 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Realistic Bokeh Effect Rendering on Mobile GPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



As mobile cameras with compact optics are unable to produce a strong bokeh effect, lots of interest is now devoted to deep learning-based solutions for this task. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based bokeh effect rendering approach that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The runtime of the resulting models was evaluated on the Kirin 9000's Mali GPU that provides excellent acceleration results for the majority of common deep learning ops. A detailed description of all models developed in this challenge is provided in this paper.
Knowledge Prompting in Pre-trained Language Model for Natural Language Understanding
Oct 16, 2022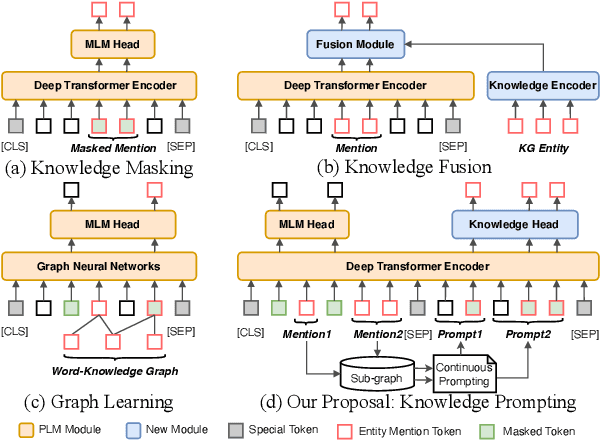
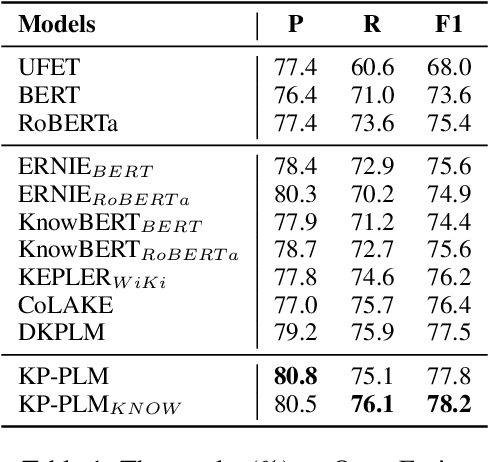
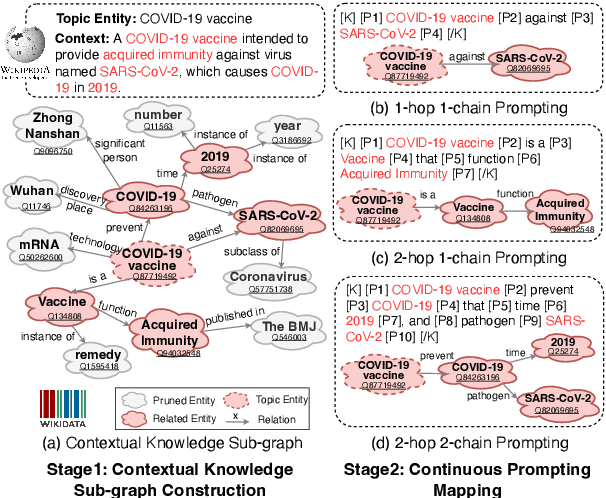
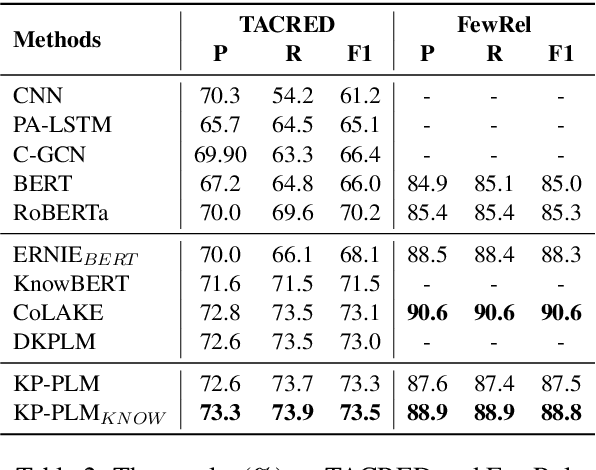
Knowledge-enhanced Pre-trained Language Model (PLM) has recently received significant attention, which aims to incorporate factual knowledge into PLMs. However, most existing methods modify the internal structures of fixed types of PLMs by stacking complicated modules, and introduce redundant and irrelevant factual knowledge from knowledge bases (KBs). In this paper, to address these problems, we introduce a seminal knowledge prompting paradigm and further propose a knowledge-prompting-based PLM framework KP-PLM. This framework can be flexibly combined with existing mainstream PLMs. Specifically, we first construct a knowledge sub-graph from KBs for each context. Then we design multiple continuous prompts rules and transform the knowledge sub-graph into natural language prompts. To further leverage the factual knowledge from these prompts, we propose two novel knowledge-aware self-supervised tasks including prompt relevance inspection and masked prompt modeling. Extensive experiments on multiple natural language understanding (NLU) tasks show the superiority of KP-PLM over other state-of-the-art methods in both full-resource and low-resource settings.
Strong Instance Segmentation Pipeline for MMSports Challenge
Sep 28, 2022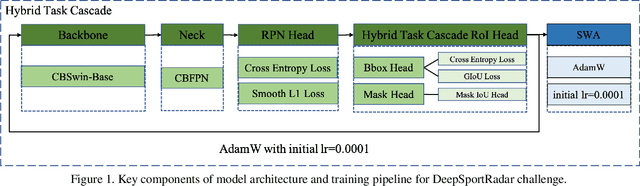

The goal of ACM MMSports2022 DeepSportRadar Instance Segmentation Challenge is to tackle the segmentation of individual humans including players, coaches and referees on a basketball court. And the main characteristics of this challenge are there is a high level of occlusions between players and the amount of data is quite limited. In order to address these problems, we designed a strong instance segmentation pipeline. Firstly, we employed a proper data augmentation strategy for this task mainly including photometric distortion transform and copy-paste strategy, which can generate more image instances with a wider distribution. Secondly, we employed a strong segmentation model, Hybrid Task Cascade based detector on the Swin-Base based CBNetV2 backbone, and we add MaskIoU head to HTCMaskHead that can simply and effectively improve the performance of instance segmentation. Finally, the SWA training strategy was applied to improve the performance further. Experimental results demonstrate the proposed pipeline can achieve a competitive result on the DeepSportRadar challenge, with 0.768AP@0.50:0.95 on the challenge set. Source code is available at https://github.com/YJingyu/Instanc_Segmentation_Pro.
The Third Place Solution for CVPR2022 AVA Accessibility Vision and Autonomy Challenge
Jun 28, 2022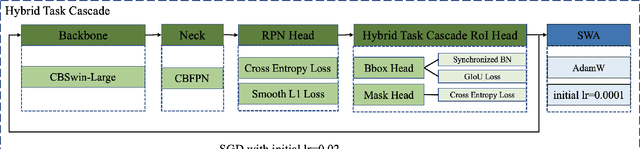

The goal of AVA challenge is to provide vision-based benchmarks and methods relevant to accessibility. In this paper, we introduce the technical details of our submission to the CVPR2022 AVA Challenge. Firstly, we conducted some experiments to help employ proper model and data augmentation strategy for this task. Secondly, an effective training strategy was applied to improve the performance. Thirdly, we integrated the results from two different segmentation frameworks to improve the performance further. Experimental results demonstrate that our approach can achieve a competitive result on the AVA test set. Finally, our approach achieves 63.008\%AP@0.50:0.95 on the test set of CVPR2022 AVA Challenge.
Bilateral Network with Channel Splitting Network and Transformer for Thermal Image Super-Resolution
Jun 24, 2022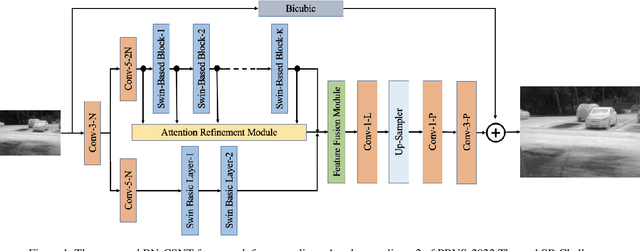
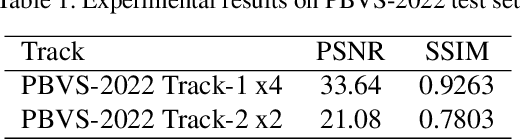
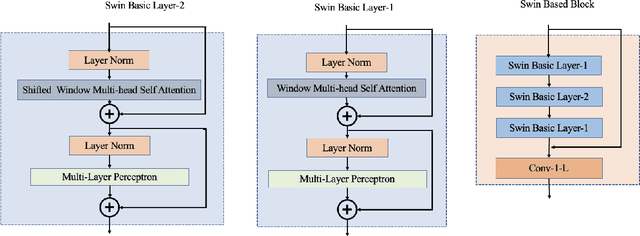
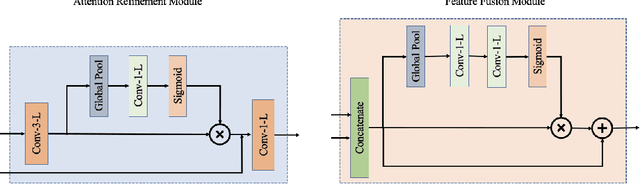
In recent years, the Thermal Image Super-Resolution (TISR) problem has become an attractive research topic. TISR would been used in a wide range of fields, including military, medical, agricultural and animal ecology. Due to the success of PBVS-2020 and PBVS-2021 workshop challenge, the result of TISR keeps improving and attracts more researchers to sign up for PBVS-2022 challenge. In this paper, we will introduce the technical details of our submission to PBVS-2022 challenge designing a Bilateral Network with Channel Splitting Network and Transformer(BN-CSNT) to tackle the TISR problem. Firstly, we designed a context branch based on channel splitting network with transformer to obtain sufficient context information. Secondly, we designed a spatial branch with shallow transformer to extract low level features which can preserve the spatial information. Finally, for the context branch in order to fuse the features from channel splitting network and transformer, we proposed an attention refinement module, and then features from context branch and spatial branch are fused by proposed feature fusion module. The proposed method can achieve PSNR=33.64, SSIM=0.9263 for x4 and PSNR=21.08, SSIM=0.7803 for x2 in the PBVS-2022 challenge test dataset.
The Second Place Solution for The 4th Large-scale Video Object Segmentation Challenge--Track 3: Referring Video Object Segmentation
Jun 24, 2022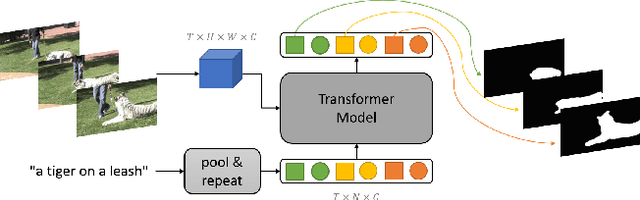
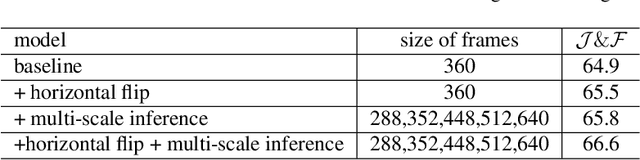
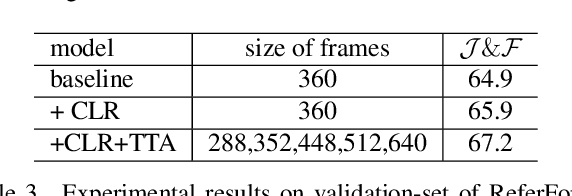
The referring video object segmentation task (RVOS) aims to segment object instances in a given video referred by a language expression in all video frames. Due to the requirement of understanding cross-modal semantics within individual instances, this task is more challenging than the traditional semi-supervised video object segmentation where the ground truth object masks in the first frame are given. With the great achievement of Transformer in object detection and object segmentation, RVOS has been made remarkable progress where ReferFormer achieved the state-of-the-art performance. In this work, based on the strong baseline framework--ReferFormer, we propose several tricks to boost further, including cyclical learning rates, semi-supervised approach, and test-time augmentation inference. The improved ReferFormer ranks 2nd place on CVPR2022 Referring Youtube-VOS Challenge.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022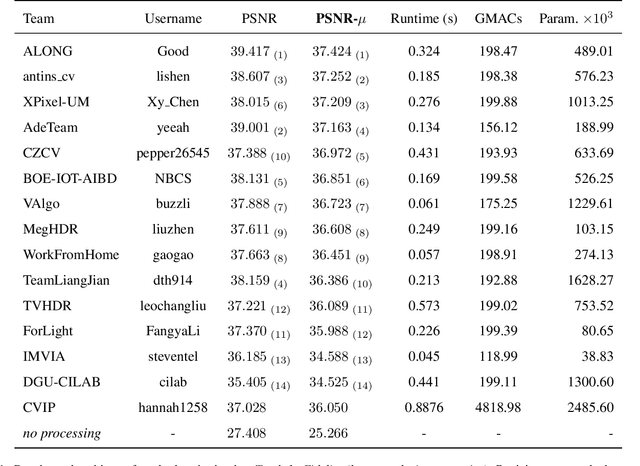
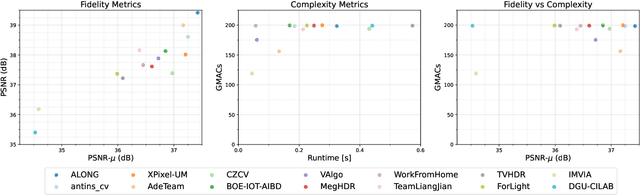
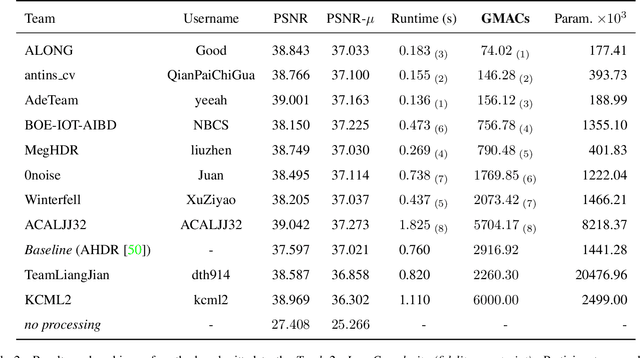
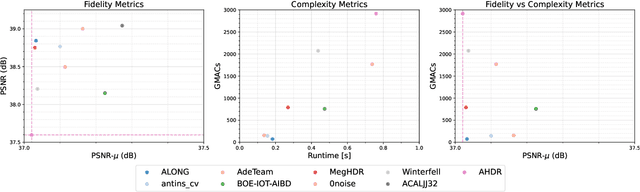
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
KECP: Knowledge Enhanced Contrastive Prompting for Few-shot Extractive Question Answering
May 06, 2022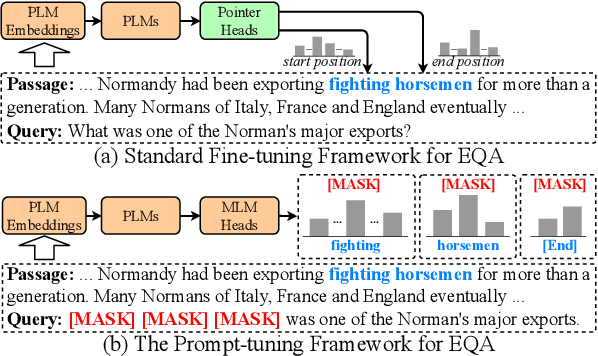
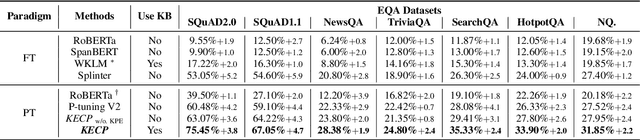
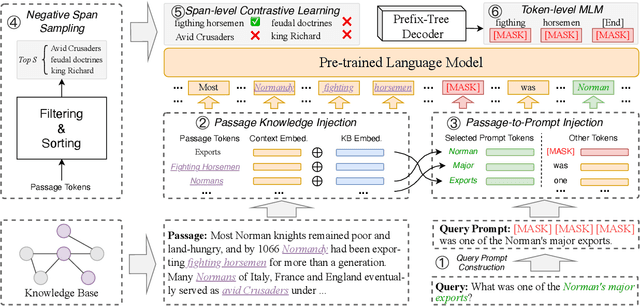
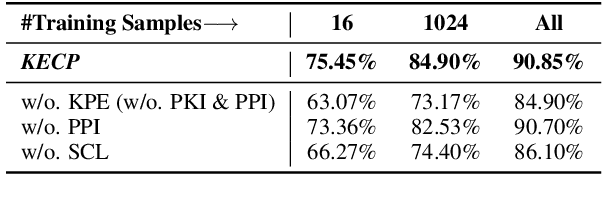
Extractive Question Answering (EQA) is one of the most important tasks in Machine Reading Comprehension (MRC), which can be solved by fine-tuning the span selecting heads of Pre-trained Language Models (PLMs). However, most existing approaches for MRC may perform poorly in the few-shot learning scenario. To solve this issue, we propose a novel framework named Knowledge Enhanced Contrastive Prompt-tuning (KECP). Instead of adding pointer heads to PLMs, we introduce a seminal paradigm for EQA that transform the task into a non-autoregressive Masked Language Modeling (MLM) generation problem. Simultaneously, rich semantics from the external knowledge base (KB) and the passage context are support for enhancing the representations of the query. In addition, to boost the performance of PLMs, we jointly train the model by the MLM and contrastive learning objectives. Experiments on multiple benchmarks demonstrate that our method consistently outperforms state-of-the-art approaches in few-shot settings by a large margin.
Efficient Progressive High Dynamic Range Image Restoration via Attention and Alignment Network
Apr 20, 2022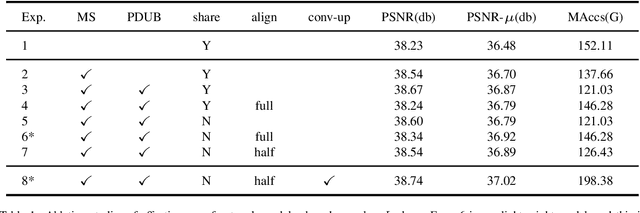
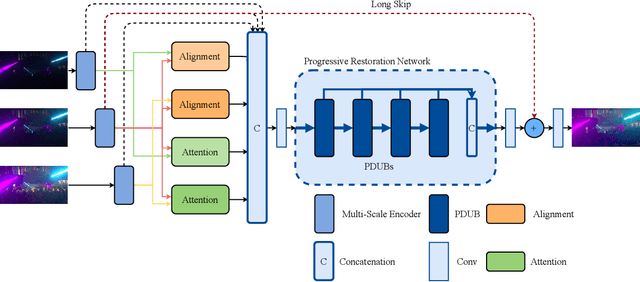
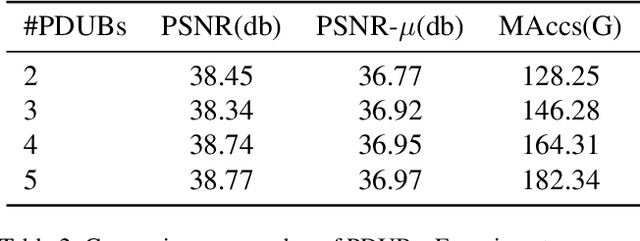
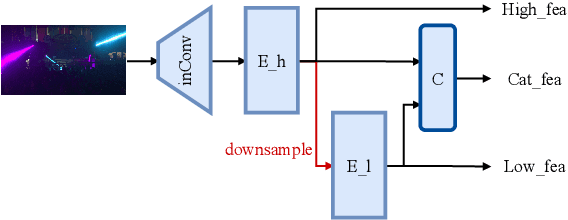
HDR is an important part of computational photography technology. In this paper, we propose a lightweight neural network called Efficient Attention-and-alignment-guided Progressive Network (EAPNet) for the challenge NTIRE 2022 HDR Track 1 and Track 2. We introduce a multi-dimensional lightweight encoding module to extract features. Besides, we propose Progressive Dilated U-shape Block (PDUB) that can be a progressive plug-and-play module for dynamically tuning MAccs and PSNR. Finally, we use fast and low-power feature-align module to deal with misalignment problem in place of the time-consuming Deformable Convolutional Network (DCN). The experiments show that our method achieves about 20 times compression on MAccs with better mu-PSNR and PSNR compared to the state-of-the-art method. We got the second place of both two tracks during the testing phase. Figure1. shows the visualized result of NTIRE 2022 HDR challenge.