 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-guided machine learning model with soil moisture for corn yield prediction under drought conditions
Mar 20, 2025Remote sensing (RS) techniques, by enabling non-contact acquisition of extensive ground observations, have become a valuable tool for corn yield prediction. Traditional process-based (PB) models are limited by fixed input features and struggle to incorporate large volumes of RS data. In contrast, machine learning (ML) models are often criticized for being ``black boxes'' with limited interpretability. To address these limitations, we used Knowledge-Guided Machine Learning (KGML), which combined the strengths of both approaches and fully used RS data. However, previous KGML methods overlooked the crucial role of soil moisture in plant growth. To bridge this gap, we proposed the Knowledge-Guided Machine Learning with Soil Moisture (KGML-SM) framework, using soil moisture as an intermediate variable to emphasize its key role in plant development. Additionally, based on the prior knowledge that the model may overestimate under drought conditions, we designed a drought-aware loss function that penalizes predicted yield in drought-affected areas. Our experiments showed that the KGML-SM model outperformed other ML models. Finally, we explored the relationships between drought, soil moisture, and corn yield prediction, assessing the importance of various features and analyzing how soil moisture impacts corn yield predictions across different regions and time periods.
Multi-UAV Behavior-based Formation with Static and Dynamic Obstacles Avoidance via Reinforcement Learning
Oct 24, 2024



Formation control of multiple Unmanned Aerial Vehicles (UAVs) is vital for practical applications. This paper tackles the task of behavior-based UAV formation while avoiding static and dynamic obstacles during directed flight. We present a two-stage reinforcement learning (RL) training pipeline to tackle the challenge of multi-objective optimization, large exploration spaces, and the sim-to-real gap. The first stage searches in a simplified scenario for a linear utility function that balances all task objectives simultaneously, whereas the second stage applies the utility function in complex scenarios, utilizing curriculum learning to navigate large exploration spaces. Additionally, we apply an attention-based observation encoder to enhance formation maintenance and manage varying obstacle quantity. Experiments in simulation and real world demonstrate that our method outperforms planning-based and RL-based baselines regarding collision-free rate and formation maintenance in scenarios with static, dynamic, and mixed obstacles.
Spatiotemporal Transformer for Imputing Sparse Data: A Deep Learning Approach
Dec 01, 2023



Effective management of environmental resources and agricultural sustainability heavily depends on accurate soil moisture data. However, datasets like the SMAP/Sentinel-1 soil moisture product often contain missing values across their spatiotemporal grid, which poses a significant challenge. This paper introduces a novel Spatiotemporal Transformer model (ST-Transformer) specifically designed to address the issue of missing values in sparse spatiotemporal datasets, particularly focusing on soil moisture data. The ST-Transformer employs multiple spatiotemporal attention layers to capture the complex spatiotemporal correlations in the data and can integrate additional spatiotemporal covariates during the imputation process, thereby enhancing its accuracy. The model is trained using a self-supervised approach, enabling it to autonomously predict missing values from observed data points. Our model's efficacy is demonstrated through its application to the SMAP 1km soil moisture data over a 36 x 36 km grid in Texas. It showcases superior accuracy compared to well-known imputation methods. Additionally, our simulation studies on other datasets highlight the model's broader applicability in various spatiotemporal imputation tasks.
Deep vs. Deep Bayesian: Reinforcement Learning on a Multi-Robot Competitive Experiment
Jul 21, 2020
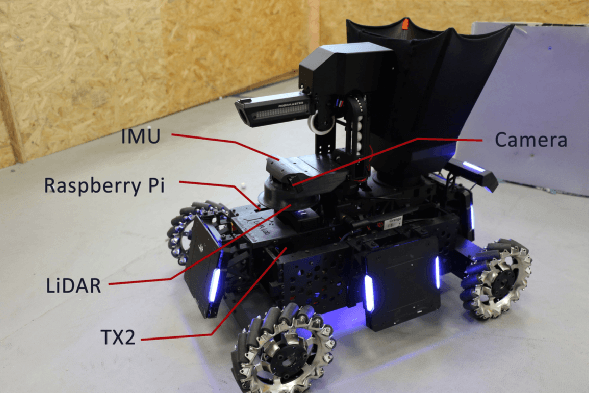
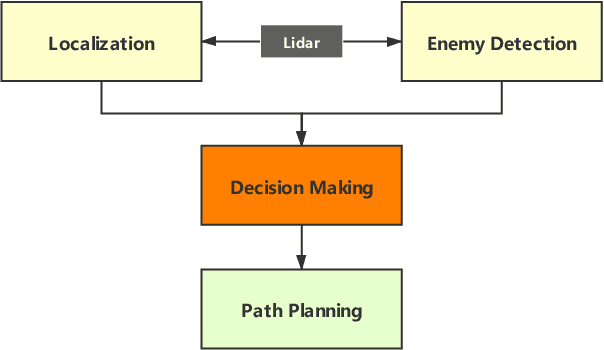
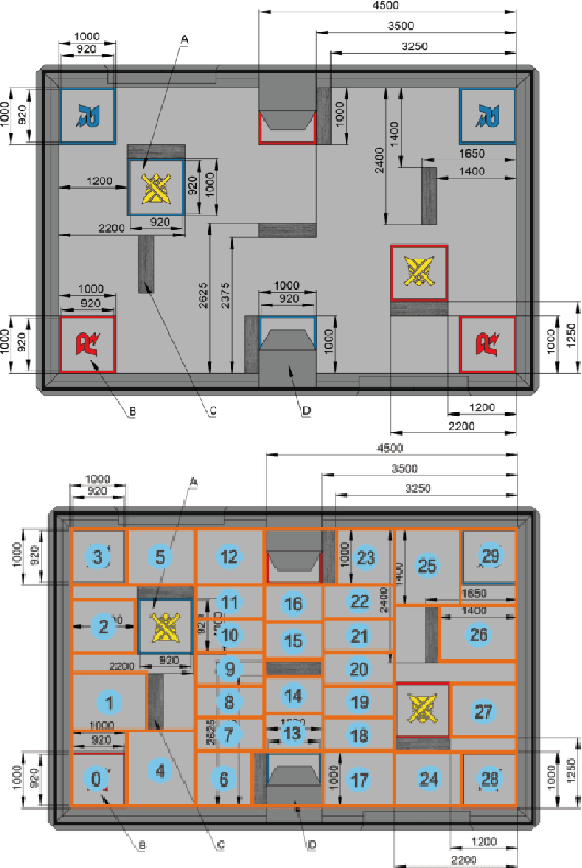
Deep Reinforcement Learning (RL) experiments are commonly performed in simulated environment, due to the tremendous training sample demand from deep neural networks. However, model-based Deep Bayesian RL, such as Deep PILCO, allows a robot to learn good policies within few trials in the real world. Although Deep PILCO has been applied on many single-robot tasks, in here we propose, for the first time, an application of Deep PILCO on a multi-robot confrontation game, and compare the algorithm with a model-free Deep RL algorithm, Deep Q-Learning. Our experiments show that Deep PILCO significantly outperforms Deep Q-Learning in learning efficiency and scalability. We conclude that sample-efficient Deep Bayesian learning algorithms have great prospects on competitive games where the agent aims to win the opponents in the real world, as opposed to simulated applications.