 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaS-VQA: A Mask-and-Select Framework for Knowledge-Based Visual Question Answering
Feb 17, 2026Knowledge-based Visual Question Answering (KB-VQA) requires models to answer questions by integrating visual information with external knowledge. However, retrieved knowledge is often noisy, partially irrelevant, or misaligned with the visual content, while internal model knowledge is difficult to control and interpret. Naive aggregation of these sources limits reasoning effectiveness and reduces answer accuracy. To address this, we propose MaS-VQA, a selection-driven framework that tightly couples explicit knowledge filtering with implicit knowledge reasoning. MaS-VQA first retrieves candidate passages and applies a Mask-and-Select mechanism to jointly prune irrelevant image regions and weakly relevant knowledge fragments, producing compact, high-signal multimodal knowledge . This filtered knowledge then guides the activation of internal knowledge in a constrained semantic space, enabling complementary co-modeling of explicit and implicit knowledge for robust answer prediction. Experiments on Encyclopedic-VQA and InfoSeek demonstrate consistent performance gains across multiple MLLM backbones, and ablations verify that the selection mechanism effectively reduces noise and enhances knowledge utilization.
REAL: Resolving Knowledge Conflicts in Knowledge-Intensive Visual Question Answering via Reasoning-Pivot Alignment
Feb 15, 2026Knowledge-intensive Visual Question Answering (KI-VQA) frequently suffers from severe knowledge conflicts caused by the inherent limitations of open-domain retrieval. However, existing paradigms face critical limitations due to the lack of generalizable conflict detection and intra-model constraint mechanisms to handle conflicting evidence. To address these challenges, we propose the REAL (Reasoning-Pivot Alignment) framework centered on the novel concept of the Reasoning-Pivot. Distinct from reasoning steps that prioritize internal self-derivation, a reasoning-pivot serves as an atomic unit (node or edge) in the reasoning chain that emphasizes knowledge linkage, and it typically relies on external evidence to complete the reasoning. Supported by our constructed REAL-VQA dataset, our approach integrates Reasoning-Pivot Aware SFT (RPA-SFT) to train a generalizable discriminator by aligning conflicts with pivot extraction, and employs Reasoning-Pivot Guided Decoding (RPGD), an intra-model decoding strategy that leverages these pivots for targeted conflict mitigation. Extensive experiments across diverse benchmarks demonstrate that REAL significantly enhances discrimination accuracy and achieves state-of-the-art performance, validating the effectiveness of our pivot-driven resolution paradigm.
Gated Group Self-Attention for Answer Selection
May 26, 2019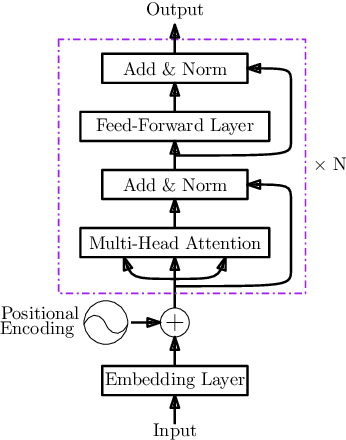
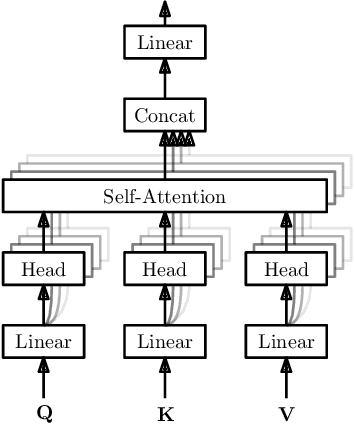
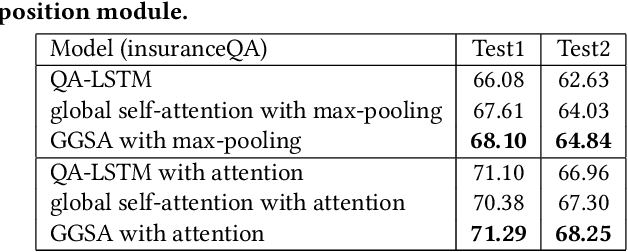
Answer selection (answer ranking) is one of the key steps in many kinds of question answering (QA) applications, where deep models have achieved state-of-the-art performance. Among these deep models, recurrent neural network (RNN) based models are most popular, typically with better performance than convolutional neural network (CNN) based models. Nevertheless, it is difficult for RNN based models to capture the information about long-range dependency among words in the sentences of questions and answers. In this paper, we propose a new deep model, called gated group self-attention (GGSA), for answer selection. GGSA is inspired by global self-attention which is originally proposed for machine translation and has not been explored in answer selection. GGSA tackles the problem of global self-attention that local and global information cannot be well distinguished. Furthermore, an interaction mechanism between questions and answers is also proposed to enhance GGSA by a residual structure. Experimental results on two popular QA datasets show that GGSA can outperform existing answer selection models to achieve state-of-the-art performance. Furthermore, GGSA can also achieve higher accuracy than global self-attention for the answer selection task, with a lower computation cost.