 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongzhi Yin
Manipulating Visually-aware Federated Recommender Systems and Its Countermeasures
May 14, 2023
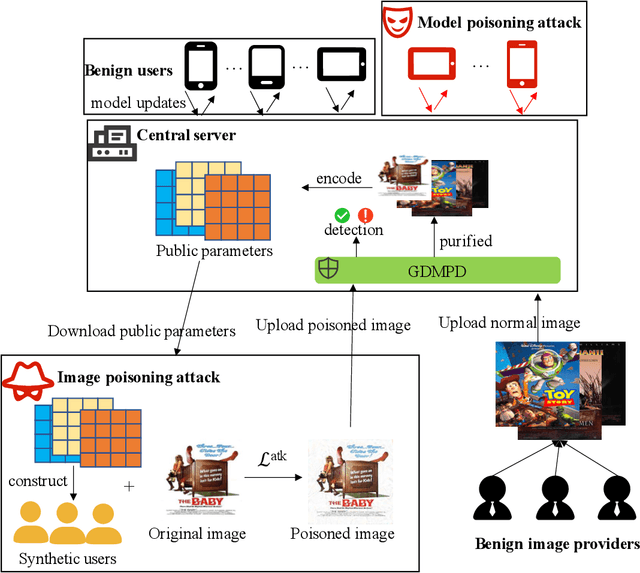

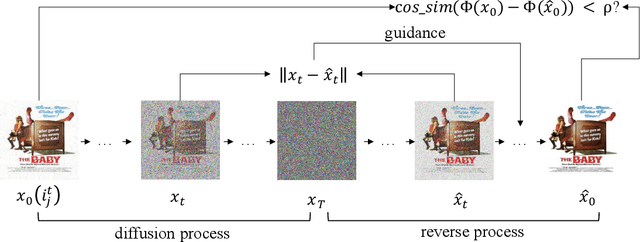

Federated recommender systems (FedRecs) have been widely explored recently due to their ability to protect user data privacy. In FedRecs, a central server collaboratively learns recommendation models by sharing model public parameters with clients, thereby offering a privacy-preserving solution. Unfortunately, the exposure of model parameters leaves a backdoor for adversaries to manipulate FedRecs. Existing works about FedRec security already reveal that items can easily be promoted by malicious users via model poisoning attacks, but all of them mainly focus on FedRecs with only collaborative information (i.e., user-item interactions). We argue that these attacks are effective because of the data sparsity of collaborative signals. In practice, auxiliary information, such as products' visual descriptions, is used to alleviate collaborative filtering data's sparsity. Therefore, when incorporating visual information in FedRecs, all existing model poisoning attacks' effectiveness becomes questionable. In this paper, we conduct extensive experiments to verify that incorporating visual information can beat existing state-of-the-art attacks in reasonable settings. However, since visual information is usually provided by external sources, simply including it will create new security problems. Specifically, we propose a new kind of poisoning attack for visually-aware FedRecs, namely image poisoning attacks, where adversaries can gradually modify the uploaded image to manipulate item ranks during FedRecs' training process. Furthermore, we reveal that the potential collaboration between image poisoning attacks and model poisoning attacks will make visually-aware FedRecs more vulnerable to being manipulated. To safely use visual information, we employ a diffusion model in visually-aware FedRecs to purify each uploaded image and detect the adversarial images.
KGA: A General Machine Unlearning Framework Based on Knowledge Gap Alignment
May 11, 2023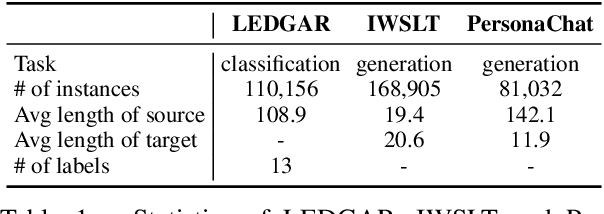
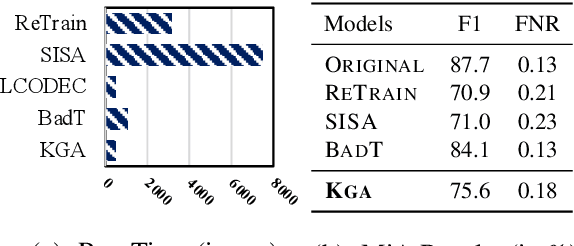
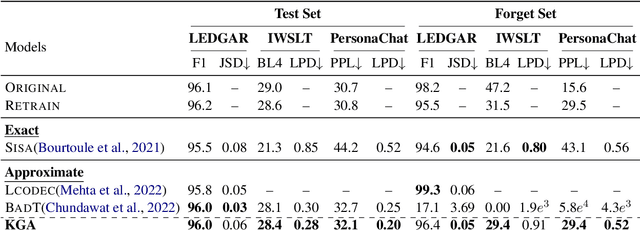
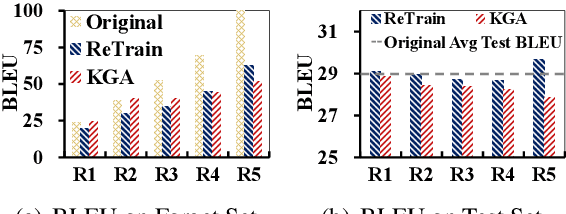
Recent legislation of the "right to be forgotten" has led to the interest in machine unlearning, where the learned models are endowed with the function to forget information about specific training instances as if they have never existed in the training set. Previous work mainly focuses on computer vision scenarios and largely ignores the essentials of unlearning in NLP field, where text data contains more explicit and sensitive personal information than images. In this paper, we propose a general unlearning framework called KGA to induce forgetfulness. Different from previous work that tries to recover gradients or forces models to perform close to one specific distribution, KGA maintains distribution differences (i.e., knowledge gap). This relaxes the distribution assumption. Furthermore, we first apply the unlearning method to various NLP tasks (i.e., classification, translation, response generation) and propose several unlearning evaluation metrics with pertinence. Experiments on large-scale datasets show that KGA yields comprehensive improvements over baselines, where extensive analyses further validate the effectiveness of KGA and provide insight into unlearning for NLP tasks.
Explicit Knowledge Graph Reasoning for Conversational Recommendation
May 01, 2023
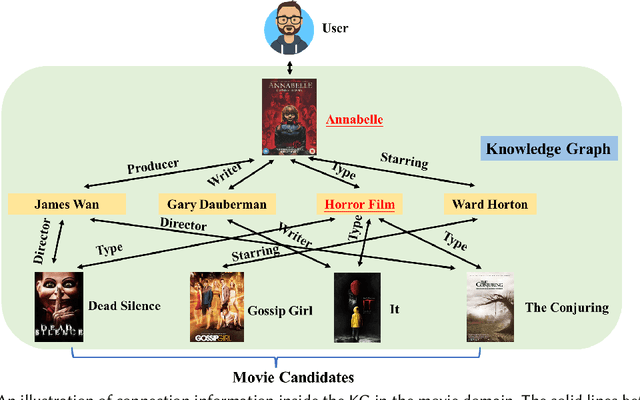
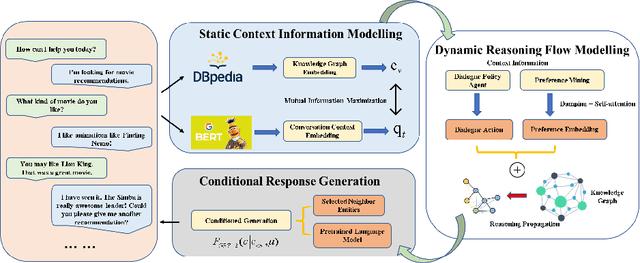
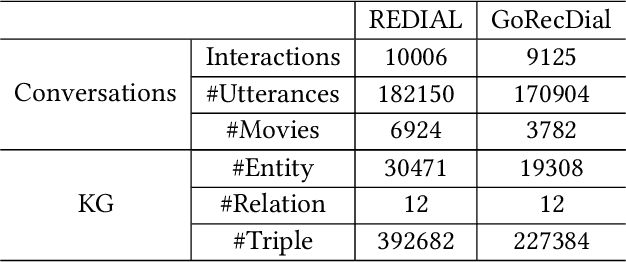
Traditional recommender systems estimate user preference on items purely based on historical interaction records, thus failing to capture fine-grained yet dynamic user interests and letting users receive recommendation only passively. Recent conversational recommender systems (CRSs) tackle those limitations by enabling recommender systems to interact with the user to obtain her/his current preference through a sequence of clarifying questions. Despite the progress achieved in CRSs, existing solutions are far from satisfaction in the following two aspects: 1) current CRSs usually require each user to answer a quantity of clarifying questions before reaching the final recommendation, which harms the user experience; 2) there is a semantic gap between the learned representations of explicitly mentioned attributes and items. To address these drawbacks, we introduce the knowledge graph (KG) as the auxiliary information for comprehending and reasoning a user's preference, and propose a new CRS framework, namely Knowledge Enhanced Conversational Reasoning (KECR) system. As a user can reflect her/his preference via both attribute- and item-level expressions, KECR closes the semantic gap between two levels by embedding the structured knowledge in the KG. Meanwhile, KECR utilizes the connectivity within the KG to conduct explicit reasoning of the user demand, making the model less dependent on the user's feedback to clarifying questions. KECR can find a prominent reasoning chain to make the recommendation explainable and more rationale, as well as smoothen the conversation process, leading to better user experience and conversational recommendation accuracy. Extensive experiments on two real-world datasets demonstrate our approach's superiority over state-of-the-art baselines in both automatic evaluations and human judgments.
Imbalanced Node Classification Beyond Homophilic Assumption
Apr 28, 2023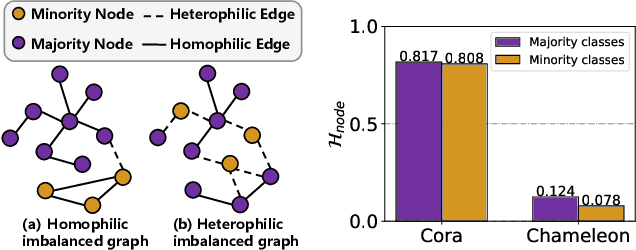
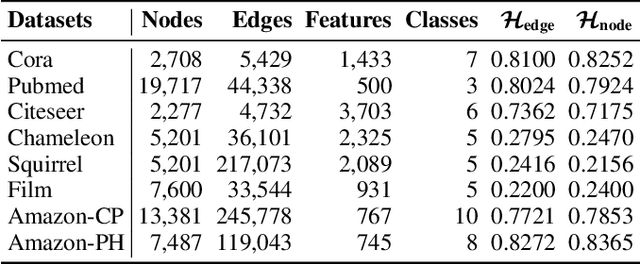
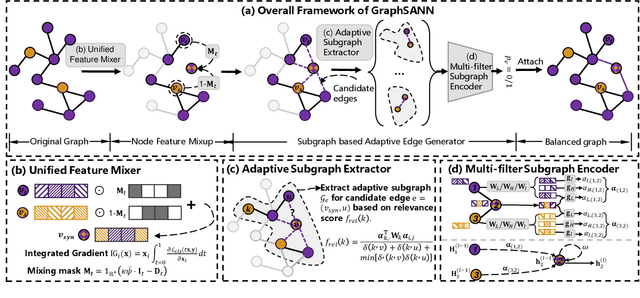
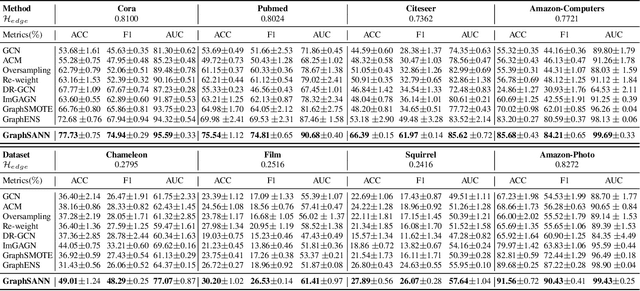
Imbalanced node classification widely exists in real-world networks where graph neural networks (GNNs) are usually highly inclined to majority classes and suffer from severe performance degradation on classifying minority class nodes. Various imbalanced node classification methods have been proposed recently which construct synthetic nodes and edges w.r.t. minority classes to balance the label and topology distribution. However, they are all based on the homophilic assumption that nodes of the same label tend to connect despite the wide existence of heterophilic edges in real-world graphs. Thus, they uniformly aggregate features from both homophilic and heterophilic neighbors and rely on feature similarity to generate synthetic edges, which cannot be applied to imbalanced graphs in high heterophily. To address this problem, we propose a novel GraphSANN for imbalanced node classification on both homophilic and heterophilic graphs. Firstly, we propose a unified feature mixer to generate synthetic nodes with both homophilic and heterophilic interpolation in a unified way. Next, by randomly sampling edges between synthetic nodes and existing nodes as candidate edges, we design an adaptive subgraph extractor to adaptively extract the contextual subgraphs of candidate edges with flexible ranges. Finally, we develop a multi-filter subgraph encoder that constructs different filter channels to discriminatively aggregate neighbor's information along the homophilic and heterophilic edges. Extensive experiments on eight datasets demonstrate the superiority of our model for imbalanced node classification on both homophilic and heterophilic graphs.
Continuous Input Embedding Size Search For Recommender Systems
Apr 25, 2023
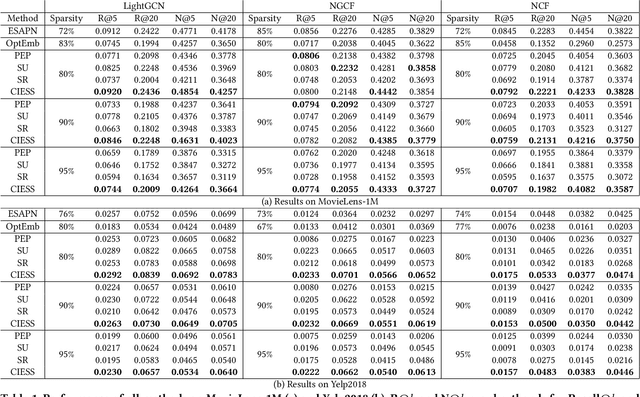
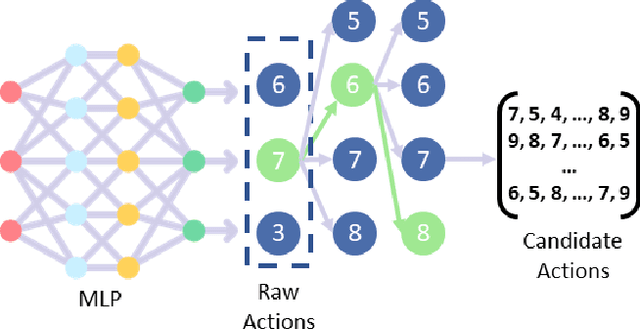
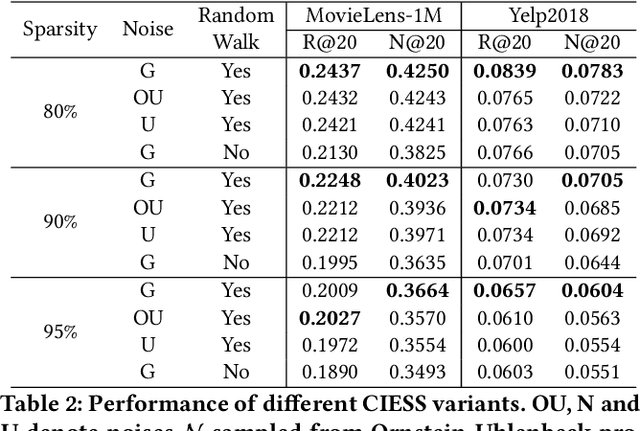
Latent factor models are the most popular backbones for today's recommender systems owing to their prominent performance. Latent factor models represent users and items as real-valued embedding vectors for pairwise similarity computation, and all embeddings are traditionally restricted to a uniform size that is relatively large (e.g., 256-dimensional). With the exponentially expanding user base and item catalog in contemporary e-commerce, this design is admittedly becoming memory-inefficient. To facilitate lightweight recommendation, reinforcement learning (RL) has recently opened up opportunities for identifying varying embedding sizes for different users/items. However, challenged by search efficiency and learning an optimal RL policy, existing RL-based methods are restricted to highly discrete, predefined embedding size choices. This leads to a largely overlooked potential of introducing finer granularity into embedding sizes to obtain better recommendation effectiveness under a given memory budget. In this paper, we propose continuous input embedding size search (CIESS), a novel RL-based method that operates on a continuous search space with arbitrary embedding sizes to choose from. In CIESS, we further present an innovative random walk-based exploration strategy to allow the RL policy to efficiently explore more candidate embedding sizes and converge to a better decision. CIESS is also model-agnostic and hence generalizable to a variety of latent factor RSs, whilst experiments on two real-world datasets have shown state-of-the-art performance of CIESS under different memory budgets when paired with three popular recommendation models.
Joint Semantic and Structural Representation Learning for Enhancing User Preference Modelling
Apr 24, 2023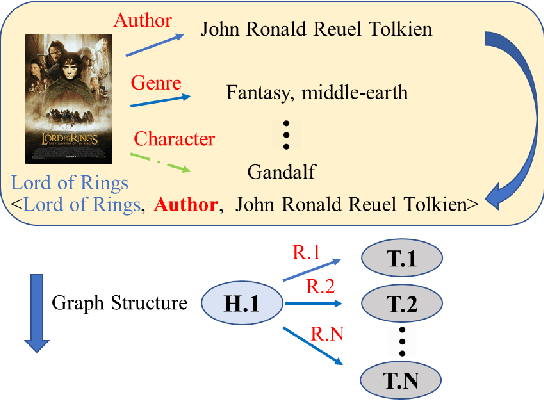
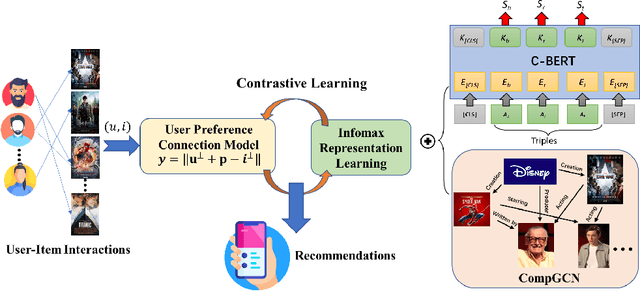
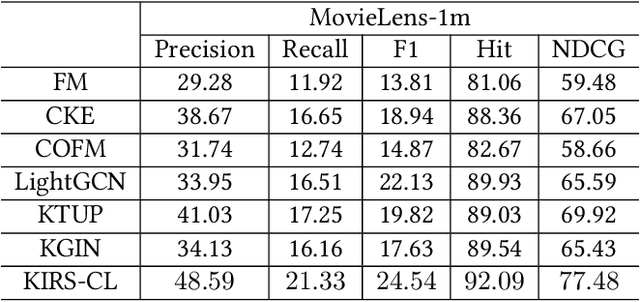
Knowledge graphs (KGs) have become important auxiliary information for helping recommender systems obtain a good understanding of user preferences. Despite recent advances in KG-based recommender systems, existing methods are prone to suboptimal performance due to the following two drawbacks: 1) current KG-based methods over-emphasize the heterogeneous structural information within a KG and overlook the underlying semantics of its connections, hindering the recommender from distilling the explicit user preferences; and 2) the inherent incompleteness of a KG (i.e., missing facts, relations and entities) will deteriorate the information extracted from KG and weaken the representation learning of recommender systems. To tackle the aforementioned problems, we investigate the potential of jointly incorporating the structural and semantic information within a KG to model user preferences in finer granularity. A new framework for KG-based recommender systems, namely \textit{K}nowledge \textit{I}nfomax \textit{R}ecommender \textit{S}ystem with \textit{C}ontrastive \textit{L}earning (KIRS-CL) is proposed in this paper. Distinct from previous KG-based approaches, KIRS-CL utilizes structural and connectivity information with high-quality item embeddings learned by encoding KG triples with a pre-trained language model. These well-trained entity representations enable KIRS-CL to find the item to recommend via the preference connection between the user and the item. Additionally, to improve the generalizability of our framework, we introduce a contrastive warm-up learning strategy, making it capable of dealing with both warm- and cold-start recommendation scenarios. Extensive experiments on two real-world datasets demonstrate remarkable improvements over state-of-the-art baselines.
Manipulating Federated Recommender Systems: Poisoning with Synthetic Users and Its Countermeasures
Apr 15, 2023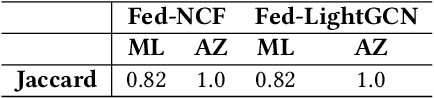
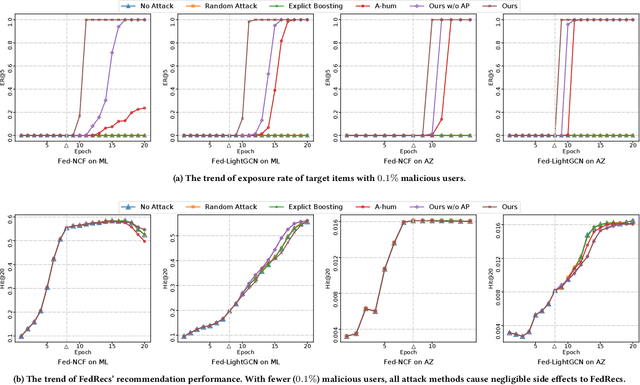
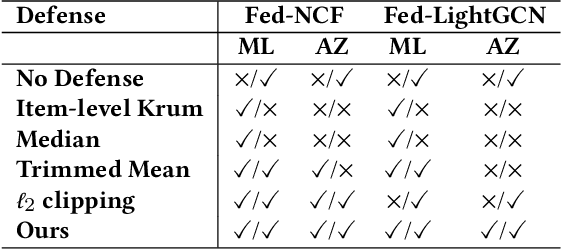
Federated Recommender Systems (FedRecs) are considered privacy-preserving techniques to collaboratively learn a recommendation model without sharing user data. Since all participants can directly influence the systems by uploading gradients, FedRecs are vulnerable to poisoning attacks of malicious clients. However, most existing poisoning attacks on FedRecs are either based on some prior knowledge or with less effectiveness. To reveal the real vulnerability of FedRecs, in this paper, we present a new poisoning attack method to manipulate target items' ranks and exposure rates effectively in the top-$K$ recommendation without relying on any prior knowledge. Specifically, our attack manipulates target items' exposure rate by a group of synthetic malicious users who upload poisoned gradients considering target items' alternative products. We conduct extensive experiments with two widely used FedRecs (Fed-NCF and Fed-LightGCN) on two real-world recommendation datasets. The experimental results show that our attack can significantly improve the exposure rate of unpopular target items with extremely fewer malicious users and fewer global epochs than state-of-the-art attacks. In addition to disclosing the security hole, we design a novel countermeasure for poisoning attacks on FedRecs. Specifically, we propose a hierarchical gradient clipping with sparsified updating to defend against existing poisoning attacks. The empirical results demonstrate that the proposed defending mechanism improves the robustness of FedRecs.
Automated Prompting for Non-overlapping Cross-domain Sequential Recommendation
Apr 09, 2023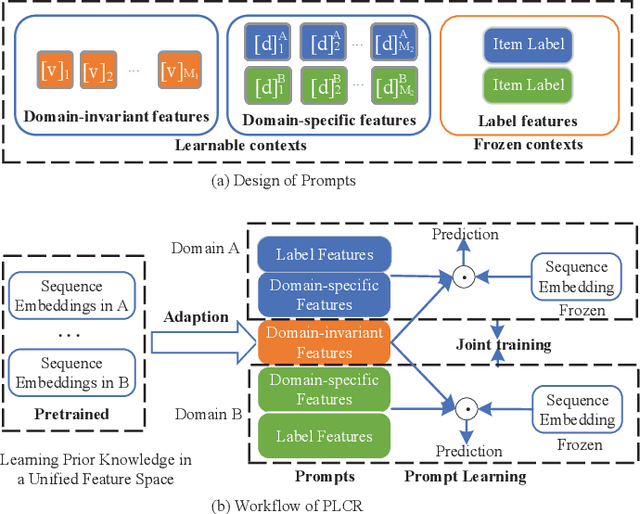
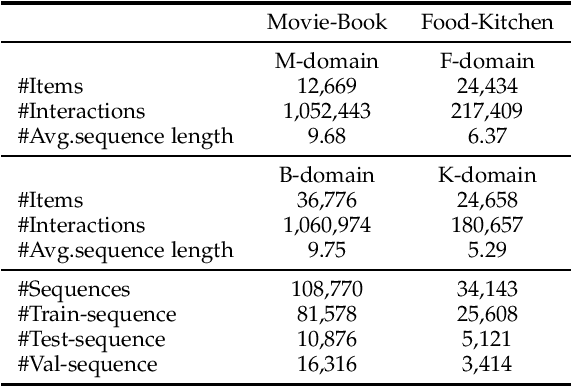
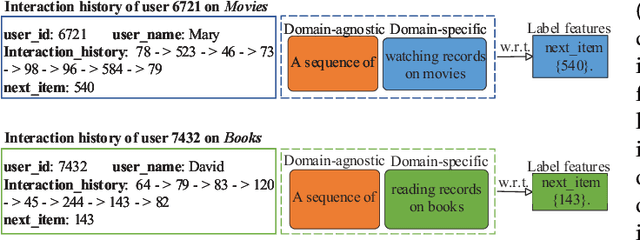
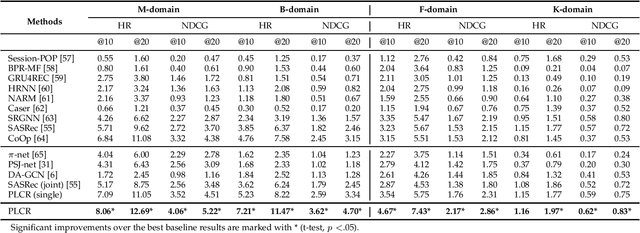
Cross-domain Recommendation (CR) has been extensively studied in recent years to alleviate the data sparsity issue in recommender systems by utilizing different domain information. In this work, we focus on the more general Non-overlapping Cross-domain Sequential Recommendation (NCSR) scenario. NCSR is challenging because there are no overlapped entities (e.g., users and items) between domains, and there is only users' implicit feedback and no content information. Previous CR methods cannot solve NCSR well, since (1) they either need extra content to align domains or need explicit domain alignment constraints to reduce the domain discrepancy from domain-invariant features, (2) they pay more attention to users' explicit feedback (i.e., users' rating data) and cannot well capture their sequential interaction patterns, (3) they usually do a single-target cross-domain recommendation task and seldom investigate the dual-target ones. Considering the above challenges, we propose Prompt Learning-based Cross-domain Recommender (PLCR), an automated prompting-based recommendation framework for the NCSR task. Specifically, to address the challenge (1), PLCR resorts to learning domain-invariant and domain-specific representations via its prompt learning component, where the domain alignment constraint is discarded. For challenges (2) and (3), PLCR introduces a pre-trained sequence encoder to learn users' sequential interaction patterns, and conducts a dual-learning target with a separation constraint to enhance recommendations in both domains. Our empirical study on two sub-collections of Amazon demonstrates the advance of PLCR compared with some related SOTA methods.
DREAM: Adaptive Reinforcement Learning based on Attention Mechanism for Temporal Knowledge Graph Reasoning
Apr 08, 2023
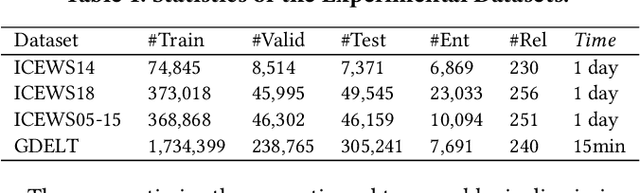
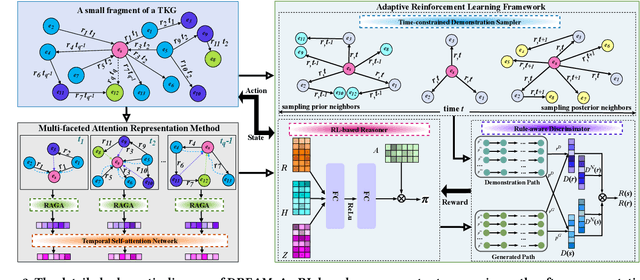
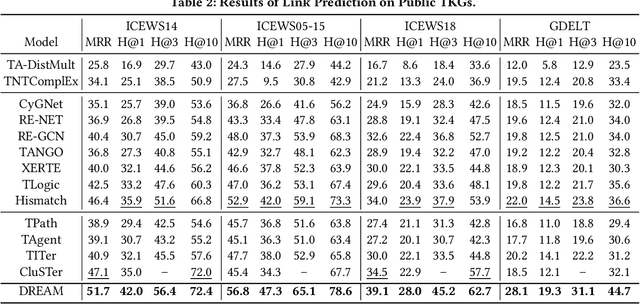
Temporal knowledge graphs (TKGs) model the temporal evolution of events and have recently attracted increasing attention. Since TKGs are intrinsically incomplete, it is necessary to reason out missing elements. Although existing TKG reasoning methods have the ability to predict missing future events, they fail to generate explicit reasoning paths and lack explainability. As reinforcement learning (RL) for multi-hop reasoning on traditional knowledge graphs starts showing superior explainability and performance in recent advances, it has opened up opportunities for exploring RL techniques on TKG reasoning. However, the performance of RL-based TKG reasoning methods is limited due to: (1) lack of ability to capture temporal evolution and semantic dependence jointly; (2) excessive reliance on manually designed rewards. To overcome these challenges, we propose an adaptive reinforcement learning model based on attention mechanism (DREAM) to predict missing elements in the future. Specifically, the model contains two components: (1) a multi-faceted attention representation learning method that captures semantic dependence and temporal evolution jointly; (2) an adaptive RL framework that conducts multi-hop reasoning by adaptively learning the reward functions. Experimental results demonstrate DREAM outperforms state-of-the-art models on public dataset