 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-entry Prediction for Online Conversations via Self-Supervised Learning
Sep 05, 2021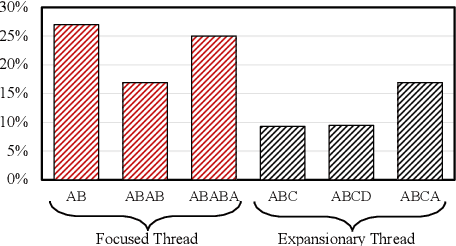
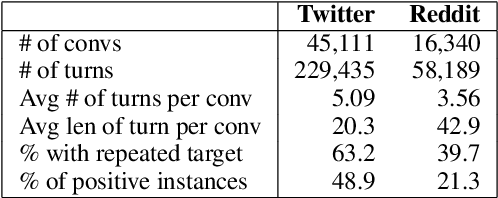
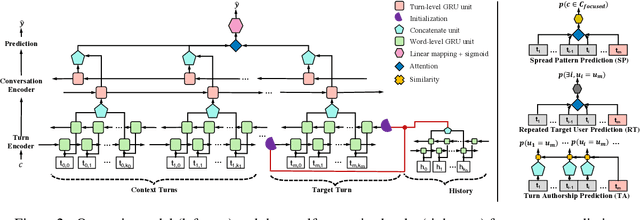
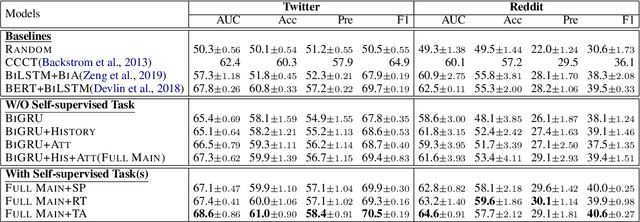
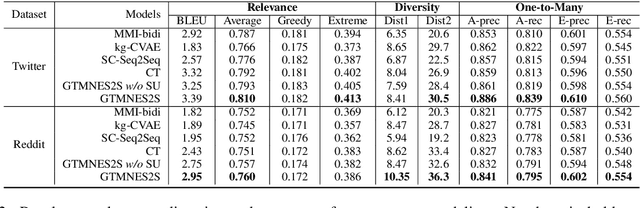
In recent years, world business in online discussions and opinion sharing on social media is booming. Re-entry prediction task is thus proposed to help people keep track of the discussions which they wish to continue. Nevertheless, existing works only focus on exploiting chatting history and context information, and ignore the potential useful learning signals underlying conversation data, such as conversation thread patterns and repeated engagement of target users, which help better understand the behavior of target users in conversations. In this paper, we propose three interesting and well-founded auxiliary tasks, namely, Spread Pattern, Repeated Target user, and Turn Authorship, as the self-supervised signals for re-entry prediction. These auxiliary tasks are trained together with the main task in a multi-task manner. Experimental results on two datasets newly collected from Twitter and Reddit show that our method outperforms the previous state-of-the-arts with fewer parameters and faster convergence. Extensive experiments and analysis show the effectiveness of our proposed models and also point out some key ideas in designing self-supervised tasks.
Neural Rule-Execution Tracking Machine For Transformer-Based Text Generation
Jul 27, 2021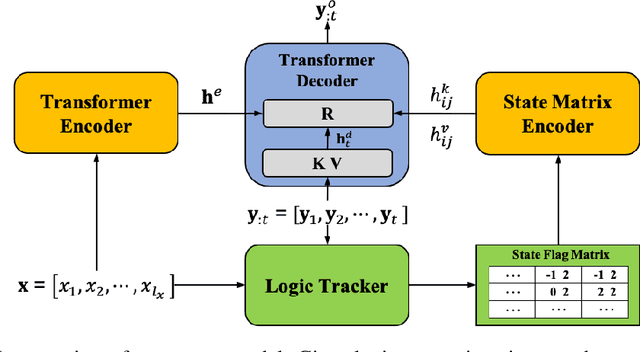

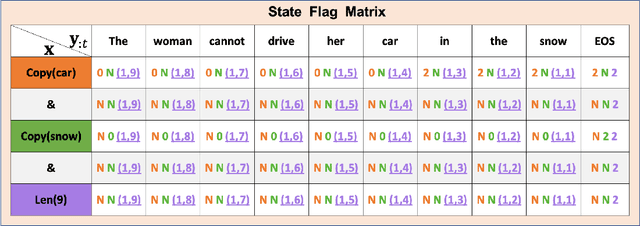
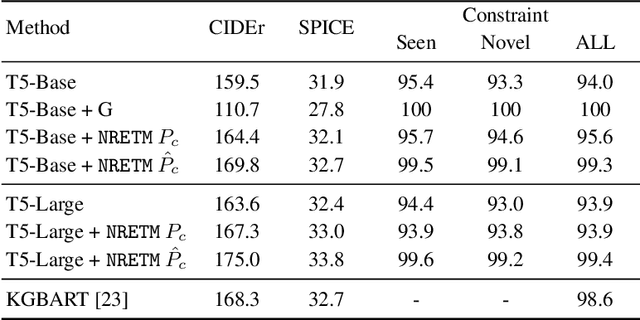
Sequence-to-Sequence (S2S) neural text generation models, especially the pre-trained ones (e.g., BART and T5), have exhibited compelling performance on various natural language generation tasks. However, the black-box nature of these models limits their application in tasks where specific rules (e.g., controllable constraints, prior knowledge) need to be executed. Previous works either design specific model structure (e.g., Copy Mechanism corresponding to the rule "the generated output should include certain words in the source input") or implement specialized inference algorithm (e.g., Constrained Beam Search) to execute particular rules through the text generation. These methods require careful design case-by-case and are difficult to support multiple rules concurrently. In this paper, we propose a novel module named Neural Rule-Execution Tracking Machine that can be equipped into various transformer-based generators to leverage multiple rules simultaneously to guide the neural generation model for superior generation performance in a unified and scalable way. Extensive experimental results on several benchmarks verify the effectiveness of our proposed model in both controllable and general text generation.
Maria: A Visual Experience Powered Conversational Agent
May 27, 2021
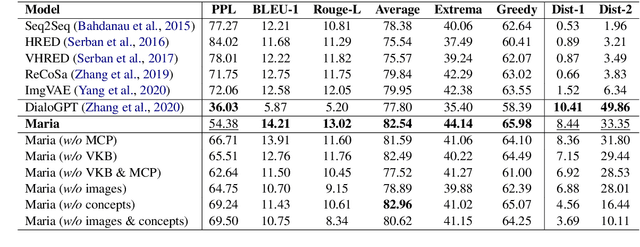
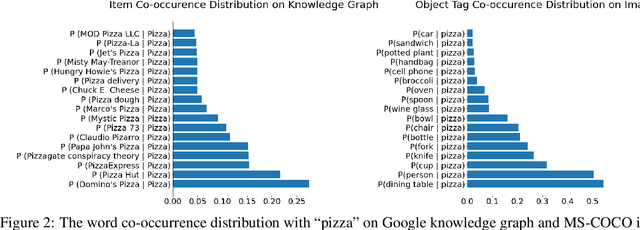
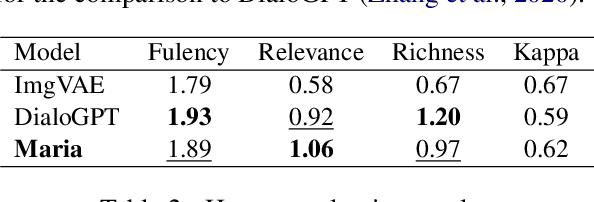
Arguably, the visual perception of conversational agents to the physical world is a key way for them to exhibit the human-like intelligence. Image-grounded conversation is thus proposed to address this challenge. Existing works focus on exploring the multimodal dialog models that ground the conversation on a given image. In this paper, we take a step further to study image-grounded conversation under a fully open-ended setting where no paired dialog and image are assumed available. Specifically, we present Maria, a neural conversation agent powered by the visual world experiences which are retrieved from a large-scale image index. Maria consists of three flexible components, i.e., text-to-image retriever, visual concept detector and visual-knowledge-grounded response generator. The retriever aims to retrieve a correlated image to the dialog from an image index, while the visual concept detector extracts rich visual knowledge from the image. Then, the response generator is grounded on the extracted visual knowledge and dialog context to generate the target response. Extensive experiments demonstrate Maria outperforms previous state-of-the-art methods on automatic metrics and human evaluation, and can generate informative responses that have some visual commonsense of the physical world.
NASE: Learning Knowledge Graph Embedding for Link Prediction via Neural Architecture Search
Aug 18, 2020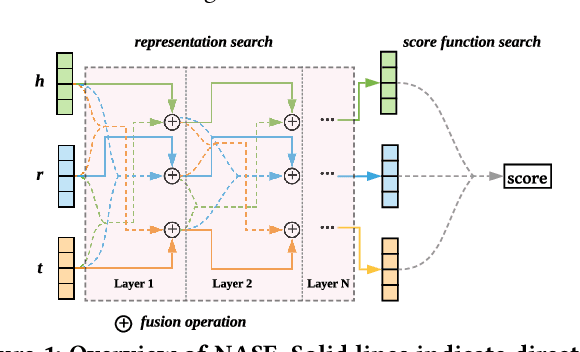
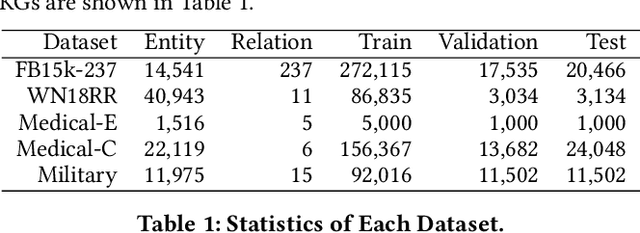
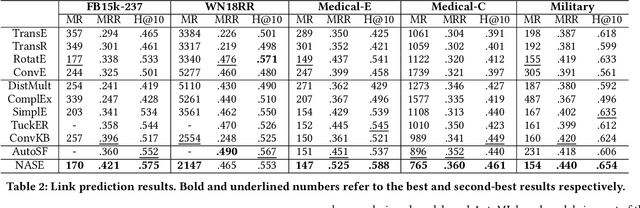

Link prediction is the task of predicting missing connections between entities in the knowledge graph (KG). While various forms of models are proposed for the link prediction task, most of them are designed based on a few known relation patterns in several well-known datasets. Due to the diversity and complexity nature of the real-world KGs, it is inherently difficult to design a model that fits all datasets well. To address this issue, previous work has tried to use Automated Machine Learning (AutoML) to search for the best model for a given dataset. However, their search space is limited only to bilinear model families. In this paper, we propose a novel Neural Architecture Search (NAS) framework for the link prediction task. First, the embeddings of the input triplet are refined by the Representation Search Module. Then, the prediction score is searched within the Score Function Search Module. This framework entails a more general search space, which enables us to take advantage of several mainstream model families, and thus it can potentially achieve better performance. We relax the search space to be continuous so that the architecture can be optimized efficiently using gradient-based search strategies. Experimental results on several benchmark datasets demonstrate the effectiveness of our method compared with several state-of-the-art approaches.
Dance Revolution: Long Sequence Dance Generation with Music via Curriculum Learning
Jun 14, 2020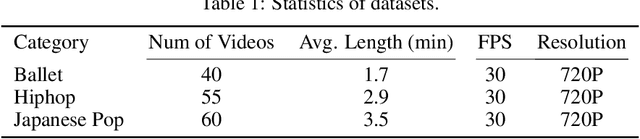
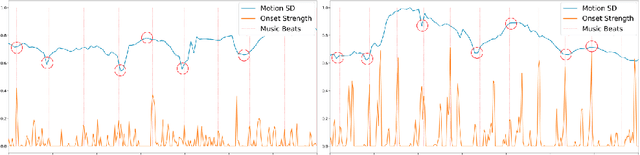

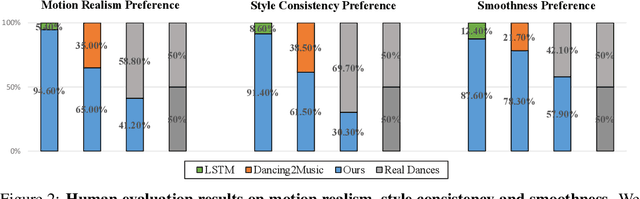
Dancing to music is one of human's innate abilities since ancient times. In artificial intelligence research, however, synthesizing dance movements (complex human motion) from music is a challenging problem, which suffers from the high spatial-temporal complexity in human motion dynamics modeling. Besides, the consistency of dance and music in terms of style, rhythm and beat also needs to be taken into account. Existing works focus on the short-term dance generation with music, e.g. less than 30 seconds. In this paper, we propose a novel seq2seq architecture for long sequence dance generation with music, which consists of a transformer based music encoder and a recurrent structure based dance decoder. By restricting the receptive field of self-attention, our encoder can efficiently process long musical sequences by reducing its quadratic memory requirements to the linear in the sequence length. To further alleviate the error accumulation in human motion synthesis, we introduce a dynamic auto-condition training strategy as a new curriculum learning method to facilitate the long-term dance generation. Extensive experiments demonstrate that our proposed approach significantly outperforms existing methods on both automatic metrics and human evaluation. Additionally, we also make a demo video to exhibit that our approach can generate minute-length dance sequences that are smooth, natural-looking, diverse, style-consistent and beat-matching with the music. The demo video is now available at https://www.youtube.com/watch?v=P6yhfv3vpDI.
Open Domain Dialogue Generation with Latent Images
Apr 04, 2020
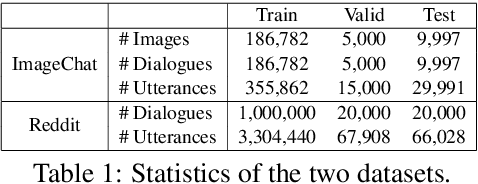
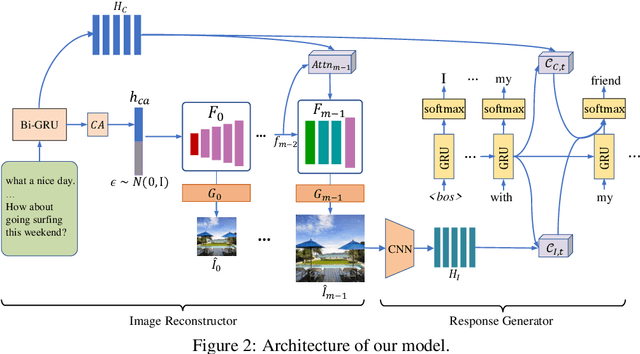
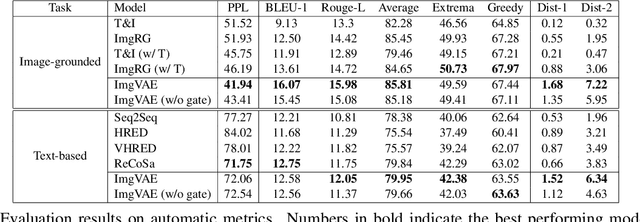
We consider grounding open domain dialogues with images. Existing work assumes that both an image and a textual context are available, but image-grounded dialogues by nature are more difficult to obtain than textual dialogues. Thus, we propose learning a response generation model with both image-grounded dialogues and textual dialogues by assuming that there is a latent variable in a textual dialogue that represents the image, and trying to recover the latent image through text-to-image generation techniques. The likelihood of the two types of dialogues is then formulated by a response generator and an image reconstructor that are learned within a conditional variational auto-encoding framework. Empirical studies are conducted in both image-grounded conversation and text-based conversation. In the first scenario, image-grounded dialogues, especially under a low-resource setting, can be effectively augmented by textual dialogues with latent images; while in the second scenario, latent images can enrich the content of responses and at the same time keep them relevant to contexts.
Neural Response Generation with Meta-Words
Jun 14, 2019
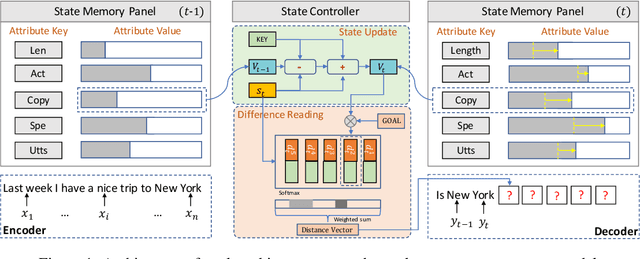
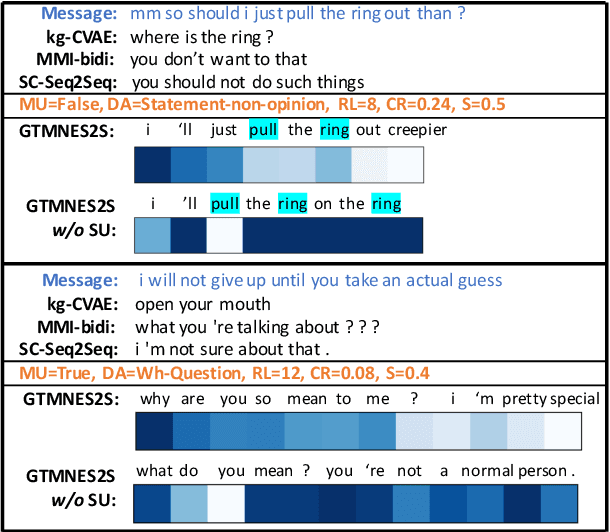
We present open domain response generation with meta-words. A meta-word is a structured record that describes various attributes of a response, and thus allows us to explicitly model the one-to-many relationship within open domain dialogues and perform response generation in an explainable and controllable manner. To incorporate meta-words into generation, we enhance the sequence-to-sequence architecture with a goal tracking memory network that formalizes meta-word expression as a goal and manages the generation process to achieve the goal with a state memory panel and a state controller. Experimental results on two large-scale datasets indicate that our model can significantly outperform several state-of-the-art generation models in terms of response relevance, response diversity, accuracy of one-to-many modeling, accuracy of meta-word expression, and human evaluation.
Playing 20 Question Game with Policy-Based Reinforcement Learning
Aug 26, 2018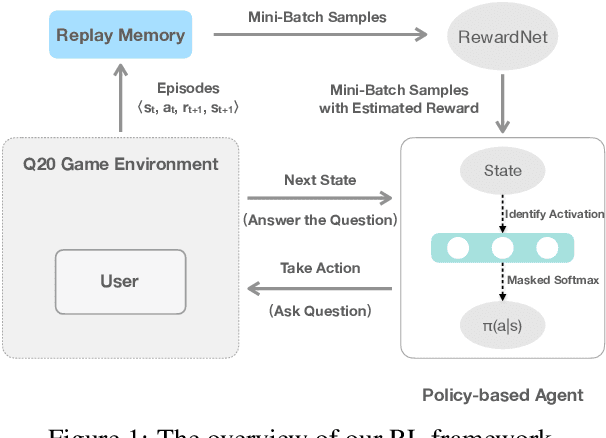

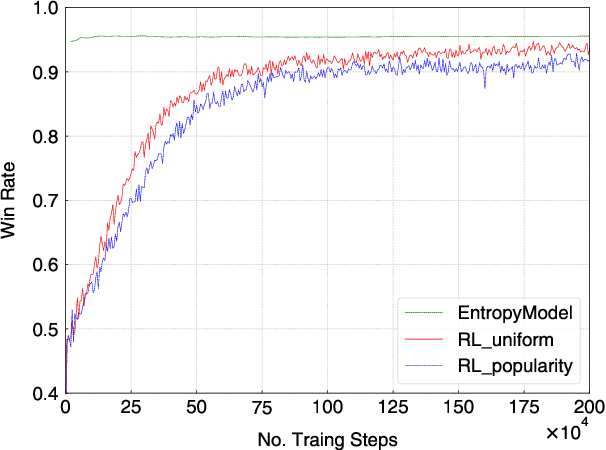
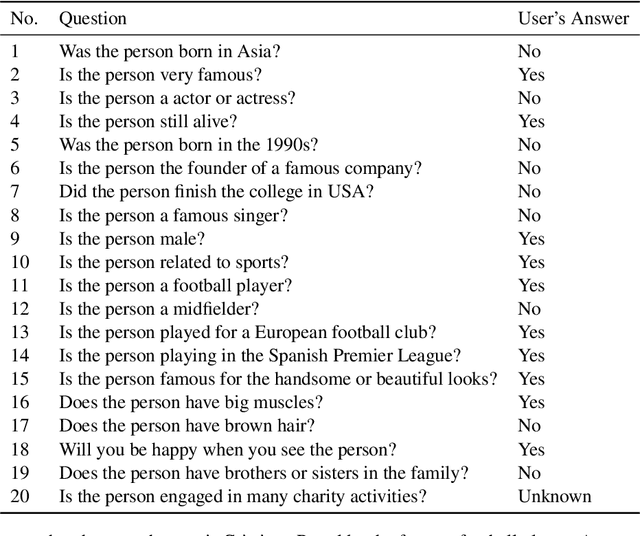
The 20 Questions (Q20) game is a well known game which encourages deductive reasoning and creativity. In the game, the answerer first thinks of an object such as a famous person or a kind of animal. Then the questioner tries to guess the object by asking 20 questions. In a Q20 game system, the user is considered as the answerer while the system itself acts as the questioner which requires a good strategy of question selection to figure out the correct object and win the game. However, the optimal policy of question selection is hard to be derived due to the complexity and volatility of the game environment. In this paper, we propose a novel policy-based Reinforcement Learning (RL) method, which enables the questioner agent to learn the optimal policy of question selection through continuous interactions with users. To facilitate training, we also propose to use a reward network to estimate the more informative reward. Compared to previous methods, our RL method is robust to noisy answers and does not rely on the Knowledge Base of objects. Experimental results show that our RL method clearly outperforms an entropy-based engineering system and has competitive performance in a noisy-free simulation environment.