 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow What You Know: Metacognitive Entropy Calibration for Verifiable RL Reasoning
Feb 26, 2026Large reasoning models (LRMs) have emerged as a powerful paradigm for solving complex real-world tasks. In practice, these models are predominantly trained via Reinforcement Learning with Verifiable Rewards (RLVR), yet most existing outcome-only RLVR pipelines rely almost exclusively on a binary correctness signal and largely ignore the model's intrinsic uncertainty. We term this discrepancy the uncertainty-reward mismatch, under which high- and low-uncertainty solutions are treated equivalently, preventing the policy from "Know What You Know" and impeding the shift from optimizing for correct answers to optimizing effective reasoning paths. This limitation is especially critical in reasoning-centric tasks such as mathematics and question answering, where performance hinges on the quality of the model's internal reasoning process rather than mere memorization of final answers. To address this, we propose EGPO, a metacognitive entropy calibration framework that explicitly integrates intrinsic uncertainty into RLVR for enhancing LRMs. EGPO estimates per-sample uncertainty using a zero-overhead entropy proxy derived from token-level likelihoods and aligns it with extrinsic correctness through an asymmetric calibration mechanism that preserves correct reasoning while selectively regulating overconfident failures, thereby enabling stable and uncertainty-aware policy optimization. Moreover, EGPO recovers informative learning signals from otherwise degenerate group-based rollouts without modifying the verifier or reward definition. Extensive experiments across multiple benchmarks demonstrate that the proposed EGPO leads to substantial and consistent improvements in reasoning performance, establishing a principled path for advancing LRMs through metacognitive entropy calibration.
MagicAgent: Towards Generalized Agent Planning
Feb 22, 2026The evolution of Large Language Models (LLMs) from passive text processors to autonomous agents has established planning as a core component of modern intelligence. However, achieving generalized planning remains elusive, not only by the scarcity of high-quality interaction data but also by inherent conflicts across heterogeneous planning tasks. These challenges result in models that excel at isolated tasks yet struggle to generalize, while existing multi-task training attempts suffer from gradient interference. In this paper, we present \textbf{MagicAgent}, a series of foundation models specifically designed for generalized agent planning. We introduce a lightweight and scalable synthetic data framework that generates high-quality trajectories across diverse planning tasks, including hierarchical task decomposition, tool-augmented planning, multi-constraint scheduling, procedural logic orchestration, and long-horizon tool execution. To mitigate training conflicts, we propose a two-stage training paradigm comprising supervised fine-tuning followed by multi-objective reinforcement learning over both static datasets and dynamic environments. Empirical results demonstrate that MagicAgent-32B and MagicAgent-30B-A3B deliver superior performance, achieving accuracies of $75.1\%$ on Worfbench, $55.9\%$ on NaturalPlan, $57.5\%$ on $τ^2$-Bench, $86.9\%$ on BFCL-v3, and $81.2\%$ on ACEBench, as well as strong results on our in-house MagicEval benchmarks. These results substantially outperform existing sub-100B models and even surpass leading closed-source models.
Multi-turn Response Selection with Commonsense-enhanced Language Models
Jul 26, 2024



As a branch of advanced artificial intelligence, dialogue systems are prospering. Multi-turn response selection is a general research problem in dialogue systems. With the assistance of background information and pre-trained language models, the performance of state-of-the-art methods on this problem gains impressive improvement. However, existing studies neglect the importance of external commonsense knowledge. Hence, we design a Siamese network where a pre-trained Language model merges with a Graph neural network (SinLG). SinLG takes advantage of Pre-trained Language Models (PLMs) to catch the word correlations in the context and response candidates and utilizes a Graph Neural Network (GNN) to reason helpful common sense from an external knowledge graph. The GNN aims to assist the PLM in fine-tuning, and arousing its related memories to attain better performance. Specifically, we first extract related concepts as nodes from an external knowledge graph to construct a subgraph with the context response pair as a super node for each sample. Next, we learn two representations for the context response pair via both the PLM and GNN. A similarity loss between the two representations is utilized to transfer the commonsense knowledge from the GNN to the PLM. Then only the PLM is used to infer online so that efficiency can be guaranteed. Finally, we conduct extensive experiments on two variants of the PERSONA-CHAT dataset, which proves that our solution can not only improve the performance of the PLM but also achieve an efficient inference.
Explicit Knowledge Graph Reasoning for Conversational Recommendation
May 01, 2023


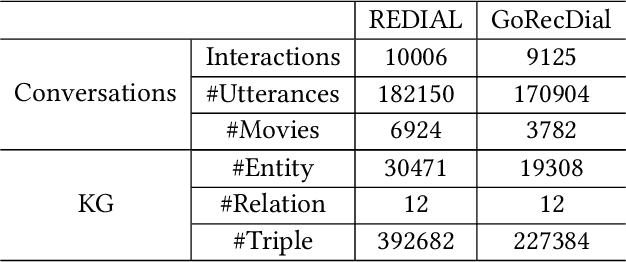
Traditional recommender systems estimate user preference on items purely based on historical interaction records, thus failing to capture fine-grained yet dynamic user interests and letting users receive recommendation only passively. Recent conversational recommender systems (CRSs) tackle those limitations by enabling recommender systems to interact with the user to obtain her/his current preference through a sequence of clarifying questions. Despite the progress achieved in CRSs, existing solutions are far from satisfaction in the following two aspects: 1) current CRSs usually require each user to answer a quantity of clarifying questions before reaching the final recommendation, which harms the user experience; 2) there is a semantic gap between the learned representations of explicitly mentioned attributes and items. To address these drawbacks, we introduce the knowledge graph (KG) as the auxiliary information for comprehending and reasoning a user's preference, and propose a new CRS framework, namely Knowledge Enhanced Conversational Reasoning (KECR) system. As a user can reflect her/his preference via both attribute- and item-level expressions, KECR closes the semantic gap between two levels by embedding the structured knowledge in the KG. Meanwhile, KECR utilizes the connectivity within the KG to conduct explicit reasoning of the user demand, making the model less dependent on the user's feedback to clarifying questions. KECR can find a prominent reasoning chain to make the recommendation explainable and more rationale, as well as smoothen the conversation process, leading to better user experience and conversational recommendation accuracy. Extensive experiments on two real-world datasets demonstrate our approach's superiority over state-of-the-art baselines in both automatic evaluations and human judgments.
Joint Semantic and Structural Representation Learning for Enhancing User Preference Modelling
Apr 24, 2023Knowledge graphs (KGs) have become important auxiliary information for helping recommender systems obtain a good understanding of user preferences. Despite recent advances in KG-based recommender systems, existing methods are prone to suboptimal performance due to the following two drawbacks: 1) current KG-based methods over-emphasize the heterogeneous structural information within a KG and overlook the underlying semantics of its connections, hindering the recommender from distilling the explicit user preferences; and 2) the inherent incompleteness of a KG (i.e., missing facts, relations and entities) will deteriorate the information extracted from KG and weaken the representation learning of recommender systems. To tackle the aforementioned problems, we investigate the potential of jointly incorporating the structural and semantic information within a KG to model user preferences in finer granularity. A new framework for KG-based recommender systems, namely \textit{K}nowledge \textit{I}nfomax \textit{R}ecommender \textit{S}ystem with \textit{C}ontrastive \textit{L}earning (KIRS-CL) is proposed in this paper. Distinct from previous KG-based approaches, KIRS-CL utilizes structural and connectivity information with high-quality item embeddings learned by encoding KG triples with a pre-trained language model. These well-trained entity representations enable KIRS-CL to find the item to recommend via the preference connection between the user and the item. Additionally, to improve the generalizability of our framework, we introduce a contrastive warm-up learning strategy, making it capable of dealing with both warm- and cold-start recommendation scenarios. Extensive experiments on two real-world datasets demonstrate remarkable improvements over state-of-the-art baselines.
Learning to Ask Appropriate Questions in Conversational Recommendation
May 11, 2021
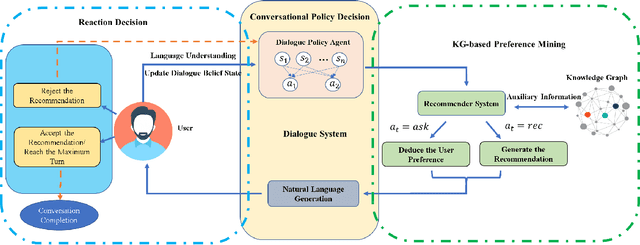
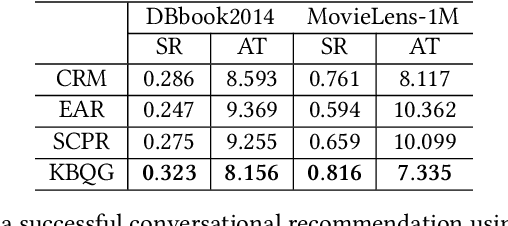
Conversational recommender systems (CRSs) have revolutionized the conventional recommendation paradigm by embracing dialogue agents to dynamically capture the fine-grained user preference. In a typical conversational recommendation scenario, a CRS firstly generates questions to let the user clarify her/his demands and then makes suitable recommendations. Hence, the ability to generate suitable clarifying questions is the key to timely tracing users' dynamic preferences and achieving successful recommendations. However, existing CRSs fall short in asking high-quality questions because: (1) system-generated responses heavily depends on the performance of the dialogue policy agent, which has to be trained with huge conversation corpus to cover all circumstances; and (2) current CRSs cannot fully utilize the learned latent user profiles for generating appropriate and personalized responses. To mitigate these issues, we propose the Knowledge-Based Question Generation System (KBQG), a novel framework for conversational recommendation. Distinct from previous conversational recommender systems, KBQG models a user's preference in a finer granularity by identifying the most relevant relations from a structured knowledge graph (KG). Conditioned on the varied importance of different relations, the generated clarifying questions could perform better in impelling users to provide more details on their preferences. Finially, accurate recommendations can be generated in fewer conversational turns. Furthermore, the proposed KBQG outperforms all baselines in our experiments on two real-world datasets.