 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Preference Reinforcement Learning
May 21, 2026Post-training has split large language model (LLM) alignment into two largely disconnected tracks. Online reinforcement learning (RL) with verifiable rewards drives emergent reasoning on math and code but depends on a programmatic verifier that cannot reach open-ended tasks, while preference optimization handles open-ended generation yet forgoes the continuous exploration that powers online RL. Closing this gap requires a verifier for open-ended quality, but a scalar reward model is the wrong shape for the job. Quality is multi-dimensional, and any scalar score is an incomplete proxy that lets online RL collapse onto whichever axis the score is most sensitive to. We turn instead to the General Preference Model (GPM), which embeds responses into $k$ skew-symmetric subspaces and represents preference as a structured, intransitivity-aware comparison. Building on this, we propose General Preference Reinforcement Learning (GPRL), which carries the $k$-way structure through to the policy update. GPRL computes per-dimension group-relative advantages, normalizes each on its own scale so no axis can dominate, and aggregates them with context-dependent eigenvalues. The same structure powers a closed-loop drift monitor that detects single-axis exploitation and corrects it on the fly by reweighting dimensions and tightening the trust region. Starting from $\texttt{Llama-3-8B-Instruct}$, GPRL reaches a length-controlled win rate of $56.51\%$ on AlpacaEval~2.0 while also outperforming SimPO and SPPO on Arena-Hard, MT-Bench, and WildBench by resisting reward hacking across extended training runs.
Pressure, What Pressure? Sycophancy Disentanglement in Language Models via Reward Decomposition
Apr 07, 2026Large language models exhibit sycophancy, the tendency to shift their stated positions toward perceived user preferences or authority cues regardless of evidence. Standard alignment methods fail to correct this because scalar reward models conflate two distinct failure modes into a single signal: pressure capitulation, where the model changes a correct answer under social pressure, and evidence blindness, where the model ignores the provided context entirely. We operationalise sycophancy through formal definitions of pressure independence and evidence responsiveness, serving as a working framework for disentangled training rather than a definitive characterisation of the phenomenon. We propose the first approach to sycophancy reduction via reward decomposition, introducing a multi-component Group Relative Policy Optimisation (GRPO) reward that decomposes the training signal into five terms: pressure resistance, context fidelity, position consistency, agreement suppression, and factual correctness. We train using a contrastive dataset pairing pressure-free baselines with pressured variants across three authority levels and two opposing evidence contexts. Across five base models, our two-phase pipeline consistently reduces sycophancy on all metric axes, with ablations confirming that each reward term governs an independent behavioural dimension. The learned resistance to pressure generalises beyond our training methodology and prompt structure, reducing answer-priming sycophancy by up to 17 points on SycophancyEval despite the absence of such pressure forms during training.
$S^3$: Stratified Scaling Search for Test-Time in Diffusion Language Models
Apr 07, 2026Test-time scaling investigates whether a fixed diffusion language model (DLM) can generate better outputs when given more inference compute, without additional training. However, naive best-of-$K$ sampling is fundamentally limited because it repeatedly draws from the same base diffusion distribution, whose high-probability regions are often misaligned with high-quality outputs. We propose $S^3$ (Stratified Scaling Search), a classical verifier-guided search method that improves generation by reallocating compute during the denoising process rather than only at the final output stage. At each denoising step, $S^3$ expands multiple candidate trajectories, evaluates them with a lightweight reference-free verifier, and selectively resamples promising candidates while preserving diversity within the search frontier. This procedure effectively approximates a reward-tilted sampling distribution that favors higher-quality outputs while remaining anchored to the model prior. Experiments with LLaDA-8B-Instruct on MATH-500, GSM8K, ARC-Challenge, and TruthfulQA demonstrate that $S^3$ consistently improves performance across benchmarks, achieving the largest gains on mathematical reasoning tasks while leaving the underlying model and decoding schedule unchanged. These results show that classical search over denoising trajectories provides a practical mechanism for test-time scaling in DLMs.
Continuous-Utility Direct Preference Optimization
Jan 31, 2026Large language model reasoning is often treated as a monolithic capability, relying on binary preference supervision that fails to capture partial progress or fine-grained reasoning quality. We introduce Continuous Utility Direct Preference Optimization (CU-DPO), a framework that aligns models to a portfolio of prompt-based cognitive strategies by replacing binary labels with continuous scores that capture fine-grained reasoning quality. We prove that learning with K strategies yields a Theta(K log K) improvement in sample complexity over binary preferences, and that DPO converges to the entropy-regularized utility-maximizing policy. To exploit this signal, we propose a two-stage training pipeline: (i) strategy selection, which optimizes the model to choose the best strategy for a given problem via best-vs-all comparisons, and (ii) execution refinement, which trains the model to correctly execute the selected strategy using margin-stratified pairs. On mathematical reasoning benchmarks, CU-DPO improves strategy selection accuracy from 35-46 percent to 68-78 percent across seven base models, yielding consistent downstream reasoning gains of up to 6.6 points on in-distribution datasets with effective transfer to out-of-distribution tasks.
Optimal Empirical Risk Minimization under Temporal Distribution Shifts
Jul 17, 2025Temporal distribution shifts pose a key challenge for machine learning models trained and deployed in dynamically evolving environments. This paper introduces RIDER (RIsk minimization under Dynamically Evolving Regimes) which derives optimally-weighted empirical risk minimization procedures under temporal distribution shifts. Our approach is theoretically grounded in the random distribution shift model, where random shifts arise as a superposition of numerous unpredictable changes in the data-generating process. We show that common weighting schemes, such as pooling all data, exponentially weighting data, and using only the most recent data, emerge naturally as special cases in our framework. We demonstrate that RIDER consistently improves out-of-sample predictive performance when applied as a fine-tuning step on the Yearbook dataset, across a range of benchmark methods in Wild-Time. Moreover, we show that RIDER outperforms standard weighting strategies in two other real-world tasks: predicting stock market volatility and forecasting ride durations in NYC taxi data.
Building Trust: Foundations of Security, Safety and Transparency in AI
Nov 19, 2024This paper explores the rapidly evolving ecosystem of publicly available AI models, and their potential implications on the security and safety landscape. As AI models become increasingly prevalent, understanding their potential risks and vulnerabilities is crucial. We review the current security and safety scenarios while highlighting challenges such as tracking issues, remediation, and the apparent absence of AI model lifecycle and ownership processes. Comprehensive strategies to enhance security and safety for both model developers and end-users are proposed. This paper aims to provide some of the foundational pieces for more standardized security, safety, and transparency in the development and operation of AI models and the larger open ecosystems and communities forming around them.
KinDEL: DNA-Encoded Library Dataset for Kinase Inhibitors
Oct 11, 2024



DNA-Encoded Libraries (DEL) are combinatorial small molecule libraries that offer an efficient way to characterize diverse chemical spaces. Selection experiments using DELs are pivotal to drug discovery efforts, enabling high-throughput screens for hit finding. However, limited availability of public DEL datasets hinders the advancement of computational techniques designed to process such data. To bridge this gap, we present KinDEL, one of the first large, publicly available DEL datasets on two kinases: Mitogen-Activated Protein Kinase 14 (MAPK14) and Discoidin Domain Receptor Tyrosine Kinase 1 (DDR1). Interest in this data modality is growing due to its ability to generate extensive supervised chemical data that densely samples around select molecular structures. Demonstrating one such application of the data, we benchmark different machine learning techniques to develop predictive models for hit identification; in particular, we highlight recent structure-based probabilistic approaches. Finally, we provide biophysical assay data, both on- and off-DNA, to validate our models on a smaller subset of molecules. Data and code for our benchmarks can be found at: https://github.com/insitro/kindel.
Learning Insulin-Glucose Dynamics in the Wild
Aug 06, 2020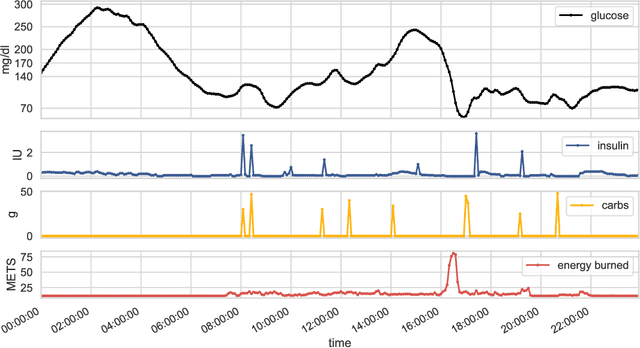

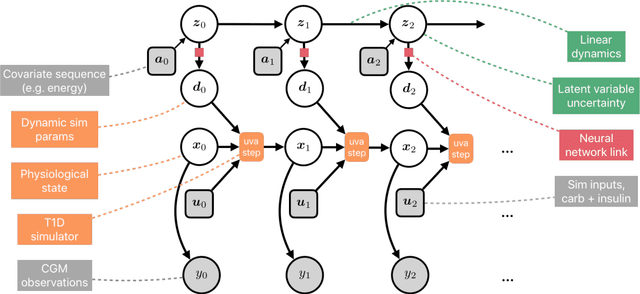
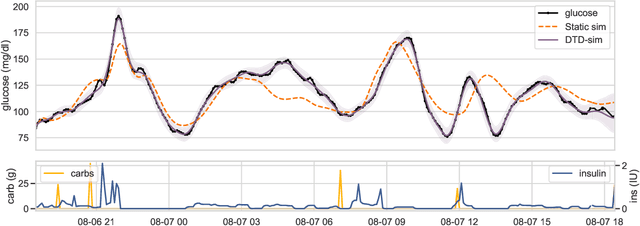
We develop a new model of insulin-glucose dynamics for forecasting blood glucose in type 1 diabetics. We augment an existing biomedical model by introducing time-varying dynamics driven by a machine learning sequence model. Our model maintains a physiologically plausible inductive bias and clinically interpretable parameters -- e.g., insulin sensitivity -- while inheriting the flexibility of modern pattern recognition algorithms. Critical to modeling success are the flexible, but structured representations of subject variability with a sequence model. In contrast, less constrained models like the LSTM fail to provide reliable or physiologically plausible forecasts. We conduct an extensive empirical study. We show that allowing biomedical model dynamics to vary in time improves forecasting at long time horizons, up to six hours, and produces forecasts consistent with the physiological effects of insulin and carbohydrates.
Improving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program)
Apr 02, 2020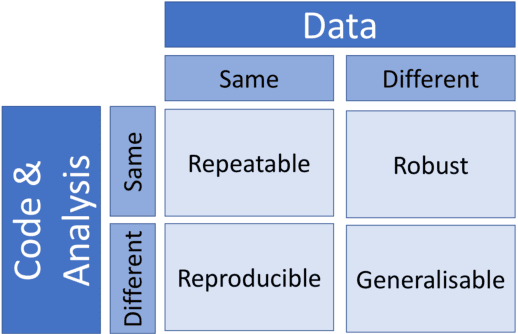
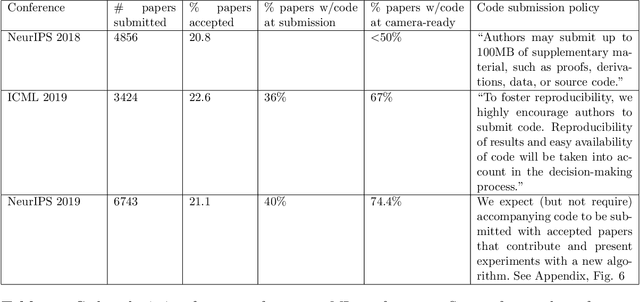
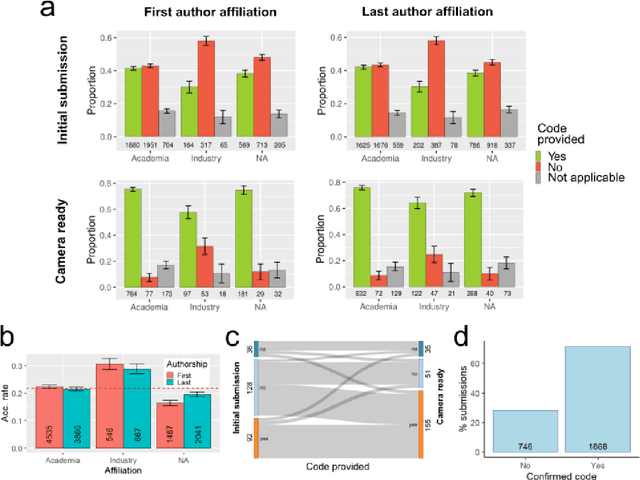
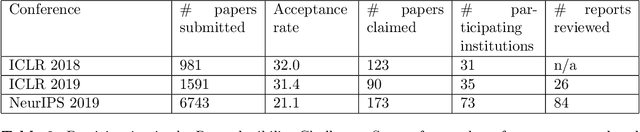
One of the challenges in machine learning research is to ensure that presented and published results are sound and reliable. Reproducibility, that is obtaining similar results as presented in a paper or talk, using the same code and data (when available), is a necessary step to verify the reliability of research findings. Reproducibility is also an important step to promote open and accessible research, thereby allowing the scientific community to quickly integrate new findings and convert ideas to practice. Reproducibility also promotes the use of robust experimental workflows, which potentially reduce unintentional errors. In 2019, the Neural Information Processing Systems (NeurIPS) conference, the premier international conference for research in machine learning, introduced a reproducibility program, designed to improve the standards across the community for how we conduct, communicate, and evaluate machine learning research. The program contained three components: a code submission policy, a community-wide reproducibility challenge, and the inclusion of the Machine Learning Reproducibility checklist as part of the paper submission process. In this paper, we describe each of these components, how it was deployed, as well as what we were able to learn from this initiative.
A Unified Framework for Long Range and Cold Start Forecasting of Seasonal Profiles in Time Series
Aug 26, 2018
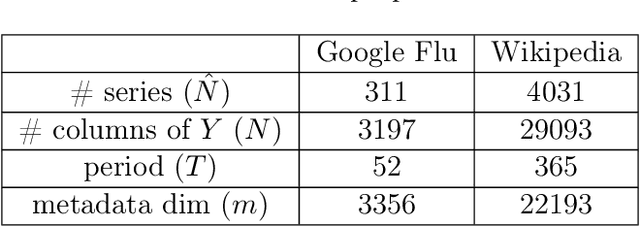
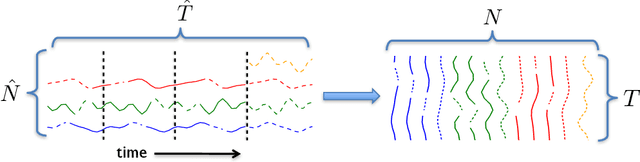
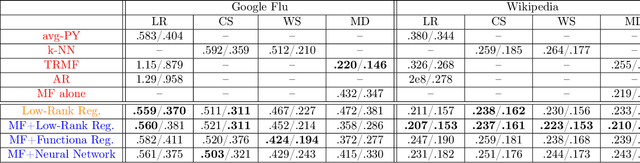
Providing long-range forecasts is a fundamental challenge in time series modeling, which is only compounded by the challenge of having to form such forecasts when a time series has never previously been observed. The latter challenge is the time series version of the cold-start problem seen in recommender systems which, to our knowledge, has not been addressed in previous work. A similar problem occurs when a long range forecast is required after only observing a small number of time points --- a warm start forecast. With these aims in mind, we focus on forecasting seasonal profiles---or baseline demand---for periods on the order of a year in three cases: the long range case with multiple previously observed seasonal profiles, the cold start case with no previous observed seasonal profiles, and the warm start case with only a single partially observed profile. Classical time series approaches that perform iterated step-ahead forecasts based on previous observations struggle to provide accurate long range predictions; in settings with little to no observed data, such approaches are simply not applicable. Instead, we present a straightforward framework which combines ideas from high-dimensional regression and matrix factorization on a carefully constructed data matrix. Key to our formulation and resulting performance is leveraging (1) repeated patterns over fixed periods of time and across series, and (2) metadata associated with the individual series; without this additional data, the cold-start/warm-start problems are nearly impossible to solve. We demonstrate that our framework can accurately forecast an array of seasonal profiles on multiple large scale datasets.