 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaizhou Li
Minimizing the Accumulated Trajectory Error to Improve Dataset Distillation
Nov 20, 2022
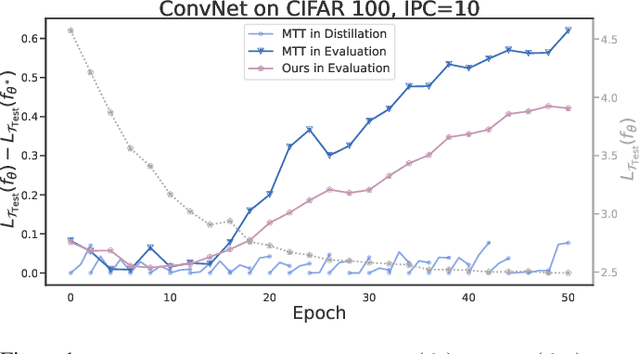
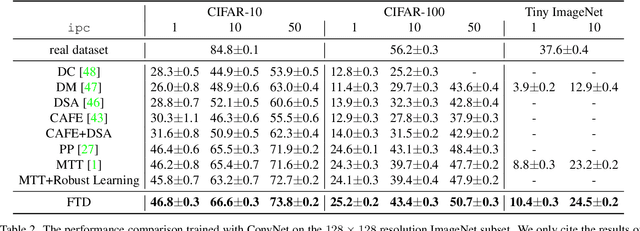
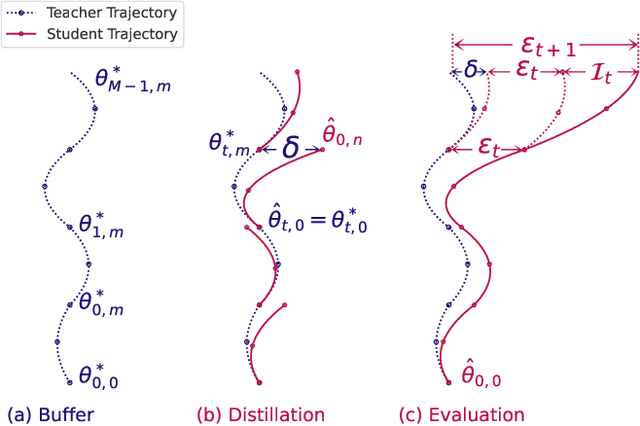

Model-based deep learning has achieved astounding successes due in part to the availability of large-scale realworld data. However, processing such massive amounts of data comes at a considerable cost in terms of computations, storage, training and the search for good neural architectures. Dataset distillation has thus recently come to the fore. This paradigm involves distilling information from large real-world datasets into tiny and compact synthetic datasets such that processing the latter yields similar performances as the former. State-of-the-art methods primarily rely on learning the synthetic dataset by matching the gradients obtained during training between the real and synthetic data. However, these gradient-matching methods suffer from the accumulated trajectory error caused by the discrepancy between the distillation and subsequent evaluation. To alleviate the adverse impact of this accumulated trajectory error, we propose a novel approach that encourages the optimization algorithm to seek a flat trajectory. We show that the weights trained on synthetic data are robust against the accumulated errors perturbations with the regularization towards the flat trajectory. Our method, called Flat Trajectory Distillation (FTD), is shown to boost the performance of gradient-matching methods by up to 4.7% on a subset of images of the ImageNet dataset with higher resolution images. We also validate the effectiveness and generalizability of our method with datasets of different resolutions and demonstrate its applicability to neural architecture search.
Self-Transriber: Few-shot Lyrics Transcription with Self-training
Nov 18, 2022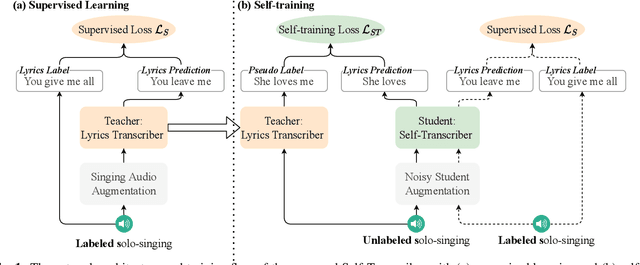
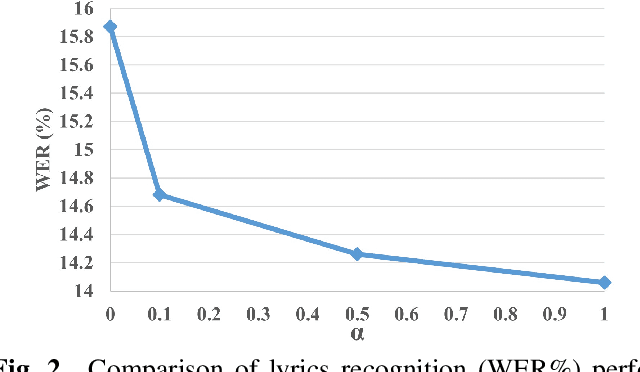
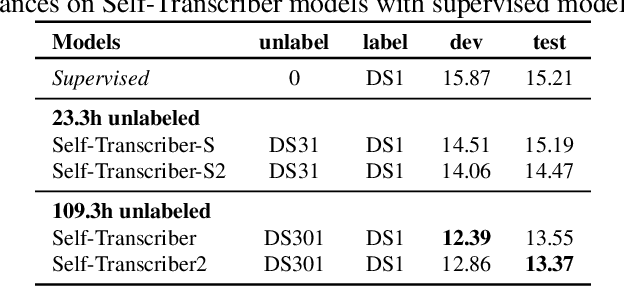
The current lyrics transcription approaches heavily rely on supervised learning with labeled data, but such data are scarce and manual labeling of singing is expensive. How to benefit from unlabeled data and alleviate limited data problem have not been explored for lyrics transcription. We propose the first semi-supervised lyrics transcription paradigm, Self-Transcriber, by leveraging on unlabeled data using self-training with noisy student augmentation. We attempt to demonstrate the possibility of lyrics transcription with a few amount of labeled data. Self-Transcriber generates pseudo labels of the unlabeled singing using teacher model, and augments pseudo-labels to the labeled data for student model update with both self-training and supervised training losses. This work closes the gap between supervised and semi-supervised learning as well as opens doors for few-shot learning of lyrics transcription. Our experiments show that our approach using only 12.7 hours of labeled data achieves competitive performance compared with the supervised approaches trained on 149.1 hours of labeled data for lyrics transcription.
I4U System Description for NIST SRE'20 CTS Challenge
Nov 02, 2022
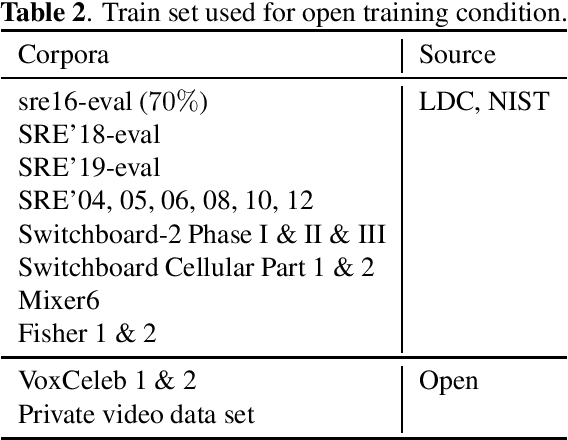


This manuscript describes the I4U submission to the 2020 NIST Speaker Recognition Evaluation (SRE'20) Conversational Telephone Speech (CTS) Challenge. The I4U's submission was resulted from active collaboration among researchers across eight research teams - I$^2$R (Singapore), UEF (Finland), VALPT (Italy, Spain), NEC (Japan), THUEE (China), LIA (France), NUS (Singapore), INRIA (France) and TJU (China). The submission was based on the fusion of top performing sub-systems and sub-fusion systems contributed by individual teams. Efforts have been spent on the use of common development and validation sets, submission schedule and milestone, minimizing inconsistency in trial list and score file format across sites.
ImagineNET: Target Speaker Extraction with Intermittent Visual Cue through Embedding Inpainting
Oct 31, 2022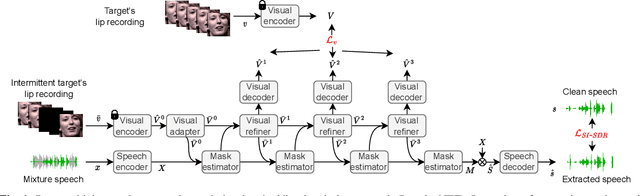
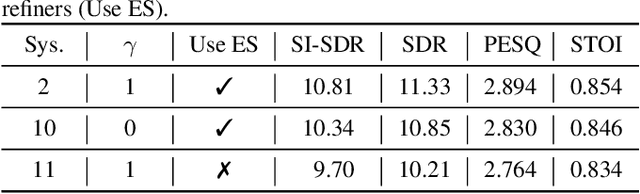
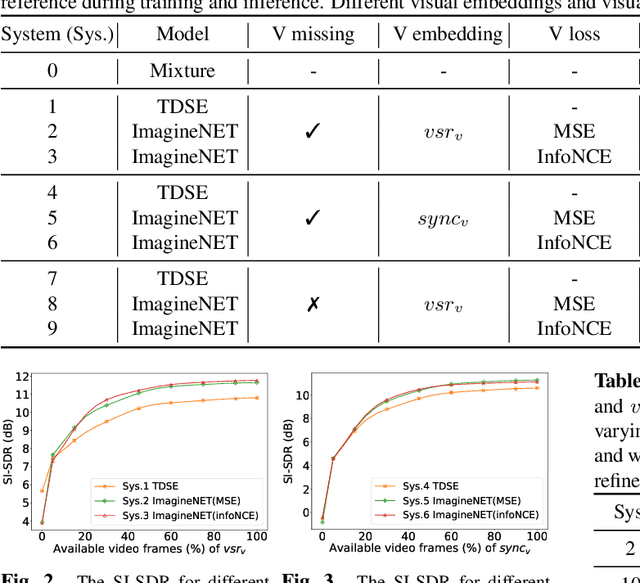
The speaker extraction technique seeks to single out the voice of a target speaker from the interfering voices in a speech mixture. Typically an auxiliary reference of the target speaker is used to form voluntary attention. Either a pre-recorded utterance or a synchronized lip movement in a video clip can serve as the auxiliary reference. The use of visual cue is not only feasible, but also effective due to its noise robustness, and becoming popular. However, it is difficult to guarantee that such parallel visual cue is always available in real-world applications where visual occlusion or intermittent communication can occur. In this paper, we study the audio-visual speaker extraction algorithms with intermittent visual cue. We propose a joint speaker extraction and visual embedding inpainting framework to explore the mutual benefits. To encourage the interaction between the two tasks, they are performed alternately with an interlacing structure and optimized jointly. We also propose two types of visual inpainting losses and study our proposed method with two types of popularly used visual embeddings. The experimental results show that we outperform the baseline in terms of signal quality, perceptual quality, and intelligibility.
Generate, Discriminate and Contrast: A Semi-Supervised Sentence Representation Learning Framework
Oct 30, 2022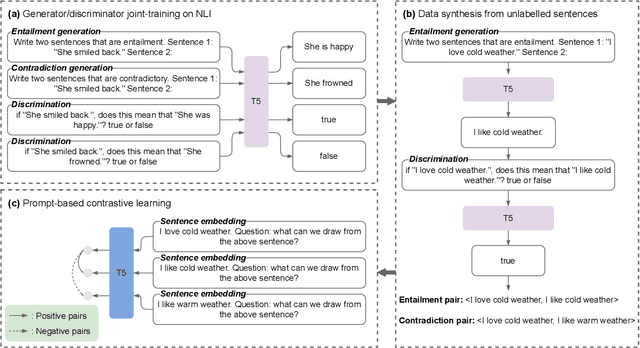

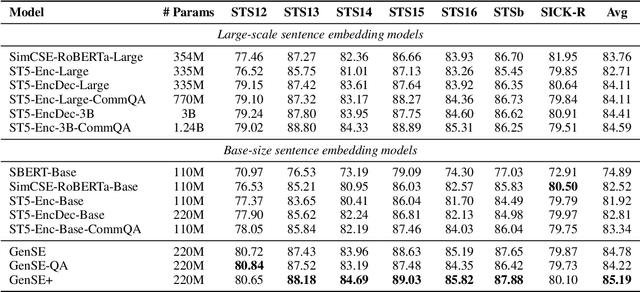
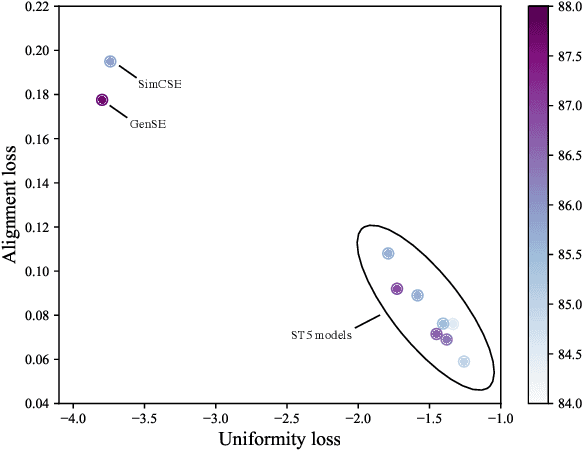
Most sentence embedding techniques heavily rely on expensive human-annotated sentence pairs as the supervised signals. Despite the use of large-scale unlabeled data, the performance of unsupervised methods typically lags far behind that of the supervised counterparts in most downstream tasks. In this work, we propose a semi-supervised sentence embedding framework, GenSE, that effectively leverages large-scale unlabeled data. Our method include three parts: 1) Generate: A generator/discriminator model is jointly trained to synthesize sentence pairs from open-domain unlabeled corpus; 2) Discriminate: Noisy sentence pairs are filtered out by the discriminator to acquire high-quality positive and negative sentence pairs; 3) Contrast: A prompt-based contrastive approach is presented for sentence representation learning with both annotated and synthesized data. Comprehensive experiments show that GenSE achieves an average correlation score of 85.19 on the STS datasets and consistent performance improvement on four domain adaptation tasks, significantly surpassing the state-of-the-art methods and convincingly corroborating its effectiveness and generalization ability.Code, Synthetic data and Models available at https://github.com/MatthewCYM/GenSE.
token2vec: A Joint Self-Supervised Pre-training Framework Using Unpaired Speech and Text
Oct 30, 2022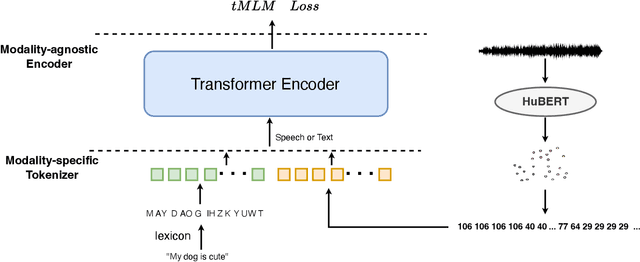
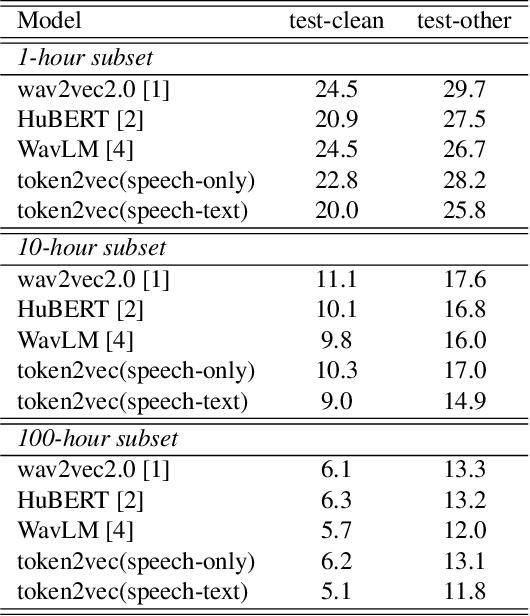
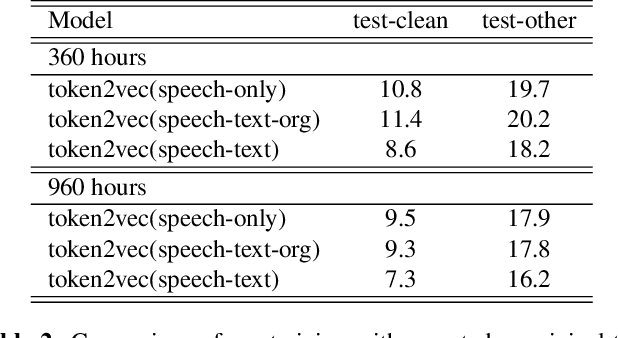
Self-supervised pre-training has been successful in both text and speech processing. Speech and text offer different but complementary information. The question is whether we are able to perform a speech-text joint pre-training on unpaired speech and text. In this paper, we take the idea of self-supervised pre-training one step further and propose token2vec, a novel joint pre-training framework for unpaired speech and text based on discrete representations of speech. Firstly, due to the distinct characteristics between speech and text modalities, where speech is continuous while text is discrete, we first discretize speech into a sequence of discrete speech tokens to solve the modality mismatch problem. Secondly, to solve the length mismatch problem, where the speech sequence is usually much longer than text sequence, we convert the words of text into phoneme sequences and randomly repeat each phoneme in the sequences. Finally, we feed the discrete speech and text tokens into a modality-agnostic Transformer encoder and pre-train with token-level masking language modeling (tMLM). Experiments show that token2vec is significantly superior to various speech-only pre-training baselines, with up to 17.7% relative WER reduction. Token2vec model is also validated on a non-ASR task, i.e., spoken intent classification, and shows good transferability.
FineD-Eval: Fine-grained Automatic Dialogue-Level Evaluation
Oct 29, 2022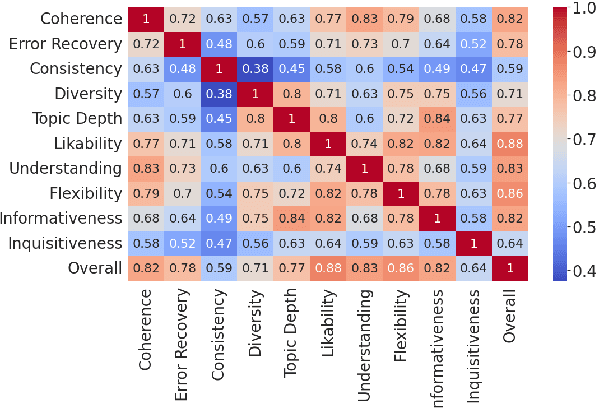
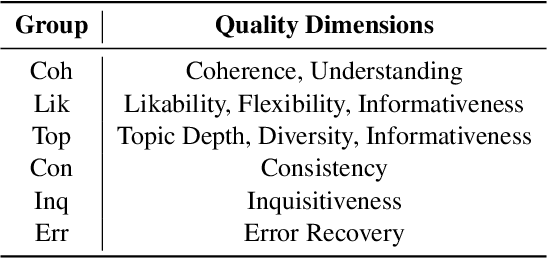
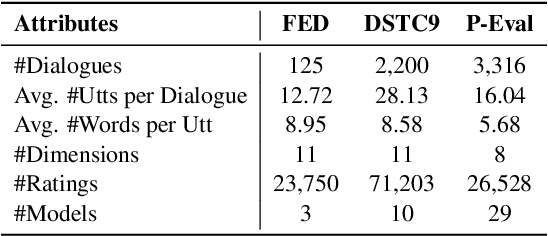
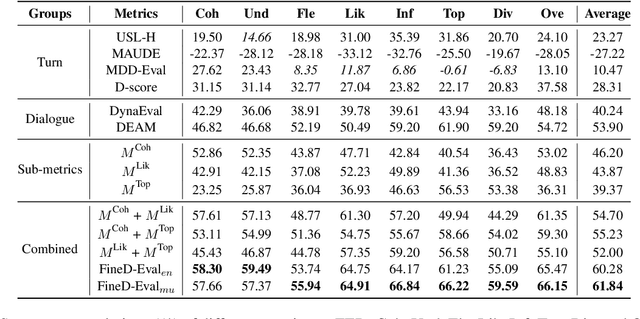
Recent model-based reference-free metrics for open-domain dialogue evaluation exhibit promising correlations with human judgment. However, they either perform turn-level evaluation or look at a single dialogue quality dimension. One would expect a good evaluation metric to assess multiple quality dimensions at the dialogue level. To this end, we are motivated to propose a multi-dimensional dialogue-level metric, which consists of three sub-metrics with each targeting a specific dimension. The sub-metrics are trained with novel self-supervised objectives and exhibit strong correlations with human judgment for their respective dimensions. Moreover, we explore two approaches to combine the sub-metrics: metric ensemble and multitask learning. Both approaches yield a holistic metric that significantly outperforms individual sub-metrics. Compared to the existing state-of-the-art metric, the combined metrics achieve around 16% relative improvement on average across three high-quality dialogue-level evaluation benchmarks.
Speaker recognition with two-step multi-modal deep cleansing
Oct 28, 2022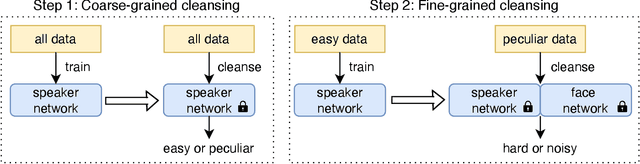
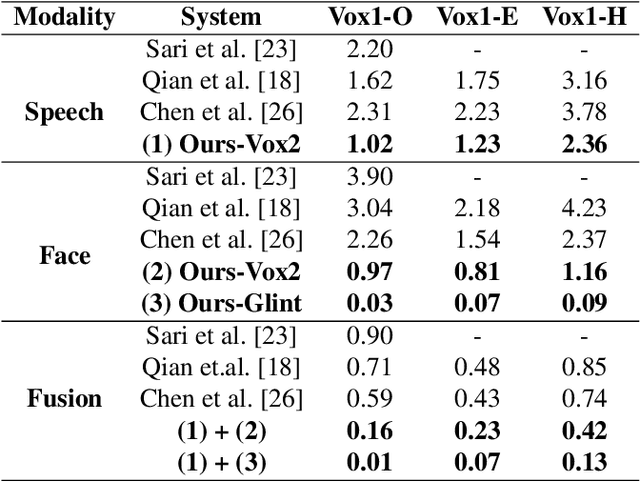
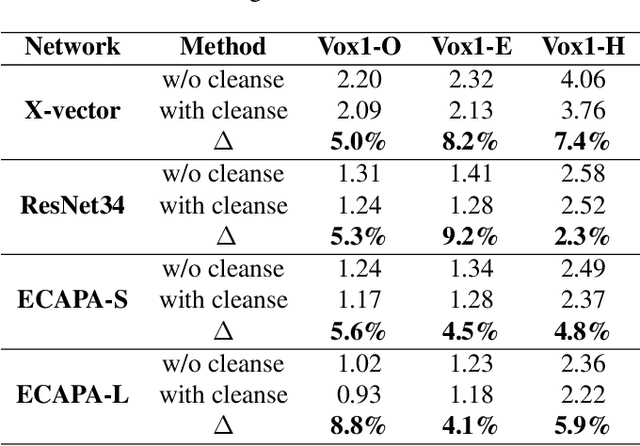
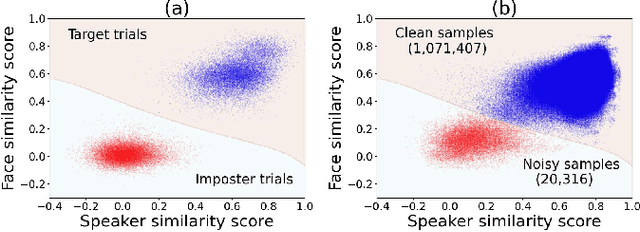
Neural network-based speaker recognition has achieved significant improvement in recent years. A robust speaker representation learns meaningful knowledge from both hard and easy samples in the training set to achieve good performance. However, noisy samples (i.e., with wrong labels) in the training set induce confusion and cause the network to learn the incorrect representation. In this paper, we propose a two-step audio-visual deep cleansing framework to eliminate the effect of noisy labels in speaker representation learning. This framework contains a coarse-grained cleansing step to search for the peculiar samples, followed by a fine-grained cleansing step to filter out the noisy labels. Our study starts from an efficient audio-visual speaker recognition system, which achieves a close to perfect equal-error-rate (EER) of 0.01\%, 0.07\% and 0.13\% on the Vox-O, E and H test sets. With the proposed multi-modal cleansing mechanism, four different speaker recognition networks achieve an average improvement of 5.9\%. Code has been made available at: \textcolor{magenta}{\url{https://github.com/TaoRuijie/AVCleanse}}.
Self-Supervised Training of Speaker Encoder with Multi-Modal Diverse Positive Pairs
Oct 27, 2022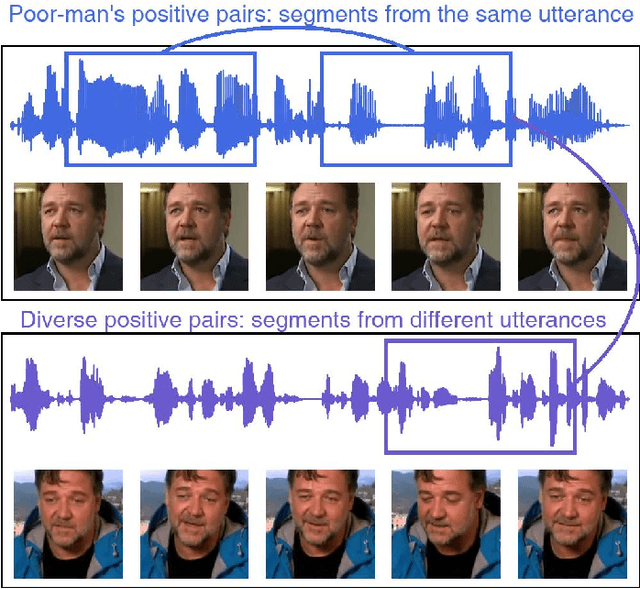
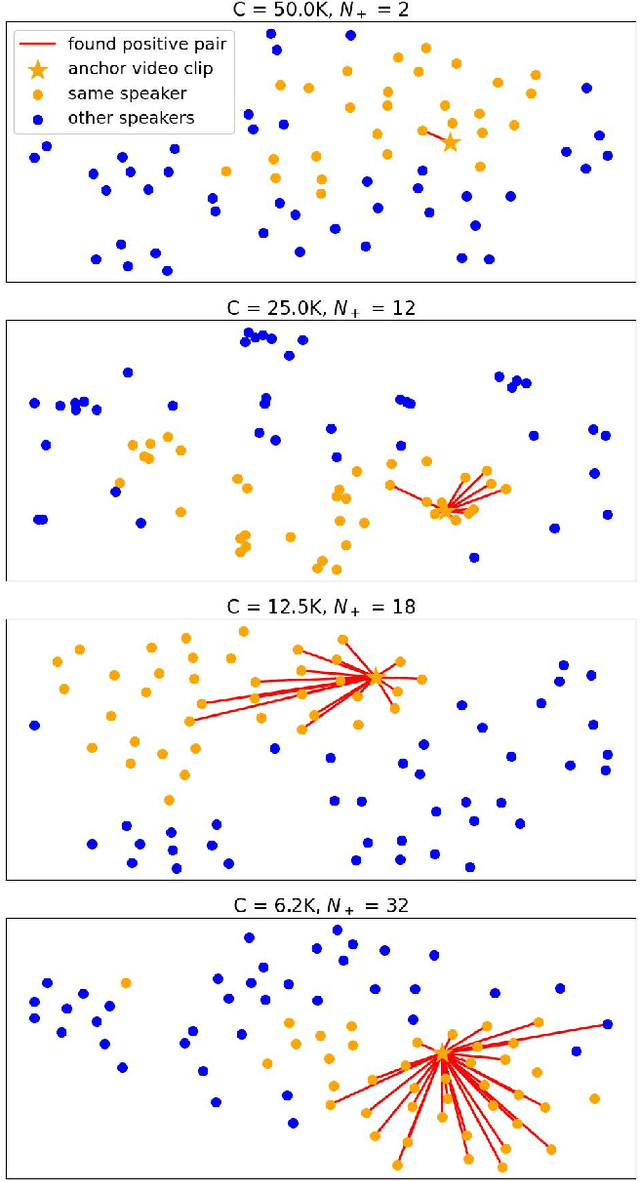
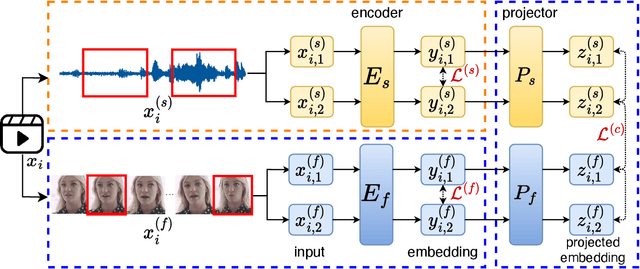
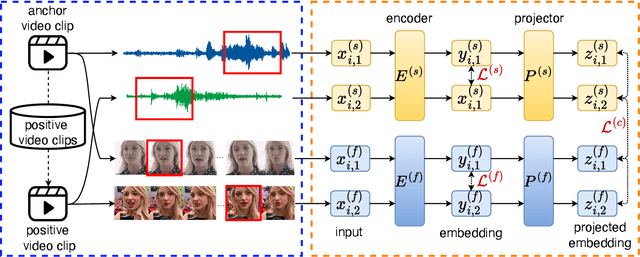
We study a novel neural architecture and its training strategies of speaker encoder for speaker recognition without using any identity labels. The speaker encoder is trained to extract a fixed-size speaker embedding from a spoken utterance of various length. Contrastive learning is a typical self-supervised learning technique. However, the quality of the speaker encoder depends very much on the sampling strategy of positive and negative pairs. It is common that we sample a positive pair of segments from the same utterance. Unfortunately, such poor-man's positive pairs (PPP) lack necessary diversity for the training of a robust encoder. In this work, we propose a multi-modal contrastive learning technique with novel sampling strategies. By cross-referencing between speech and face data, we study a method that finds diverse positive pairs (DPP) for contrastive learning, thus improving the robustness of the speaker encoder. We train the speaker encoder on the VoxCeleb2 dataset without any speaker labels, and achieve an equal error rate (EER) of 2.89\%, 3.17\% and 6.27\% under the proposed progressive clustering strategy, and an EER of 1.44\%, 1.77\% and 3.27\% under the two-stage learning strategy with pseudo labels, on the three test sets of VoxCeleb1. This novel solution outperforms the state-of-the-art self-supervised learning methods by a large margin, at the same time, achieves comparable results with the supervised learning counterpart. We also evaluate our self-supervised learning technique on LRS2 and LRW datasets, where the speaker information is unknown. All experiments suggest that the proposed neural architecture and sampling strategies are robust across datasets.
Explicit Intensity Control for Accented Text-to-speech
Oct 27, 2022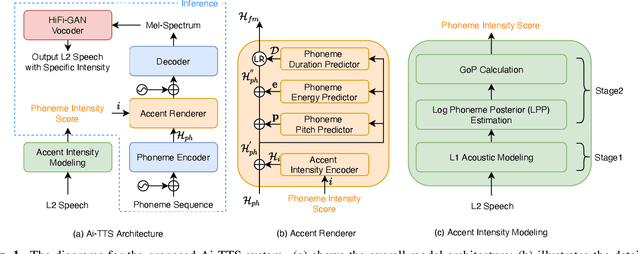
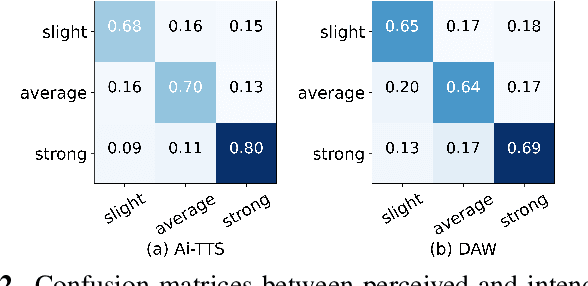
Accented text-to-speech (TTS) synthesis seeks to generate speech with an accent (L2) as a variant of the standard version (L1). How to control the intensity of accent in the process of TTS is a very interesting research direction, and has attracted more and more attention. Recent work design a speaker-adversarial loss to disentangle the speaker and accent information, and then adjust the loss weight to control the accent intensity. However, such a control method lacks interpretability, and there is no direct correlation between the controlling factor and natural accent intensity. To this end, this paper propose a new intuitive and explicit accent intensity control scheme for accented TTS. Specifically, we first extract the posterior probability, called as ``goodness of pronunciation (GoP)'' from the L1 speech recognition model to quantify the phoneme accent intensity for accented speech, then design a FastSpeech2 based TTS model, named Ai-TTS, to take the accent intensity expression into account during speech generation. Experiments show that the our method outperforms the baseline model in terms of accent rendering and intensity control.