 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Face Stylization with a Generative Prior
May 29, 2023In this work, we introduce a new approach for artistic face stylization. Despite existing methods achieving impressive results in this task, there is still room for improvement in generating high-quality stylized faces with diverse styles and accurate facial reconstruction. Our proposed framework, MMFS, supports multi-modal face stylization by leveraging the strengths of StyleGAN and integrates it into an encoder-decoder architecture. Specifically, we use the mid-resolution and high-resolution layers of StyleGAN as the decoder to generate high-quality faces, while aligning its low-resolution layer with the encoder to extract and preserve input facial details. We also introduce a two-stage training strategy, where we train the encoder in the first stage to align the feature maps with StyleGAN and enable a faithful reconstruction of input faces. In the second stage, the entire network is fine-tuned with artistic data for stylized face generation. To enable the fine-tuned model to be applied in zero-shot and one-shot stylization tasks, we train an additional mapping network from the large-scale Contrastive-Language-Image-Pre-training (CLIP) space to a latent $w+$ space of fine-tuned StyleGAN. Qualitative and quantitative experiments show that our framework achieves superior face stylization performance in both one-shot and zero-shot stylization tasks, outperforming state-of-the-art methods by a large margin.
ProSpect: Expanded Conditioning for the Personalization of Attribute-aware Image Generation
May 25, 2023



Personalizing generative models offers a way to guide image generation with user-provided references. Current personalization methods can invert an object or concept into the textual conditioning space and compose new natural sentences for text-to-image diffusion models. However, representing and editing specific visual attributes like material, style, layout, etc. remains a challenge, leading to a lack of disentanglement and editability. To address this, we propose a novel approach that leverages the step-by-step generation process of diffusion models, which generate images from low- to high-frequency information, providing a new perspective on representing, generating, and editing images. We develop Prompt Spectrum Space P*, an expanded textual conditioning space, and a new image representation method called ProSpect. ProSpect represents an image as a collection of inverted textual token embeddings encoded from per-stage prompts, where each prompt corresponds to a specific generation stage (i.e., a group of consecutive steps) of the diffusion model. Experimental results demonstrate that P* and ProSpect offer stronger disentanglement and controllability compared to existing methods. We apply ProSpect in various personalized attribute-aware image generation applications, such as image/text-guided material/style/layout transfer/editing, achieving previously unattainable results with a single image input without fine-tuning the diffusion models.
Semi-Weakly Supervised Object Kinematic Motion Prediction
Apr 03, 2023



Given a 3D object, kinematic motion prediction aims to identify the mobile parts as well as the corresponding motion parameters. Due to the large variations in both topological structure and geometric details of 3D objects, this remains a challenging task and the lack of large scale labeled data also constrain the performance of deep learning based approaches. In this paper, we tackle the task of object kinematic motion prediction problem in a semi-weakly supervised manner. Our key observations are two-fold. First, although 3D dataset with fully annotated motion labels is limited, there are existing datasets and methods for object part semantic segmentation at large scale. Second, semantic part segmentation and mobile part segmentation is not always consistent but it is possible to detect the mobile parts from the underlying 3D structure. Towards this end, we propose a graph neural network to learn the map between hierarchical part-level segmentation and mobile parts parameters, which are further refined based on geometric alignment. This network can be first trained on PartNet-Mobility dataset with fully labeled mobility information and then applied on PartNet dataset with fine-grained and hierarchical part-level segmentation. The network predictions yield a large scale of 3D objects with pseudo labeled mobility information and can further be used for weakly-supervised learning with pre-existing segmentation. Our experiments show there are significant performance boosts with the augmented data for previous method designed for kinematic motion prediction on 3D partial scans.
HairStep: Transfer Synthetic to Real Using Strand and Depth Maps for Single-View 3D Hair Modeling
Mar 05, 2023



In this work, we tackle the challenging problem of learning-based single-view 3D hair modeling. Due to the great difficulty of collecting paired real image and 3D hair data, using synthetic data to provide prior knowledge for real domain becomes a leading solution. This unfortunately introduces the challenge of domain gap. Due to the inherent difficulty of realistic hair rendering, existing methods typically use orientation maps instead of hair images as input to bridge the gap. We firmly think an intermediate representation is essential, but we argue that orientation map using the dominant filtering-based methods is sensitive to uncertain noise and far from a competent representation. Thus, we first raise this issue up and propose a novel intermediate representation, termed as HairStep, which consists of a strand map and a depth map. It is found that HairStep not only provides sufficient information for accurate 3D hair modeling, but also is feasible to be inferred from real images. Specifically, we collect a dataset of 1,250 portrait images with two types of annotations. A learning framework is further designed to transfer real images to the strand map and depth map. It is noted that, an extra bonus of our new dataset is the first quantitative metric for 3D hair modeling. Our experiments show that HairStep narrows the domain gap between synthetic and real and achieves state-of-the-art performance on single-view 3D hair reconstruction.
Self-Supervised Category-Level Articulated Object Pose Estimation with Part-Level SE(3) Equivariance
Feb 28, 2023



Category-level articulated object pose estimation aims to estimate a hierarchy of articulation-aware object poses of an unseen articulated object from a known category. To reduce the heavy annotations needed for supervised learning methods, we present a novel self-supervised strategy that solves this problem without any human labels. Our key idea is to factorize canonical shapes and articulated object poses from input articulated shapes through part-level equivariant shape analysis. Specifically, we first introduce the concept of part-level SE(3) equivariance and devise a network to learn features of such property. Then, through a carefully designed fine-grained pose-shape disentanglement strategy, we expect that canonical spaces to support pose estimation could be induced automatically. Thus, we could further predict articulated object poses as per-part rigid transformations describing how parts transform from their canonical part spaces to the camera space. Extensive experiments demonstrate the effectiveness of our method on both complete and partial point clouds from synthetic and real articulated object datasets.
LitAR: Visually Coherent Lighting for Mobile Augmented Reality
Jan 15, 2023



An accurate understanding of omnidirectional environment lighting is crucial for high-quality virtual object rendering in mobile augmented reality (AR). In particular, to support reflective rendering, existing methods have leveraged deep learning models to estimate or have used physical light probes to capture physical lighting, typically represented in the form of an environment map. However, these methods often fail to provide visually coherent details or require additional setups. For example, the commercial framework ARKit uses a convolutional neural network that can generate realistic environment maps; however the corresponding reflective rendering might not match the physical environments. In this work, we present the design and implementation of a lighting reconstruction framework called LitAR that enables realistic and visually-coherent rendering. LitAR addresses several challenges of supporting lighting information for mobile AR. First, to address the spatial variance problem, LitAR uses two-field lighting reconstruction to divide the lighting reconstruction task into the spatial variance-aware near-field reconstruction and the directional-aware far-field reconstruction. The corresponding environment map allows reflective rendering with correct color tones. Second, LitAR uses two noise-tolerant data capturing policies to ensure data quality, namely guided bootstrapped movement and motion-based automatic capturing. Third, to handle the mismatch between the mobile computation capability and the high computation requirement of lighting reconstruction, LitAR employs two novel real-time environment map rendering techniques called multi-resolution projection and anchor extrapolation. These two techniques effectively remove the need of time-consuming mesh reconstruction while maintaining visual quality.
Inversion-Based Creativity Transfer with Diffusion Models
Nov 23, 2022In this paper, we introduce the task of "Creativity Transfer". The artistic creativity within a painting is the means of expression, which includes not only the painting material, colors, and brushstrokes, but also the high-level attributes including semantic elements, object shape, etc. Previous arbitrary example-guided artistic image generation methods (e.g., style transfer) often fail to control shape changes or convey semantic elements. The pre-trained text-to-image synthesis diffusion probabilistic models have achieved remarkable quality, but they often require extensive textual descriptions to accurately portray attributes of a particular painting. We believe that the uniqueness of an artwork lies precisely in the fact that it cannot be adequately explained with normal language. Our key idea is to learn artistic creativity directly from a single painting and then guide the synthesis without providing complex textual descriptions. Specifically, we assume creativity as a learnable textual description of a painting. We propose an attention-based inversion method, which can efficiently and accurately learn the holistic and detailed information of an image, thus capturing the complete artistic creativity of a painting. We demonstrate the quality and efficiency of our method on numerous paintings of various artists and styles. Code and models are available at https://github.com/zyxElsa/creativity-transfer.
DiffStyler: Controllable Dual Diffusion for Text-Driven Image Stylization
Nov 19, 2022Despite the impressive results of arbitrary image-guided style transfer methods, text-driven image stylization has recently been proposed for transferring a natural image into the stylized one according to textual descriptions of the target style provided by the user. Unlike previous image-to-image transfer approaches, text-guided stylization progress provides users with a more precise and intuitive way to express the desired style. However, the huge discrepancy between cross-modal inputs/outputs makes it challenging to conduct text-driven image stylization in a typical feed-forward CNN pipeline. In this paper, we present DiffStyler on the basis of diffusion models. The cross-modal style information can be easily integrated as guidance during the diffusion progress step-by-step. In particular, we use a dual diffusion processing architecture to control the balance between the content and style of the diffused results. Furthermore, we propose a content image-based learnable noise on which the reverse denoising process is based, enabling the stylization results to better preserve the structure information of the content image. We validate the proposed DiffStyler beyond the baseline methods through extensive qualitative and quantitative experiments.
Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
May 20, 2022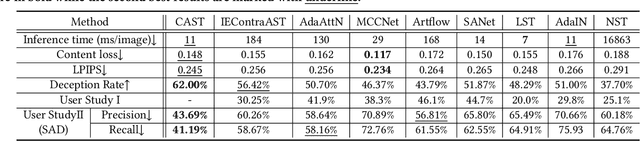

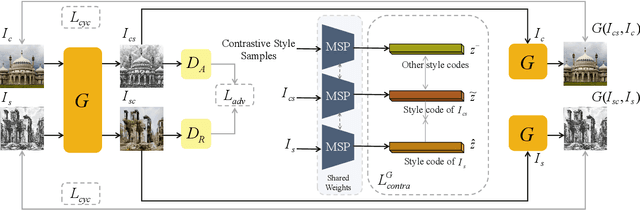
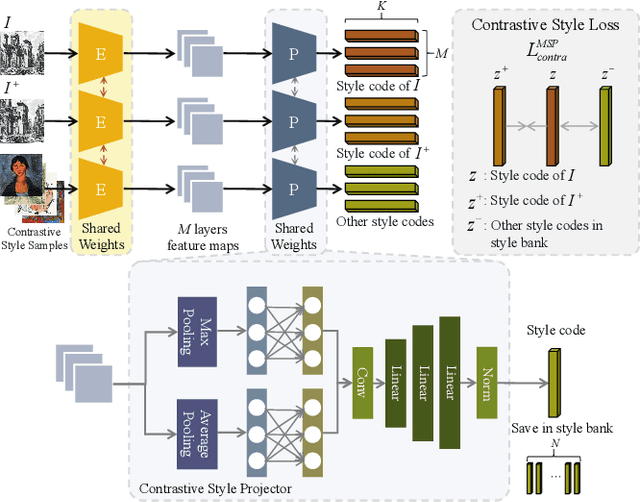
In this work, we tackle the challenging problem of arbitrary image style transfer using a novel style feature representation learning method. A suitable style representation, as a key component in image stylization tasks, is essential to achieve satisfactory results. Existing deep neural network based approaches achieve reasonable results with the guidance from second-order statistics such as Gram matrix of content features. However, they do not leverage sufficient style information, which results in artifacts such as local distortions and style inconsistency. To address these issues, we propose to learn style representation directly from image features instead of their second-order statistics, by analyzing the similarities and differences between multiple styles and considering the style distribution. Specifically, we present Contrastive Arbitrary Style Transfer (CAST), which is a new style representation learning and style transfer method via contrastive learning. Our framework consists of three key components, i.e., a multi-layer style projector for style code encoding, a domain enhancement module for effective learning of style distribution, and a generative network for image style transfer. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results compared to those obtained via state-of-the-art methods. Code and models are available at https://github.com/zyxElsa/CAST_pytorch
Towards Self-Supervised Category-Level Object Pose and Size Estimation
Mar 31, 2022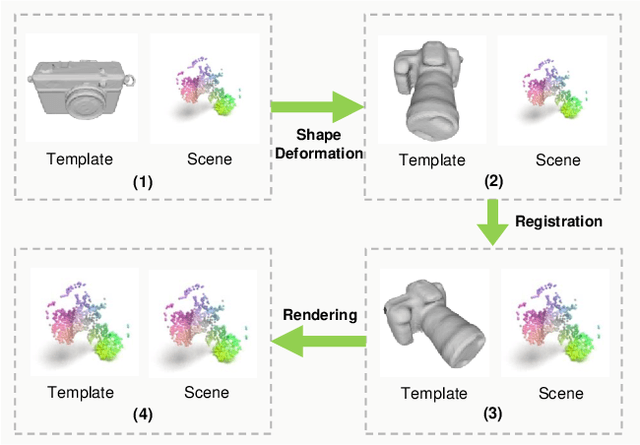

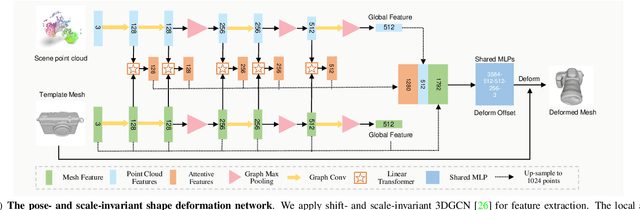
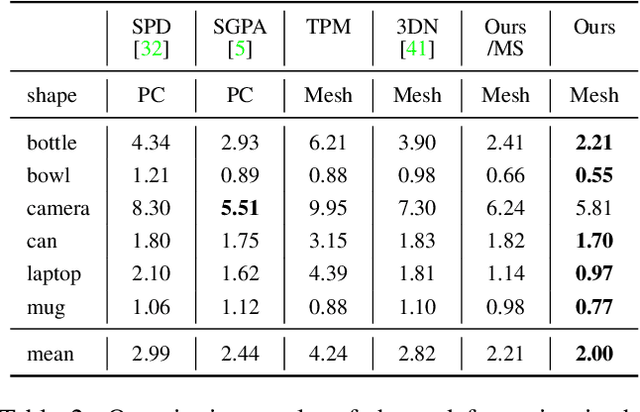
In this work, we tackle the challenging problem of category-level object pose and size estimation from a single depth image. Although previous fully-supervised works have demonstrated promising performance, collecting ground-truth pose labels is generally time-consuming and labor-intensive. Instead, we propose a label-free method that learns to enforce the geometric consistency between category template mesh and observed object point cloud under a self-supervision manner. Specifically, our method consists of three key components: differentiable shape deformation, registration, and rendering. In particular, shape deformation and registration are applied to the template mesh to eliminate the differences in shape, pose and scale. A differentiable renderer is then deployed to enforce geometric consistency between point clouds lifted from the rendered depth and the observed scene for self-supervision. We evaluate our approach on real-world datasets and find that our approach outperforms the simple traditional baseline by large margins while being competitive with some fully-supervised approaches.