 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVox-Fusion: Dense Tracking and Mapping with Voxel-based Neural Implicit Representation
Oct 28, 2022In this work, we present a dense tracking and mapping system named Vox-Fusion, which seamlessly fuses neural implicit representations with traditional volumetric fusion methods. Our approach is inspired by the recently developed implicit mapping and positioning system and further extends the idea so that it can be freely applied to practical scenarios. Specifically, we leverage a voxel-based neural implicit surface representation to encode and optimize the scene inside each voxel. Furthermore, we adopt an octree-based structure to divide the scene and support dynamic expansion, enabling our system to track and map arbitrary scenes without knowing the environment like in previous works. Moreover, we proposed a high-performance multi-process framework to speed up the method, thus supporting some applications that require real-time performance. The evaluation results show that our methods can achieve better accuracy and completeness than previous methods. We also show that our Vox-Fusion can be used in augmented reality and virtual reality applications. Our source code is publicly available at https://github.com/zju3dv/Vox-Fusion.
Approximate Computing and the Efficient Machine Learning Expedition
Oct 02, 2022
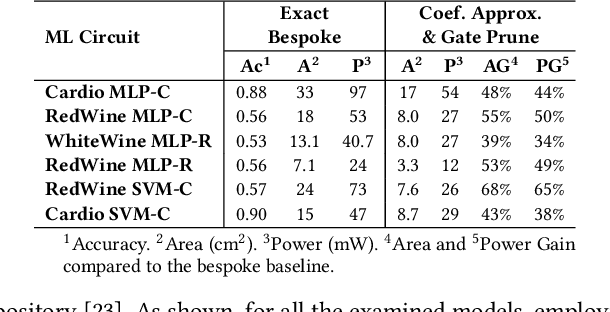
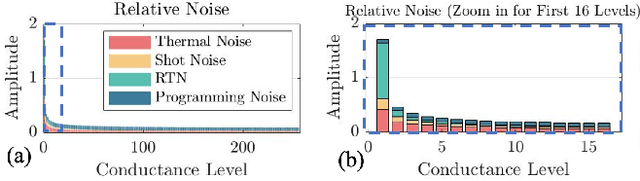
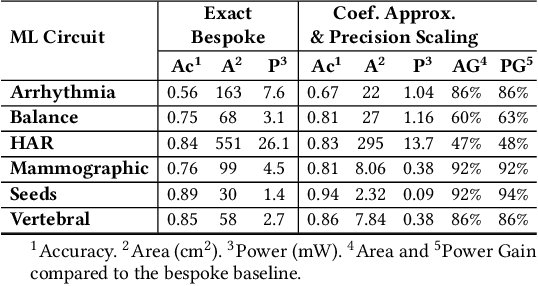
Approximate computing (AxC) has been long accepted as a design alternative for efficient system implementation at the cost of relaxed accuracy requirements. Despite the AxC research activities in various application domains, AxC thrived the past decade when it was applied in Machine Learning (ML). The by definition approximate notion of ML models but also the increased computational overheads associated with ML applications-that were effectively mitigated by corresponding approximations-led to a perfect matching and a fruitful synergy. AxC for AI/ML has transcended beyond academic prototypes. In this work, we enlighten the synergistic nature of AxC and ML and elucidate the impact of AxC in designing efficient ML systems. To that end, we present an overview and taxonomy of AxC for ML and use two descriptive application scenarios to demonstrate how AxC boosts the efficiency of ML systems.
Fed-CBS: A Heterogeneity-Aware Client Sampling Mechanism for Federated Learning via Class-Imbalance Reduction
Sep 30, 2022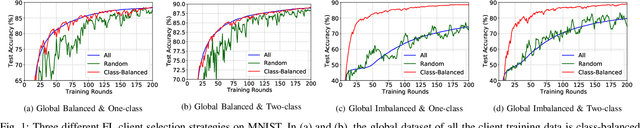
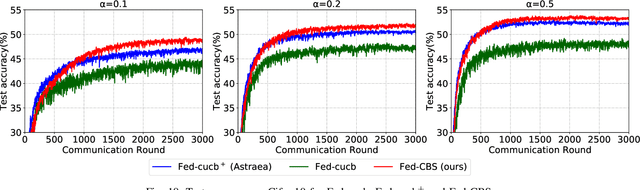
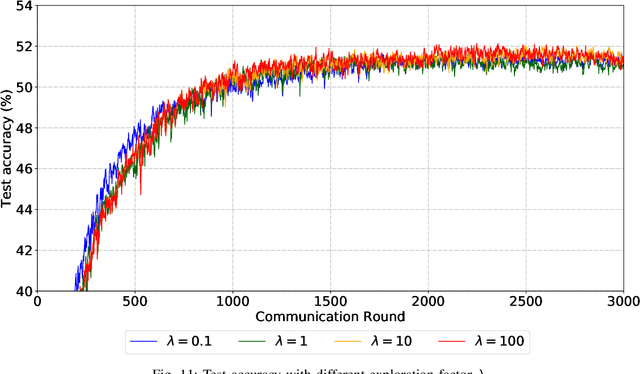
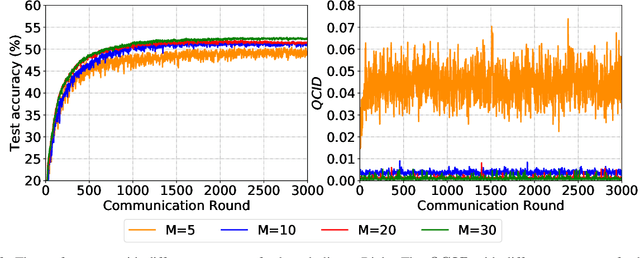
Due to limited communication capacities of edge devices, most existing federated learning (FL) methods randomly select only a subset of devices to participate in training for each communication round. Compared with engaging all the available clients, the random-selection mechanism can lead to significant performance degradation on non-IID (independent and identically distributed) data. In this paper, we show our key observation that the essential reason resulting in such performance degradation is the class-imbalance of the grouped data from randomly selected clients. Based on our key observation, we design an efficient heterogeneity-aware client sampling mechanism, i.e., Federated Class-balanced Sampling (Fed-CBS), which can effectively reduce class-imbalance of the group dataset from the intentionally selected clients. In particular, we propose a measure of class-imbalance and then employ homomorphic encryption to derive this measure in a privacy-preserving way. Based on this measure, we also design a computation-efficient client sampling strategy, such that the actively selected clients will generate a more class-balanced grouped dataset with theoretical guarantees. Extensive experimental results demonstrate Fed-CBS outperforms the status quo approaches. Furthermore, it achieves comparable or even better performance than the ideal setting where all the available clients participate in the FL training.
NashAE: Disentangling Representations through Adversarial Covariance Minimization
Sep 21, 2022We present a self-supervised method to disentangle factors of variation in high-dimensional data that does not rely on prior knowledge of the underlying variation profile (e.g., no assumptions on the number or distribution of the individual latent variables to be extracted). In this method which we call NashAE, high-dimensional feature disentanglement is accomplished in the low-dimensional latent space of a standard autoencoder (AE) by promoting the discrepancy between each encoding element and information of the element recovered from all other encoding elements. Disentanglement is promoted efficiently by framing this as a minmax game between the AE and an ensemble of regression networks which each provide an estimate of an element conditioned on an observation of all other elements. We quantitatively compare our approach with leading disentanglement methods using existing disentanglement metrics. Furthermore, we show that NashAE has increased reliability and increased capacity to capture salient data characteristics in the learned latent representation.
Fine-grain Inference on Out-of-Distribution Data with Hierarchical Classification
Sep 09, 2022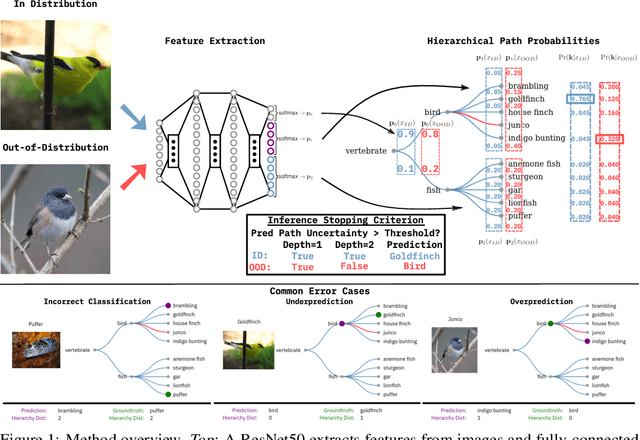
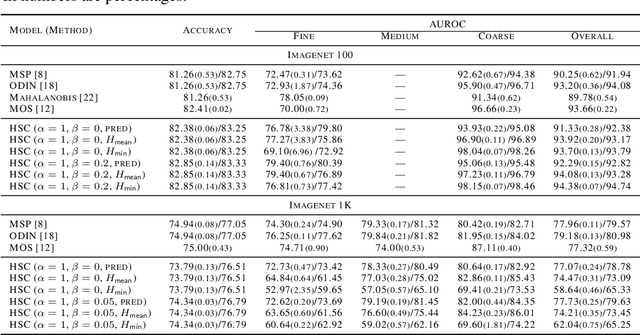
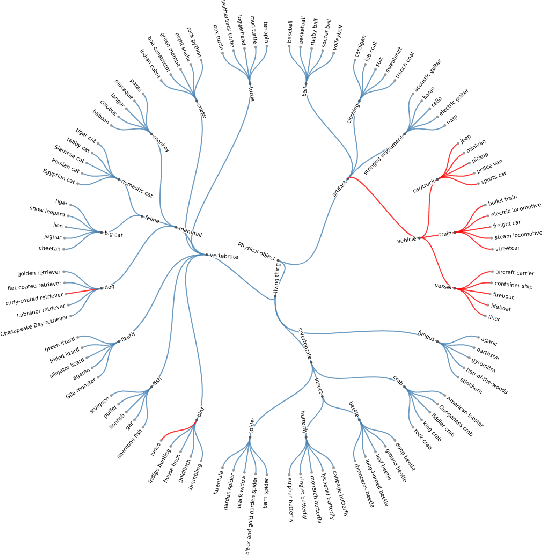
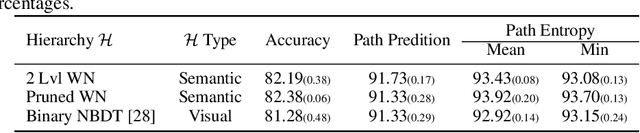
Machine learning methods must be trusted to make appropriate decisions in real-world environments, even when faced with out-of-distribution (OOD) samples. Many current approaches simply aim to detect OOD examples and alert the user when an unrecognized input is given. However, when the OOD sample significantly overlaps with the training data, a binary anomaly detection is not interpretable or explainable, and provides little information to the user. We propose a new model for OOD detection that makes predictions at varying levels of granularity as the inputs become more ambiguous, the model predictions become coarser and more conservative. Consider an animal classifier that encounters an unknown bird species and a car. Both cases are OOD, but the user gains more information if the classifier recognizes that its uncertainty over the particular species is too large and predicts bird instead of detecting it as OOD. Furthermore, we diagnose the classifiers performance at each level of the hierarchy improving the explainability and interpretability of the models predictions. We demonstrate the effectiveness of hierarchical classifiers for both fine- and coarse-grained OOD tasks.
FADE: Enabling Large-Scale Federated Adversarial Training on Resource-Constrained Edge Devices
Sep 08, 2022
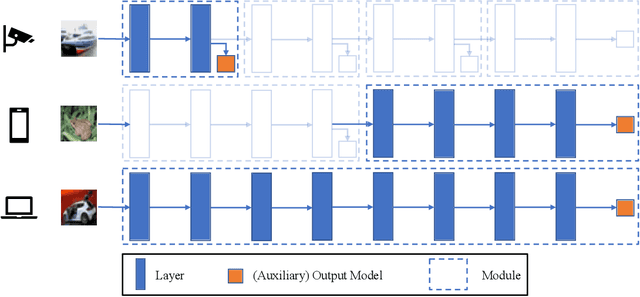
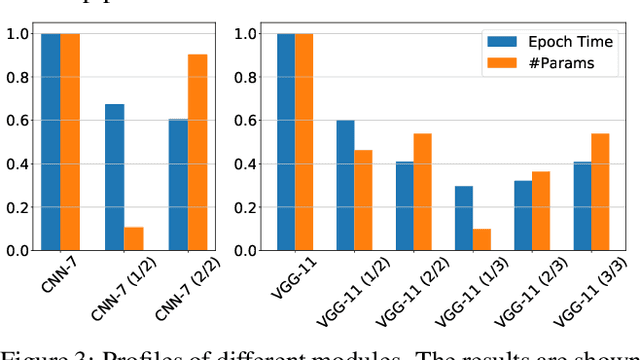
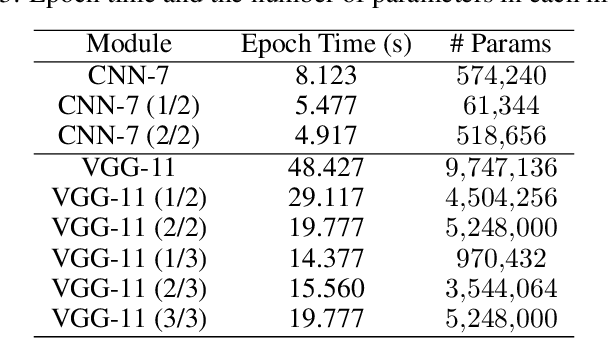
Adversarial Training (AT) has been proven to be an effective method of introducing strong adversarial robustness into deep neural networks. However, the high computational cost of AT prohibits the deployment of large-scale AT on resource-constrained edge devices, e.g., with limited computing power and small memory footprint, in Federated Learning (FL) applications. Very few previous studies have tried to tackle these constraints in FL at the same time. In this paper, we propose a new framework named Federated Adversarial Decoupled Learning (FADE) to enable AT on resource-constrained edge devices in FL. FADE reduces the computation and memory usage by applying Decoupled Greedy Learning (DGL) to federated adversarial training such that each client only needs to perform AT on a small module of the entire model in each communication round. In addition, we improve vanilla DGL by adding an auxiliary weight decay to alleviate objective inconsistency and achieve better performance. FADE offers a theoretical guarantee for the adversarial robustness and convergence. The experimental results also show that FADE can significantly reduce the computing resources consumed by AT while maintaining almost the same accuracy and robustness as fully joint training.
Joint Optimization of STAR-RIS Assisted UAV Communication Systems
Sep 08, 2022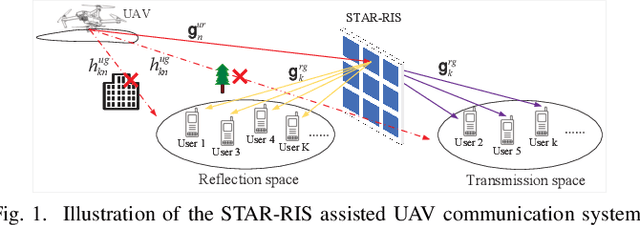
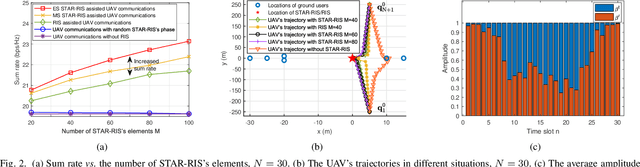
In this letter, we study the simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted unmanned aerial vehicle (UAV) communications. Our goal is to maximize the sum rate of all users by jointly optimizing the STAR-RIS's beamforming vectors, the UAV's trajectory and power allocation. We decompose the formulated non-convex problem into three subproblems and solve them alternately to obtain the solution. Simulations show that: 1) the STAR-RIS achieves a higher sum rate than traditional RIS; 2) to exploit the benefits of STAR-RIS, the UAV's trajectory is closer to STAR-RIS than that of RIS; 3) the energy splitting for reflection and transmission highly depends on the real-time trajectory of UAV.
* 5 pages, 4 figures
Learning and Compositionality: a Unification Attempt via Connectionist Probabilistic Programming
Aug 26, 2022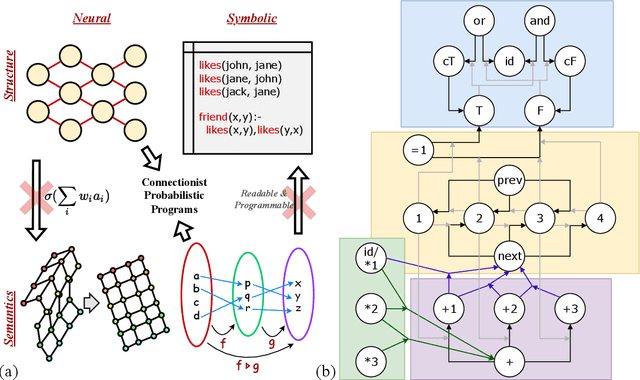
We consider learning and compositionality as the key mechanisms towards simulating human-like intelligence. While each mechanism is successfully achieved by neural networks and symbolic AIs, respectively, it is the combination of the two mechanisms that makes human-like intelligence possible. Despite the numerous attempts on building hybrid neuralsymbolic systems, we argue that our true goal should be unifying learning and compositionality, the core mechanisms, instead of neural and symbolic methods, the surface approaches to achieve them. In this work, we review and analyze the strengths and weaknesses of neural and symbolic methods by separating their forms and meanings (structures and semantics), and propose Connectionist Probabilistic Program (CPPs), a framework that connects connectionist structures (for learning) and probabilistic program semantics (for compositionality). Under the framework, we design a CPP extension for small scale sequence modeling and provide a learning algorithm based on Bayesian inference. Although challenges exist in learning complex patterns without supervision, our early results demonstrate CPP's successful extraction of concepts and relations from raw sequential data, an initial step towards compositional learning.
Self-Trained Proposal Networks for the Open World
Aug 23, 2022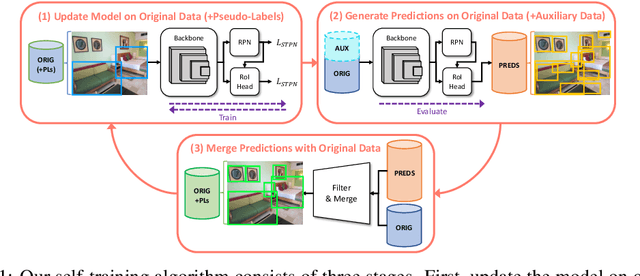
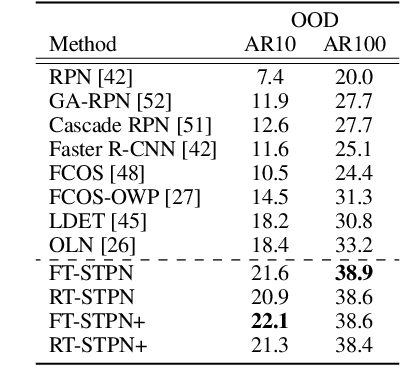
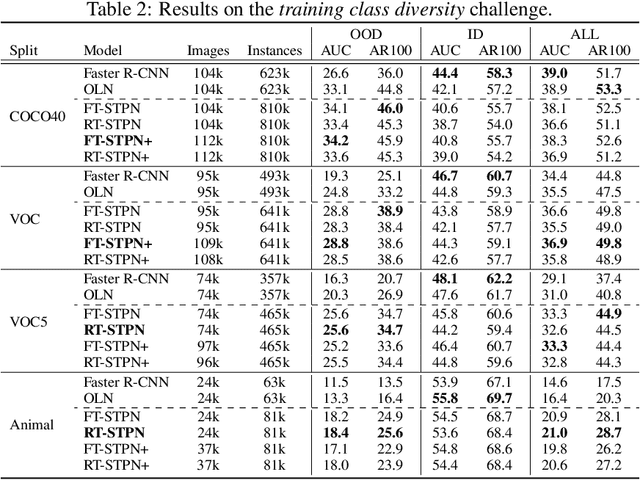
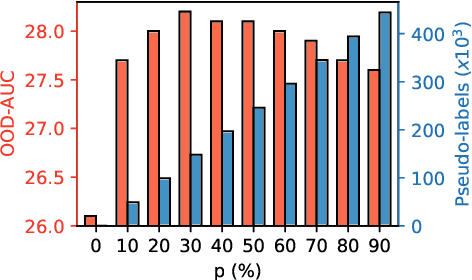
Deep learning-based object proposal methods have enabled significant advances in many computer vision pipelines. However, current state-of-the-art proposal networks use a closed-world assumption, meaning they are only trained to detect instances of the training classes while treating every other region as background. This style of solution fails to provide high recall on out-of-distribution objects, rendering it inadequate for use in realistic open-world applications where novel object categories of interest may be observed. To better detect all objects, we propose a classification-free Self-Trained Proposal Network (STPN) that leverages a novel self-training optimization strategy combined with dynamically weighted loss functions that account for challenges such as class imbalance and pseudo-label uncertainty. Not only is our model designed to excel in existing optimistic open-world benchmarks, but also in challenging operating environments where there is significant label bias. To showcase this, we devise two challenges to test the generalization of proposal models when the training data contains (1) less diversity within the labeled classes, and (2) fewer labeled instances. Our results show that STPN achieves state-of-the-art novel object generalization on all tasks.
Vox-Surf: Voxel-based Implicit Surface Representation
Aug 21, 2022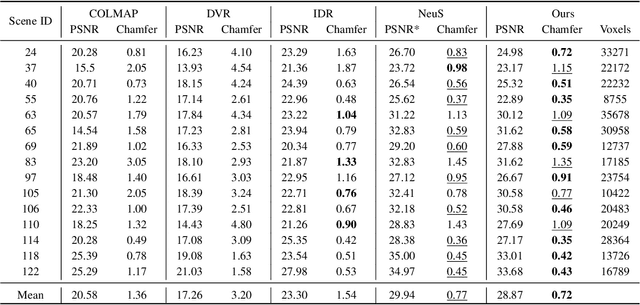
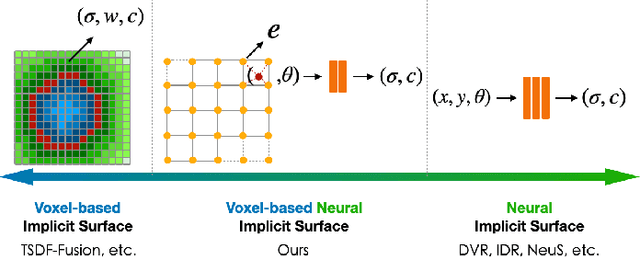
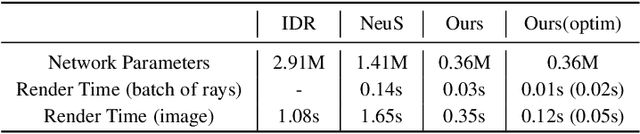
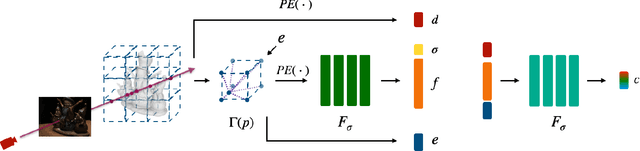
Virtual content creation and interaction play an important role in modern 3D applications such as AR and VR. Recovering detailed 3D models from real scenes can significantly expand the scope of its applications and has been studied for decades in the computer vision and computer graphics community. We propose Vox-Surf, a voxel-based implicit surface representation. Our Vox-Surf divides the space into finite bounded voxels. Each voxel stores geometry and appearance information in its corner vertices. Vox-Surf is suitable for almost any scenario thanks to sparsity inherited from voxel representation and can be easily trained from multiple view images. We leverage the progressive training procedure to extract important voxels gradually for further optimization so that only valid voxels are preserved, which greatly reduces the number of sampling points and increases rendering speed.The fine voxels can also be considered as the bounding volume for collision detection.The experiments show that Vox-Surf representation can learn delicate surface details and accurate color with less memory and faster rendering speed than other methods.We also show that Vox-Surf can be more practical in scene editing and AR applications.