 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsePoint: Fully End-to-End Sparse 3D Object Detector
Mar 18, 2021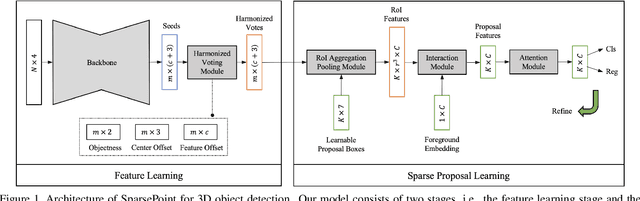
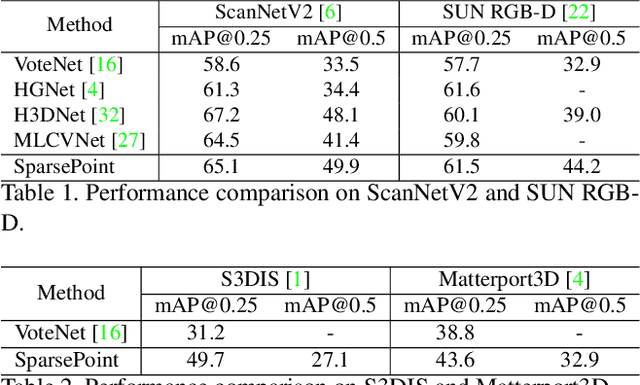
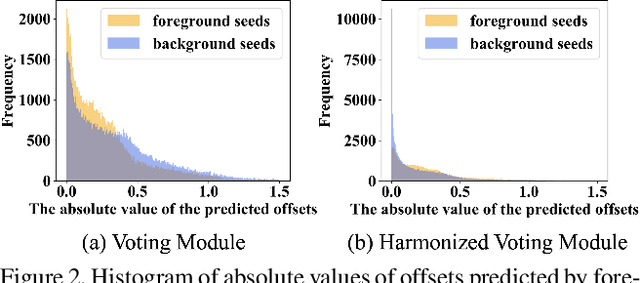
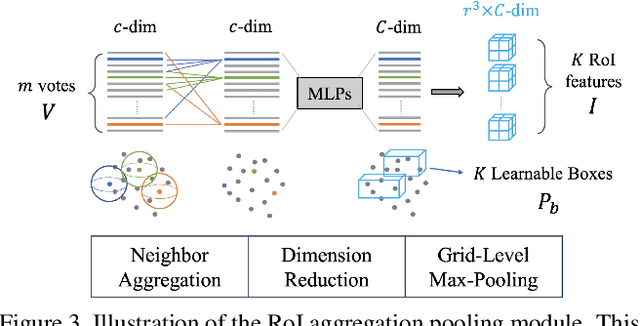
Object detectors based on sparse object proposals have recently been proven to be successful in the 2D domain, which makes it possible to establish a fully end-to-end detector without time-consuming post-processing. This development is also attractive for 3D object detectors. However, considering the remarkably larger search space in the 3D domain, whether it is feasible to adopt the sparse method in the 3D object detection setting is still an open question. In this paper, we propose SparsePoint, the first sparse method for 3D object detection. Our SparsePoint adopts a number of learnable proposals to encode most likely potential positions of 3D objects and a foreground embedding to encode shared semantic features of all objects. Besides, with the attention module to provide object-level interaction for redundant proposal removal and Hungarian algorithm to supply one-one label assignment, our method can produce sparse and accurate predictions. SparsePoint sets a new state-of-the-art on four public datasets, including ScanNetV2, SUN RGB-D, S3DIS, and Matterport3D. Our code will be publicly available soon.
Complementary Pseudo Labels For Unsupervised Domain Adaptation On Person Re-identification
Feb 07, 2021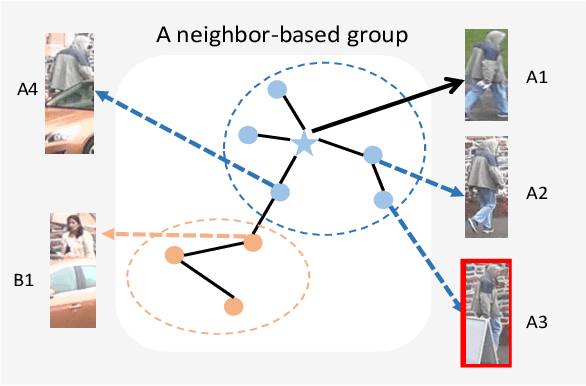
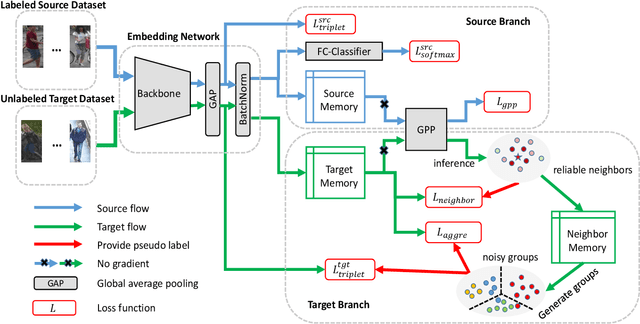
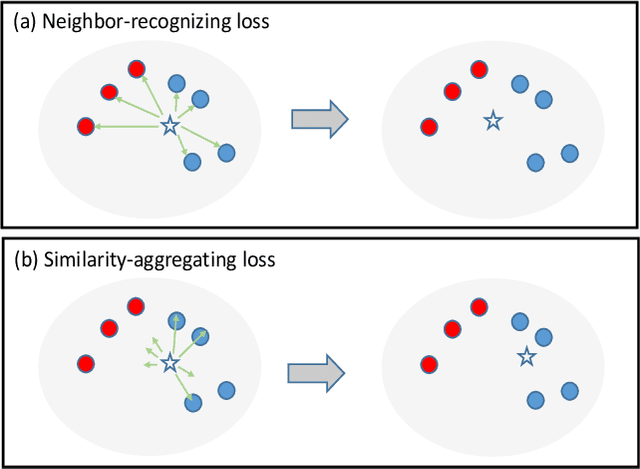
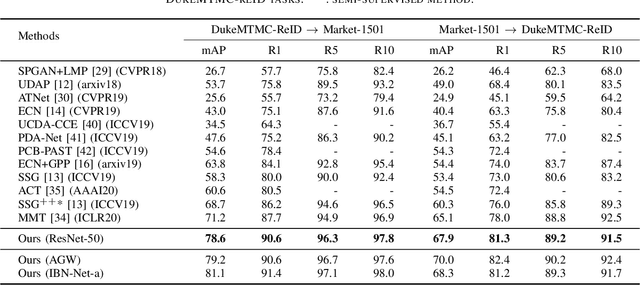
In recent years, supervised person re-identification (re-ID) models have received increasing studies. However, these models trained on the source domain always suffer dramatic performance drop when tested on an unseen domain. Existing methods are primary to use pseudo labels to alleviate this problem. One of the most successful approaches predicts neighbors of each unlabeled image and then uses them to train the model. Although the predicted neighbors are credible, they always miss some hard positive samples, which may hinder the model from discovering important discriminative information of the unlabeled domain. In this paper, to complement these low recall neighbor pseudo labels, we propose a joint learning framework to learn better feature embeddings via high precision neighbor pseudo labels and high recall group pseudo labels. The group pseudo labels are generated by transitively merging neighbors of different samples into a group to achieve higher recall. However, the merging operation may cause subgroups in the group due to imperfect neighbor predictions. To utilize these group pseudo labels properly, we propose using a similarity-aggregating loss to mitigate the influence of these subgroups by pulling the input sample towards the most similar embeddings. Extensive experiments on three large-scale datasets demonstrate that our method can achieve state-of-the-art performance under the unsupervised domain adaptation re-ID setting.
Accelerate Your CNN from Three Dimensions: A Comprehensive Pruning Framework
Oct 10, 2020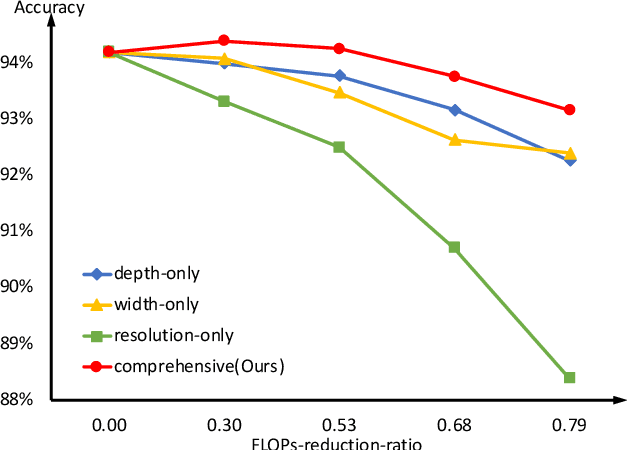
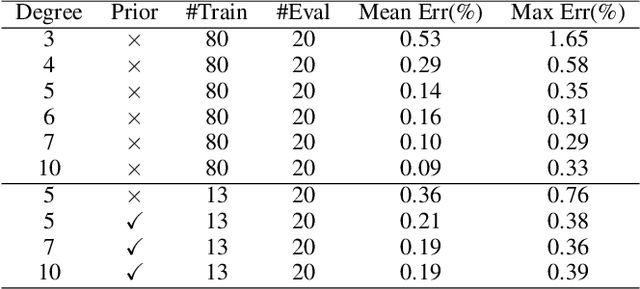
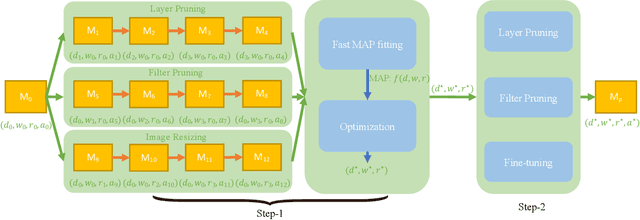
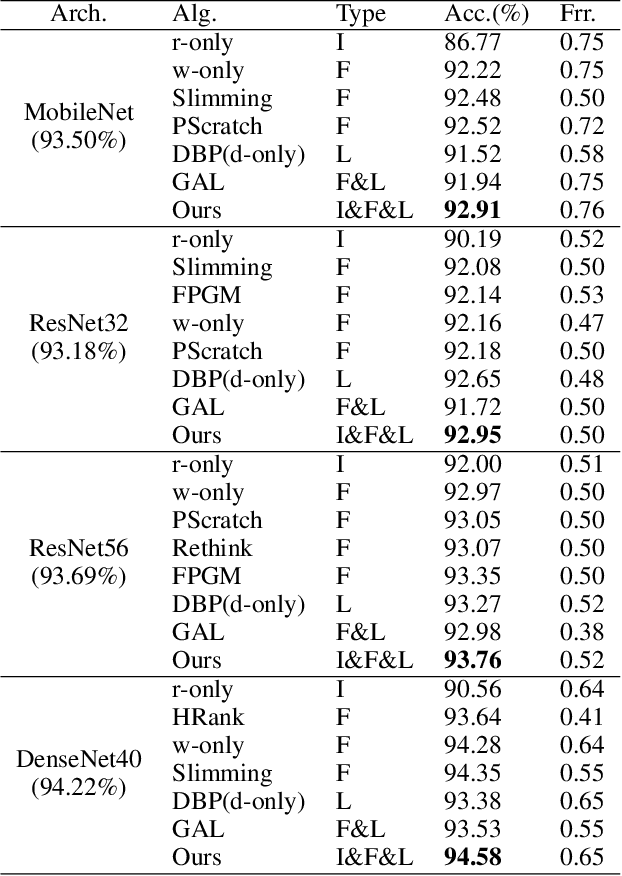
To deploy a pre-trained deep CNN on resource-constrained mobile devices, neural network pruning is often used to cut down the model's computational cost. For example, filter-level pruning (reducing the model's width) or layer-level pruning (reducing the model's depth) can both save computations with some sacrifice of accuracy. Besides, reducing the resolution of input images can also reach the same goal. Most previous methods focus on reducing one or two of these dimensions (i.e., depth, width, and image resolution) for acceleration. However, excessive reduction of any single dimension will lead to unacceptable accuracy loss, and we have to prune these three dimensions comprehensively to yield the best result. In this paper, a simple yet effective pruning framework is proposed to comprehensively consider these three dimensions. Our framework falls into two steps: 1) Determining the optimal depth (d*), width (w*), and image resolution (r) for the model. 2) Pruning the model in terms of (d*, w*, r*). Specifically, at the first step, we formulate model acceleration as an optimization problem. It takes depth (d), width (w) and image resolution (r) as variables and the model's accuracy as the optimization objective. Although it is hard to determine the expression of the objective function, approximating it with polynomials is still feasible, during which several properties of the objective function are utilized to ease and speedup the fitting process. Then the optimal d*, w* and r* are attained by maximizing the objective function with Lagrange multiplier theorem and KKT conditions. Extensive experiments are done on several popular architectures and datasets. The results show that we have outperformd the state-of-the-art pruning methods. The code will be published soon.
RESA: Recurrent Feature-Shift Aggregator for Lane Detection
Aug 31, 2020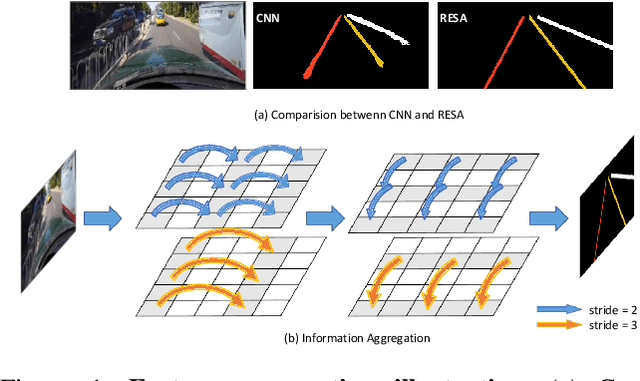

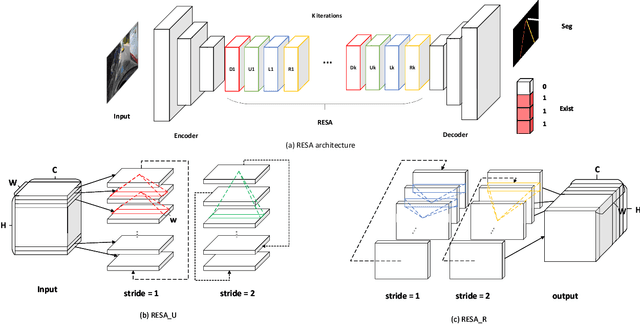
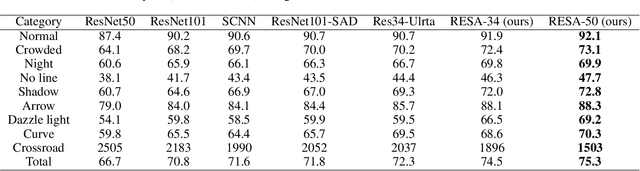
Lane detection is one of the most important tasks in self-driving. Due to various complex scenarios (e.g., severe occlusion, ambiguous lanes, and etc.) and the sparse supervisory signals inherent in lane annotations, lane detection task is still challenging. Thus, it is difficult for ordinary convolutional neural network (CNN) trained in general scenes to catch subtle lane feature from raw image. In this paper, we present a novel module named REcurrent Feature-Shift Aggregator (RESA) to enrich lane feature after preliminary feature extraction with an ordinary CNN. RESA takes advantage of strong shape priors of lanes and captures spatial relationships of pixels across rows and columns. It shifts sliced feature map recurrently in vertical and horizontal directions and enables each pixel to gather global information. With the help of slice-by-slice information propagation, RESA can conjecture lanes accurately in challenging scenarios with weak appearance clues. Moreover, we also propose a Bilateral Up-Sampling Decoder which combines coarse grained feature and fine detailed feature in up-sampling stage, and it can recover low-resolution feature map into pixel-wise prediction meticulously. Our method achieves state-of-the-art results on two popular lane detection benchmarks (CULane and Tusimple). The code will be released publicly available.
Parts-dependent Label Noise: Towards Instance-dependent Label Noise
Jun 14, 2020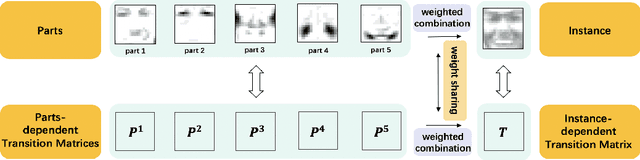
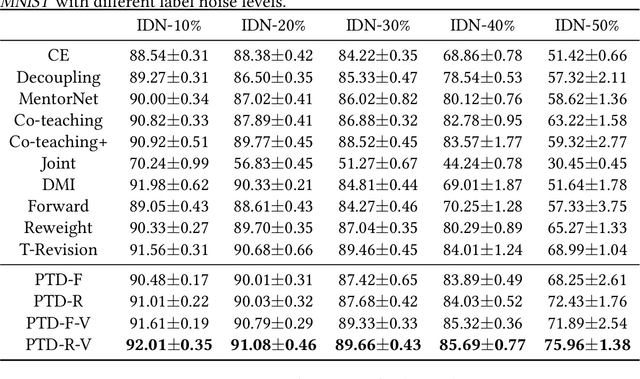
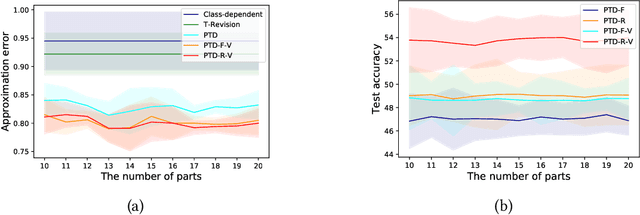
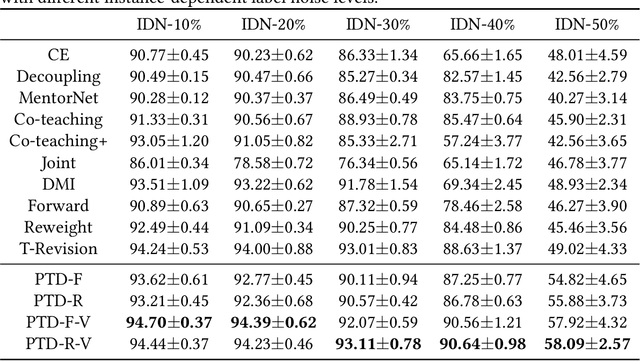
Learning with the \textit{instance-dependent} label noise is challenging, because it is hard to model such real-world noise. Note that there are psychological and physiological evidences showing that we humans perceive instances by decomposing them into parts. Annotators are therefore more likely to annotate instances based on the parts rather than the whole instances. Motivated by this human cognition, in this paper, we approximate the instance-dependent label noise by exploiting \textit{parts-dependent} label noise. Specifically, since instances can be approximately reconstructed by a combination of parts, we approximate the instance-dependent \textit{transition matrix} for an instance by a combination of the transition matrices for the parts of the instance. The transition matrices for parts can be learned by exploiting anchor points (i.e., data points that belong to a specific class almost surely). Empirical evaluations on synthetic and real-world datasets demonstrate our method is superior to the state-of-the-art approaches for learning from the instance-dependent label noise.
Class2Simi: A New Perspective on Learning with Label Noise
Jun 14, 2020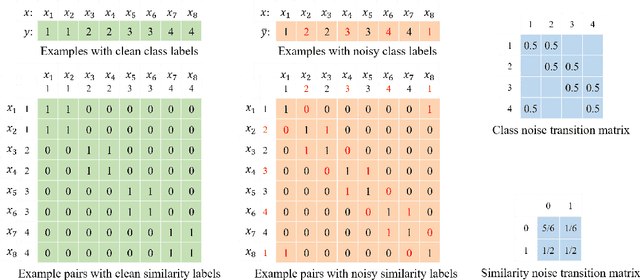


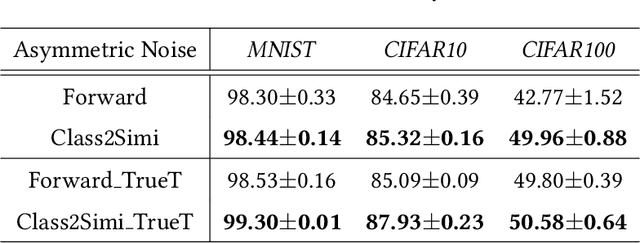
Label noise is ubiquitous in the era of big data. Deep learning algorithms can easily fit the noise and thus cannot generalize well without properly modeling the noise. In this paper, we propose a new perspective on dealing with label noise called Class2Simi. Specifically, we transform the training examples with noisy class labels into pairs of examples with noisy similarity labels and propose a deep learning framework to learn robust classifiers directly with the noisy similarity labels. Note that a class label shows the class that an instance belongs to; while a similarity label indicates whether or not two instances belong to the same class. It is worthwhile to perform the transformation: We prove that the noise rate for the noisy similarity labels is lower than that of the noisy class labels, because similarity labels themselves are robust to noise. For example, given two instances, even if both of their class labels are incorrect, their similarity label could be correct. Due to the lower noise rate, Class2Simi achieves remarkably better classification accuracy than its baselines that directly deals with the noisy class labels.
Boundary-Aware Dense Feature Indicator for Single-Stage 3D Object Detection from Point Clouds
Apr 01, 2020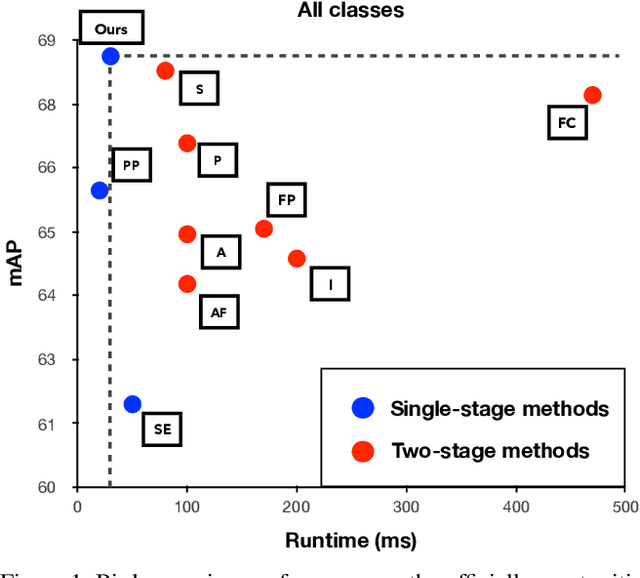

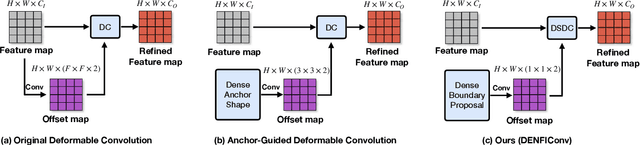
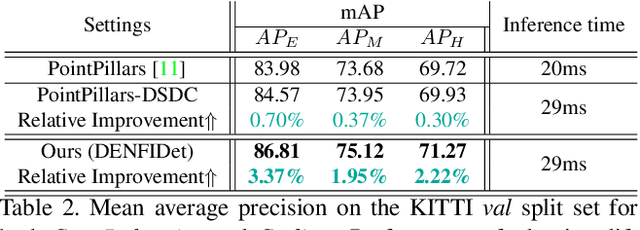
3D object detection based on point clouds has become more and more popular. Some methods propose localizing 3D objects directly from raw point clouds to avoid information loss. However, these methods come with complex structures and significant computational overhead, limiting its broader application in real-time scenarios. Some methods choose to transform the point cloud data into compact tensors first and leverage off-the-shelf 2D detectors to propose 3D objects, which is much faster and achieves state-of-the-art results. However, because of the inconsistency between 2D and 3D data, we argue that the performance of compact tensor-based 3D detectors is restricted if we use 2D detectors without corresponding modification. Specifically, the distribution of point clouds is uneven, with most points gather on the boundary of objects, while detectors for 2D data always extract features evenly. Motivated by this observation, we propose DENse Feature Indicator (DENFI), a universal module that helps 3D detectors focus on the densest region of the point clouds in a boundary-aware manner. Moreover, DENFI is lightweight and guarantees real-time speed when applied to 3D object detectors. Experiments on KITTI dataset show that DENFI improves the performance of the baseline single-stage detector remarkably, which achieves new state-of-the-art performance among previous 3D detectors, including both two-stage and multi-sensor fusion methods, in terms of mAP with a 34FPS detection speed.
Multi-Class Classification from Noisy-Similarity-Labeled Data
Feb 16, 2020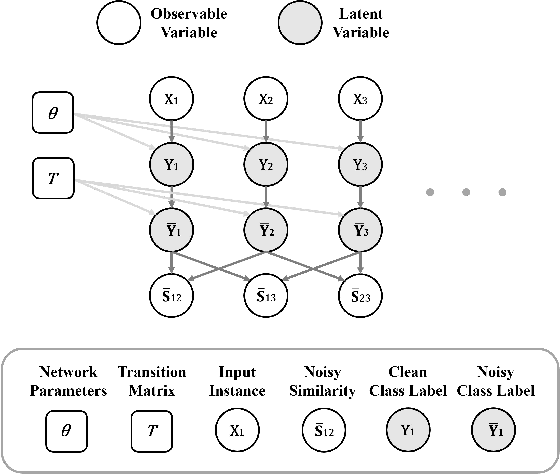
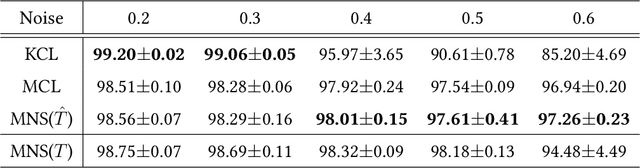

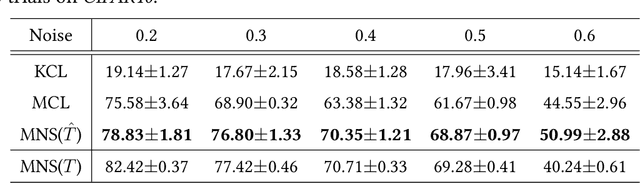
A similarity label indicates whether two instances belong to the same class while a class label shows the class of the instance. Without class labels, a multi-class classifier could be learned from similarity-labeled pairwise data by meta classification learning. However, since the similarity label is less informative than the class label, it is more likely to be noisy. Deep neural networks can easily remember noisy data, leading to overfitting in classification. In this paper, we propose a method for learning from only noisy-similarity-labeled data. Specifically, to model the noise, we employ a noise transition matrix to bridge the class-posterior probability between clean and noisy data. We further estimate the transition matrix from only noisy data and build a novel learning system to learn a classifier which can assign noise-free class labels for instances. Moreover, we theoretically justify how our proposed method generalizes for learning classifiers. Experimental results demonstrate the superiority of the proposed method over the state-of-the-art method on benchmark-simulated and real-world noisy-label datasets.
Adversarial-Learned Loss for Domain Adaptation
Jan 04, 2020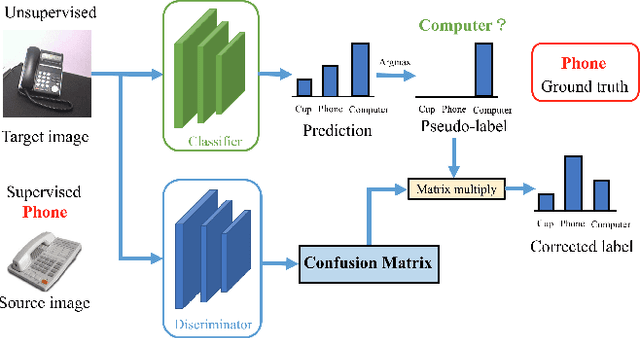
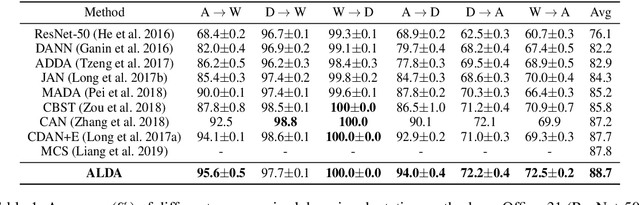
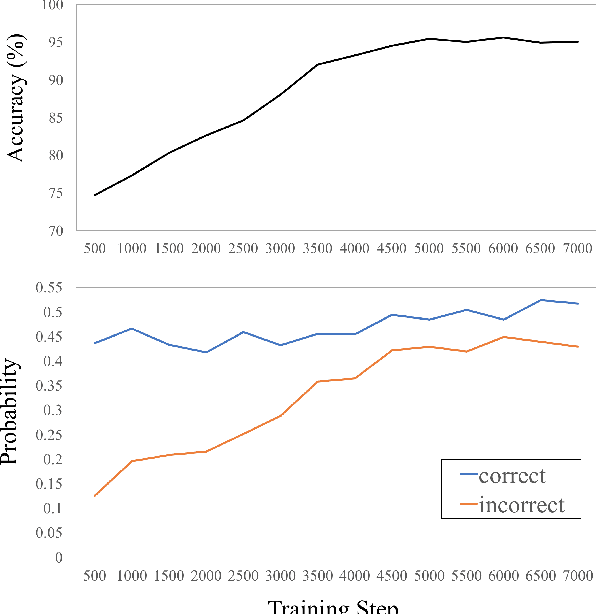
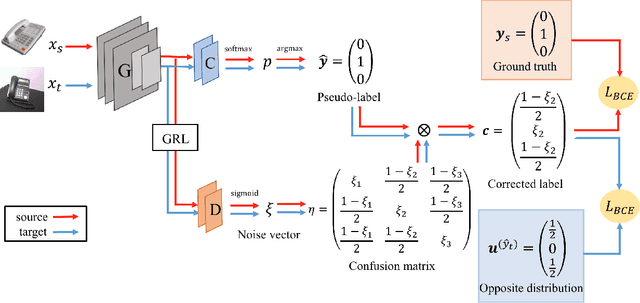
Recently, remarkable progress has been made in learning transferable representation across domains. Previous works in domain adaptation are majorly based on two techniques: domain-adversarial learning and self-training. However, domain-adversarial learning only aligns feature distributions between domains but does not consider whether the target features are discriminative. On the other hand, self-training utilizes the model predictions to enhance the discrimination of target features, but it is unable to explicitly align domain distributions. In order to combine the strengths of these two methods, we propose a novel method called Adversarial-Learned Loss for Domain Adaptation (ALDA). We first analyze the pseudo-label method, a typical self-training method. Nevertheless, there is a gap between pseudo-labels and the ground truth, which can cause incorrect training. Thus we introduce the confusion matrix, which is learned through an adversarial manner in ALDA, to reduce the gap and align the feature distributions. Finally, a new loss function is auto-constructed from the learned confusion matrix, which serves as the loss for unlabeled target samples. Our ALDA outperforms state-of-the-art approaches in four standard domain adaptation datasets. Our code is available at https://github.com/ZJULearning/ALDA.
DBP: Discrimination Based Block-Level Pruning for Deep Model Acceleration
Dec 21, 2019
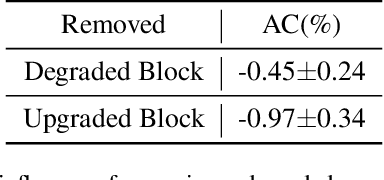
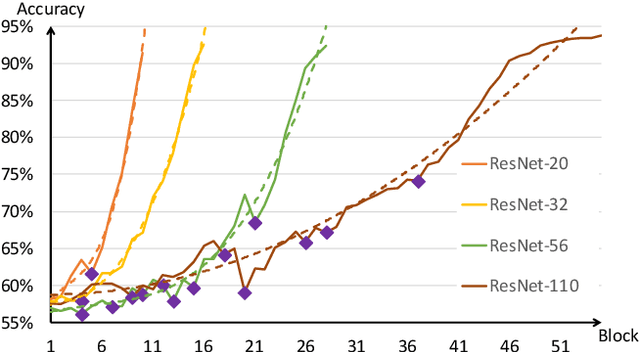
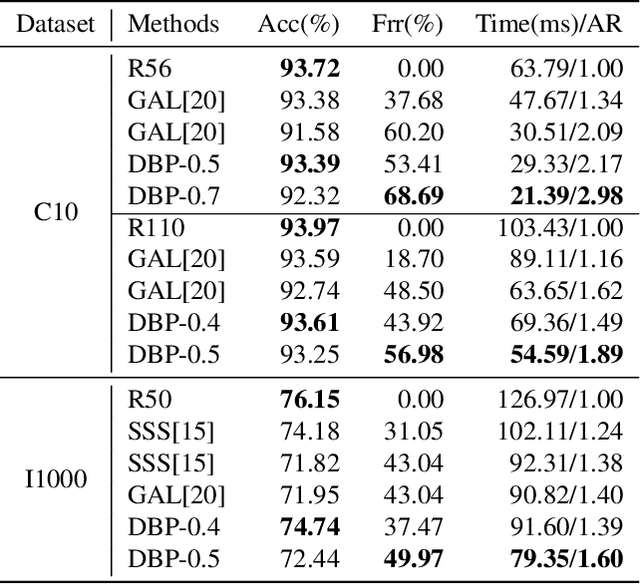
Neural network pruning is one of the most popular methods of accelerating the inference of deep convolutional neural networks (CNNs). The dominant pruning methods, filter-level pruning methods, evaluate their performance through the reduction ratio of computations and deem that a higher reduction ratio of computations is equivalent to a higher acceleration ratio in terms of inference time. However, we argue that they are not equivalent if parallel computing is considered. Given that filter-level pruning only prunes filters in layers and computations in a layer usually run in parallel, most computations reduced by filter-level pruning usually run in parallel with the un-reduced ones. Thus, the acceleration ratio of filter-level pruning is limited. To get a higher acceleration ratio, it is better to prune redundant layers because computations of different layers cannot run in parallel. In this paper, we propose our Discrimination based Block-level Pruning method (DBP). Specifically, DBP takes a sequence of consecutive layers (e.g., Conv-BN-ReLu) as a block and removes redundant blocks according to the discrimination of their output features. As a result, DBP achieves a considerable acceleration ratio by reducing the depth of CNNs. Extensive experiments show that DBP has surpassed state-of-the-art filter-level pruning methods in both accuracy and acceleration ratio. Our code will be made available soon.