 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025



Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models
Dec 16, 2025



Click-Through Rate (CTR) prediction, a core task in recommendation systems, aims to estimate the probability of users clicking on items. Existing models predominantly follow a discriminative paradigm, which relies heavily on explicit interactions between raw ID embeddings. However, this paradigm inherently renders them susceptible to two critical issues: embedding dimensional collapse and information redundancy, stemming from the over-reliance on feature interactions \emph{over raw ID embeddings}. To address these limitations, we propose a novel \emph{Supervised Feature Generation (SFG)} framework, \emph{shifting the paradigm from discriminative ``feature interaction" to generative ``feature generation"}. Specifically, SFG comprises two key components: an \emph{Encoder} that constructs hidden embeddings for each feature, and a \emph{Decoder} tasked with regenerating the feature embeddings of all features from these hidden representations. Unlike existing generative approaches that adopt self-supervised losses, we introduce a supervised loss to utilize the supervised signal, \ie, click or not, in the CTR prediction task. This framework exhibits strong generalizability: it can be seamlessly integrated with most existing CTR models, reformulating them under the generative paradigm. Extensive experiments demonstrate that SFG consistently mitigates embedding collapse and reduces information redundancy, while yielding substantial performance gains across various datasets and base models. The code is available at https://github.com/USTC-StarTeam/GE4Rec.
Building from Scratch: A Multi-Agent Framework with Human-in-the-Loop for Multilingual Legal Terminology Mapping
Dec 15, 2025Accurately mapping legal terminology across languages remains a significant challenge, especially for language pairs like Chinese and Japanese, which share a large number of homographs with different meanings. Existing resources and standardized tools for these languages are limited. To address this, we propose a human-AI collaborative approach for building a multilingual legal terminology database, based on a multi-agent framework. This approach integrates advanced large language models and legal domain experts throughout the entire process-from raw document preprocessing, article-level alignment, to terminology extraction, mapping, and quality assurance. Unlike a single automated pipeline, our approach places greater emphasis on how human experts participate in this multi-agent system. Humans and AI agents take on different roles: AI agents handle specific, repetitive tasks, such as OCR, text segmentation, semantic alignment, and initial terminology extraction, while human experts provide crucial oversight, review, and supervise the outputs with contextual knowledge and legal judgment. We tested the effectiveness of this framework using a trilingual parallel corpus comprising 35 key Chinese statutes, along with their English and Japanese translations. The experimental results show that this human-in-the-loop, multi-agent workflow not only improves the precision and consistency of multilingual legal terminology mapping but also offers greater scalability compared to traditional manual methods.
Fast 2DGS: Efficient Image Representation with Deep Gaussian Prior
Dec 14, 2025



As generative models become increasingly capable of producing high-fidelity visual content, the demand for efficient, interpretable, and editable image representations has grown substantially. Recent advances in 2D Gaussian Splatting (2DGS) have emerged as a promising solution, offering explicit control, high interpretability, and real-time rendering capabilities (>1000 FPS). However, high-quality 2DGS typically requires post-optimization. Existing methods adopt random or heuristics (e.g., gradient maps), which are often insensitive to image complexity and lead to slow convergence (>10s). More recent approaches introduce learnable networks to predict initial Gaussian configurations, but at the cost of increased computational and architectural complexity. To bridge this gap, we present Fast-2DGS, a lightweight framework for efficient Gaussian image representation. Specifically, we introduce Deep Gaussian Prior, implemented as a conditional network to capture the spatial distribution of Gaussian primitives under different complexities. In addition, we propose an attribute regression network to predict dense Gaussian properties. Experiments demonstrate that this disentangled architecture achieves high-quality reconstruction in a single forward pass, followed by minimal fine-tuning. More importantly, our approach significantly reduces computational cost without compromising visual quality, bringing 2DGS closer to industry-ready deployment.
Breaking Expert Knowledge Limits: Self-Pruning for Large Language Models
Nov 19, 2025



Large language models (LLMs) have achieved remarkable performance on a wide range of tasks, hindering real-world deployment due to their massive size. Existing pruning methods (e.g., Wanda) tailored for LLMs rely heavily on manual design pruning algorithms, thereby leading to \textit{huge labor costs} and \textit{requires expert knowledge}. Furthermore, we are the first to identify the serious \textit{outlier value issue} behind dramatic performance degradation under high pruning ratios that are caused by uniform sparsity, raising an additional concern about how to design adaptive pruning sparsity ideal for LLMs. Can LLMs prune by themselves? In this work, we introduce an affirmative answer by proposing a novel pruning method called \textbf{AutoPrune}, which first overcomes expert knowledge limits by leveraging LLMs to design optimal pruning algorithms for themselves automatically without any expert knowledge. Specifically, to mitigate the black-box nature of LLMs, we propose a Graph-driven Chain-of-Thought (GCoT) to optimize prompts, significantly enhancing the reasoning process in learning the pruning algorithm and enabling us to generate pruning algorithms with superior performance and interpretability in the next generation. Finally, grounded in insights of outlier value issue, we introduce Skew-aware Dynamic Sparsity Allocation (SDSA) to overcome the outlier value issue, mitigating performance degradation under high pruning ratios. We conduct extensive experiments on mainstream LLMs benchmarks, demonstrating the superiority of AutoPrune, which consistently excels state-of-the-art competitors. The code is available at: https://anonymous.4open.science/r/AutoPrune.
iGaussian: Real-Time Camera Pose Estimation via Feed-Forward 3D Gaussian Splatting Inversion
Nov 18, 2025Recent trends in SLAM and visual navigation have embraced 3D Gaussians as the preferred scene representation, highlighting the importance of estimating camera poses from a single image using a pre-built Gaussian model. However, existing approaches typically rely on an iterative \textit{render-compare-refine} loop, where candidate views are first rendered using NeRF or Gaussian Splatting, then compared against the target image, and finally, discrepancies are used to update the pose. This multi-round process incurs significant computational overhead, hindering real-time performance in robotics. In this paper, we propose iGaussian, a two-stage feed-forward framework that achieves real-time camera pose estimation through direct 3D Gaussian inversion. Our method first regresses a coarse 6DoF pose using a Gaussian Scene Prior-based Pose Regression Network with spatial uniform sampling and guided attention mechanisms, then refines it through feature matching and multi-model fusion. The key contribution lies in our cross-correlation module that aligns image embeddings with 3D Gaussian attributes without differentiable rendering, coupled with a Weighted Multiview Predictor that fuses features from Multiple strategically sampled viewpoints. Experimental results on the NeRF Synthetic, Mip-NeRF 360, and T\&T+DB datasets demonstrate a significant performance improvement over previous methods, reducing median rotation errors to 0.2° while achieving 2.87 FPS tracking on mobile robots, which is an impressive 10 times speedup compared to optimization-based approaches. Code: https://github.com/pythongod-exe/iGaussian
MicroEvoEval: A Systematic Evaluation Framework for Image-Based Microstructure Evolution Prediction
Nov 18, 2025



Simulating microstructure evolution (MicroEvo) is vital for materials design but demands high numerical accuracy, efficiency, and physical fidelity. Although recent studies on deep learning (DL) offer a promising alternative to traditional solvers, the field lacks standardized benchmarks. Existing studies are flawed due to a lack of comparing specialized MicroEvo DL models with state-of-the-art spatio-temporal architectures, an overemphasis on numerical accuracy over physical fidelity, and a failure to analyze error propagation over time. To address these gaps, we introduce MicroEvoEval, the first comprehensive benchmark for image-based microstructure evolution prediction. We evaluate 14 models, encompassing both domain-specific and general-purpose architectures, across four representative MicroEvo tasks with datasets specifically structured for both short- and long-term assessment. Our multi-faceted evaluation framework goes beyond numerical accuracy and computational cost, incorporating a curated set of structure-preserving metrics to assess physical fidelity. Our extensive evaluations yield several key insights. Notably, we find that modern architectures (e.g., VMamba), not only achieve superior long-term stability and physical fidelity but also operate with an order-of-magnitude greater computational efficiency. The results highlight the necessity of holistic evaluation and identify these modern architectures as a highly promising direction for developing efficient and reliable surrogate models in data-driven materials science.
H-LDM: Hierarchical Latent Diffusion Models for Controllable and Interpretable PCG Synthesis from Clinical Metadata
Nov 18, 2025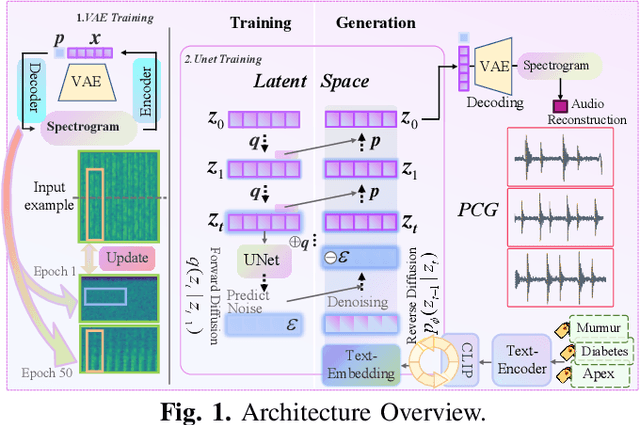
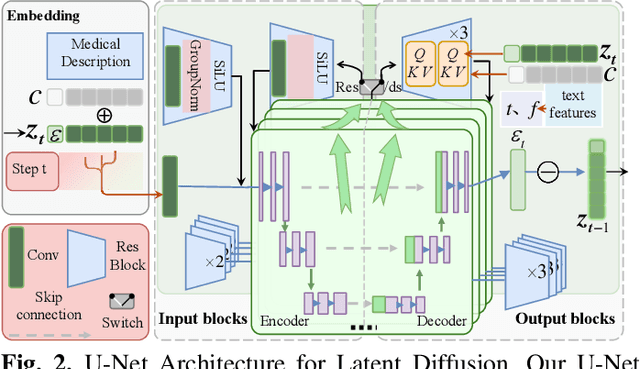
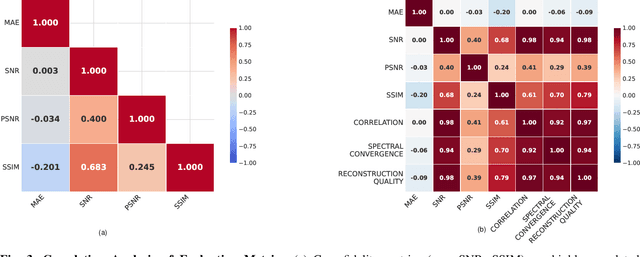
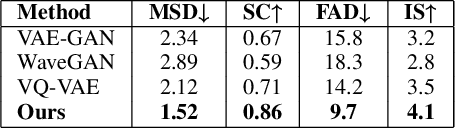
Phonocardiogram (PCG) analysis is vital for cardiovascular disease diagnosis, yet the scarcity of labeled pathological data hinders the capability of AI systems. To bridge this, we introduce H-LDM, a Hierarchical Latent Diffusion Model for generating clinically accurate and controllable PCG signals from structured metadata. Our approach features: (1) a multi-scale VAE that learns a physiologically-disentangled latent space, separating rhythm, heart sounds, and murmurs; (2) a hierarchical text-to-biosignal pipeline that leverages rich clinical metadata for fine-grained control over 17 distinct conditions; and (3) an interpretable diffusion process guided by a novel Medical Attention module. Experiments on the PhysioNet CirCor dataset demonstrate state-of-the-art performance, achieving a Fréchet Audio Distance of 9.7, a 92% attribute disentanglement score, and 87.1% clinical validity confirmed by cardiologists. Augmenting diagnostic models with our synthetic data improves the accuracy of rare disease classification by 11.3\%. H-LDM establishes a new direction for data augmentation in cardiac diagnostics, bridging data scarcity with interpretable clinical insights.
Beyond SELECT: A Comprehensive Taxonomy-Guided Benchmark for Real-World Text-to-SQL Translation
Nov 17, 2025Text-to-SQL datasets are essential for training and evaluating text-to-SQL models, but existing datasets often suffer from limited coverage and fail to capture the diversity of real-world applications. To address this, we propose a novel taxonomy for text-to-SQL classification based on dimensions including core intents, statement types, syntax structures, and key actions. Using this taxonomy, we evaluate widely used public text-to-SQL datasets (e.g., Spider and Bird) and reveal limitations in their coverage and diversity. We then introduce a taxonomy-guided dataset synthesis pipeline, yielding a new dataset named SQL-Synth. This approach combines the taxonomy with Large Language Models (LLMs) to ensure the dataset reflects the breadth and complexity of real-world text-to-SQL applications. Extensive analysis and experimental results validate the effectiveness of our taxonomy, as SQL-Synth exhibits greater diversity and coverage compared to existing benchmarks. Moreover, we uncover that existing LLMs typically fall short in adequately capturing the full range of scenarios, resulting in limited performance on SQL-Synth. However, fine-tuning can substantially improve their performance in these scenarios. The proposed taxonomy has significant potential impact, as it not only enables comprehensive analysis of datasets and the performance of different LLMs, but also guides the construction of training data for LLMs.
Center-Outward q-Dominance: A Sample-Computable Proxy for Strong Stochastic Dominance in Multi-Objective Optimisation
Nov 16, 2025



Stochastic multi-objective optimization (SMOOP) requires ranking multivariate distributions; yet, most empirical studies perform scalarization, which loses information and is unreliable. Based on the optimal transport theory, we introduce the center-outward q-dominance relation and prove it implies strong first-order stochastic dominance (FSD). Also, we develop an empirical test procedure based on q-dominance, and derive an explicit sample size threshold, $n^*(δ)$, to control the Type I error. We verify the usefulness of our approach in two scenarios: (1) as a ranking method in hyperparameter tuning; (2) as a selection method in multi-objective optimization algorithms. For the former, we analyze the final stochastic Pareto sets of seven multi-objective hyperparameter tuners on the YAHPO-MO benchmark tasks with q-dominance, which allows us to compare these tuners when the expected hypervolume indicator (HVI, the most common performance metric) of the Pareto sets becomes indistinguishable. For the latter, we replace the mean value-based selection in the NSGA-II algorithm with $q$-dominance, which shows a superior convergence rate on noise-augmented ZDT benchmark problems. These results establish center-outward q-dominance as a principled, tractable foundation for seeking truly stochastically dominant solutions for SMOOPs.