 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting RCNN: On Awakening the Classification Power of Faster RCNN
Jul 14, 2018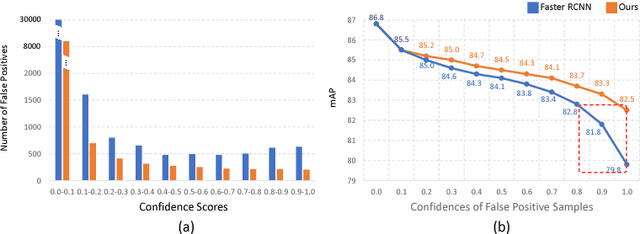
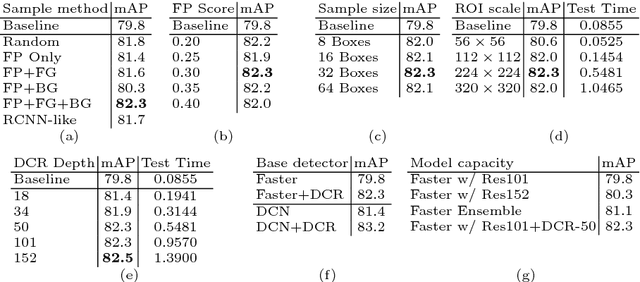
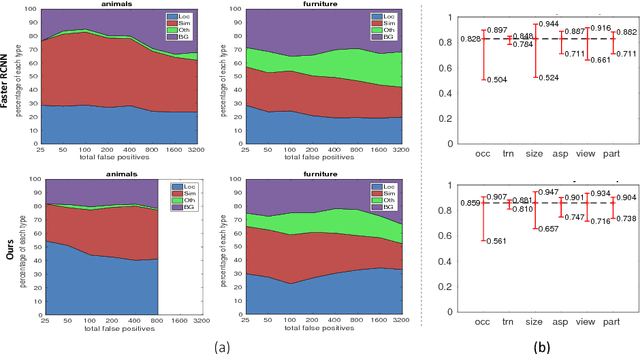
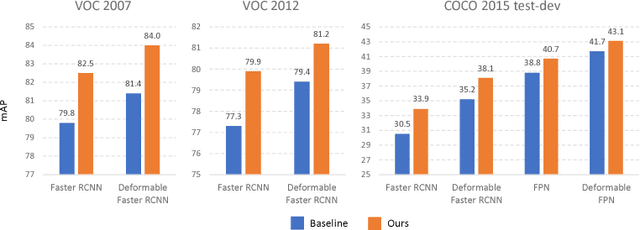
Recent region-based object detectors are usually built with separate classification and localization branches on top of shared feature extraction networks. In this paper, we analyze failure cases of state-of-the-art detectors and observe that most hard false positives result from classification instead of localization. We conjecture that: (1) Shared feature representation is not optimal due to the mismatched goals of feature learning for classification and localization; (2) multi-task learning helps, yet optimization of the multi-task loss may result in sub-optimal for individual tasks; (3) large receptive field for different scales leads to redundant context information for small objects.We demonstrate the potential of detector classification power by a simple, effective, and widely-applicable Decoupled Classification Refinement (DCR) network. DCR samples hard false positives from the base classifier in Faster RCNN and trains a RCNN-styled strong classifier. Experiments show new state-of-the-art results on PASCAL VOC and COCO without any bells and whistles.
TS2C: Tight Box Mining with Surrounding Segmentation Context for Weakly Supervised Object Detection
Jul 13, 2018

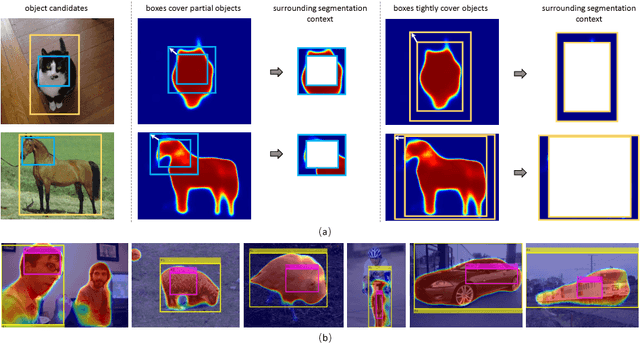
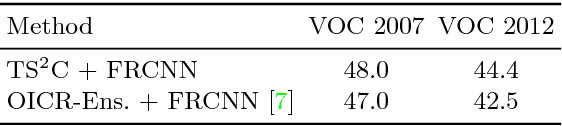
This work provides a simple approach to discover tight object bounding boxes with only image-level supervision, called Tight box mining with Surrounding Segmentation Context (TS2C). We observe that object candidates mined through current multiple instance learning methods are usually trapped to discriminative object parts, rather than the entire object. TS2C leverages surrounding segmentation context derived from weakly-supervised segmentation to suppress such low-quality distracting candidates and boost the high-quality ones. Specifically, TS2C is developed based on two key properties of desirable bounding boxes: 1) high purity, meaning most pixels in the box are with high object response, and 2) high completeness, meaning the box covers high object response pixels comprehensively. With such novel and computable criteria, more tight candidates can be discovered for learning a better object detector. With TS2C, we obtain 48.0% and 44.4% mAP scores on VOC 2007 and 2012 benchmarks, which are the new state-of-the-arts.
Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised Semantic Segmentation
May 28, 2018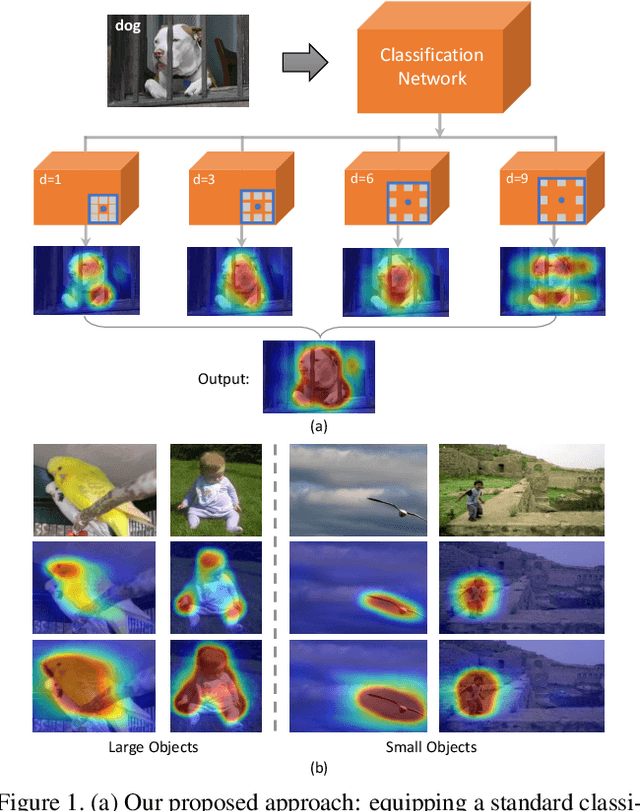
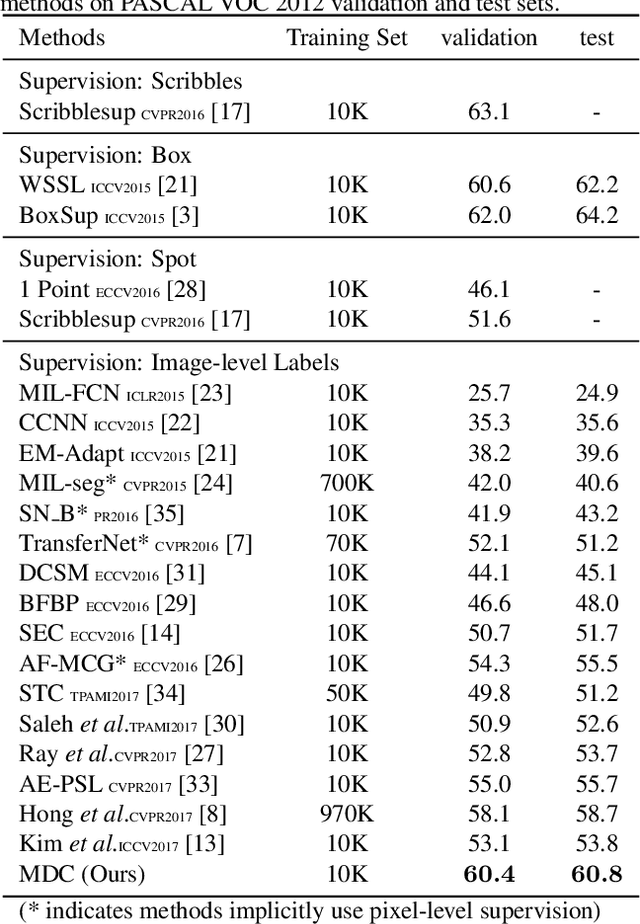


Despite the remarkable progress, weakly supervised segmentation approaches are still inferior to their fully supervised counterparts. We obverse the performance gap mainly comes from their limitation on learning to produce high-quality dense object localization maps from image-level supervision. To mitigate such a gap, we revisit the dilated convolution [1] and reveal how it can be utilized in a novel way to effectively overcome this critical limitation of weakly supervised segmentation approaches. Specifically, we find that varying dilation rates can effectively enlarge the receptive fields of convolutional kernels and more importantly transfer the surrounding discriminative information to non-discriminative object regions, promoting the emergence of these regions in the object localization maps. Then, we design a generic classification network equipped with convolutional blocks of different dilated rates. It can produce dense and reliable object localization maps and effectively benefit both weakly- and semi- supervised semantic segmentation. Despite the apparent simplicity, our proposed approach obtains superior performance over state-of-the-arts. In particular, it achieves 60.8% and 67.6% mIoU scores on Pascal VOC 2012 test set in weakly- (only image-level labels are available) and semi- (1,464 segmentation masks are available) supervised settings, which are the new state-of-the-arts.
Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
Dec 04, 2017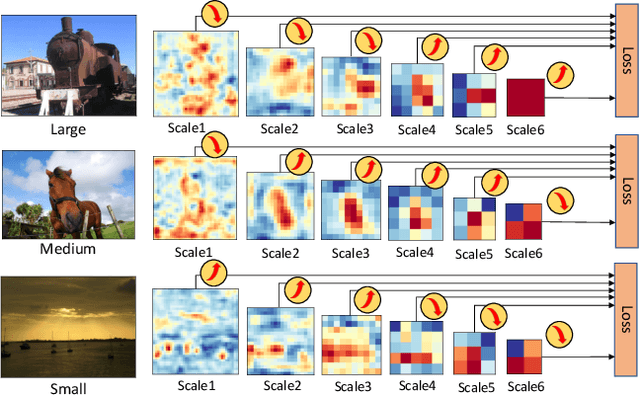

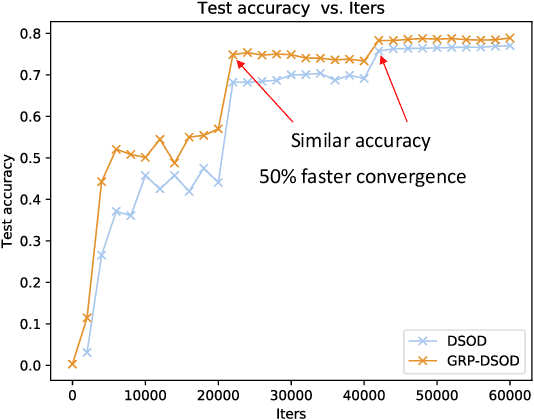
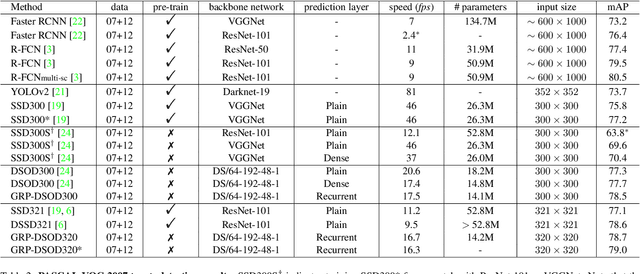
In this paper, we propose gated recurrent feature pyramid for the problem of learning object detection from scratch. Our approach is motivated by the recent work of deeply supervised object detector (DSOD), but explores new network architecture that dynamically adjusts the supervision intensities of intermediate layers for various scales in object detection. The benefits of the proposed method are two-fold: First, we propose a recurrent feature-pyramid structure to squeeze rich spatial and semantic features into a single prediction layer that further reduces the number of parameters to learn (DSOD need learn 1/2, but our method need only 1/3). Thus our new model is more fit for learning from scratch, and can converge faster than DSOD (using only 50% of iterations). Second, we introduce a novel gate-controlled prediction strategy to adaptively enhance or attenuate supervision at different scales based on the input object size. As a result, our model is more suitable for detecting small objects. To the best of our knowledge, our study is the best performed model of learning object detection from scratch. Our method in the PASCAL VOC 2012 comp3 leaderboard (which compares object detectors that are trained only with PASCAL VOC data) demonstrates a significant performance jump, from previous 64% to our 77% (VOC 07++12) and 72.5% (VOC 12). We also evaluate the performance of our method on PASCAL VOC 2007, 2012 and MS COCO datasets, and find that the accuracy of our learning from scratch method can even beat a lot of the state-of-the-art detection methods which use pre-trained models from ImageNet. Code is available at: https://github.com/szq0214/GRP-DSOD .
Stacked Approximated Regression Machine: A Simple Deep Learning Approach
Sep 08, 2016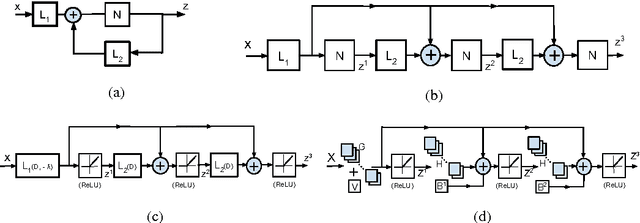
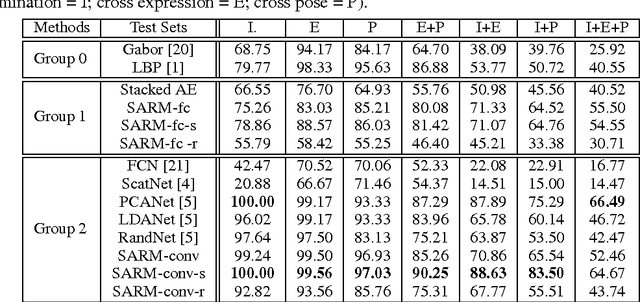
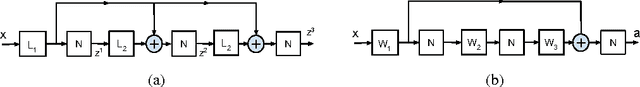

With the agreement of my coauthors, I Zhangyang Wang would like to withdraw the manuscript "Stacked Approximated Regression Machine: A Simple Deep Learning Approach". Some experimental procedures were not included in the manuscript, which makes a part of important claims not meaningful. In the relevant research, I was solely responsible for carrying out the experiments; the other coauthors joined in the discussions leading to the main algorithm. Please see the updated text for more details.
Seq-NMS for Video Object Detection
Aug 22, 2016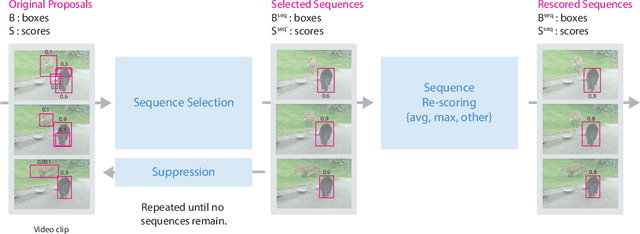
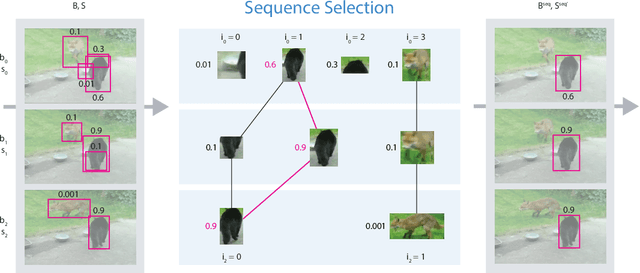
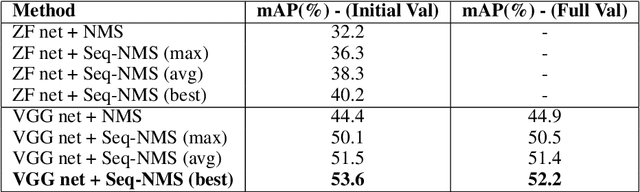
Video object detection is challenging because objects that are easily detected in one frame may be difficult to detect in another frame within the same clip. Recently, there have been major advances for doing object detection in a single image. These methods typically contain three phases: (i) object proposal generation (ii) object classification and (iii) post-processing. We propose a modification of the post-processing phase that uses high-scoring object detections from nearby frames to boost scores of weaker detections within the same clip. We show that our method obtains superior results to state-of-the-art single image object detection techniques. Our method placed 3rd in the video object detection (VID) task of the ImageNet Large Scale Visual Recognition Challenge 2015 (ILSVRC2015).