 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support
Apr 09, 2026Deploying LLM-powered agents in enterprise scenarios such as cloud technical support demands high-quality, domain-specific skills. However, existing skill creators lack domain grounding, producing skills poorly aligned with real-world task requirements. Moreover, once deployed, there is no systematic mechanism to trace execution failures back to skill deficiencies and drive targeted refinements, leaving skill quality stagnant despite accumulating operational evidence. We introduce SkillForge, a self-evolving framework that closes an end-to-end creation-evaluation-refinement loop. To produce well-aligned initial skills, a Domain-Contextualized Skill Creator grounds skill synthesis in knowledge bases and historical support tickets. To enable continuous self-optimization, a three-stage pipeline -- Failure Analyzer, Skill Diagnostician, and Skill Optimizer -- automatically diagnoses execution failures in batch, pinpoints the underlying skill deficiencies, and rewrites the skill to eliminate them. This cycle runs iteratively, allowing skills to self-improve with every round of deployment feedback. Evaluated on five real-world cloud support scenarios spanning 1,883 tickets and 3,737 tasks, experiments show that: (1) the Domain-Contextualized Skill Creator produces substantially better initial skills than the generic skill creator, as measured by consistency with expert-authored reference responses from historical tickets; and (2) the self-evolution loop progressively improves skill quality from diverse starting points (including expert-authored, domain-created, and generic skills) across successive rounds, demonstrating that automated evolution can surpass manually curated expert knowledge.
CirrusBench: Evaluating LLM-based Agents Beyond Correctness in Real-World Cloud Service Environments
Mar 30, 2026The increasing agentic capabilities of Large Language Models (LLMs) have enabled their deployment in real-world applications, such as cloud services, where customer-assistant interactions exhibit high technical complexity and long-horizon dependencies, making robustness and resolution efficiency critical for customer satisfaction. However, existing benchmarks for LLM-based agents largely rely on synthetic environments that fail to capture the diversity and unpredictability of authentic customer inputs, often ignoring the resolution efficiency essential for real-world deployment. To bridge this gap, we introduce CirrusBench, a novel evaluation framework distinguished by its foundation in real-world data from authentic cloud service tickets. CirrusBench preserves the intricate multi-turn logical chains and realistic tool dependencies inherent to technical service environments. Moving beyond execution correctness, we introduce novel Customer-Centric metrics to define agent success, quantifying service quality through metrics such as the Normalized Efficiency Index and Multi-Turn Latency to explicitly measure resolution efficiency. Experiments utilizing our framework reveal that while state-of-the-art models demonstrate strong reasoning capabilities, they frequently struggle in complex, realistic multi-turn tasks and fail to meet the high-efficiency standards required for customer service, highlighting critical directions for the future development of LLM-based agents in practical technical service applications. CirrusBench evaluation framework is released at: https://github.com/CirrusAI
Lightweight Adaptation for LLM-based Technical Service Agent: Latent Logic Augmentation and Robust Noise Reduction
Mar 18, 2026Adapting Large Language Models in complex technical service domains is constrained by the absence of explicit cognitive chains in human demonstrations and the inherent ambiguity arising from the diversity of valid responses. These limitations severely hinder agents from internalizing latent decision dynamics and generalizing effectively. Moreover, practical adaptation is often impeded by the prohibitive resource and time costs associated with standard training paradigms. To overcome these challenges and guarantee computational efficiency, we propose a lightweight adaptation framework comprising three key contributions. (1) Latent Logic Augmentation: We introduce Planning-Aware Trajectory Modeling and Decision Reasoning Augmentation to bridge the gap between surface-level supervision and latent decision logic. These approaches strengthen the stability of Supervised Fine-Tuning alignment. (2) Robust Noise Reduction: We construct a Multiple Ground Truths dataset through a dual-filtering method to reduce the noise by validating diverse responses, thereby capturing the semantic diversity. (3) Lightweight Adaptation: We design a Hybrid Reward mechanism that fuses an LLM-based judge with a lightweight relevance-based Reranker to distill high-fidelity reward signals while reducing the computational cost compared to standard LLM-as-a-Judge reinforcement learning. Empirical evaluations on real-world Cloud service tasks, conducted across semantically diverse settings, demonstrate that our framework achieves stability and performance gains through Latent Logic Augmentation and Robust Noise Reduction. Concurrently, our Hybrid Reward mechanism achieves alignment comparable to standard LLM-as-a-judge methods with reduced training time, underscoring the practical value for deploying technical service agents.
Deep Explainable Learning with Graph Based Data Assessing and Rule Reasoning
Nov 10, 2022



Learning an explainable classifier often results in low accuracy model or ends up with a huge rule set, while learning a deep model is usually more capable of handling noisy data at scale, but with the cost of hard to explain the result and weak at generalization. To mitigate this gap, we propose an end-to-end deep explainable learning approach that combines the advantage of deep model in noise handling and expert rule-based interpretability. Specifically, we propose to learn a deep data assessing model which models the data as a graph to represent the correlations among different observations, whose output will be used to extract key data features. The key features are then fed into a rule network constructed following predefined noisy expert rules with trainable parameters. As these models are correlated, we propose an end-to-end training framework, utilizing the rule classification loss to optimize the rule learning model and data assessing model at the same time. As the rule-based computation is none-differentiable, we propose a gradient linking search module to carry the gradient information from the rule learning model to the data assessing model. The proposed method is tested in an industry production system, showing comparable prediction accuracy, much higher generalization stability and better interpretability when compared with a decent deep ensemble baseline, and shows much better fitting power than pure rule-based approach.
AAformer: Auto-Aligned Transformer for Person Re-Identification
Apr 02, 2021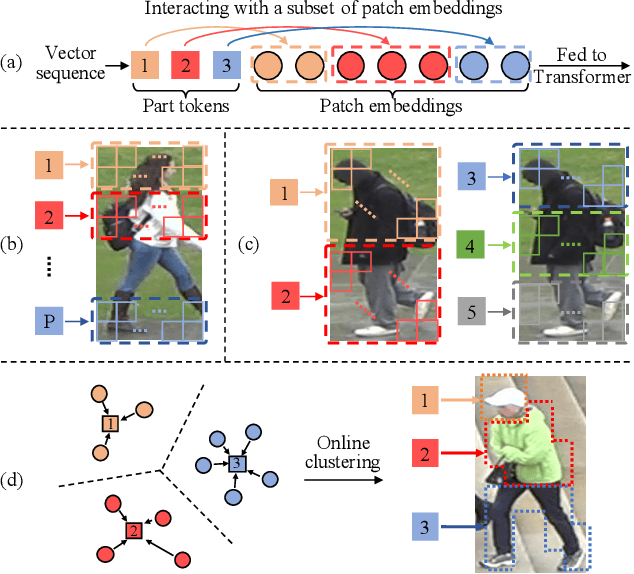
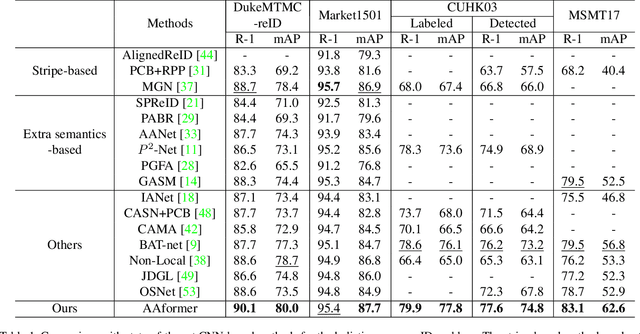
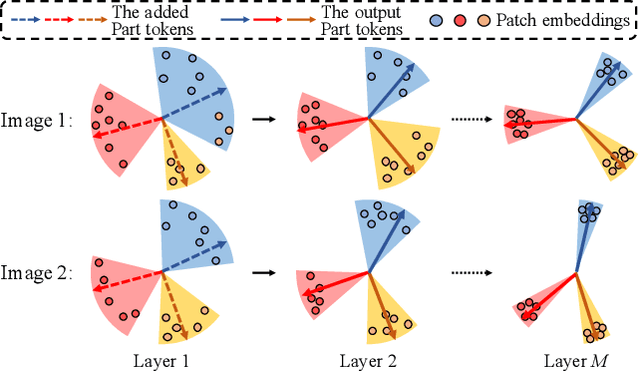
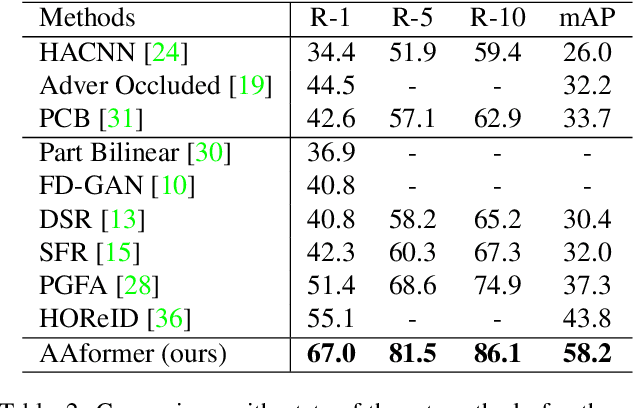
Transformer is showing its superiority over convolutional architectures in many vision tasks like image classification and object detection. However, the lacking of an explicit alignment mechanism limits its capability in person re-identification (re-ID), in which there are inevitable misalignment issues caused by pose/viewpoints variations, etc. On the other hand, the alignment paradigm of convolutional neural networks does not perform well in Transformer in our experiments. To address this problem, we develop a novel alignment framework for Transformer through adding the learnable vectors of "part tokens" to learn the part representations and integrating the part alignment into the self-attention. A part token only interacts with a subset of patch embeddings and learns to represent this subset. Based on the framework, we design an online Auto-Aligned Transformer (AAformer) to adaptively assign the patch embeddings of the same semantics to the identical part token in the running time. The part tokens can be regarded as the part prototypes, and a fast variant of Sinkhorn-Knopp algorithm is employed to cluster the patch embeddings to part tokens online. AAformer can be viewed as a new principled formulation for simultaneously learning both part alignment and part representations. Extensive experiments validate the effectiveness of part tokens and the superiority of AAformer over various state-of-the-art CNN-based methods. Our codes will be released.
Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications
Feb 12, 2018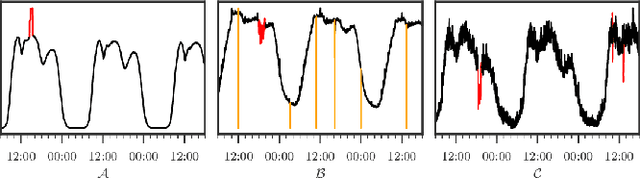
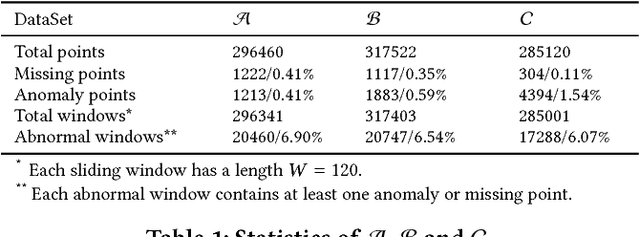
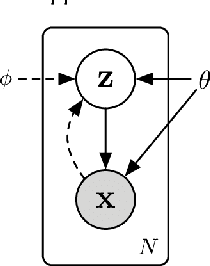

To ensure undisrupted business, large Internet companies need to closely monitor various KPIs (e.g., Page Views, number of online users, and number of orders) of its Web applications, to accurately detect anomalies and trigger timely troubleshooting/mitigation. However, anomaly detection for these seasonal KPIs with various patterns and data quality has been a great challenge, especially without labels. In this paper, we proposed Donut, an unsupervised anomaly detection algorithm based on VAE. Thanks to a few of our key techniques, Donut greatly outperforms a state-of-arts supervised ensemble approach and a baseline VAE approach, and its best F-scores range from 0.75 to 0.9 for the studied KPIs from a top global Internet company. We come up with a novel KDE interpretation of reconstruction for Donut, making it the first VAE-based anomaly detection algorithm with solid theoretical explanation.