ which is even comparable to the class-conditional BigGAN~\citep{biggan} model. This achieves a new state-of-the-art in unconditional image synthesis setting without introducing extra parameters or additional training.
DIBS: Diversity inducing Information Bottleneck in Model Ensembles
Mar 10, 2020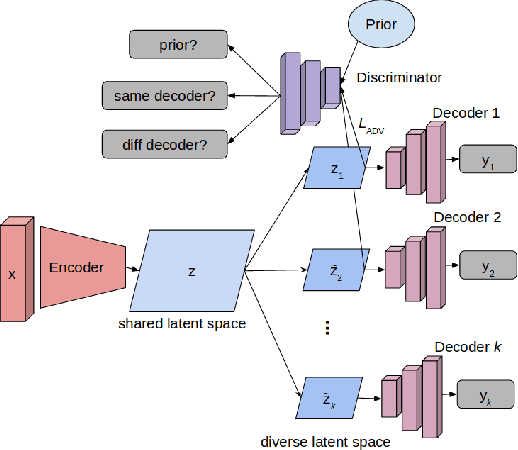
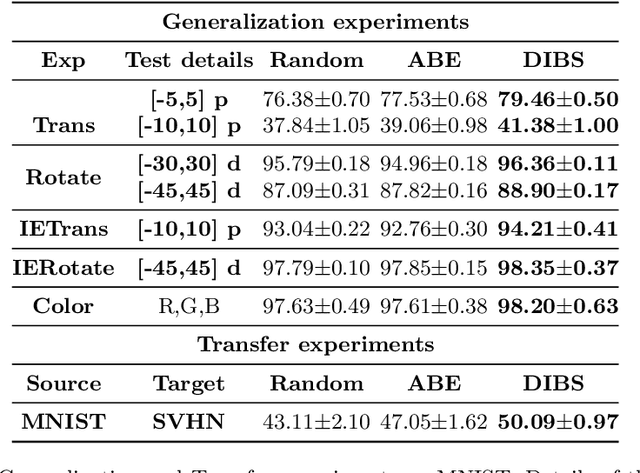
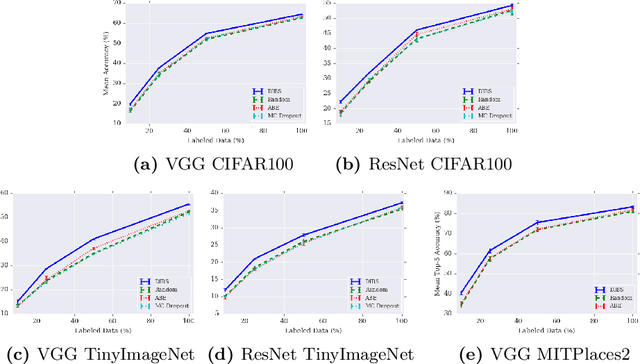
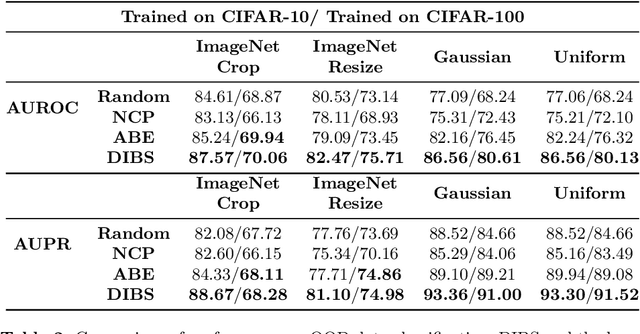
Although deep learning models have achieved state-of-the-art performance on a number of vision tasks, generalization over high dimensional multi-modal data, and reliable predictive uncertainty estimation are still active areas of research. Bayesian approaches including Bayesian Neural Nets (BNNs) do not scale well to modern computer vision tasks, as they are difficult to train, and have poor generalization under dataset-shift. This motivates the need for effective ensembles which can generalize and give reliable uncertainty estimates. In this paper, we target the problem of generating effective ensembles of neural networks by encouraging diversity in prediction. We explicitly optimize a diversity inducing adversarial loss for learning the stochastic latent variables and thereby obtain diversity in the output predictions necessary for modeling multi-modal data. We evaluate our method on benchmark datasets: MNIST, CIFAR100, TinyImageNet and MIT Places 2, and compared to the most competitive baselines show significant improvements in classification accuracy, under a shift in the data distribution and in out-of-distribution detection. Code will be released in this url https://github.com/rvl-lab-utoronto/dibs
Curriculum By Texture
Mar 03, 2020



Convolutional Neural Networks (CNNs) have shown impressive performance in computer vision tasks such as image classification and segmentation. One factor for the success of CNNs is that they have an inductive bias that assumes a certain type of spatial structure is present in the data. Recent work by Geirhos et al. (2018) shows how learning in CNNs causes the learned CNN models to be biased towards high-frequency textural information, compared to low-frequency shape information in images. Many tasks generally requires both shape and textural information. Hence, we propose a simple curriculum based scheme which improves the ability of CNNs to be less biased towards textural information, and at the same time, being able to represent both the shape and textural information. We propose to augment the training of CNNs by controlling the amount of textural information that is available to the CNNs during the training process, by convolving the output of a CNN layer with a low-pass filter, or simply a Gaussian kernel. By reducing the standard deviation of the Gaussian kernel, we are able to gradually increase the amount of textural information available as training progresses, and hence reduce the texture bias. Such an augmented training scheme significantly improves the performance of CNNs on various image classification tasks, while adding no additional trainable parameters or auxiliary regularization objectives. We also observe significant improvements when using the trained CNNs to perform transfer learning on a different dataset, and transferring to a different task which shows how the learned CNNs using the proposed method act as better feature extractors.
On Catastrophic Interference in Atari 2600 Games
Feb 28, 2020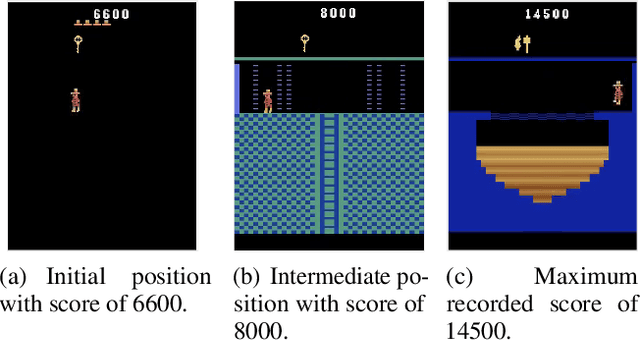
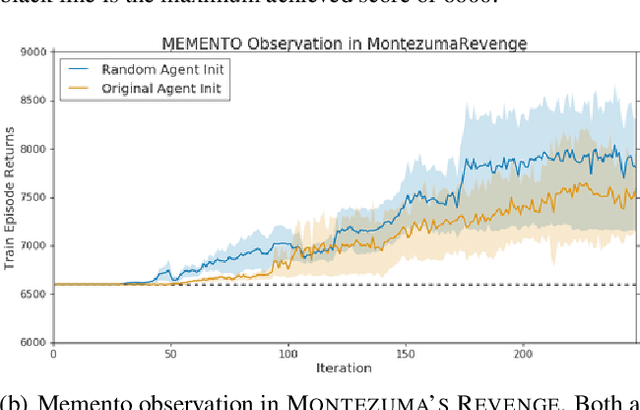
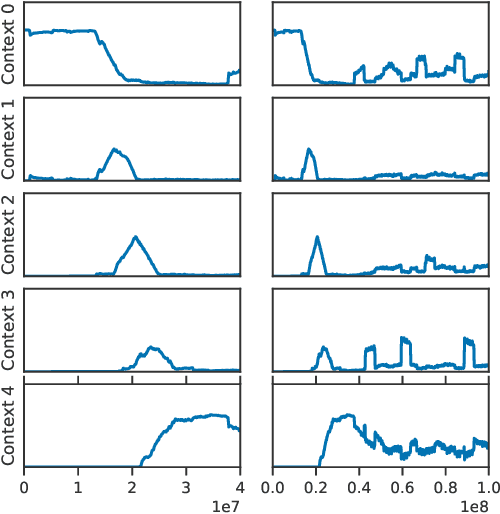
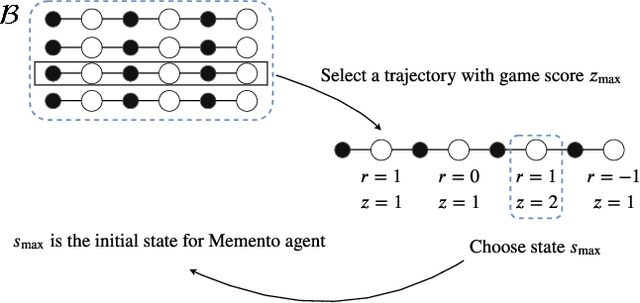
Model-free deep reinforcement learning algorithms are troubled with poor sample efficiency -- learning reliable policies generally requires a vast amount of interaction with the environment. One hypothesis is that catastrophic interference between various segments within the environment is an issue. In this paper, we perform a large-scale empirical study on the presence of catastrophic interference in the Arcade Learning Environment and find that learning particular game segments frequently degrades performance on previously learned segments. In what we term the Memento observation, we show that an identically parameterized agent spawned from a state where the original agent plateaued, reliably makes further progress. This phenomenon is general -- we find consistent performance boosts across architectures, learning algorithms and environments. Our results indicate that eliminating catastrophic interference can contribute towards improved performance and data efficiency of deep reinforcement learning algorithms.
Algorithmic Improvements for Deep Reinforcement Learning applied to Interactive Fiction
Nov 28, 2019

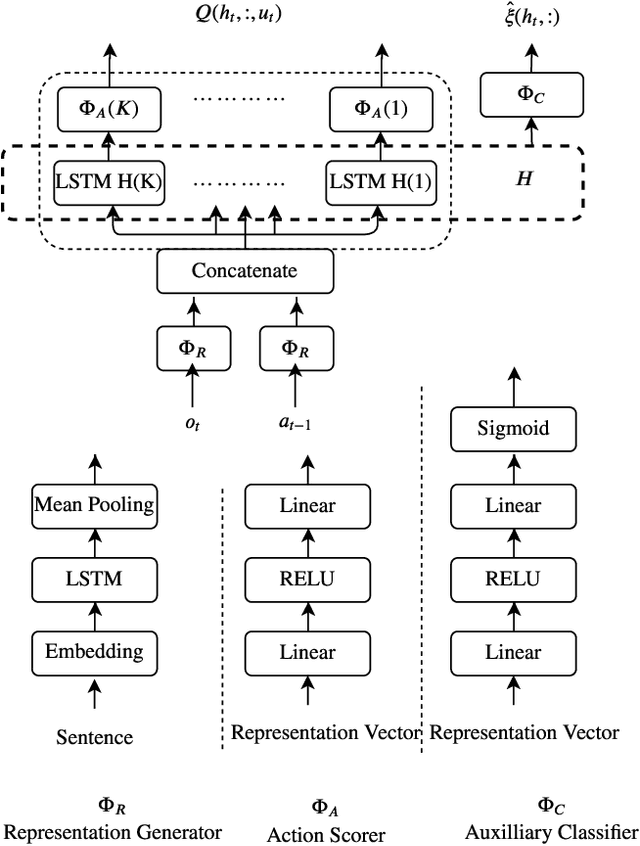

Text-based games are a natural challenge domain for deep reinforcement learning algorithms. Their state and action spaces are combinatorially large, their reward function is sparse, and they are partially observable: the agent is informed of the consequences of its actions through textual feedback. In this paper we emphasize this latter point and consider the design of a deep reinforcement learning agent that can play from feedback alone. Our design recognizes and takes advantage of the structural characteristics of text-based games. We first propose a contextualisation mechanism, based on accumulated reward, which simplifies the learning problem and mitigates partial observability. We then study different methods that rely on the notion that most actions are ineffectual in any given situation, following Zahavy et al.'s idea of an admissible action. We evaluate these techniques in a series of text-based games of increasing difficulty based on the TextWorld framework, as well as the iconic game Zork. Empirically, we find that these techniques improve the performance of a baseline deep reinforcement learning agent applied to text-based games.
Small-GAN: Speeding Up GAN Training Using Core-sets
Oct 29, 2019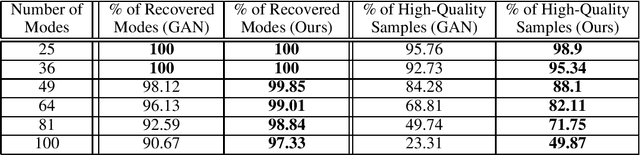
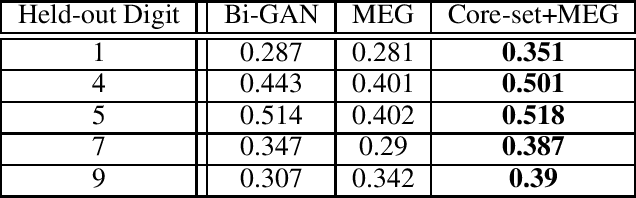


Recent work by Brock et al. (2018) suggests that Generative Adversarial Networks (GANs) benefit disproportionately from large mini-batch sizes. Unfortunately, using large batches is slow and expensive on conventional hardware. Thus, it would be nice if we could generate batches that were effectively large though actually small. In this work, we propose a method to do this, inspired by the use of Coreset-selection in active learning. When training a GAN, we draw a large batch of samples from the prior and then compress that batch using Coreset-selection. To create effectively large batches of 'real' images, we create a cached dataset of Inception activations of each training image, randomly project them down to a smaller dimension, and then use Coreset-selection on those projected activations at training time. We conduct experiments showing that this technique substantially reduces training time and memory usage for modern GAN variants, that it reduces the fraction of dropped modes in a synthetic dataset, and that it allows GANs to reach a new state of the art in anomaly detection.
Learning Neural Causal Models from Unknown Interventions
Oct 02, 2019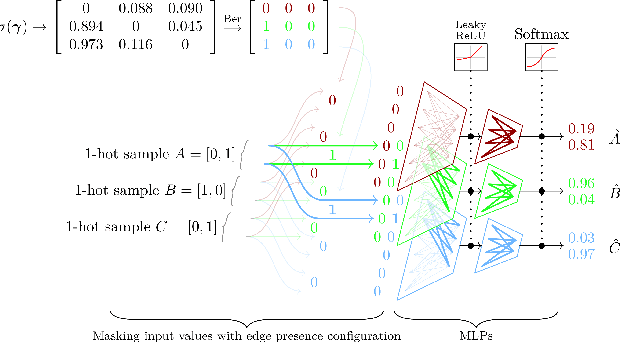



Meta-learning over a set of distributions can be interpreted as learning different types of parameters corresponding to short-term vs long-term aspects of the mechanisms underlying the generation of data. These are respectively captured by quickly-changing parameters and slowly-changing meta-parameters. We present a new framework for meta-learning causal models where the relationship between each variable and its parents is modeled by a neural network, modulated by structural meta-parameters which capture the overall topology of a directed graphical model. Our approach avoids a discrete search over models in favour of a continuous optimization procedure. We study a setting where interventional distributions are induced as a result of a random intervention on a single unknown variable of an unknown ground truth causal model, and the observations arising after such an intervention constitute one meta-example. To disentangle the slow-changing aspects of each conditional from the fast-changing adaptations to each intervention, we parametrize the neural network into fast parameters and slow meta-parameters. We introduce a meta-learning objective that favours solutions robust to frequent but sparse interventional distribution change, and which generalize well to previously unseen interventions. Optimizing this objective is shown experimentally to recover the structure of the causal graph.
InfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019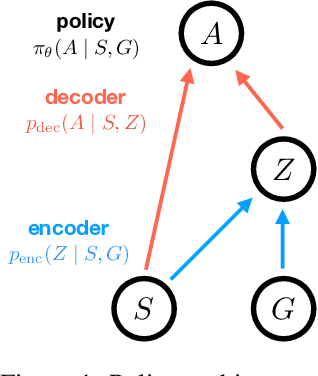



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.