 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Human and LLM Preferences
Feb 17, 2024



As a relative quality comparison of model responses, human and Large Language Model (LLM) preferences serve as common alignment goals in model fine-tuning and criteria in evaluation. Yet, these preferences merely reflect broad tendencies, resulting in less explainable and controllable models with potential safety risks. In this work, we dissect the preferences of human and 32 different LLMs to understand their quantitative composition, using annotations from real-world user-model conversations for a fine-grained, scenario-wise analysis. We find that humans are less sensitive to errors, favor responses that support their stances, and show clear dislike when models admit their limits. On the contrary, advanced LLMs like GPT-4-Turbo emphasize correctness, clarity, and harmlessness more. Additionally, LLMs of similar sizes tend to exhibit similar preferences, regardless of their training methods, and fine-tuning for alignment does not significantly alter the preferences of pretrained-only LLMs. Finally, we show that preference-based evaluation can be intentionally manipulated. In both training-free and training-based settings, aligning a model with the preferences of judges boosts scores, while injecting the least preferred properties lowers them. This results in notable score shifts: up to 0.59 on MT-Bench (1-10 scale) and 31.94 on AlpacaEval 2.0 (0-100 scale), highlighting the significant impact of this strategic adaptation. Interactive Demo: https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization Dataset: https://huggingface.co/datasets/GAIR/preference-dissection Code: https://github.com/GAIR-NLP/Preference-Dissection
Is it Possible to Edit Large Language Models Robustly?
Feb 08, 2024Large language models (LLMs) have played a pivotal role in building communicative AI to imitate human behaviors but face the challenge of efficient customization. To tackle this challenge, recent studies have delved into the realm of model editing, which manipulates specific memories of language models and changes the related language generation. However, the robustness of model editing remains an open question. This work seeks to understand the strengths and limitations of editing methods, thus facilitating robust, realistic applications of communicative AI. Concretely, we conduct extensive analysis to address the three key research questions. Q1: Can edited LLMs behave consistently resembling communicative AI in realistic situations? Q2: To what extent does the rephrasing of prompts lead LLMs to deviate from the edited knowledge memory? Q3: Which knowledge features are correlated with the performance and robustness of editing? Our experimental results uncover a substantial disparity between existing editing methods and the practical application of LLMs. On rephrased prompts that are complex and flexible but common in realistic applications, the performance of editing experiences a significant decline. Further analysis shows that more popular knowledge is memorized better, easier to recall, and more challenging to edit effectively.
GLaPE: Gold Label-agnostic Prompt Evaluation and Optimization for Large Language Model
Feb 04, 2024



Despite the rapid progress of large language models (LLMs), their task performance remains sensitive to prompt design. Recent studies have explored leveraging the LLM itself as an optimizer to identify optimal prompts that maximize task accuracy. However, when evaluating prompts, such approaches heavily rely on elusive manually annotated gold labels to calculate task accuracy for each candidate prompt, which hinders the widespread implementation and generality. To overcome the limitation, this work proposes a gold label-agnostic prompt evaluation (GLaPE) to alleviate dependence on gold labels. Motivated by the observed correlation between self-consistency and the accuracy of the answer, we adopt self-consistency as the initial evaluation score. Subsequently, we refine the scores of prompts producing identical answers to be mutually consistent. Experimental results show that GLaPE provides reliable evaluations uniform with accuracy, even in the absence of gold labels. Moreover, on six popular reasoning tasks, our GLaPE-based prompt optimization yields effective prompts comparable to accuracy-based ones. The code is publicly available at https://github.com/thunderous77/GLaPE.
Sparse is Enough in Fine-tuning Pre-trained Large Language Model
Dec 19, 2023With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation, including Adapters, Bia-only, and the recently widely used Low-Rank Adaptation. Although these methods have demonstrated their effectiveness to some extent and have been widely applied, the underlying principles are still unclear. In this paper, we reveal the transition of loss landscape in the downstream domain from random initialization to pre-trained initialization, that is, from low-amplitude oscillation to high-amplitude oscillation. The parameter gradients exhibit a property akin to sparsity, where a small fraction of components dominate the total gradient norm, for instance, 1% of the components account for 99% of the gradient. This property ensures that the pre-trained model can easily find a flat minimizer which guarantees the model's ability to generalize even with a low number of trainable parameters. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
A Novel Energy based Model Mechanism for Multi-modal Aspect-Based Sentiment Analysis
Dec 15, 2023Multi-modal aspect-based sentiment analysis (MABSA) has recently attracted increasing attention. The span-based extraction methods, such as FSUIE, demonstrate strong performance in sentiment analysis due to their joint modeling of input sequences and target labels. However, previous methods still have certain limitations: (i) They ignore the difference in the focus of visual information between different analysis targets (aspect or sentiment). (ii) Combining features from uni-modal encoders directly may not be sufficient to eliminate the modal gap and can cause difficulties in capturing the image-text pairwise relevance. (iii) Existing span-based methods for MABSA ignore the pairwise relevance of target span boundaries. To tackle these limitations, we propose a novel framework called DQPSA for multi-modal sentiment analysis. Specifically, our model contains a Prompt as Dual Query (PDQ) module that uses the prompt as both a visual query and a language query to extract prompt-aware visual information and strengthen the pairwise relevance between visual information and the analysis target. Additionally, we introduce an Energy-based Pairwise Expert (EPE) module that models the boundaries pairing of the analysis target from the perspective of an Energy-based Model. This expert predicts aspect or sentiment span based on pairwise stability. Experiments on three widely used benchmarks demonstrate that DQPSA outperforms previous approaches and achieves a new state-of-the-art performance.
Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents
Nov 20, 2023



Large language models (LLMs) have dramatically enhanced the field of language intelligence, as demonstrably evidenced by their formidable empirical performance across a spectrum of complex reasoning tasks. Additionally, theoretical proofs have illuminated their emergent reasoning capabilities, providing a compelling showcase of their advanced cognitive abilities in linguistic contexts. Critical to their remarkable efficacy in handling complex reasoning tasks, LLMs leverage the intriguing chain-of-thought (CoT) reasoning techniques, obliging them to formulate intermediate steps en route to deriving an answer. The CoT reasoning approach has not only exhibited proficiency in amplifying reasoning performance but also in enhancing interpretability, controllability, and flexibility. In light of these merits, recent research endeavors have extended CoT reasoning methodologies to nurture the development of autonomous language agents, which adeptly adhere to language instructions and execute actions within varied environments. This survey paper orchestrates a thorough discourse, penetrating vital research dimensions, encompassing: (i) the foundational mechanics of CoT techniques, with a focus on elucidating the circumstances and justification behind its efficacy; (ii) the paradigm shift in CoT; and (iii) the burgeoning of language agents fortified by CoT approaches. Prospective research avenues envelop explorations into generalization, efficiency, customization, scaling, and safety. This paper caters to a wide audience, including beginners seeking comprehensive knowledge of CoT reasoning and language agents, as well as experienced researchers interested in foundational mechanics and engaging in cutting-edge discussions on these topics. A repository for the related papers is available at https://github.com/Zoeyyao27/CoT-Igniting-Agent.
Multi-grained Evidence Inference for Multi-choice Reading Comprehension
Oct 27, 2023



Multi-choice Machine Reading Comprehension (MRC) is a major and challenging task for machines to answer questions according to provided options. Answers in multi-choice MRC cannot be directly extracted in the given passages, and essentially require machines capable of reasoning from accurate extracted evidence. However, the critical evidence may be as simple as just one word or phrase, while it is hidden in the given redundant, noisy passage with multiple linguistic hierarchies from phrase, fragment, sentence until the entire passage. We thus propose a novel general-purpose model enhancement which integrates multi-grained evidence comprehensively, named Multi-grained evidence inferencer (Mugen), to make up for the inability. Mugen extracts three different granularities of evidence: coarse-, middle- and fine-grained evidence, and integrates evidence with the original passages, achieving significant and consistent performance improvement on four multi-choice MRC benchmarks.
* Accepted by TASLP 2023, vol. 31, pp. 3896-3907
Self-prompted Chain-of-Thought on Large Language Models for Open-domain Multi-hop Reasoning
Oct 23, 2023



In open-domain question-answering (ODQA), most existing questions require single-hop reasoning on commonsense. To further extend this task, we officially introduce open-domain multi-hop reasoning (ODMR) by answering multi-hop questions with explicit reasoning steps in open-domain setting. Recently, large language models (LLMs) have found significant utility in facilitating ODQA without external corpus. Furthermore, chain-of-thought (CoT) prompting boosts the reasoning capability of LLMs to a greater extent with manual or automated paradigms. However, existing automated methods lack of quality assurance, while manual approaches suffer from limited scalability and poor diversity, hindering the capabilities of LLMs. In this paper, we propose Self-prompted Chain-of-Thought (SP-CoT), an automated framework to mass-produce high quality CoTs of LLMs, by LLMs and for LLMs. SP-CoT introduces an automated generation pipeline of high quality ODMR datasets, an adaptive sampler for in-context CoT selection and self-prompted inference via in-context learning. Extensive experiments on four multi-hop question-answering benchmarks show that our proposed SP-CoT not only significantly surpasses the previous SOTA methods on large-scale (175B) LLMs, but also nearly doubles the zero-shot performance of small-scale (13B) LLMs. Further analysis reveals the remarkable capability of SP-CoT to elicit direct and concise intermediate reasoning steps by recalling $\sim$50\% of intermediate answers on MuSiQue-Ans dataset.
Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models
Oct 11, 2023



Large language models (LLMs) have unveiled remarkable reasoning capabilities by exploiting chain-of-thought (CoT) prompting, which generates intermediate reasoning chains to serve as the rationale for deriving the answer. However, current CoT methods either simply employ general prompts such as Let's think step by step, or heavily rely on handcrafted task-specific demonstrations to attain preferable performances, thereby engendering an inescapable gap between performance and generalization. To bridge this gap, we propose Meta-CoT, a generalizable CoT prompting method in mixed-task scenarios where the type of input questions is unknown. Meta-CoT firstly categorizes the scenario based on the input question and subsequently constructs diverse demonstrations from the corresponding data pool in an automatic pattern. Meta-CoT simultaneously enjoys remarkable performances on ten public benchmark reasoning tasks and superior generalization capabilities. Notably, Meta-CoT achieves the state-of-the-art result on SVAMP (93.7%) without any additional program-aided methods. Our further experiments on five out-of-distribution datasets verify the stability and generality of Meta-CoT.
Generative Judge for Evaluating Alignment
Oct 09, 2023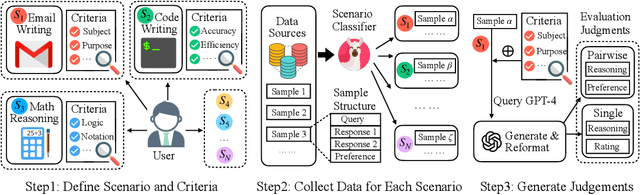
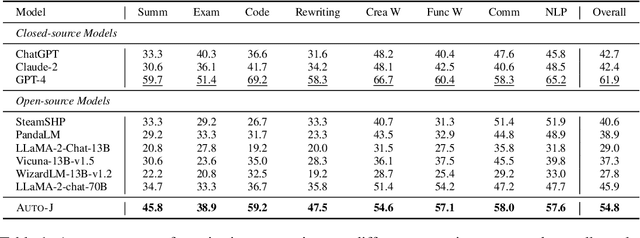
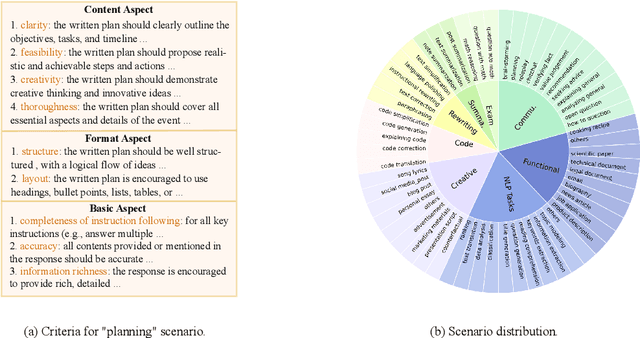
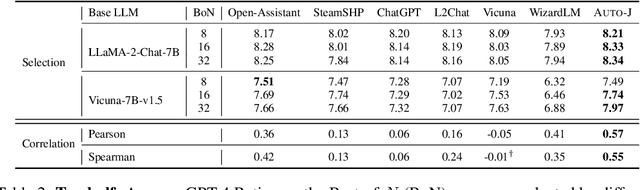
The rapid development of Large Language Models (LLMs) has substantially expanded the range of tasks they can address. In the field of Natural Language Processing (NLP), researchers have shifted their focus from conventional NLP tasks (e.g., sequence tagging and parsing) towards tasks that revolve around aligning with human needs (e.g., brainstorming and email writing). This shift in task distribution imposes new requirements on evaluating these aligned models regarding generality (i.e., assessing performance across diverse scenarios), flexibility (i.e., examining under different protocols), and interpretability (i.e., scrutinizing models with explanations). In this paper, we propose a generative judge with 13B parameters, Auto-J, designed to address these challenges. Our model is trained on user queries and LLM-generated responses under massive real-world scenarios and accommodates diverse evaluation protocols (e.g., pairwise response comparison and single-response evaluation) with well-structured natural language critiques. To demonstrate the efficacy of our approach, we construct a new testbed covering 58 different scenarios. Experimentally, Auto-J outperforms a series of strong competitors, including both open-source and closed-source models, by a large margin. We also provide detailed analysis and case studies to further reveal the potential of our method and make a variety of resources public at https://github.com/GAIR-NLP/auto-j.