 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DNeX: Feed-Forward 4D Generative Modeling Made Easy
Aug 18, 2025



We present 4DNeX, the first feed-forward framework for generating 4D (i.e., dynamic 3D) scene representations from a single image. In contrast to existing methods that rely on computationally intensive optimization or require multi-frame video inputs, 4DNeX enables efficient, end-to-end image-to-4D generation by fine-tuning a pretrained video diffusion model. Specifically, 1) to alleviate the scarcity of 4D data, we construct 4DNeX-10M, a large-scale dataset with high-quality 4D annotations generated using advanced reconstruction approaches. 2) we introduce a unified 6D video representation that jointly models RGB and XYZ sequences, facilitating structured learning of both appearance and geometry. 3) we propose a set of simple yet effective adaptation strategies to repurpose pretrained video diffusion models for 4D modeling. 4DNeX produces high-quality dynamic point clouds that enable novel-view video synthesis. Extensive experiments demonstrate that 4DNeX outperforms existing 4D generation methods in efficiency and generalizability, offering a scalable solution for image-to-4D modeling and laying the foundation for generative 4D world models that simulate dynamic scene evolution.
Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
Jul 08, 2025As language agents tackle increasingly complex tasks, they struggle with effective error correction and experience reuse across domains. We introduce Agent KB, a hierarchical experience framework that enables complex agentic problem solving via a novel Reason-Retrieve-Refine pipeline. Agent KB addresses a core limitation: agents traditionally cannot learn from each other's experiences. By capturing both high-level strategies and detailed execution logs, Agent KB creates a shared knowledge base that enables cross-agent knowledge transfer. Evaluated on the GAIA benchmark, Agent KB improves success rates by up to 16.28 percentage points. On the most challenging tasks, Claude-3 improves from 38.46% to 57.69%, while GPT-4 improves from 53.49% to 73.26% on intermediate tasks. On SWE-bench code repair, Agent KB enables Claude-3 to improve from 41.33% to 53.33%. Our results suggest that Agent KB provides a modular, framework-agnostic infrastructure for enabling agents to learn from past experiences and generalize successful strategies to new tasks.
TAG-INSTRUCT: Controlled Instruction Complexity Enhancement through Structure-based Augmentation
May 24, 2025High-quality instruction data is crucial for developing large language models (LLMs), yet existing approaches struggle to effectively control instruction complexity. We present TAG-INSTRUCT, a novel framework that enhances instruction complexity through structured semantic compression and controlled difficulty augmentation. Unlike previous prompt-based methods operating on raw text, TAG-INSTRUCT compresses instructions into a compact tag space and systematically enhances complexity through RL-guided tag expansion. Through extensive experiments, we show that TAG-INSTRUCT outperforms existing instruction complexity augmentation approaches. Our analysis reveals that operating in tag space provides superior controllability and stability across different instruction synthesis frameworks.
PlanGPT-VL: Enhancing Urban Planning with Domain-Specific Vision-Language Models
May 21, 2025In the field of urban planning, existing Vision-Language Models (VLMs) frequently fail to effectively analyze and evaluate planning maps, despite the critical importance of these visual elements for urban planners and related educational contexts. Planning maps, which visualize land use, infrastructure layouts, and functional zoning, require specialized understanding of spatial configurations, regulatory requirements, and multi-scale analysis. To address this challenge, we introduce PlanGPT-VL, the first domain-specific Vision-Language Model tailored specifically for urban planning maps. PlanGPT-VL employs three innovative approaches: (1) PlanAnno-V framework for high-quality VQA data synthesis, (2) Critical Point Thinking to reduce hallucinations through structured verification, and (3) comprehensive training methodology combining Supervised Fine-Tuning with frozen vision encoder parameters. Through systematic evaluation on our proposed PlanBench-V benchmark, we demonstrate that PlanGPT-VL significantly outperforms general-purpose state-of-the-art VLMs in specialized planning map interpretation tasks, offering urban planning professionals a reliable tool for map analysis, assessment, and educational applications while maintaining high factual accuracy. Our lightweight 7B parameter model achieves comparable performance to models exceeding 72B parameters, demonstrating efficient domain specialization without sacrificing performance.
Retrieval-augmented in-context learning for multimodal large language models in disease classification
May 04, 2025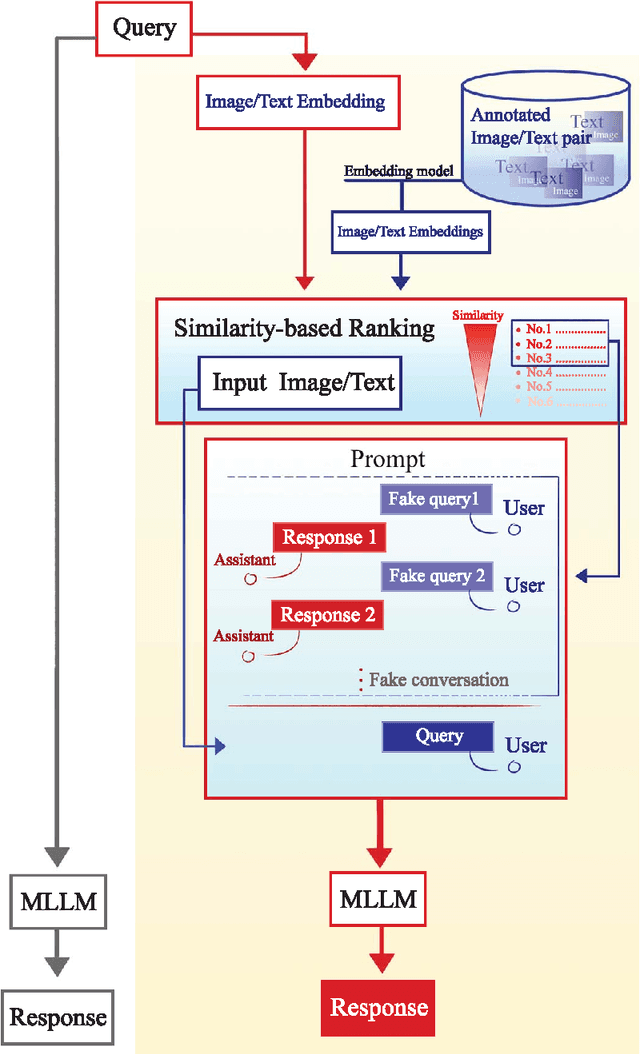
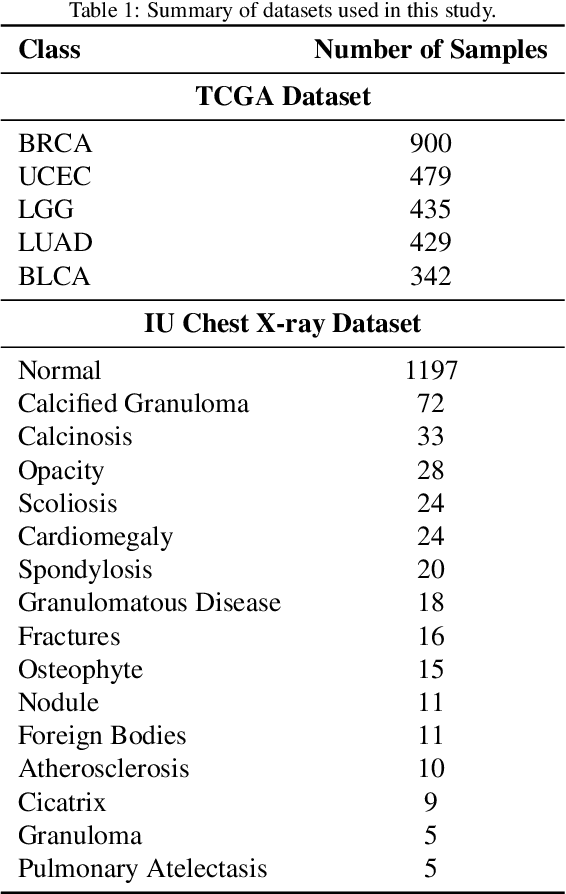
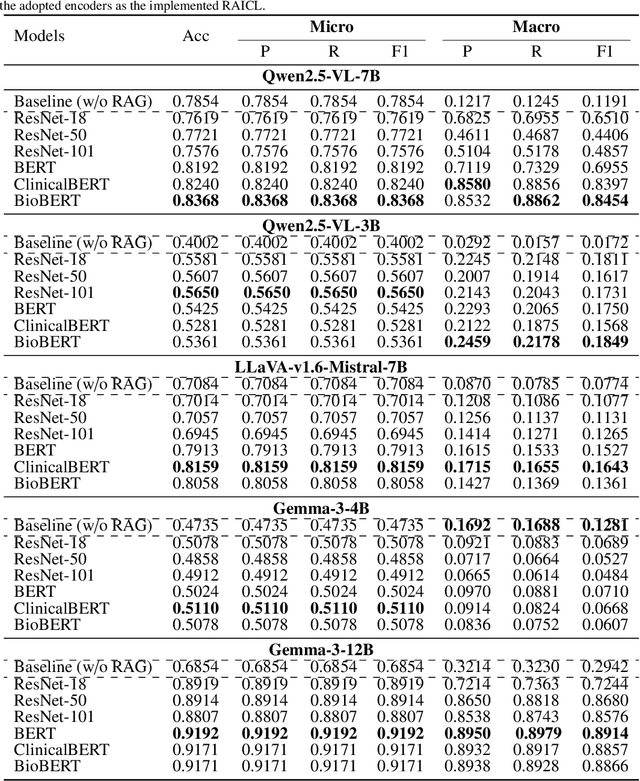
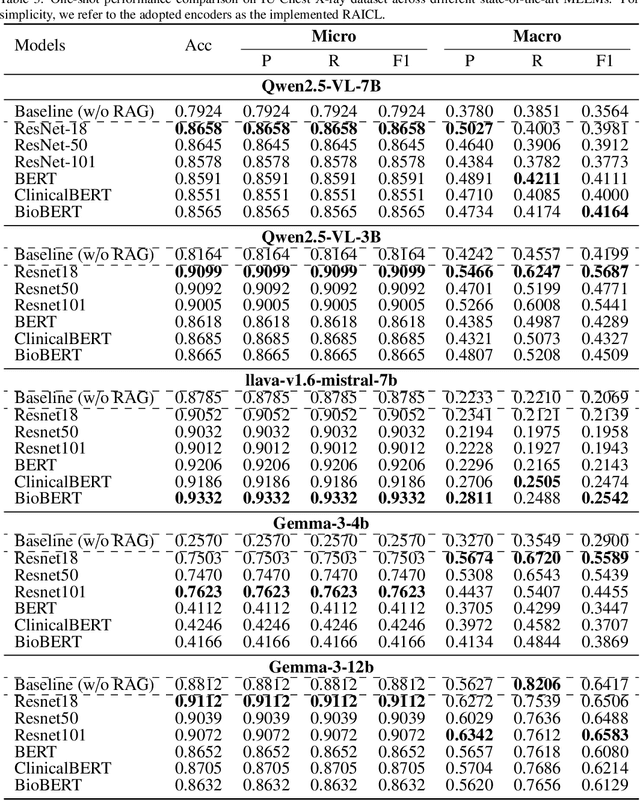
Objectives: We aim to dynamically retrieve informative demonstrations, enhancing in-context learning in multimodal large language models (MLLMs) for disease classification. Methods: We propose a Retrieval-Augmented In-Context Learning (RAICL) framework, which integrates retrieval-augmented generation (RAG) and in-context learning (ICL) to adaptively select demonstrations with similar disease patterns, enabling more effective ICL in MLLMs. Specifically, RAICL examines embeddings from diverse encoders, including ResNet, BERT, BioBERT, and ClinicalBERT, to retrieve appropriate demonstrations, and constructs conversational prompts optimized for ICL. We evaluated the framework on two real-world multi-modal datasets (TCGA and IU Chest X-ray), assessing its performance across multiple MLLMs (Qwen, Llava, Gemma), embedding strategies, similarity metrics, and varying numbers of demonstrations. Results: RAICL consistently improved classification performance. Accuracy increased from 0.7854 to 0.8368 on TCGA and from 0.7924 to 0.8658 on IU Chest X-ray. Multi-modal inputs outperformed single-modal ones, with text-only inputs being stronger than images alone. The richness of information embedded in each modality will determine which embedding model can be used to get better results. Few-shot experiments showed that increasing the number of retrieved examples further enhanced performance. Across different similarity metrics, Euclidean distance achieved the highest accuracy while cosine similarity yielded better macro-F1 scores. RAICL demonstrated consistent improvements across various MLLMs, confirming its robustness and versatility. Conclusions: RAICL provides an efficient and scalable approach to enhance in-context learning in MLLMs for multimodal disease classification.
FMLGS: Fast Multilevel Language Embedded Gaussians for Part-level Interactive Agents
Apr 11, 2025The semantically interactive radiance field has long been a promising backbone for 3D real-world applications, such as embodied AI to achieve scene understanding and manipulation. However, multi-granularity interaction remains a challenging task due to the ambiguity of language and degraded quality when it comes to queries upon object components. In this work, we present FMLGS, an approach that supports part-level open-vocabulary query within 3D Gaussian Splatting (3DGS). We propose an efficient pipeline for building and querying consistent object- and part-level semantics based on Segment Anything Model 2 (SAM2). We designed a semantic deviation strategy to solve the problem of language ambiguity among object parts, which interpolates the semantic features of fine-grained targets for enriched information. Once trained, we can query both objects and their describable parts using natural language. Comparisons with other state-of-the-art methods prove that our method can not only better locate specified part-level targets, but also achieve first-place performance concerning both speed and accuracy, where FMLGS is 98 x faster than LERF, 4 x faster than LangSplat and 2.5 x faster than LEGaussians. Meanwhile, we further integrate FMLGS as a virtual agent that can interactively navigate through 3D scenes, locate targets, and respond to user demands through a chat interface, which demonstrates the potential of our work to be further expanded and applied in the future.
Grounding 3D Object Affordance with Language Instructions, Visual Observations and Interactions
Apr 07, 2025



Grounding 3D object affordance is a task that locates objects in 3D space where they can be manipulated, which links perception and action for embodied intelligence. For example, for an intelligent robot, it is necessary to accurately ground the affordance of an object and grasp it according to human instructions. In this paper, we introduce a novel task that grounds 3D object affordance based on language instructions, visual observations and interactions, which is inspired by cognitive science. We collect an Affordance Grounding dataset with Points, Images and Language instructions (AGPIL) to support the proposed task. In the 3D physical world, due to observation orientation, object rotation, or spatial occlusion, we can only get a partial observation of the object. So this dataset includes affordance estimations of objects from full-view, partial-view, and rotation-view perspectives. To accomplish this task, we propose LMAffordance3D, the first multi-modal, language-guided 3D affordance grounding network, which applies a vision-language model to fuse 2D and 3D spatial features with semantic features. Comprehensive experiments on AGPIL demonstrate the effectiveness and superiority of our method on this task, even in unseen experimental settings. Our project is available at https://sites.google.com/view/lmaffordance3d.
Multi-view Reconstruction via SfM-guided Monocular Depth Estimation
Mar 18, 2025In this paper, we present a new method for multi-view geometric reconstruction. In recent years, large vision models have rapidly developed, performing excellently across various tasks and demonstrating remarkable generalization capabilities. Some works use large vision models for monocular depth estimation, which have been applied to facilitate multi-view reconstruction tasks in an indirect manner. Due to the ambiguity of the monocular depth estimation task, the estimated depth values are usually not accurate enough, limiting their utility in aiding multi-view reconstruction. We propose to incorporate SfM information, a strong multi-view prior, into the depth estimation process, thus enhancing the quality of depth prediction and enabling their direct application in multi-view geometric reconstruction. Experimental results on public real-world datasets show that our method significantly improves the quality of depth estimation compared to previous monocular depth estimation works. Additionally, we evaluate the reconstruction quality of our approach in various types of scenes including indoor, streetscape, and aerial views, surpassing state-of-the-art MVS methods. The code and supplementary materials are available at https://zju3dv.github.io/murre/ .
Structural Entropy Guided Unsupervised Graph Out-Of-Distribution Detection
Mar 05, 2025With the emerging of huge amount of unlabeled data, unsupervised out-of-distribution (OOD) detection is vital for ensuring the reliability of graph neural networks (GNNs) by identifying OOD samples from in-distribution (ID) ones during testing, where encountering novel or unknown data is inevitable. Existing methods often suffer from compromised performance due to redundant information in graph structures, which impairs their ability to effectively differentiate between ID and OOD data. To address this challenge, we propose SEGO, an unsupervised framework that integrates structural entropy into OOD detection regarding graph classification. Specifically, within the architecture of contrastive learning, SEGO introduces an anchor view in the form of coding tree by minimizing structural entropy. The obtained coding tree effectively removes redundant information from graphs while preserving essential structural information, enabling the capture of distinct graph patterns between ID and OOD samples. Furthermore, we present a multi-grained contrastive learning scheme at local, global, and tree levels using triplet views, where coding trees with essential information serve as the anchor view. Extensive experiments on real-world datasets validate the effectiveness of SEGO, demonstrating superior performance over state-of-the-art baselines in OOD detection. Specifically, our method achieves the best performance on 9 out of 10 dataset pairs, with an average improvement of 3.7\% on OOD detection datasets, significantly surpassing the best competitor by 10.8\% on the FreeSolv/ToxCast dataset pair.
LayAlign: Enhancing Multilingual Reasoning in Large Language Models via Layer-Wise Adaptive Fusion and Alignment Strategy
Feb 17, 2025



Despite being pretrained on multilingual corpora, large language models (LLMs) exhibit suboptimal performance on low-resource languages. Recent approaches have leveraged multilingual encoders alongside LLMs by introducing trainable parameters connecting the two models. However, these methods typically focus on the encoder's output, overlooking valuable information from other layers. We propose \aname (\mname), a framework that integrates representations from all encoder layers, coupled with the \attaname mechanism to enable layer-wise interaction between the LLM and the multilingual encoder. Extensive experiments on multilingual reasoning tasks, along with analyses of learned representations, show that our approach consistently outperforms existing baselines.