 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath-based Deep Network for Candidate Item Matching in Recommenders
May 18, 2021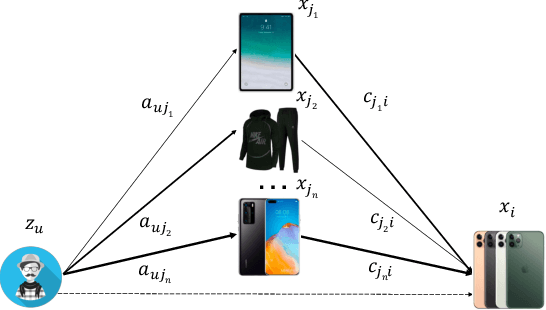
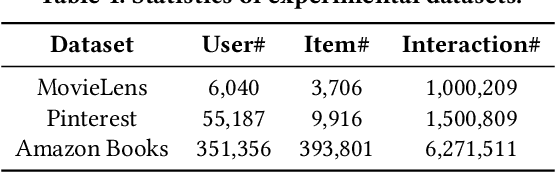
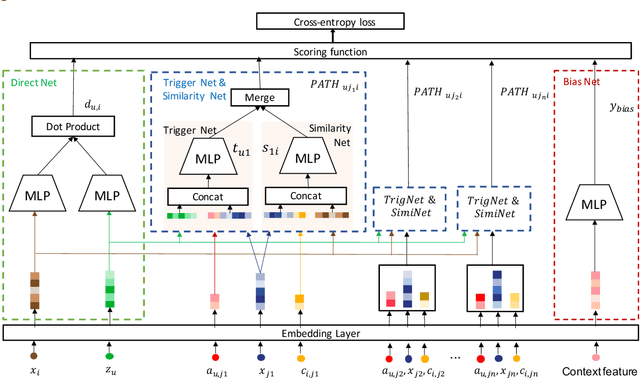
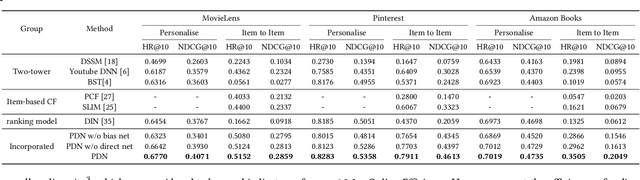
The large-scale recommender system mainly consists of two stages: matching and ranking. The matching stage (also known as the retrieval step) identifies a small fraction of relevant items from billion-scale item corpus in low latency and computational cost. Item-to-item collaborative filter (item-based CF) and embedding-based retrieval (EBR) have been long used in the industrial matching stage owing to its efficiency. However, item-based CF is hard to meet personalization, while EBR has difficulty in satisfying diversity. In this paper, we propose a novel matching architecture, Path-based Deep Network (named PDN), which can incorporate both personalization and diversity to enhance matching performance. Specifically, PDN is comprised of two modules: Trigger Net and Similarity Net. PDN utilizes Trigger Net to capture the user's interest in each of his/her interacted item, and Similarity Net to evaluate the similarity between each interacted item and the target item based on these items' profile and CF information. The final relevance between the user and the target item is calculated by explicitly considering user's diverse interests, \ie aggregating the relevance weights of the related two-hop paths (one hop of a path corresponds to user-item interaction and the other to item-item relevance). Furthermore, we describe the architecture design of a matching system with the proposed PDN in a leading real-world E-Commerce service (Mobile Taobao App). Based on offline evaluations and online A/B test, we show that PDN outperforms the existing solutions for the same task. The online results also demonstrate that PDN can retrieve more personalized and more diverse relevant items to significantly improve user engagement. Currently, PDN system has been successfully deployed at Mobile Taobao App and handling major online traffic.
Learning a Product Relevance Model from Click-Through Data in E-Commerce
Feb 14, 2021

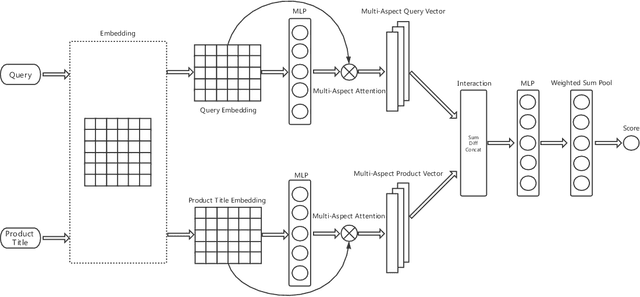

The search engine plays a fundamental role in online e-commerce systems, to help users find the products they want from the massive product collections. Relevance is an essential requirement for e-commerce search, since showing products that do not match search query intent will degrade user experience. With the existence of vocabulary gap between user language of queries and seller language of products, measuring semantic relevance is necessary and neural networks are engaged to address this task. However, semantic relevance is different from click-through rate prediction in that no direct training signal is available. Most previous attempts learn relevance models from user click-through data that are cheap and abundant. Unfortunately, click behavior is noisy and misleading, which is affected by not only relevance but also factors including price, image and attractive titles. Therefore, it is challenging but valuable to learn relevance models from click-through data. In this paper, we propose a new relevance learning framework that concentrates on how to train a relevance model from the weak supervision of click-through data. Different from previous efforts that treat samples as either relevant or irrelevant, we construct more fine-grained samples for training. We propose a novel way to consider samples of different relevance confidence, and come up with a new training objective to learn a robust relevance model with desirable score distribution. The proposed model is evaluated on offline annotated data and online A/B testing, and it achieves both promising performance and high computational efficiency. The model has already been deployed online, serving the search traffic of Taobao for over a year.
Explanation as a Defense of Recommendation
Jan 24, 2021
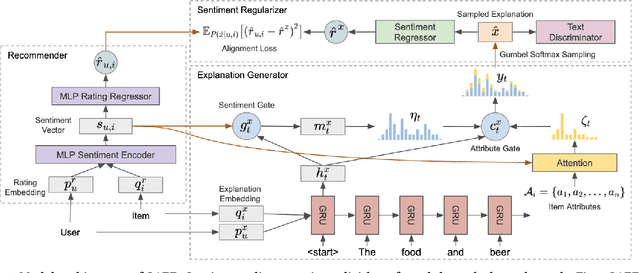
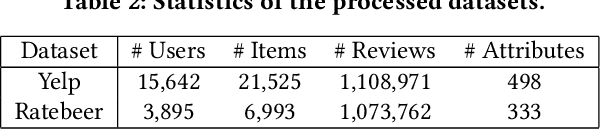
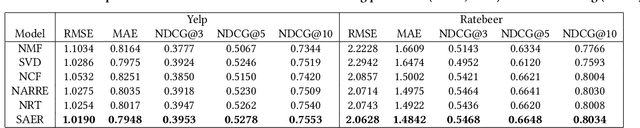
Textual explanations have proved to help improve user satisfaction on machine-made recommendations. However, current mainstream solutions loosely connect the learning of explanation with the learning of recommendation: for example, they are often separately modeled as rating prediction and content generation tasks. In this work, we propose to strengthen their connection by enforcing the idea of sentiment alignment between a recommendation and its corresponding explanation. At training time, the two learning tasks are joined by a latent sentiment vector, which is encoded by the recommendation module and used to make word choices for explanation generation. At both training and inference time, the explanation module is required to generate explanation text that matches sentiment predicted by the recommendation module. Extensive experiments demonstrate our solution outperforms a rich set of baselines in both recommendation and explanation tasks, especially on the improved quality of its generated explanations. More importantly, our user studies confirm our generated explanations help users better recognize the differences between recommended items and understand why an item is recommended.
CATN: Cross-Domain Recommendation for Cold-Start Users via Aspect Transfer Network
May 23, 2020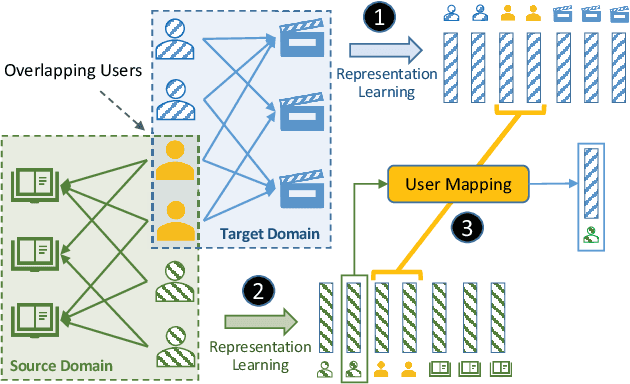
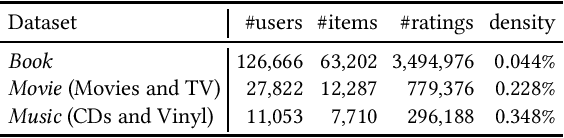
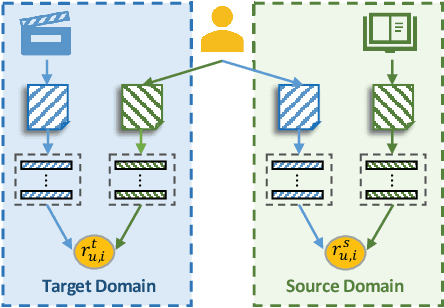
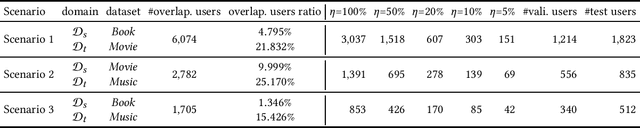
In a large recommender system, the products (or items) could be in many different categories or domains. Given two relevant domains (e.g., Book and Movie), users may have interactions with items in one domain but not in the other domain. To the latter, these users are considered as cold-start users. How to effectively transfer users' preferences based on their interactions from one domain to the other relevant domain, is the key issue in cross-domain recommendation. Inspired by the advances made in review-based recommendation, we propose to model user preference transfer at aspect-level derived from reviews. To this end, we propose a cross-domain recommendation framework via aspect transfer network for cold-start users (named CATN). CATN is devised to extract multiple aspects for each user and each item from their review documents, and learn aspect correlations across domains with an attention mechanism. In addition, we further exploit auxiliary reviews from like-minded users to enhance a user's aspect representations. Then, an end-to-end optimization framework is utilized to strengthen the robustness of our model. On real-world datasets, the proposed CATN outperforms SOTA models significantly in terms of rating prediction accuracy. Further analysis shows that our model is able to reveal user aspect connections across domains at a fine level of granularity, making the recommendation explainable.
AdaBERT: Task-Adaptive BERT Compression with Differentiable Neural Architecture Search
Jan 13, 2020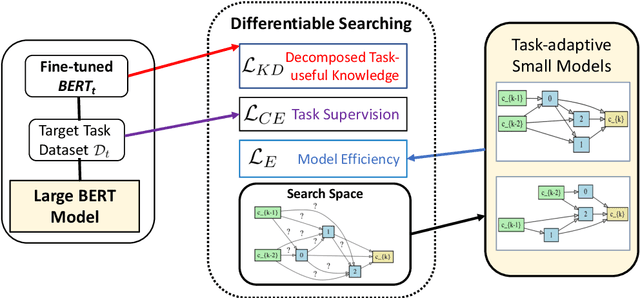
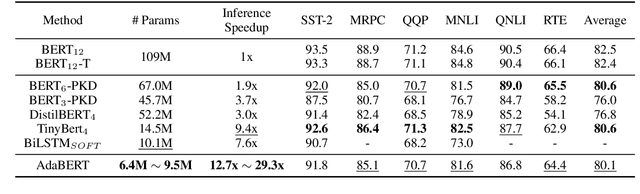
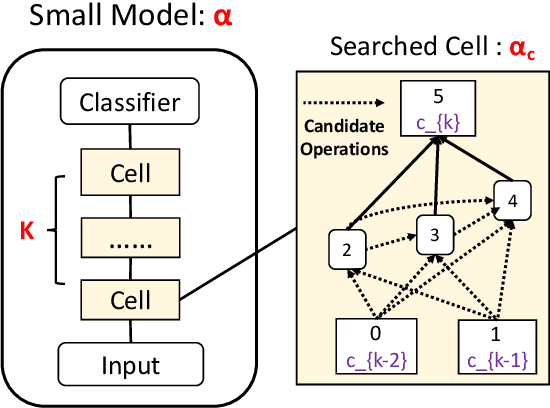

Large pre-trained language models such as BERT have shown their effectiveness in various natural language processing tasks. However, the huge parameter size makes them difficult to be deployed in real-time applications that require quick inference with limited resources. Existing methods compress BERT into small models while such compression is task-independent, i.e., the same compressed BERT for all different downstream tasks. Motivated by the necessity and benefits of task-oriented BERT compression, we propose a novel compression method, AdaBERT, that leverages differentiable Neural Architecture Search to automatically compress BERT into task-adaptive small models for specific tasks. We incorporate a task-oriented knowledge distillation loss to provide search hints and an efficiency-aware loss as search constraints, which enables a good trade-off between efficiency and effectiveness for task-adaptive BERT compression. We evaluate AdaBERT on several NLP tasks, and the results demonstrate that those task-adaptive compressed models are 12.7x to 29.3x faster than BERT in inference time and 11.5x to 17.0x smaller in terms of parameter size, while comparable performance is maintained.
Gated Group Self-Attention for Answer Selection
May 26, 2019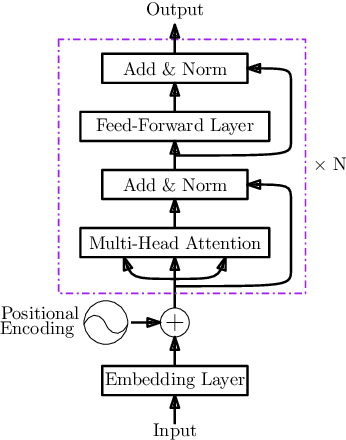
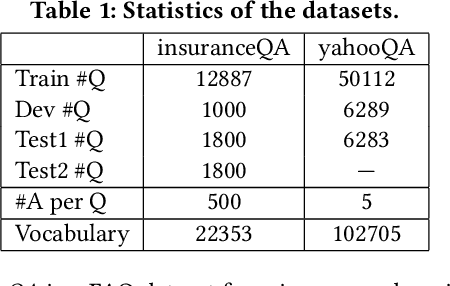
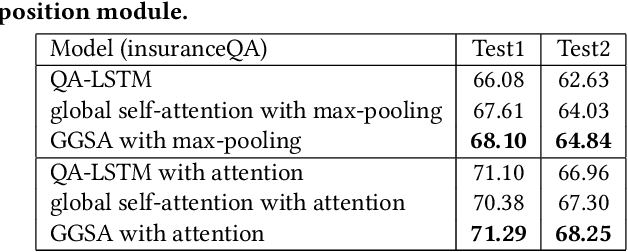
Answer selection (answer ranking) is one of the key steps in many kinds of question answering (QA) applications, where deep models have achieved state-of-the-art performance. Among these deep models, recurrent neural network (RNN) based models are most popular, typically with better performance than convolutional neural network (CNN) based models. Nevertheless, it is difficult for RNN based models to capture the information about long-range dependency among words in the sentences of questions and answers. In this paper, we propose a new deep model, called gated group self-attention (GGSA), for answer selection. GGSA is inspired by global self-attention which is originally proposed for machine translation and has not been explored in answer selection. GGSA tackles the problem of global self-attention that local and global information cannot be well distinguished. Furthermore, an interaction mechanism between questions and answers is also proposed to enhance GGSA by a residual structure. Experimental results on two popular QA datasets show that GGSA can outperform existing answer selection models to achieve state-of-the-art performance. Furthermore, GGSA can also achieve higher accuracy than global self-attention for the answer selection task, with a lower computation cost.