 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Single-Slice Segmentation with 3D-to-2D Unpaired Scan Distillation
Jun 18, 2024



2D single-slice abdominal computed tomography (CT) enables the assessment of body habitus and organ health with low radiation exposure. However, single-slice data necessitates the use of 2D networks for segmentation, but these networks often struggle to capture contextual information effectively. Consequently, even when trained on identical datasets, 3D networks typically achieve superior segmentation results. In this work, we propose a novel 3D-to-2D distillation framework, leveraging pre-trained 3D models to enhance 2D single-slice segmentation. Specifically, we extract the prediction distribution centroid from the 3D representations, to guide the 2D student by learning intra- and inter-class correlation. Unlike traditional knowledge distillation methods that require the same data input, our approach employs unpaired 3D CT scans with any contrast to guide the 2D student model. Experiments conducted on 707 subjects from the single-slice Baltimore Longitudinal Study of Aging (BLSA) dataset demonstrate that state-of-the-art 2D multi-organ segmentation methods can benefit from the 3D teacher model, achieving enhanced performance in single-slice multi-organ segmentation. Notably, our approach demonstrates considerable efficacy in low-data regimes, outperforming the model trained with all available training subjects even when utilizing only 200 training subjects. Thus, this work underscores the potential to alleviate manual annotation burdens.
Full-ECE: A Metric For Token-level Calibration on Large Language Models
Jun 17, 2024Deep Neural Networks (DNNs) excel in various domains but face challenges in providing accurate uncertainty estimates, which are crucial for high-stakes applications. Large Language Models (LLMs) have recently emerged as powerful tools, demonstrating exceptional performance in language tasks. However, traditional calibration metrics such as Expected Calibration Error (ECE) and classwise-ECE (cw-ECE) are inadequate for LLMs due to their vast vocabularies, data complexity, and distributional focus. To address this, we propose a novel calibration concept called full calibration and introduce its corresponding metric, Full-ECE. Full-ECE evaluates the entire predicted probability distribution, offering a more accurate and robust measure of calibration for LLMs.
Deconstructing The Ethics of Large Language Models from Long-standing Issues to New-emerging Dilemmas
Jun 08, 2024


Large Language Models (LLMs) have achieved unparalleled success across diverse language modeling tasks in recent years. However, this progress has also intensified ethical concerns, impacting the deployment of LLMs in everyday contexts. This paper provides a comprehensive survey of ethical challenges associated with LLMs, from longstanding issues such as copyright infringement, systematic bias, and data privacy, to emerging problems like truthfulness and social norms. We critically analyze existing research aimed at understanding, examining, and mitigating these ethical risks. Our survey underscores integrating ethical standards and societal values into the development of LLMs, thereby guiding the development of responsible and ethically aligned language models.
Computational Limits of Low-Rank Adaptation (LoRA) for Transformer-Based Models
Jun 05, 2024We study the computational limits of Low-Rank Adaptation (LoRA) update for finetuning transformer-based models using fine-grained complexity theory. Our key observation is that the existence of low-rank decompositions within the gradient computation of LoRA adaptation leads to possible algorithmic speedup. This allows us to (i) identify a phase transition behavior and (ii) prove the existence of nearly linear algorithms by controlling the LoRA update computation term by term, assuming the Strong Exponential Time Hypothesis (SETH). For the former, we identify a sharp transition in the efficiency of all possible rank-$r$ LoRA update algorithms for transformers, based on specific norms resulting from the multiplications of the input sequence $\mathbf{X}$, pretrained weights $\mathbf{W^\star}$, and adapter matrices $\alpha \mathbf{B} \mathbf{A} / r$. Specifically, we derive a shared upper bound threshold for such norms and show that efficient (sub-quadratic) approximation algorithms of LoRA exist only below this threshold. For the latter, we prove the existence of nearly linear approximation algorithms for LoRA adaptation by utilizing the hierarchical low-rank structures of LoRA gradients and approximating the gradients with a series of chained low-rank approximations. To showcase our theory, we consider two practical scenarios: partial (e.g., only $\mathbf{W}_V$ and $\mathbf{W}_Q$) and full adaptations (e.g., $\mathbf{W}_Q$, $\mathbf{W}_V$, and $\mathbf{W}_K$) of weights in attention heads.
Decoupled Alignment for Robust Plug-and-Play Adaptation
Jun 04, 2024



We introduce a low-resource safety enhancement method for aligning large language models (LLMs) without the need for supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF). Our main idea is to exploit knowledge distillation to extract the alignment information from existing well-aligned LLMs and integrate it into unaligned LLMs in a plug-and-play fashion. Methodology, we employ delta debugging to identify the critical components of knowledge necessary for effective distillation. On the harmful question dataset, our method significantly enhances the average defense success rate by approximately 14.41%, reaching as high as 51.39%, in 17 unaligned pre-trained LLMs, without compromising performance.
Enhancing Jailbreak Attack Against Large Language Models through Silent Tokens
May 31, 2024Along with the remarkable successes of Language language models, recent research also started to explore the security threats of LLMs, including jailbreaking attacks. Attackers carefully craft jailbreaking prompts such that a target LLM will respond to the harmful question. Existing jailbreaking attacks require either human experts or leveraging complicated algorithms to craft jailbreaking prompts. In this paper, we introduce BOOST, a simple attack that leverages only the eos tokens. We demonstrate that rather than constructing complicated jailbreaking prompts, the attacker can simply append a few eos tokens to the end of a harmful question. It will bypass the safety alignment of LLMs and lead to successful jailbreaking attacks. We further apply BOOST to four representative jailbreak methods and show that the attack success rates of these methods can be significantly enhanced by simply adding eos tokens to the prompt. To understand this simple but novel phenomenon, we conduct empirical analyses. Our analysis reveals that adding eos tokens makes the target LLM believe the input is much less harmful, and eos tokens have low attention values and do not affect LLM's understanding of the harmful questions, leading the model to actually respond to the questions. Our findings uncover how fragile an LLM is against jailbreak attacks, motivating the development of strong safety alignment approaches.
Accurate and Reliable Predictions with Mutual-Transport Ensemble
May 30, 2024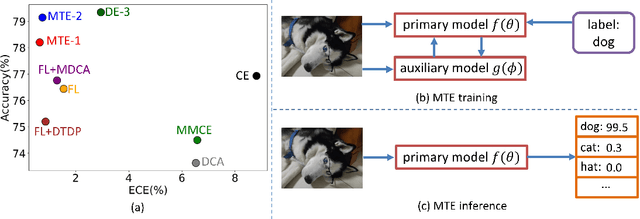
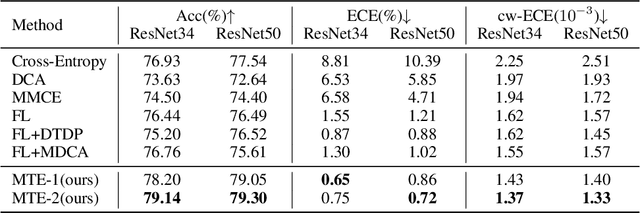
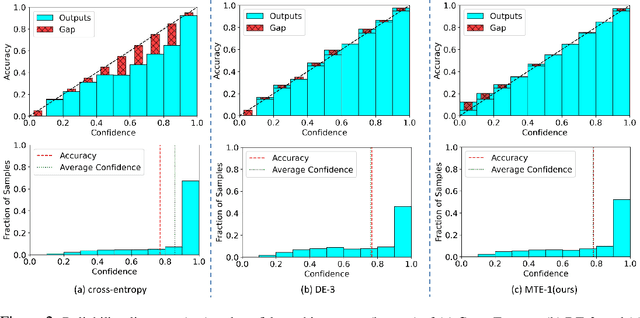
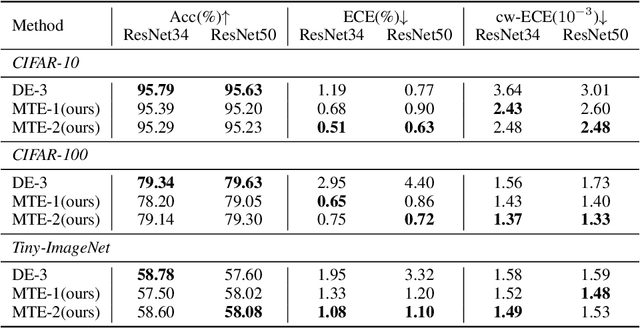
Deep Neural Networks (DNNs) have achieved remarkable success in a variety of tasks, especially when it comes to prediction accuracy. However, in complex real-world scenarios, particularly in safety-critical applications, high accuracy alone is not enough. Reliable uncertainty estimates are crucial. Modern DNNs, often trained with cross-entropy loss, tend to be overconfident, especially with ambiguous samples. To improve uncertainty calibration, many techniques have been developed, but they often compromise prediction accuracy. To tackle this challenge, we propose the ``mutual-transport ensemble'' (MTE). This approach introduces a co-trained auxiliary model and adaptively regularizes the cross-entropy loss using Kullback-Leibler (KL) divergence between the prediction distributions of the primary and auxiliary models. We conducted extensive studies on various benchmarks to validate the effectiveness of our method. The results show that MTE can simultaneously enhance both accuracy and uncertainty calibration. For example, on the CIFAR-100 dataset, our MTE method on ResNet34/50 achieved significant improvements compared to previous state-of-the-art method, with absolute accuracy increases of 2.4%/3.7%, relative reductions in ECE of $42.3%/29.4%, and relative reductions in classwise-ECE of 11.6%/15.3%.
Conv-CoA: Improving Open-domain Question Answering in Large Language Models via Conversational Chain-of-Action
May 28, 2024


We present a Conversational Chain-of-Action (Conv-CoA) framework for Open-domain Conversational Question Answering (OCQA). Compared with literature, Conv-CoA addresses three major challenges: (i) unfaithful hallucination that is inconsistent with real-time or domain facts, (ii) weak reasoning performance in conversational scenarios, and (iii) unsatisfying performance in conversational information retrieval. Our key contribution is a dynamic reasoning-retrieval mechanism that extracts the intent of the question and decomposes it into a reasoning chain to be solved via systematic prompting, pre-designed actions, updating the Contextual Knowledge Set (CKS), and a novel Hopfield-based retriever. Methodologically, we propose a resource-efficiency Hopfield retriever to enhance the efficiency and accuracy of conversational information retrieval within our actions. Additionally, we propose a conversational-multi-reference faith score (Conv-MRFS) to verify and resolve conflicts between retrieved knowledge and answers in conversations. Empirically, we conduct comparisons between our framework and 23 state-of-the-art methods across five different research directions and two public benchmarks. These comparisons demonstrate that our Conv-CoA outperforms other methods in both the accuracy and efficiency dimensions.
HeteGraph-Mamba: Heterogeneous Graph Learning via Selective State Space Model
May 22, 2024

We propose a heterogeneous graph mamba network (HGMN) as the first exploration in leveraging the selective state space models (SSSMs) for heterogeneous graph learning. Compared with the literature, our HGMN overcomes two major challenges: (i) capturing long-range dependencies among heterogeneous nodes and (ii) adapting SSSMs to heterogeneous graph data. Our key contribution is a general graph architecture that can solve heterogeneous nodes in real-world scenarios, followed an efficient flow. Methodologically, we introduce a two-level efficient tokenization approach that first captures long-range dependencies within identical node types, and subsequently across all node types. Empirically, we conduct comparisons between our framework and 19 state-of-the-art methods on the heterogeneous benchmarks. The extensive comparisons demonstrate that our framework outperforms other methods in both the accuracy and efficiency dimensions.
Input Snapshots Fusion for Scalable Discrete Dynamic Graph Nerual Networks
May 11, 2024



Dynamic graphs are ubiquitous in the real world, yet there is a lack of suitable theoretical frameworks to effectively extend existing static graph models into the temporal domain. Additionally, for link prediction tasks on discrete dynamic graphs, the requirement of substantial GPU memory to store embeddings of all nodes hinders the scalability of existing models. In this paper, we introduce an Input {\bf S}napshots {\bf F}usion based {\bf Dy}namic {\bf G}raph Neural Network (SFDyG). By eliminating the partitioning of snapshots within the input window, we obtain a multi-graph (more than one edge between two nodes). Subsequently, by introducing a graph denoising problem with the assumption of temporal decayed smoothing, we integrate Hawkes process theory into Graph Neural Networks to model the generated multi-graph. Furthermore, based on the multi-graph, we propose a scalable three-step mini-batch training method and demonstrate its equivalence to full-batch training counterpart. Our experiments, conducted on eight distinct dynamic graph datasets for future link prediction tasks, revealed that SFDyG generally surpasses related methods.