 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Apr 20, 2021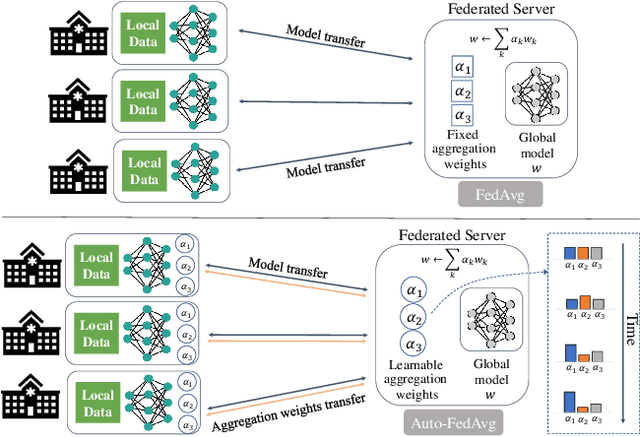
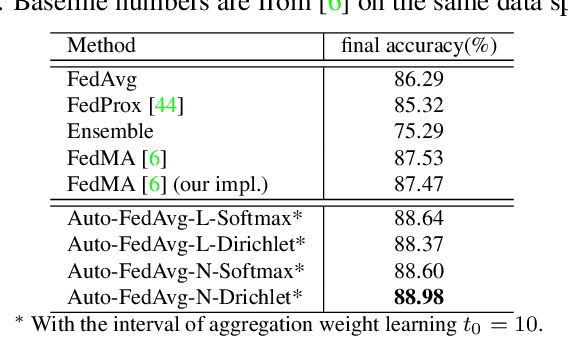
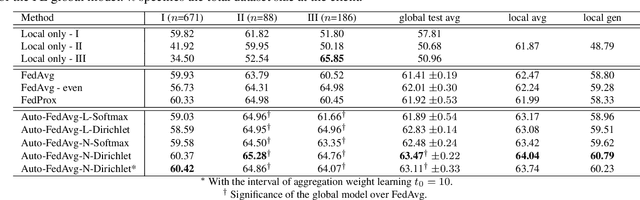
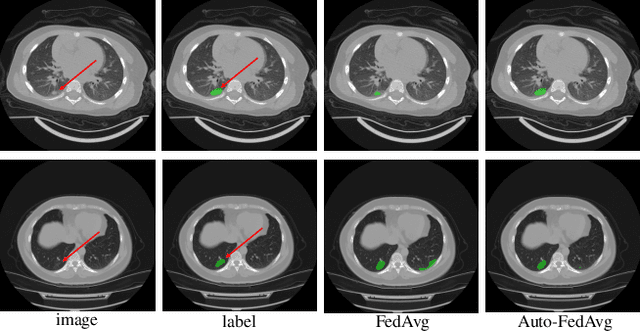
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
DiNTS: Differentiable Neural Network Topology Search for 3D Medical Image Segmentation
Mar 29, 2021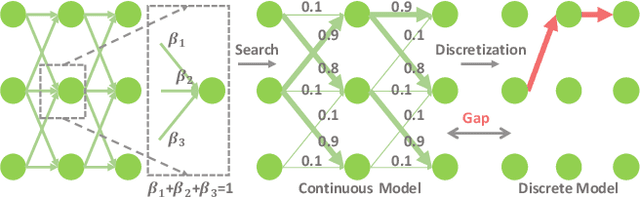
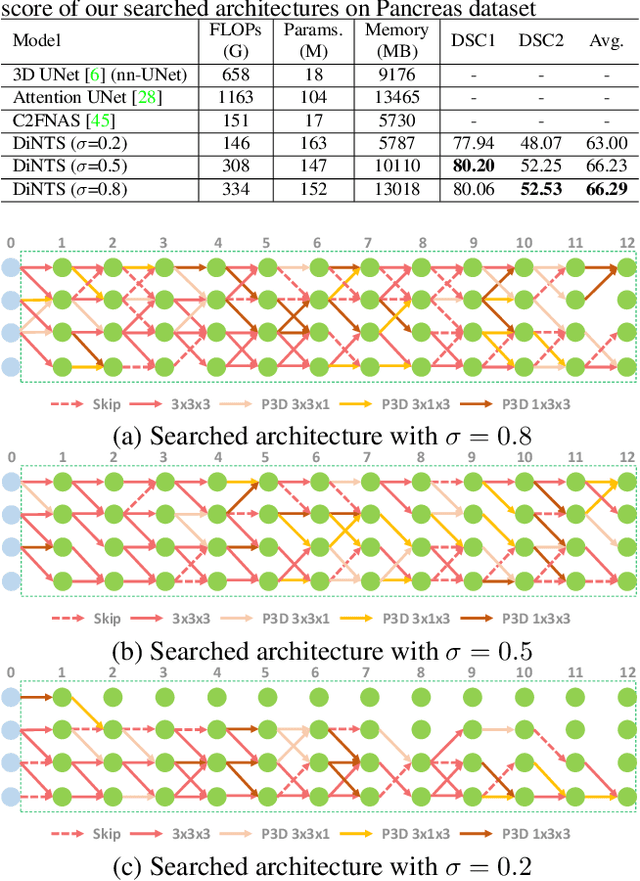
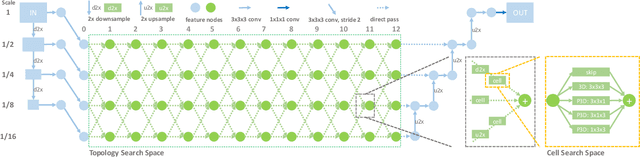
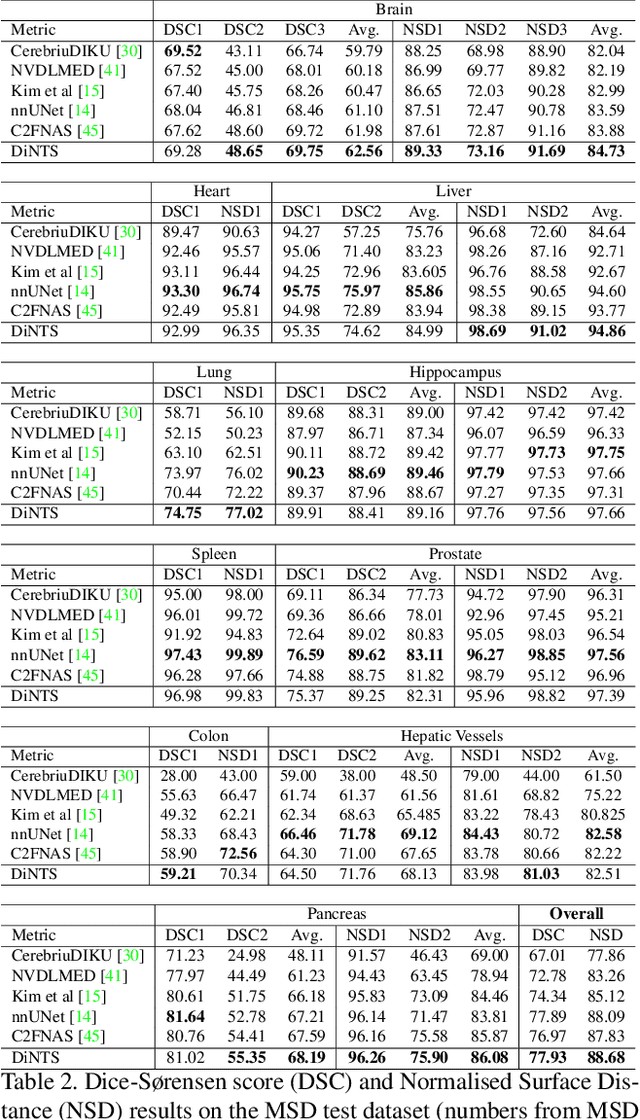
Recently, neural architecture search (NAS) has been applied to automatically search high-performance networks for medical image segmentation. The NAS search space usually contains a network topology level (controlling connections among cells with different spatial scales) and a cell level (operations within each cell). Existing methods either require long searching time for large-scale 3D image datasets, or are limited to pre-defined topologies (such as U-shaped or single-path). In this work, we focus on three important aspects of NAS in 3D medical image segmentation: flexible multi-path network topology, high search efficiency, and budgeted GPU memory usage. A novel differentiable search framework is proposed to support fast gradient-based search within a highly flexible network topology search space. The discretization of the searched optimal continuous model in differentiable scheme may produce a sub-optimal final discrete model (discretization gap). Therefore, we propose a topology loss to alleviate this problem. In addition, the GPU memory usage for the searched 3D model is limited with budget constraints during search. Our Differentiable Network Topology Search scheme (DiNTS) is evaluated on the Medical Segmentation Decathlon (MSD) challenge, which contains ten challenging segmentation tasks. Our method achieves the state-of-the-art performance and the top ranking on the MSD challenge leaderboard.
UNETR: Transformers for 3D Medical Image Segmentation
Mar 18, 2021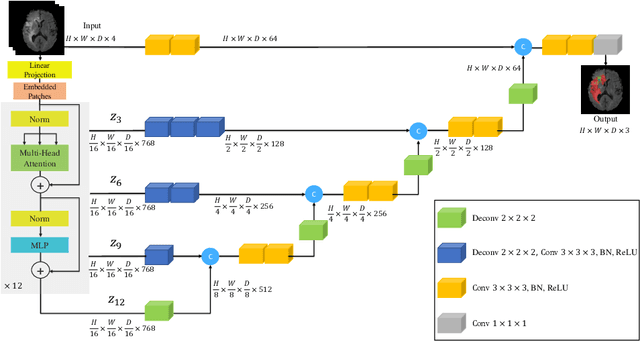
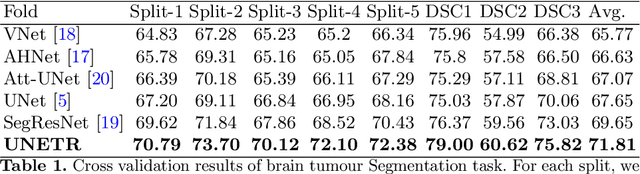
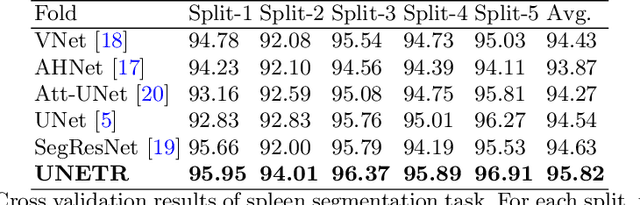
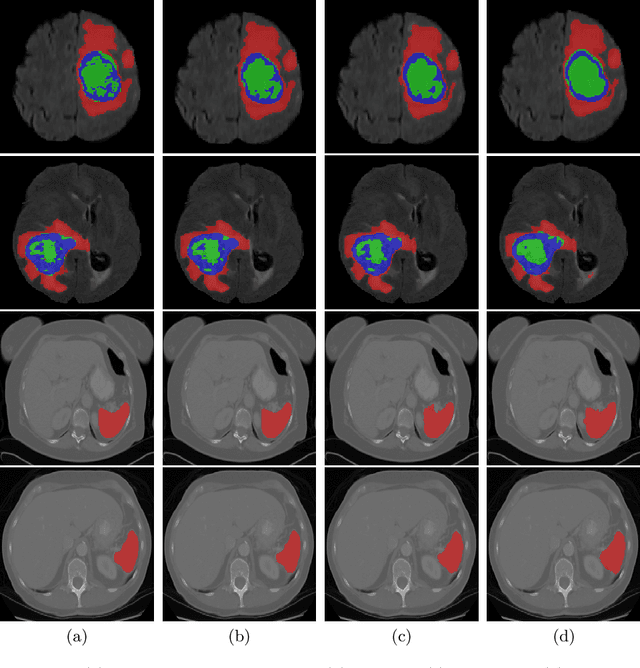
Fully Convolutional Neural Networks (FCNNs) with contracting and expansive paths (e.g. encoder and decoder) have shown prominence in various medical image segmentation applications during the recent years. In these architectures, the encoder plays an integral role by learning global contextual representations which will be further utilized for semantic output prediction by the decoder. Despite their success, the locality of convolutional layers , as the main building block of FCNNs limits the capability of learning long-range spatial dependencies in such networks. Inspired by the recent success of transformers in Natural Language Processing (NLP) in long-range sequence learning, we reformulate the task of volumetric (3D) medical image segmentation as a sequence-to-sequence prediction problem. In particular, we introduce a novel architecture, dubbed as UNEt TRansformers (UNETR), that utilizes a pure transformer as the encoder to learn sequence representations of the input volume and effectively capture the global multi-scale information. The transformer encoder is directly connected to a decoder via skip connections at different resolutions to compute the final semantic segmentation output. We have extensively validated the performance of our proposed model across different imaging modalities(i.e. MR and CT) on volumetric brain tumour and spleen segmentation tasks using the Medical Segmentation Decathlon (MSD) dataset, and our results consistently demonstrate favorable benchmarks.
Learning Image Labels On-the-fly for Training Robust Classification Models
Oct 02, 2020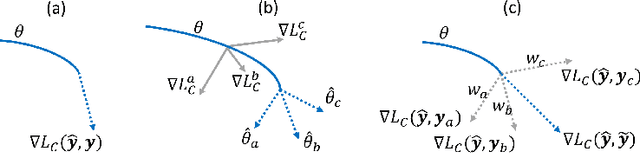
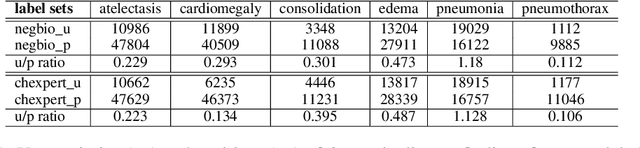
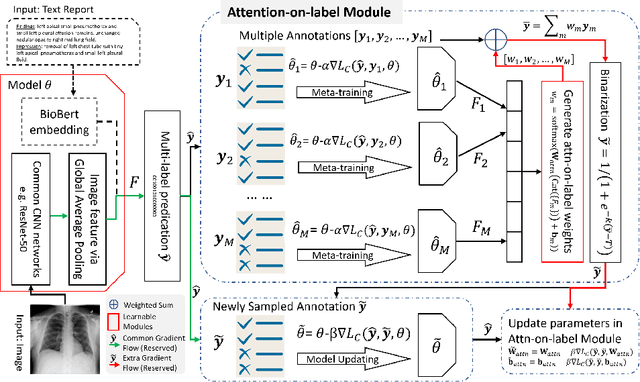

Current deep learning paradigms largely benefit from the tremendous amount of annotated data. However, the quality of the annotations often varies among labelers. Multi-observer studies have been conducted to study these annotation variances (by labeling the same data for multiple times) and its effects on critical applications like medical image analysis. This process indeed adds an extra burden to the already tedious annotation work that usually requires professional training and expertise in the specific domains. On the other hand, automated annotation methods based on NLP algorithms have recently shown promise as a reasonable alternative, relying on the existing diagnostic reports of those images that are widely available in the clinical system. Compared to human labelers, different algorithms provide labels with varying qualities that are even noisier. In this paper, we show how noisy annotations (e.g., from different algorithm-based labelers) can be utilized together and mutually benefit the learning of classification tasks. Specifically, the concept of attention-on-label is introduced to sample better label sets on-the-fly as the training data. A meta-training based label-sampling module is designed to attend the labels that benefit the model learning the most through additional back-propagation processes. We apply the attention-on-label scheme on the classification task of a synthetic noisy CIFAR-10 dataset to prove the concept, and then demonstrate superior results (3-5% increase on average in multiple disease classification AUCs) on the chest x-ray images from a hospital-scale dataset (MIMIC-CXR) and hand-labeled dataset (OpenI) in comparison to regular training paradigms.
Democratizing Artificial Intelligence in Healthcare: A Study of Model Development Across Two Institutions Incorporating Transfer Learning
Sep 25, 2020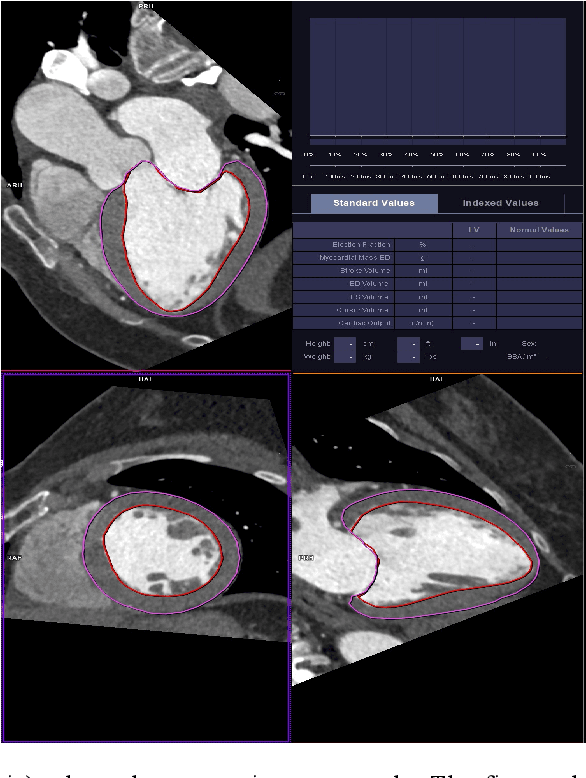
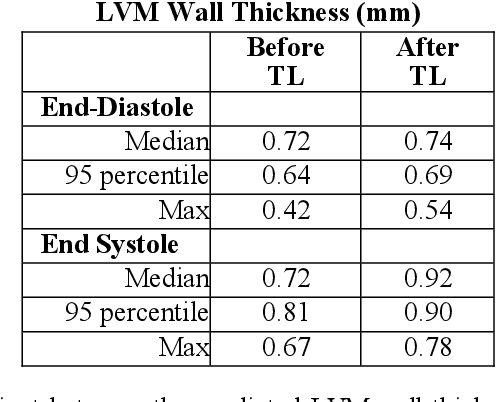
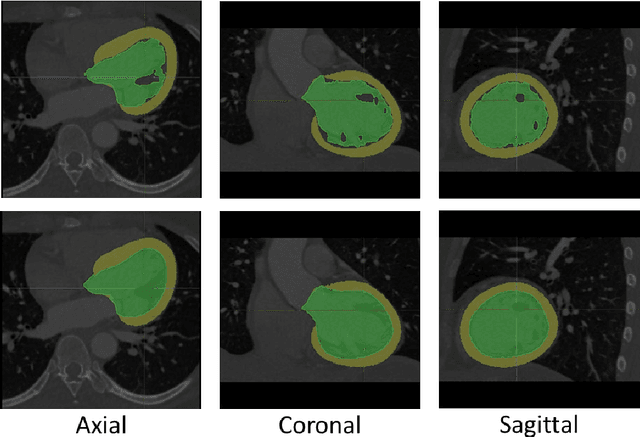
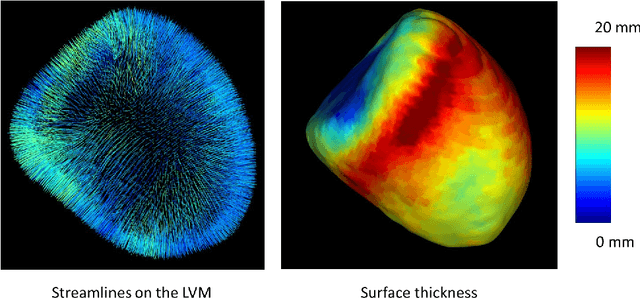
The training of deep learning models typically requires extensive data, which are not readily available as large well-curated medical-image datasets for development of artificial intelligence (AI) models applied in Radiology. Recognizing the potential for transfer learning (TL) to allow a fully trained model from one institution to be fine-tuned by another institution using a much small local dataset, this report describes the challenges, methodology, and benefits of TL within the context of developing an AI model for a basic use-case, segmentation of Left Ventricular Myocardium (LVM) on images from 4-dimensional coronary computed tomography angiography. Ultimately, our results from comparisons of LVM segmentation predicted by a model locally trained using random initialization, versus one training-enhanced by TL, showed that a use-case model initiated by TL can be developed with sparse labels with acceptable performance. This process reduces the time required to build a new model in the clinical environment at a different institution.
Uncertainty-aware multi-view co-training for semi-supervised medical image segmentation and domain adaptation
Jun 28, 2020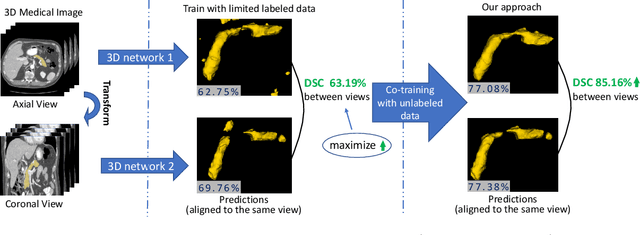
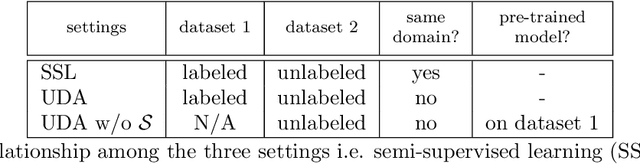
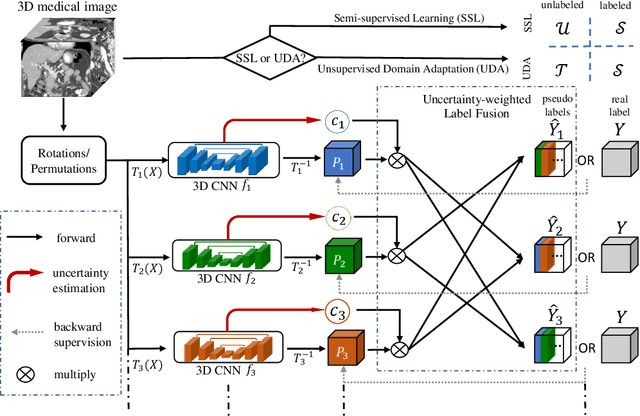
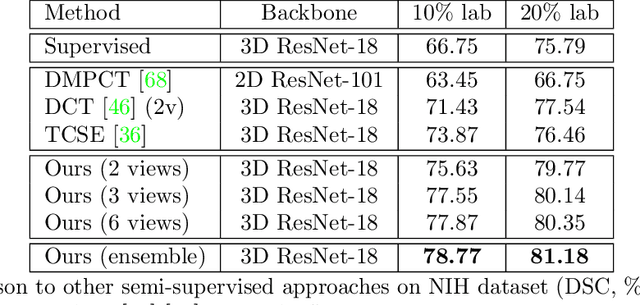
Although having achieved great success in medical image segmentation, deep learning-based approaches usually require large amounts of well-annotated data, which can be extremely expensive in the field of medical image analysis. Unlabeled data, on the other hand, is much easier to acquire. Semi-supervised learning and unsupervised domain adaptation both take the advantage of unlabeled data, and they are closely related to each other. In this paper, we propose uncertainty-aware multi-view co-training (UMCT), a unified framework that addresses these two tasks for volumetric medical image segmentation. Our framework is capable of efficiently utilizing unlabeled data for better performance. We firstly rotate and permute the 3D volumes into multiple views and train a 3D deep network on each view. We then apply co-training by enforcing multi-view consistency on unlabeled data, where an uncertainty estimation of each view is utilized to achieve accurate labeling. Experiments on the NIH pancreas segmentation dataset and a multi-organ segmentation dataset show state-of-the-art performance of the proposed framework on semi-supervised medical image segmentation. Under unsupervised domain adaptation settings, we validate the effectiveness of this work by adapting our multi-organ segmentation model to two pathological organs from the Medical Segmentation Decathlon Datasets. Additionally, we show that our UMCT-DA model can even effectively handle the challenging situation where labeled source data is inaccessible, demonstrating strong potentials for real-world applications.
* 19 pages, 6 figures, to appear in Medical Image Analysis. This article is an extension of the conference paper arXiv:1811.12506
LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation
Jun 26, 2020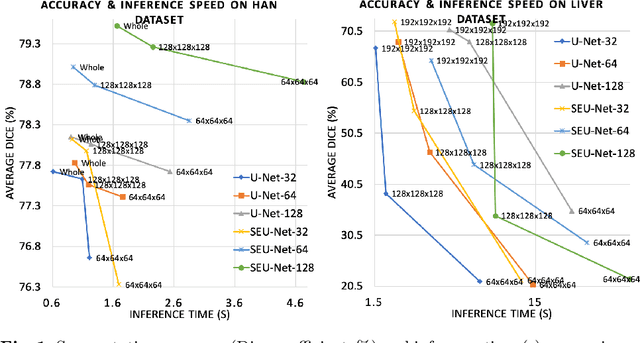
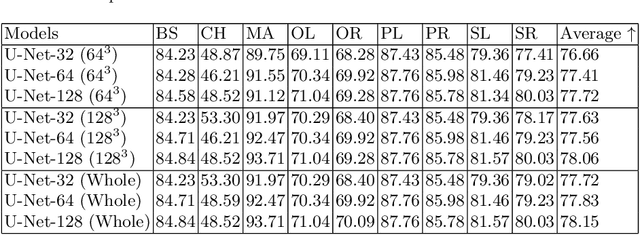
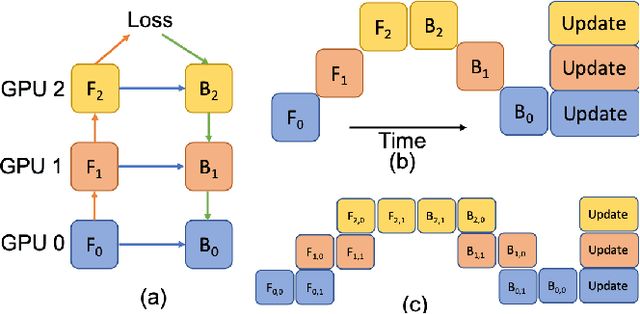
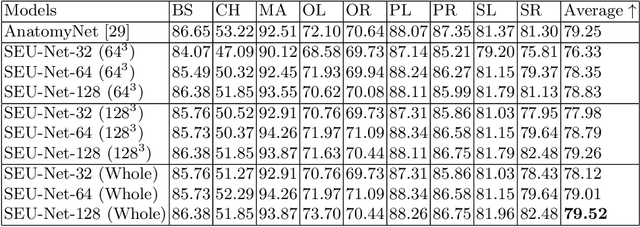
Deep Learning (DL) models are becoming larger, because the increase in model size might offer significant accuracy gain. To enable the training of large deep networks, data parallelism and model parallelism are two well-known approaches for parallel training. However, data parallelism does not help reduce memory footprint per device. In this work, we introduce Large deep 3D ConvNets with Automated Model Parallelism (LAMP) and investigate the impact of both input's and deep 3D ConvNets' size on segmentation accuracy. Through automated model parallelism, it is feasible to train large deep 3D ConvNets with a large input patch, even the whole image. Extensive experiments demonstrate that, facilitated by the automated model parallelism, the segmentation accuracy can be improved through increasing model size and input context size, and large input yields significant inference speedup compared with sliding window of small patches in the inference. Code is available\footnote{https://monai.io/research/lamp-automated-model-parallelism}.
Cardiac Segmentation on Late Gadolinium Enhancement MRI: A Benchmark Study from Multi-Sequence Cardiac MR Segmentation Challenge
Jun 22, 2020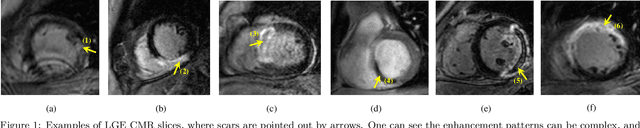
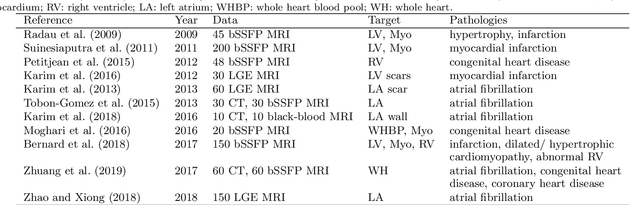
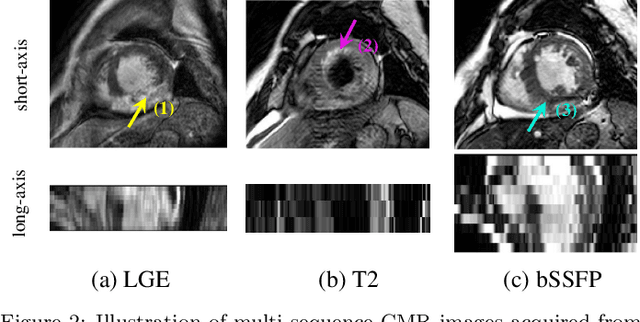

Accurate computing, analysis and modeling of the ventricles and myocardium from medical images are important, especially in the diagnosis and treatment management for patients suffering from myocardial infarction (MI). Late gadolinium enhancement (LGE) cardiac magnetic resonance (CMR) provides an important protocol to visualize MI. However, automated segmentation of LGE CMR is still challenging, due to the indistinguishable boundaries, heterogeneous intensity distribution and complex enhancement patterns of pathological myocardium from LGE CMR. Furthermore, compared with the other sequences LGE CMR images with gold standard labels are particularly limited, which represents another obstacle for developing novel algorithms for automatic segmentation of LGE CMR. This paper presents the selective results from the Multi-Sequence Cardiac MR (MS-CMR) Segmentation challenge, in conjunction with MICCAI 2019. The challenge offered a data set of paired MS-CMR images, including auxiliary CMR sequences as well as LGE CMR, from 45 patients who underwent cardiomyopathy. It was aimed to develop new algorithms, as well as benchmark existing ones for LGE CMR segmentation and compare them objectively. In addition, the paired MS-CMR images could enable algorithms to combine the complementary information from the other sequences for the segmentation of LGE CMR. Nine representative works were selected for evaluation and comparisons, among which three methods are unsupervised methods and the other six are supervised. The results showed that the average performance of the nine methods was comparable to the inter-observer variations. The success of these methods was mainly attributed to the inclusion of the auxiliary sequences from the MS-CMR images, which provide important label information for the training of deep neural networks.
Searching Learning Strategy with Reinforcement Learning for 3D Medical Image Segmentation
Jun 10, 2020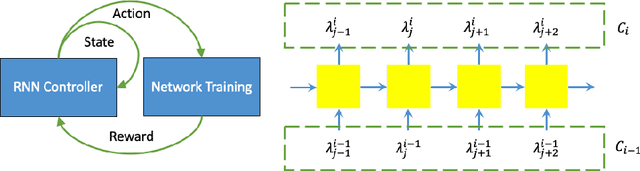
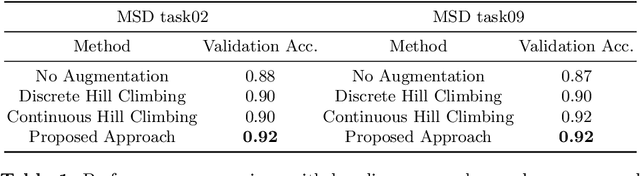
Deep neural network (DNN) based approaches have been widely investigated and deployed in medical image analysis. For example, fully convolutional neural networks (FCN) achieve the state-of-the-art performance in several applications of 2D/3D medical image segmentation. Even the baseline neural network models (U-Net, V-Net, etc.) have been proven to be very effective and efficient when the training process is set up properly. Nevertheless, to fully exploit the potentials of neural networks, we propose an automated searching approach for the optimal training strategy with reinforcement learning. The proposed approach can be utilized for tuning hyper-parameters, and selecting necessary data augmentation with certain probabilities. The proposed approach is validated on several tasks of 3D medical image segmentation. The performance of the baseline model is boosted after searching, and it can achieve comparable accuracy to other manually-tuned state-of-the-art segmentation approaches.
* 9 pages, 1 figures
Enhancing Foreground Boundaries for Medical Image Segmentation
May 29, 2020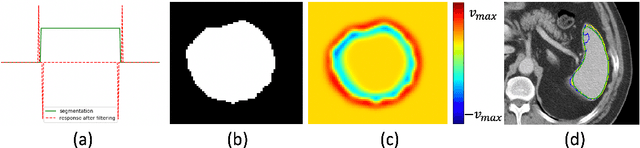

Object segmentation plays an important role in the modern medical image analysis, which benefits clinical study, disease diagnosis, and surgery planning. Given the various modalities of medical images, the automated or semi-automated segmentation approaches have been used to identify and parse organs, bones, tumors, and other regions-of-interest (ROI). However, these contemporary segmentation approaches tend to fail to predict the boundary areas of ROI, because of the fuzzy appearance contrast caused during the imaging procedure. To further improve the segmentation quality of boundary areas, we propose a boundary enhancement loss to enforce additional constraints on optimizing machine learning models. The proposed loss function is light-weighted and easy to implement without any pre- or post-processing. Our experimental results validate that our loss function are better than, or at least comparable to, other state-of-the-art loss functions in terms of segmentation accuracy.