 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Assisted Adaptive Sharpening Scheme Considering Bitrate and Quality Tradeoff
Aug 12, 2025Sharpening is a widely adopted technique to improve video quality, which can effectively emphasize textures and alleviate blurring. However, increasing the sharpening level comes with a higher video bitrate, resulting in degraded Quality of Service (QoS). Furthermore, the video quality does not necessarily improve with increasing sharpening levels, leading to issues such as over-sharpening. Clearly, it is essential to figure out how to boost video quality with a proper sharpening level while also controlling bandwidth costs effectively. This paper thus proposes a novel Frequency-assisted Sharpening level Prediction model (FreqSP). We first label each video with the sharpening level correlating to the optimal bitrate and quality tradeoff as ground truth. Then taking uncompressed source videos as inputs, the proposed FreqSP leverages intricate CNN features and high-frequency components to estimate the optimal sharpening level. Extensive experiments demonstrate the effectiveness of our method.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024



Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
TSMD: A Database for Static Color Mesh Quality Assessment Study
Aug 03, 2023Static meshes with texture map are widely used in modern industrial and manufacturing sectors, attracting considerable attention in the mesh compression community due to its huge amount of data. To facilitate the study of static mesh compression algorithm and objective quality metric, we create the Tencent - Static Mesh Dataset (TSMD) containing 42 reference meshes with rich visual characteristics. 210 distorted samples are generated by the lossy compression scheme developed for the Call for Proposals on polygonal static mesh coding, released on June 23 by the Alliance for Open Media Volumetric Visual Media group. Using processed video sequences, a large-scale, crowdsourcing-based, subjective experiment was conducted to collect subjective scores from 74 viewers. The dataset undergoes analysis to validate its sample diversity and Mean Opinion Scores (MOS) accuracy, establishing its heterogeneous nature and reliability. State-of-the-art objective metrics are evaluated on the new dataset. Pearson and Spearman correlations around 0.75 are reported, deviating from results typically observed on less heterogeneous datasets, demonstrating the need for further development of more robust metrics. The TSMD, including meshes, PVSs, bitstreams, and MOS, is made publicly available at the following location: https://multimedia.tencent.com/resources/tsmd.
C3DVQA: Full-Reference Video Quality Assessment with 3D Convolutional Neural Network
Oct 30, 2019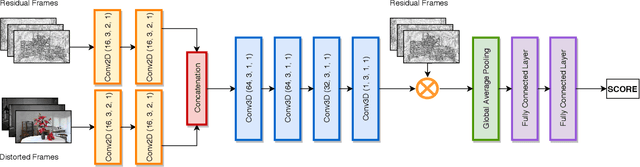
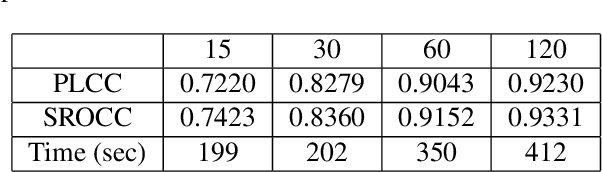

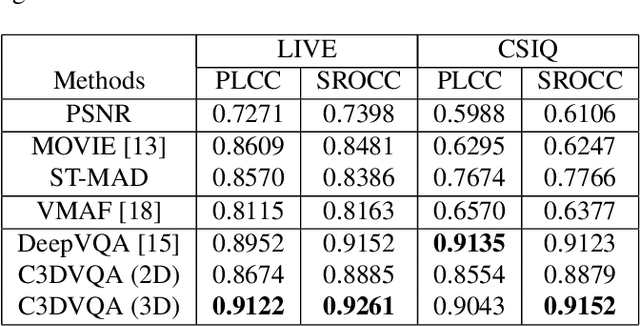
Traditional video quality assessment (VQA) methods evaluate localized picture quality and video score is predicted by temporally aggregating frame scores. However, video quality exhibits different characteristics from static image quality due to the existence of temporal masking effects. In this paper, we present a novel architecture, namely C3DVQA, that uses Convolutional Neural Network with 3D kernels (C3D) for full-reference VQA task. C3DVQA combines feature learning and score pooling into one spatiotemporal feature learning process. We use 2D convolutional layers to extract spatial features and 3D convolutional layers to learn spatiotemporal features. We empirically found that 3D convolutional layers are capable to capture temporal masking effects of videos.We evaluated the proposed method on the LIVE and CSIQ datasets. The experimental results demonstrate that the proposed method achieves the state-of-the-art performance.
A GMM-Based Stair Quality Model for Human Perceived JPEG Images
Nov 11, 2015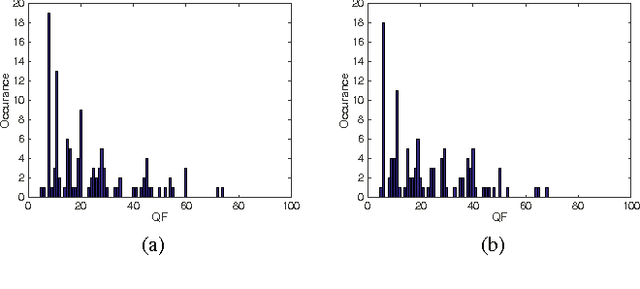
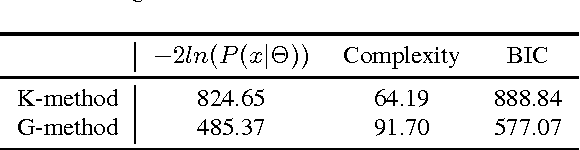
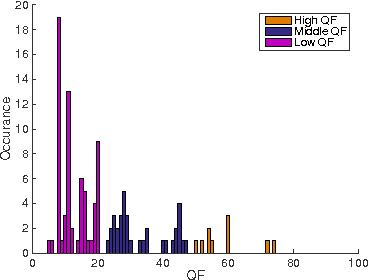
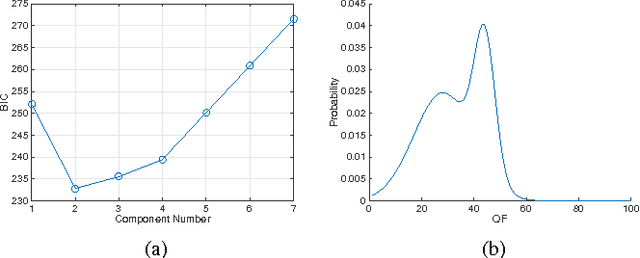
Based on the notion of just noticeable differences (JND), a stair quality function (SQF) was recently proposed to model human perception on JPEG images. Furthermore, a k-means clustering algorithm was adopted to aggregate JND data collected from multiple subjects to generate a single SQF. In this work, we propose a new method to derive the SQF using the Gaussian Mixture Model (GMM). The newly derived SQF can be interpreted as a way to characterize the mean viewer experience. Furthermore, it has a lower information criterion (BIC) value than the previous one, indicating that it offers a better model. A specific example is given to demonstrate the advantages of the new approach.