 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHWA-UNETR: Hierarchical Window Aggregate UNETR for 3D Multimodal Gastric Lesion Segmentation
May 15, 2025Multimodal medical image segmentation faces significant challenges in the context of gastric cancer lesion analysis. This clinical context is defined by the scarcity of independent multimodal datasets and the imperative to amalgamate inherently misaligned modalities. As a result, algorithms are constrained to train on approximate data and depend on application migration, leading to substantial resource expenditure and a potential decline in analysis accuracy. To address those challenges, we have made two major contributions: First, we publicly disseminate the GCM 2025 dataset, which serves as the first large-scale, open-source collection of gastric cancer multimodal MRI scans, featuring professionally annotated FS-T2W, CE-T1W, and ADC images from 500 patients. Second, we introduce HWA-UNETR, a novel 3D segmentation framework that employs an original HWA block with learnable window aggregation layers to establish dynamic feature correspondences between different modalities' anatomical structures, and leverages the innovative tri-orientated fusion mamba mechanism for context modeling and capturing long-range spatial dependencies. Extensive experiments on our GCM 2025 dataset and the publicly BraTS 2021 dataset validate the performance of our framework, demonstrating that the new approach surpasses existing methods by up to 1.68\% in the Dice score while maintaining solid robustness. The dataset and code are public via https://github.com/JeMing-creater/HWA-UNETR.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
Robust Human Matting via Semantic Guidance
Oct 11, 2022
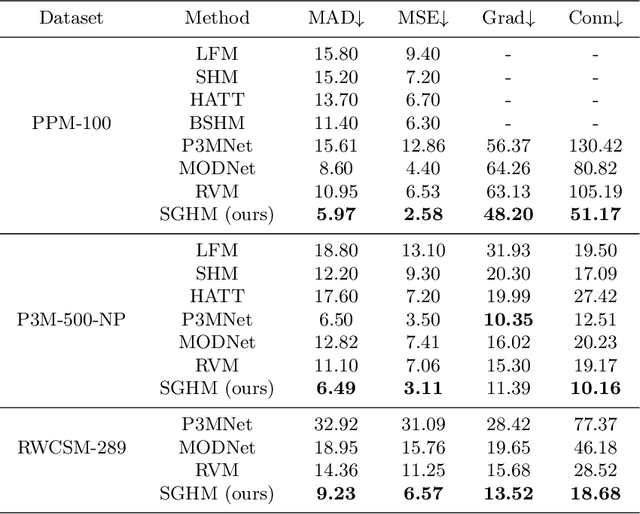
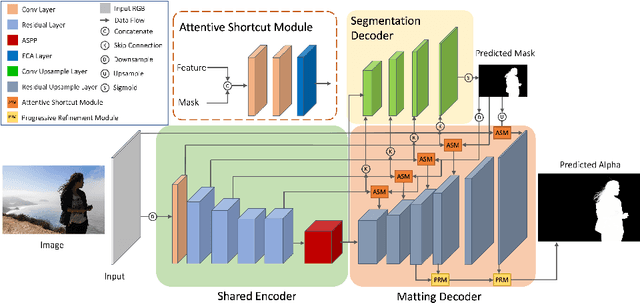
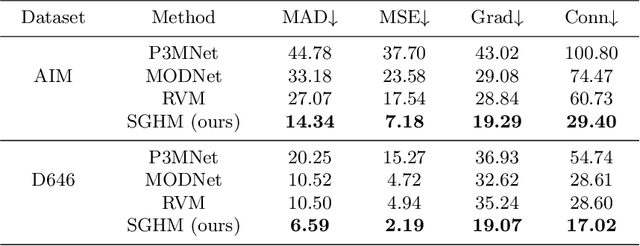
Automatic human matting is highly desired for many real applications. We investigate recent human matting methods and show that common bad cases happen when semantic human segmentation fails. This indicates that semantic understanding is crucial for robust human matting. From this, we develop a fast yet accurate human matting framework, named Semantic Guided Human Matting (SGHM). It builds on a semantic human segmentation network and introduces a light-weight matting module with only marginal computational cost. Unlike previous works, our framework is data efficient, which requires a small amount of matting ground-truth to learn to estimate high quality object mattes. Our experiments show that trained with merely 200 matting images, our method can generalize well to real-world datasets, and outperform recent methods on multiple benchmarks, while remaining efficient. Considering the unbearable labeling cost of matting data and widely available segmentation data, our method becomes a practical and effective solution for the task of human matting. Source code is available at https://github.com/cxgincsu/SemanticGuidedHumanMatting.