 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondensing Graphs via One-Step Gradient Matching
Jun 15, 2022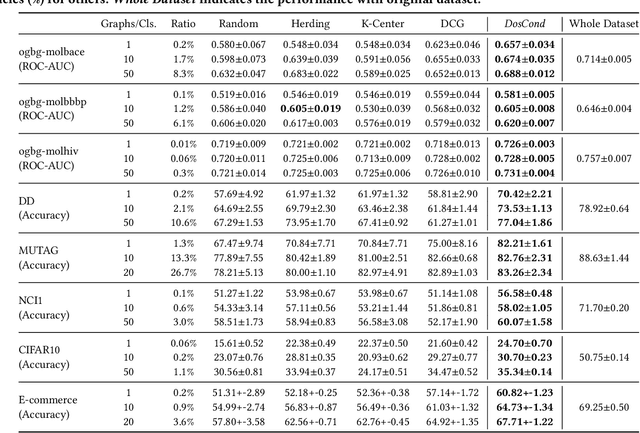
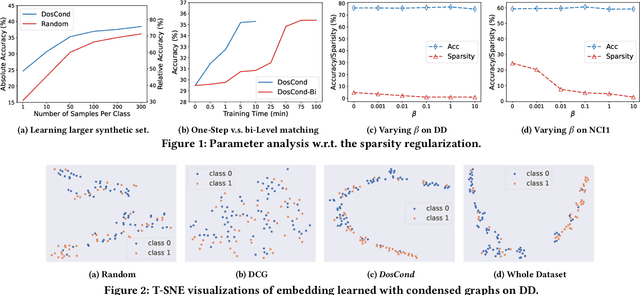
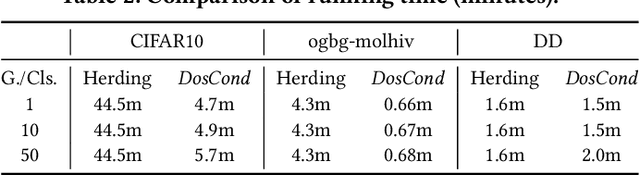
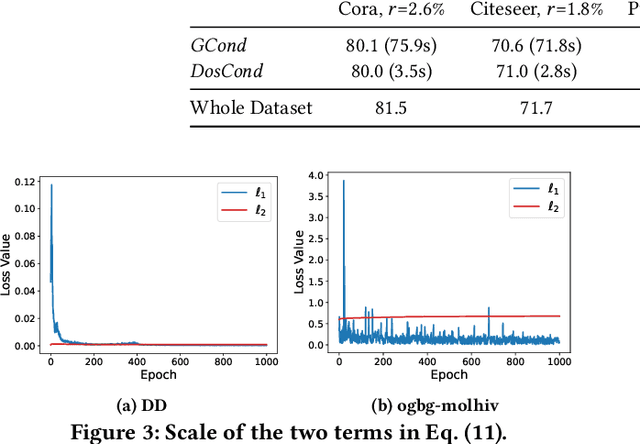
As training deep learning models on large dataset takes a lot of time and resources, it is desired to construct a small synthetic dataset with which we can train deep learning models sufficiently. There are recent works that have explored solutions on condensing image datasets through complex bi-level optimization. For instance, dataset condensation (DC) matches network gradients w.r.t. large-real data and small-synthetic data, where the network weights are optimized for multiple steps at each outer iteration. However, existing approaches have their inherent limitations: (1) they are not directly applicable to graphs where the data is discrete; and (2) the condensation process is computationally expensive due to the involved nested optimization. To bridge the gap, we investigate efficient dataset condensation tailored for graph datasets where we model the discrete graph structure as a probabilistic model. We further propose a one-step gradient matching scheme, which performs gradient matching for only one single step without training the network weights. Our theoretical analysis shows this strategy can generate synthetic graphs that lead to lower classification loss on real graphs. Extensive experiments on various graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, we are able to reduce the dataset size by 90% while approximating up to 98% of the original performance and our method is significantly faster than multi-step gradient matching (e.g. 15x in CIFAR10 for synthesizing 500 graphs).
SeqZero: Few-shot Compositional Semantic Parsing with Sequential Prompts and Zero-shot Models
May 15, 2022
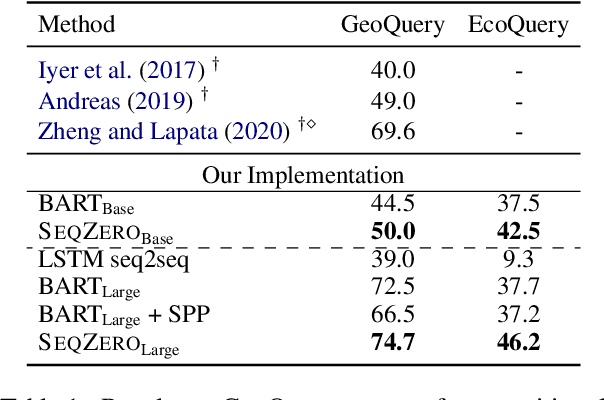

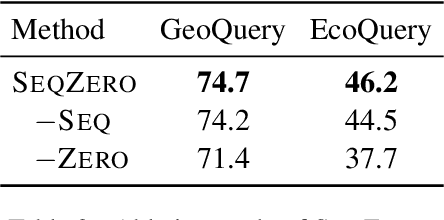
Recent research showed promising results on combining pretrained language models (LMs) with canonical utterance for few-shot semantic parsing. The canonical utterance is often lengthy and complex due to the compositional structure of formal languages. Learning to generate such canonical utterance requires significant amount of data to reach high performance. Fine-tuning with only few-shot samples, the LMs can easily forget pretrained knowledge, overfit spurious biases, and suffer from compositionally out-of-distribution generalization errors. To tackle these issues, we propose a novel few-shot semantic parsing method -- SeqZero. SeqZero decomposes the problem into a sequence of sub-problems, which correspond to the sub-clauses of the formal language. Based on the decomposition, the LMs only need to generate short answers using prompts for predicting sub-clauses. Thus, SeqZero avoids generating a long canonical utterance at once. Moreover, SeqZero employs not only a few-shot model but also a zero-shot model to alleviate the overfitting. In particular, SeqZero brings out the merits from both models via ensemble equipped with our proposed constrained rescaling. SeqZero achieves SOTA performance of BART-based models on GeoQuery and EcommerceQuery, which are two few-shot datasets with compositional data split.
Multilingual Knowledge Graph Completion with Self-Supervised Adaptive Graph Alignment
Mar 28, 2022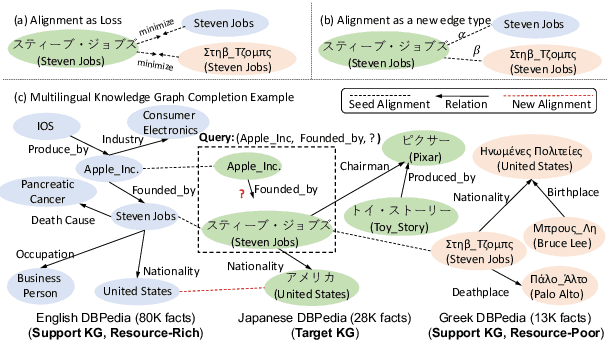
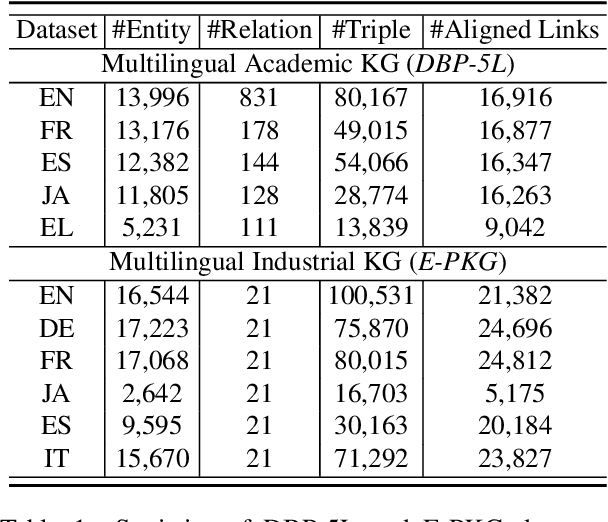
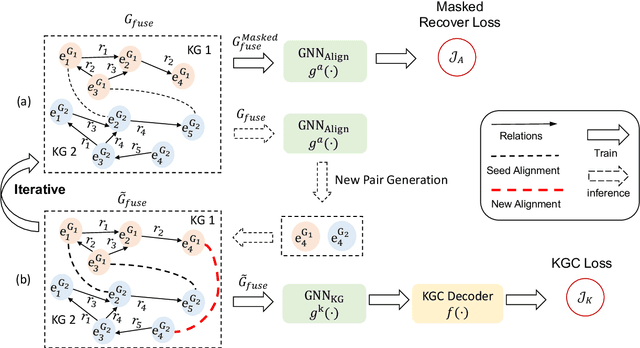
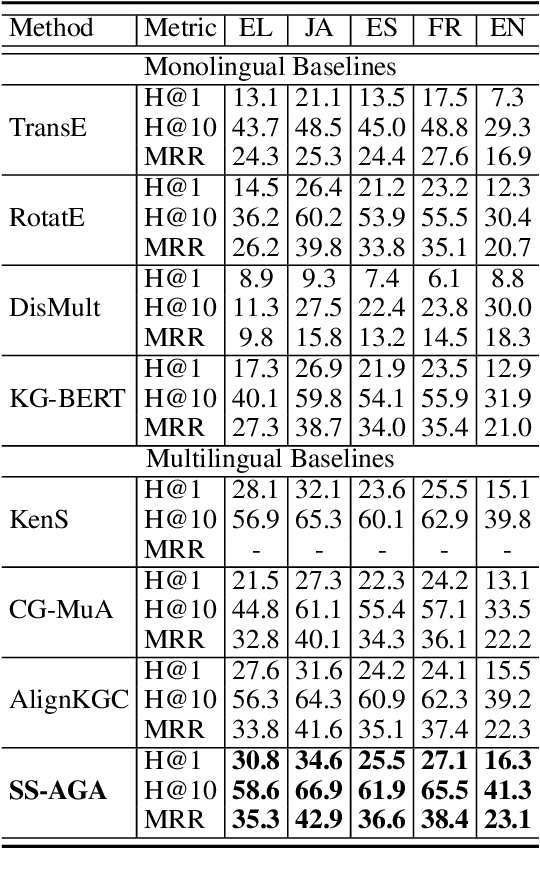
Predicting missing facts in a knowledge graph (KG) is crucial as modern KGs are far from complete. Due to labor-intensive human labeling, this phenomenon deteriorates when handling knowledge represented in various languages. In this paper, we explore multilingual KG completion, which leverages limited seed alignment as a bridge, to embrace the collective knowledge from multiple languages. However, language alignment used in prior works is still not fully exploited: (1) alignment pairs are treated equally to maximally push parallel entities to be close, which ignores KG capacity inconsistency; (2) seed alignment is scarce and new alignment identification is usually in a noisily unsupervised manner. To tackle these issues, we propose a novel self-supervised adaptive graph alignment (SS-AGA) method. Specifically, SS-AGA fuses all KGs as a whole graph by regarding alignment as a new edge type. As such, information propagation and noise influence across KGs can be adaptively controlled via relation-aware attention weights. Meanwhile, SS-AGA features a new pair generator that dynamically captures potential alignment pairs in a self-supervised paradigm. Extensive experiments on both the public multilingual DBPedia KG and newly-created industrial multilingual E-commerce KG empirically demonstrate the effectiveness of SS-AG
No Parameters Left Behind: Sensitivity Guided Adaptive Learning Rate for Training Large Transformer Models
Feb 14, 2022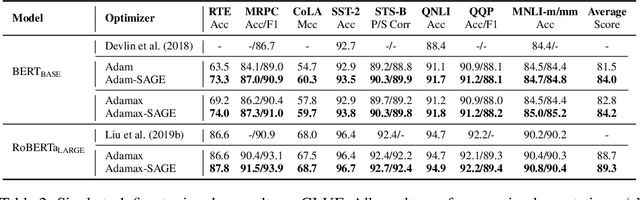
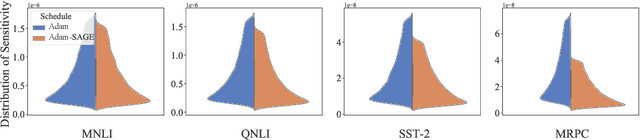

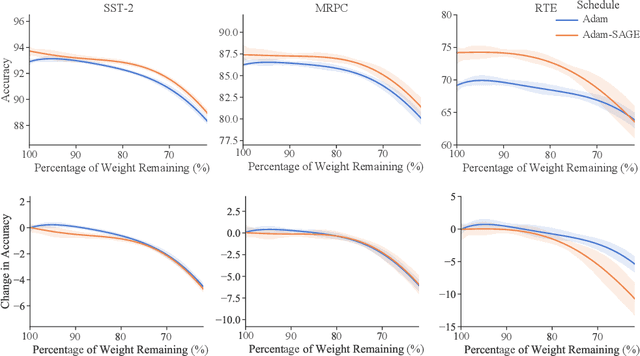
Recent research has shown the existence of significant redundancy in large Transformer models. One can prune the redundant parameters without significantly sacrificing the generalization performance. However, we question whether the redundant parameters could have contributed more if they were properly trained. To answer this question, we propose a novel training strategy that encourages all parameters to be trained sufficiently. Specifically, we adaptively adjust the learning rate for each parameter according to its sensitivity, a robust gradient-based measure reflecting this parameter's contribution to the model performance. A parameter with low sensitivity is redundant, and we improve its fitting by increasing its learning rate. In contrast, a parameter with high sensitivity is well-trained, and we regularize it by decreasing its learning rate to prevent further overfitting. We conduct extensive experiments on natural language understanding, neural machine translation, and image classification to demonstrate the effectiveness of the proposed schedule. Analysis shows that the proposed schedule indeed reduces the redundancy and improves generalization performance.
Self-Training with Differentiable Teacher
Sep 15, 2021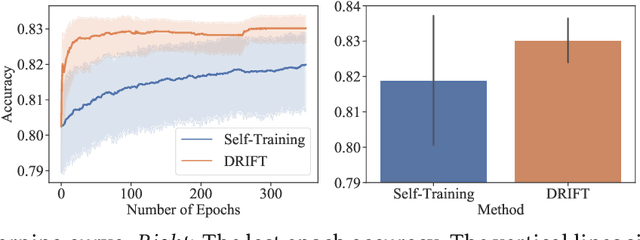
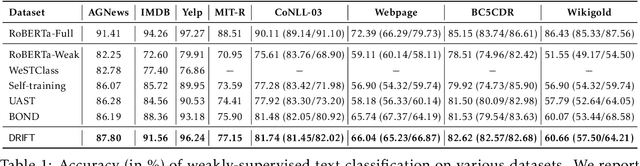
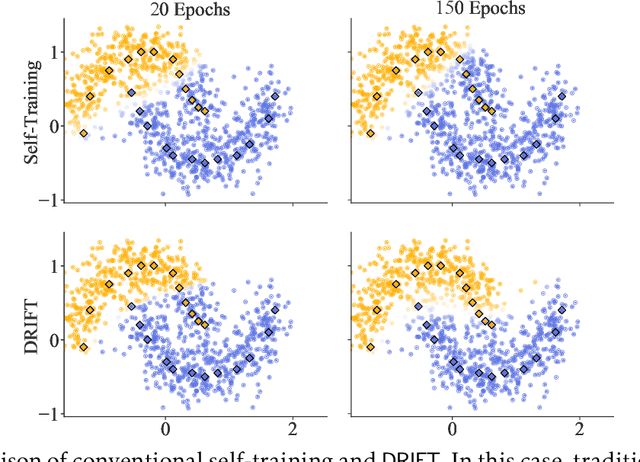
Self-training achieves enormous success in various semi-supervised and weakly-supervised learning tasks. The method can be interpreted as a teacher-student framework, where the teacher generates pseudo-labels, and the student makes predictions. The two models are updated alternatingly. However, such a straightforward alternating update rule leads to training instability. This is because a small change in the teacher may result in a significant change in the student. To address this issue, we propose {\ours}, short for differentiable self-training, that treats teacher-student as a Stackelberg game. In this game, a leader is always in a more advantageous position than a follower. In self-training, the student contributes to the prediction performance, and the teacher controls the training process by generating pseudo-labels. Therefore, we treat the student as the leader and the teacher as the follower. The leader procures its advantage by acknowledging the follower's strategy, which involves differentiable pseudo-labels and differentiable sample weights. Consequently, the leader-follower interaction can be effectively captured via Stackelberg gradient, obtained by differentiating the follower's strategy. Experimental results on semi- and weakly-supervised classification and named entity recognition tasks show that our model outperforms existing approaches by large margins.
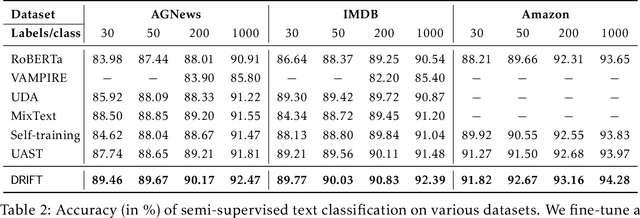
ARCH: Efficient Adversarial Regularized Training with Caching
Sep 15, 2021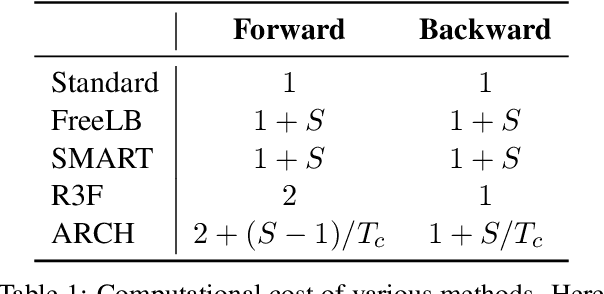
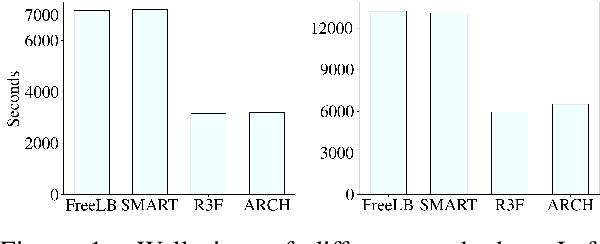
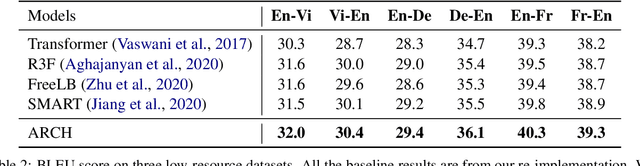
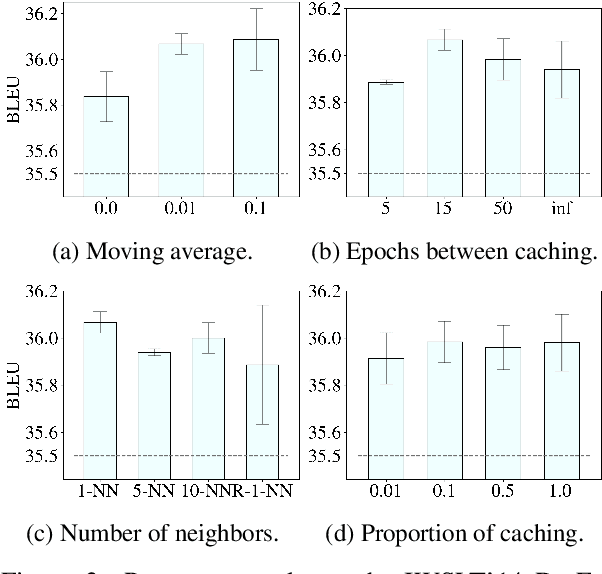
Adversarial regularization can improve model generalization in many natural language processing tasks. However, conventional approaches are computationally expensive since they need to generate a perturbation for each sample in each epoch. We propose a new adversarial regularization method ARCH (adversarial regularization with caching), where perturbations are generated and cached once every several epochs. As caching all the perturbations imposes memory usage concerns, we adopt a K-nearest neighbors-based strategy to tackle this issue. The strategy only requires caching a small amount of perturbations, without introducing additional training time. We evaluate our proposed method on a set of neural machine translation and natural language understanding tasks. We observe that ARCH significantly eases the computational burden (saves up to 70\% of computational time in comparison with conventional approaches). More surprisingly, by reducing the variance of stochastic gradients, ARCH produces a notably better (in most of the tasks) or comparable model generalization. Our code is publicly available.
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Jun 16, 2021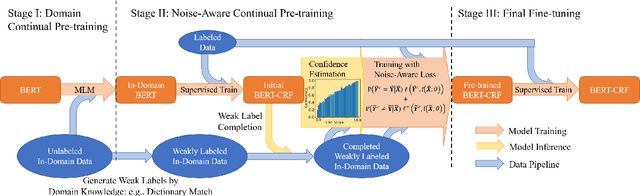
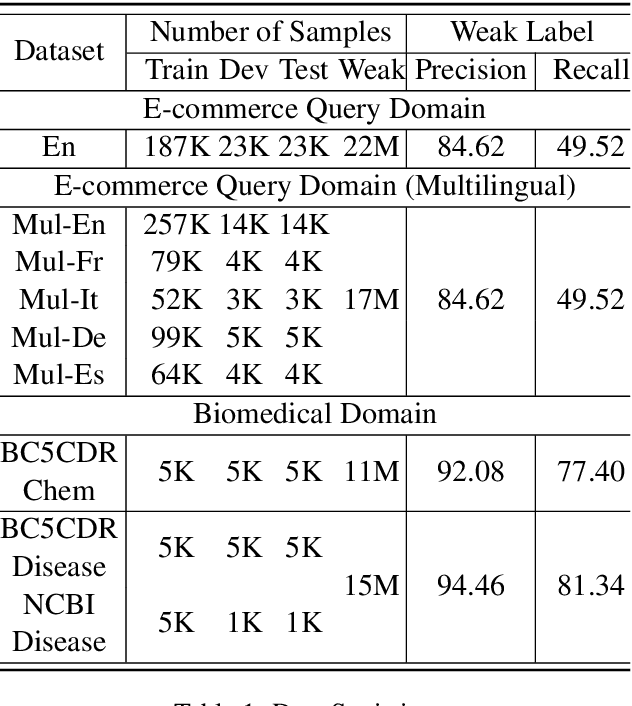
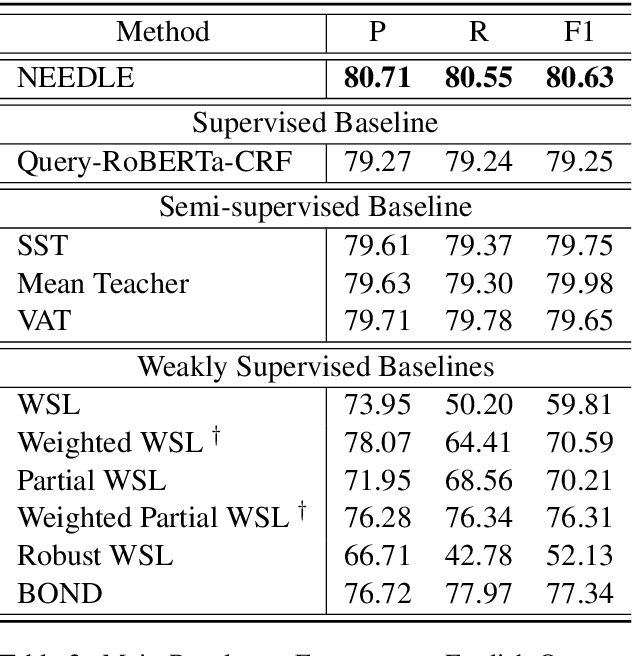
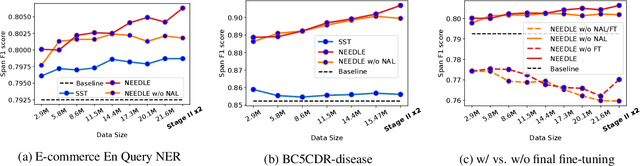
Weak supervision has shown promising results in many natural language processing tasks, such as Named Entity Recognition (NER). Existing work mainly focuses on learning deep NER models only with weak supervision, i.e., without any human annotation, and shows that by merely using weakly labeled data, one can achieve good performance, though still underperforms fully supervised NER with manually/strongly labeled data. In this paper, we consider a more practical scenario, where we have both a small amount of strongly labeled data and a large amount of weakly labeled data. Unfortunately, we observe that weakly labeled data does not necessarily improve, or even deteriorate the model performance (due to the extensive noise in the weak labels) when we train deep NER models over a simple or weighted combination of the strongly labeled and weakly labeled data. To address this issue, we propose a new multi-stage computational framework -- NEEDLE with three essential ingredients: (1) weak label completion, (2) noise-aware loss function, and (3) final fine-tuning over the strongly labeled data. Through experiments on E-commerce query NER and Biomedical NER, we demonstrate that NEEDLE can effectively suppress the noise of the weak labels and outperforms existing methods. In particular, we achieve new SOTA F1-scores on 3 Biomedical NER datasets: BC5CDR-chem 93.74, BC5CDR-disease 90.69, NCBI-disease 92.28.
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization
Jun 08, 2021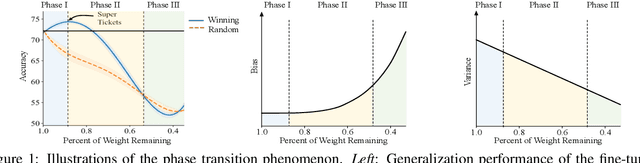


The Lottery Ticket Hypothesis suggests that an over-parametrized network consists of ``lottery tickets'', and training a certain collection of them (i.e., a subnetwork) can match the performance of the full model. In this paper, we study such a collection of tickets, which is referred to as ``winning tickets'', in extremely over-parametrized models, e.g., pre-trained language models. We observe that at certain compression ratios, the generalization performance of the winning tickets can not only match but also exceed that of the full model. In particular, we observe a phase transition phenomenon: As the compression ratio increases, generalization performance of the winning tickets first improves then deteriorates after a certain threshold. We refer to the tickets on the threshold as ``super tickets''. We further show that the phase transition is task and model dependent -- as the model size becomes larger and the training data set becomes smaller, the transition becomes more pronounced. Our experiments on the GLUE benchmark show that the super tickets improve single task fine-tuning by $0.9$ points on BERT-base and $1.0$ points on BERT-large, in terms of task-average score. We also demonstrate that adaptively sharing the super tickets across tasks benefits multi-task learning.
Adversarial Training as Stackelberg Game: An Unrolled Optimization Approach
Apr 11, 2021
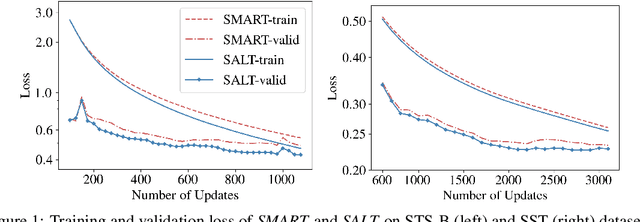
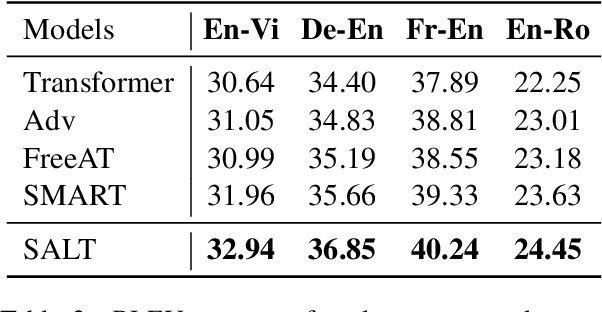
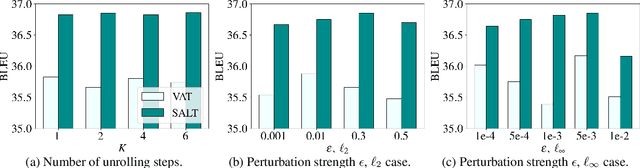
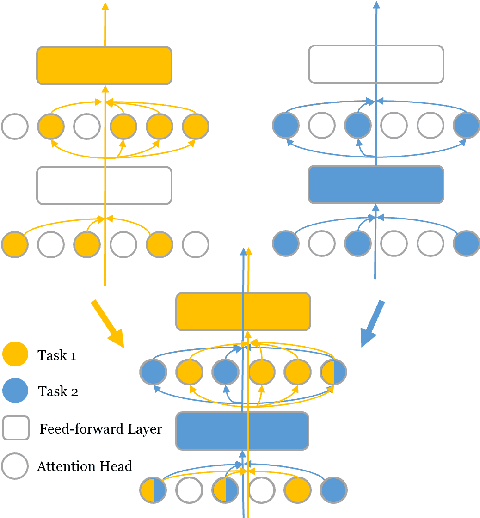
Adversarial training has been shown to improve the generalization performance of deep learning models in various natural language processing tasks. Existing works usually formulate adversarial training as a zero-sum game, which is solved by alternating gradient descent/ascent algorithms. Such a formulation treats the adversarial and the defending players equally, which is undesirable because only the defending player contributes to the generalization performance. To address this issue, we propose Stackelberg Adversarial Training (SALT), which formulates adversarial training as a Stackelberg game. This formulation induces a competition between a leader and a follower, where the follower generates perturbations, and the leader trains the model subject to the perturbations. Different from conventional adversarial training, in SALT, the leader is in an advantageous position. When the leader moves, it recognizes the strategy of the follower and takes the anticipated follower's outcomes into consideration. Such a leader's advantage enables us to improve the model fitting to the unperturbed data. The leader's strategic information is captured by the Stackelberg gradient, which is obtained using an unrolling algorithm. Our experimental results on a set of machine translation and natural language understanding tasks show that SALT outperforms existing adversarial training baselines across all tasks.
Token-wise Curriculum Learning for Neural Machine Translation
Mar 20, 2021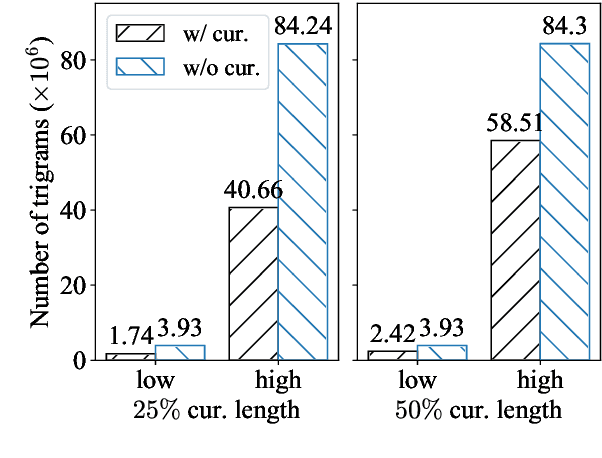
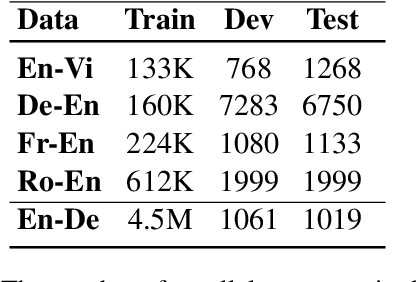
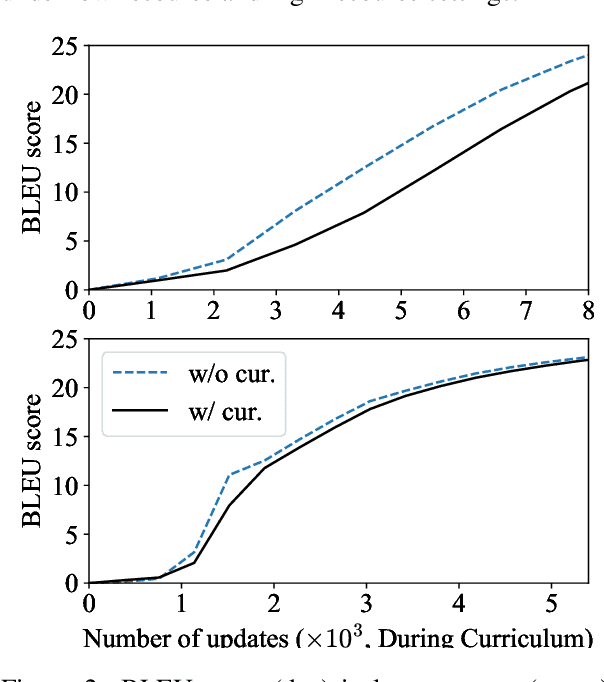
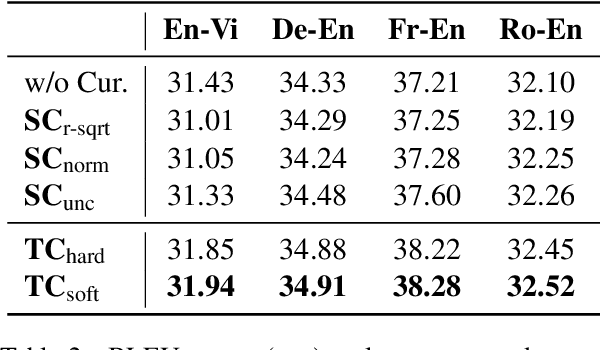
Existing curriculum learning approaches to Neural Machine Translation (NMT) require sampling sufficient amounts of "easy" samples from training data at the early training stage. This is not always achievable for low-resource languages where the amount of training data is limited. To address such limitation, we propose a novel token-wise curriculum learning approach that creates sufficient amounts of easy samples. Specifically, the model learns to predict a short sub-sequence from the beginning part of each target sentence at the early stage of training, and then the sub-sequence is gradually expanded as the training progresses. Such a new curriculum design is inspired by the cumulative effect of translation errors, which makes the latter tokens more difficult to predict than the beginning ones. Extensive experiments show that our approach can consistently outperform baselines on 5 language pairs, especially for low-resource languages. Combining our approach with sentence-level methods further improves the performance on high-resource languages.