 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Empowered 6G Intelligent Networks: From Massive MIMO Processing to Semantic Communication
May 08, 2022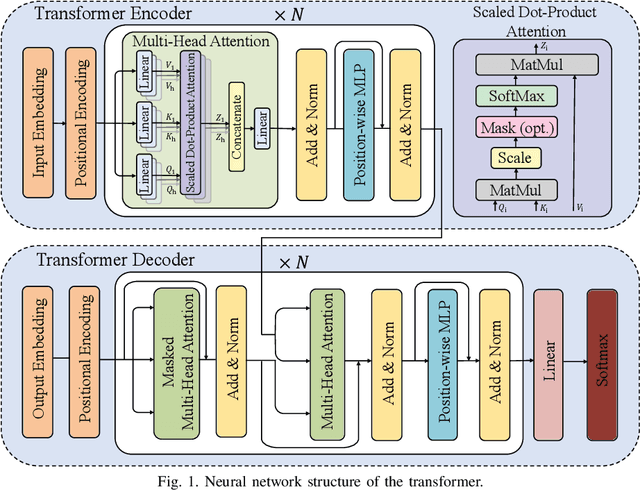
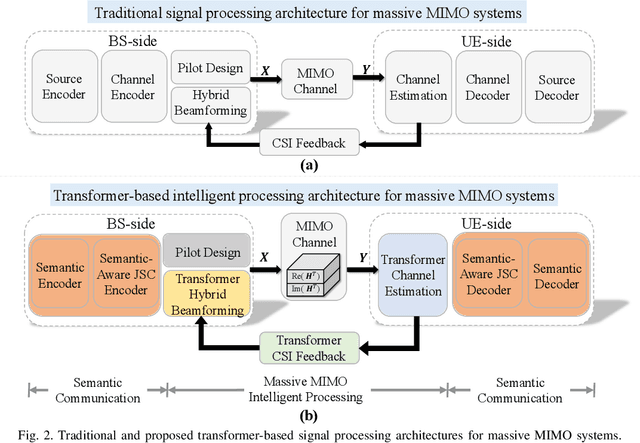
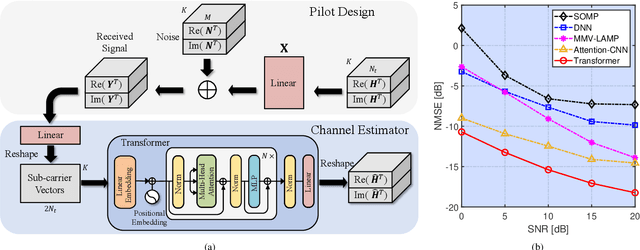
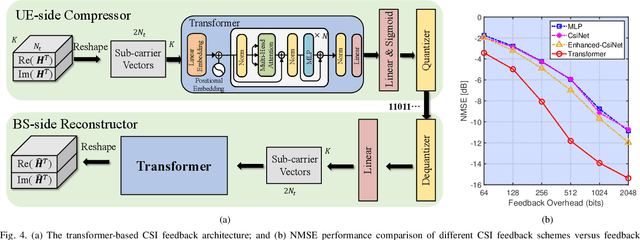
6G wireless networks are foreseen to speed up the convergence of the physical and cyber worlds and to enable a paradigm-shift in the way we deploy and exploit communication networks. Machine learning, in particular deep learning (DL), is going to be one of the key technological enablers of 6G by offering a new paradigm for the design and optimization of networks with a high level of intelligence. In this article, we introduce an emerging DL architecture, known as the transformer, and discuss its potential impact on 6G network design. We first discuss the differences between the transformer and classical DL architectures, and emphasize the transformer's self-attention mechanism and strong representation capabilities, which make it particularly appealing in tackling various challenges in wireless network design. Specifically, we propose transformer-based solutions for massive multiple-input multiple-output (MIMO) systems and various semantic communication problems in 6G networks. Finally, we discuss key challenges and open issues in transformer-based solutions, and identify future research directions for their deployment in intelligent 6G networks.
Sensing RISs: Enabling Dimension-Independent CSI Acquisition for Beamforming
Apr 28, 2022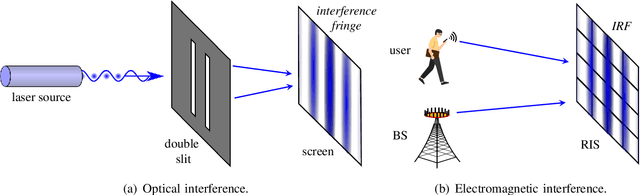
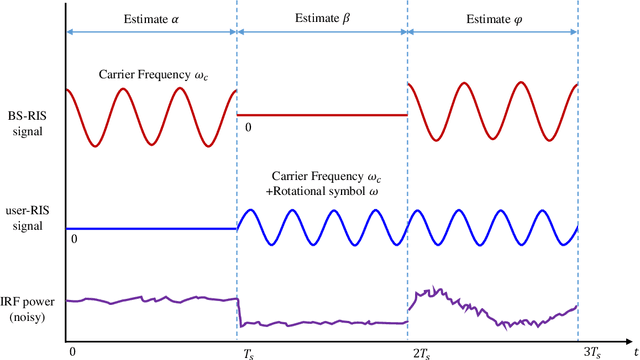
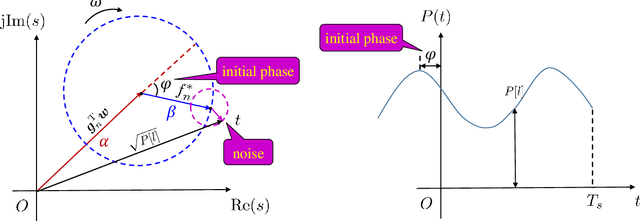
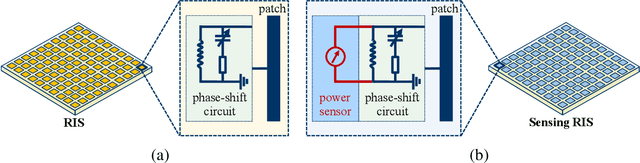
Reconfigurable intelligent surfaces (RISs) are envisioned as a potentially transformative technology for future wireless communications. However, RIS's inability to process signals and their attendant increased channel dimension have brought new challenges to RIS-assisted systems, which greatly increases the pilot overhead required for channel estimation. To address these problems, several prior contributions that enhance the hardware architecture of RISs or develop algorithms to exploit the channels' mathematical properties have been made, where the required pilot overhead is reduced to be proportional to the number of RIS elements. In this paper, we propose a dimension-independent channel state information (CSI) acquisition approach in which the required pilot overhead is independent of the number of RIS elements. Specifically, in contrast to traditional signal transmission methods, where signals from the base station (BS) and the users are transmitted in different time slots, we propose a novel method in which signals are transmitted from the BS and the user simultaneously during CSI acquisition. Under this method, an electromagnetic interference random field (IRF) will be induced on the RIS, and we employ a sensing RIS to capture its features. Moreover, we develop three algorithms for parameter estimation in this system, and also derive the Cramer-Rao lower bound (CRLB) and an asymptotic expression for it. Simulation results verify that our proposed signal transmission method and the corresponding algorithms can achieve dimension-independent CSI acquisition for beamforming.
Phase Shift Design in RIS Empowered Wireless Networks: From Optimization to AI-Based Methods
Apr 28, 2022
Reconfigurable intelligent surfaces (RISs) have a revolutionary capability to customize the radio propagation environment for wireless networks. To fully exploit the advantages of RISs in wireless systems, the phases of the reflecting elements must be jointly designed with conventional communication resources, such as beamformers, transmit power, and computation time. However, due to the unique constraints on the phase shift, and massive numbers of reflecting units and users in large-scale networks, the resulting optimization problems are challenging to solve. This paper provides a review of current optimization methods and artificial intelligence-based methods for handling the constraints imposed by RIS and compares them in terms of solution quality and computational complexity. Future challenges in phase shift optimization involving RISs are also described and potential solutions are discussed.
RIS-Assisted Visible Light Communication Systems: A Tutorial
Apr 14, 2022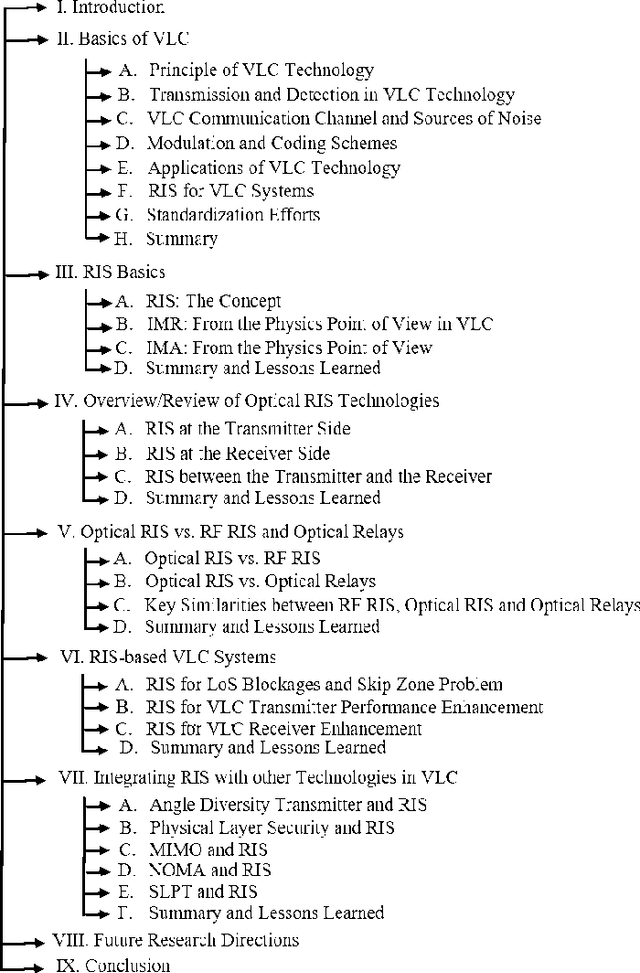
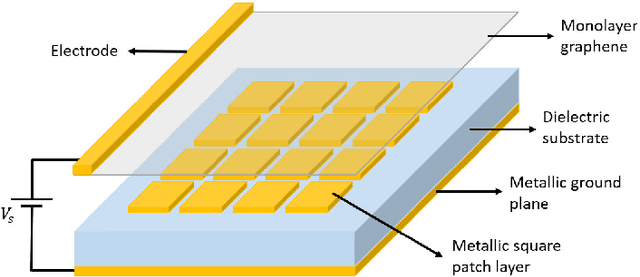
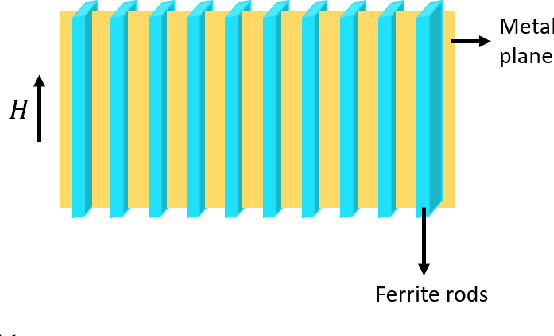

Recent development of the fifth-generation (5G) of cellular networks has led to their deployment worldwide. As part of the implementation, one of the challenges that must be addressed is the skip-zone problem, which occurs when objects obstruct the transmission of signals. A signal obstruction can significantly reduce the signal-to-noise ratio in radio frequency (RF) and indoor visible light communications (VLC) systems, whereas the obstruction can completely disrupt data transmission in free-space optical (FSO) systems. Therefore, the skip-zone dilemma must be resolved to ensure the efficient operation of 5G and beyond networks. In recent years, reconfigurable intelligent surfaces (RISs) that are more efficient than relays have become widely accepted as a method of mitigating skip-zones and providing reconfigurable radio environments. However, there have been limited studies on RISs for optical wireless communication (OWC) systems. This paper aims to provide a comprehensive tutorial on indoor VLC systems utilizing RISs technology. The article discusses the basics of VLC and RISs and reintroduces RISs for OWC systems, focusing on RIS-assisted indoor VLC systems. We also provide a comprehensive overview of optical RISs and examine the differences between optical RISs, RF-RISs, and optical relays. Furthermore, we discuss in detail how RISs can be used to overcome line-of-sight blockages and device orientation issue in VLC systems while revealing key challenges such as RIS element orientation design, RIS elements to access point/user assignment design, and RIS array positioning design problems that need to be studied. Moreover, we discuss and propose several research problems on integrating optical RISs with other emerging technologies and highlight other important research directions for RIS-assisted VLC systems.
Flexible LED Index Modulation for MIMO Optical Wireless Communications
Apr 14, 2022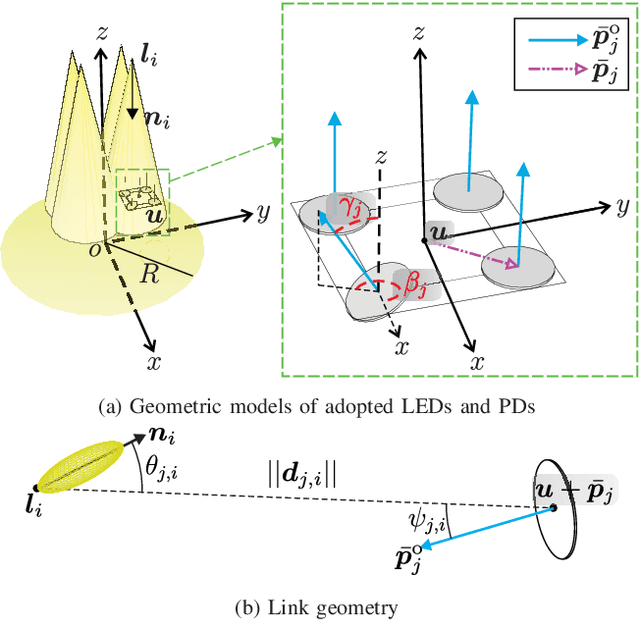
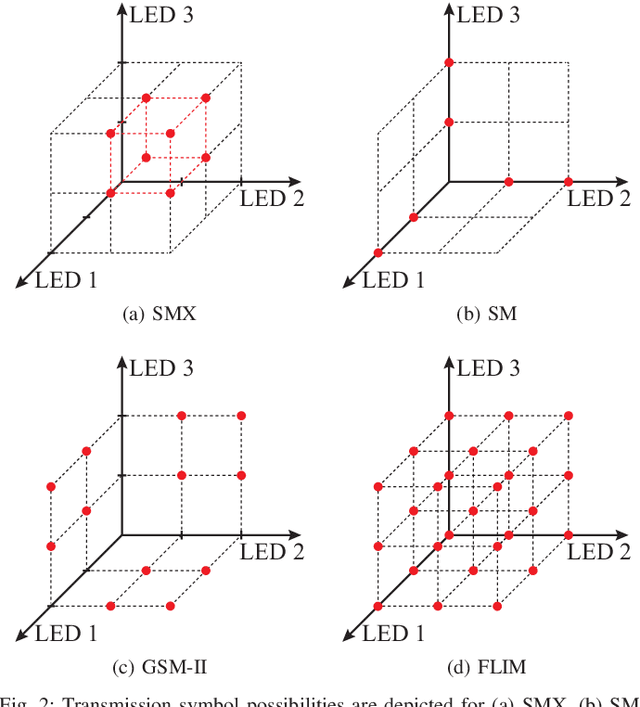
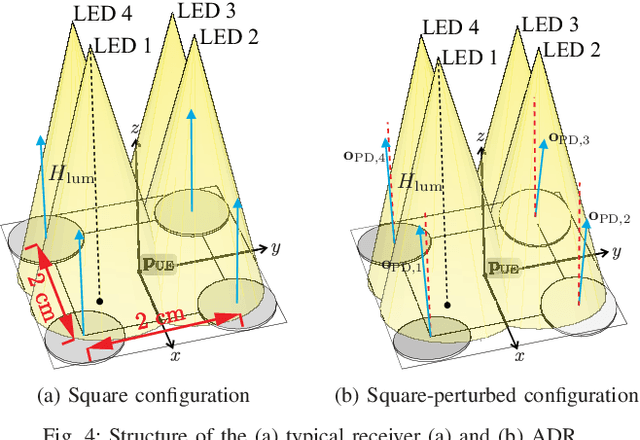
The limited bandwidth of optical wireless communication (OWC) front-end devices motivates the use of multiple-input-multiple-output (MIMO) techniques to enhance data rates. It is known that very high multiplexing gains could be achieved by spatial multiplexing (SMX) in exchange for exhaustive detection complexity. Alternatively, in spatial modulation (SM), a single light emitting diode (LED) is activated per time instance where information is carried by both the signal and the LED index. Since only an LED is active, both transmitter (TX) and receiver (RX) complexity reduces significantly while retaining the information transmission in the spatial domain. However, significant spectral efficiency losses occur in SM compared to SMX. In this paper, we propose a technique which adopts the advantages of both systems. Accordingly, the proposed flexible LED index modulation (FLIM) technique harnesses the inactive state of the LEDs as a transmit symbol. Therefore, the number of active LEDs changes in each transmission, unlike conventional techniques. Moreover, the system complexity is reduced by employing a linear minimum mean squared error (MMSE) equalizer and an angle perturbed receiver at the RX. Numerical results show that FLIM outperforms the reference systems by at least 6 dB in the low and medium/high spectral efficiency regions.
Semi-Data-Aided Channel Estimation for MIMO Systems via Reinforcement Learning
Apr 03, 2022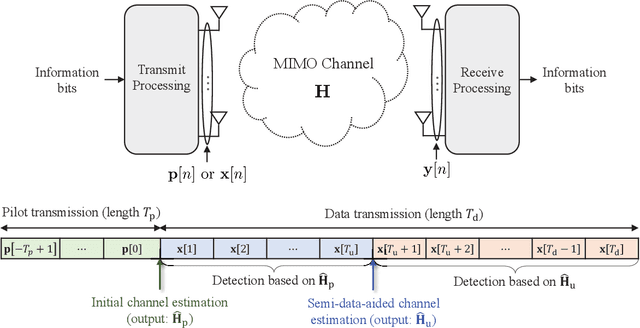
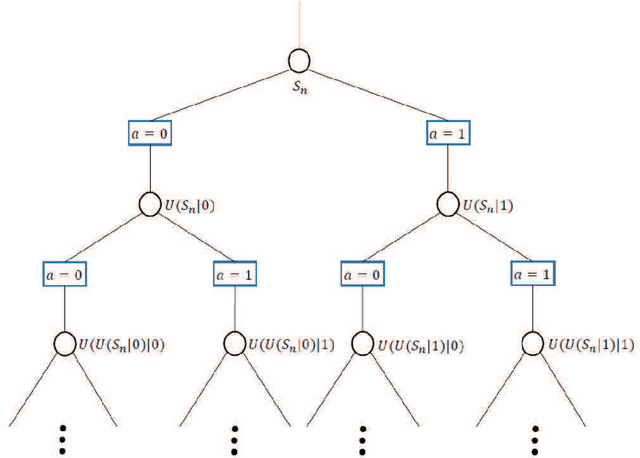
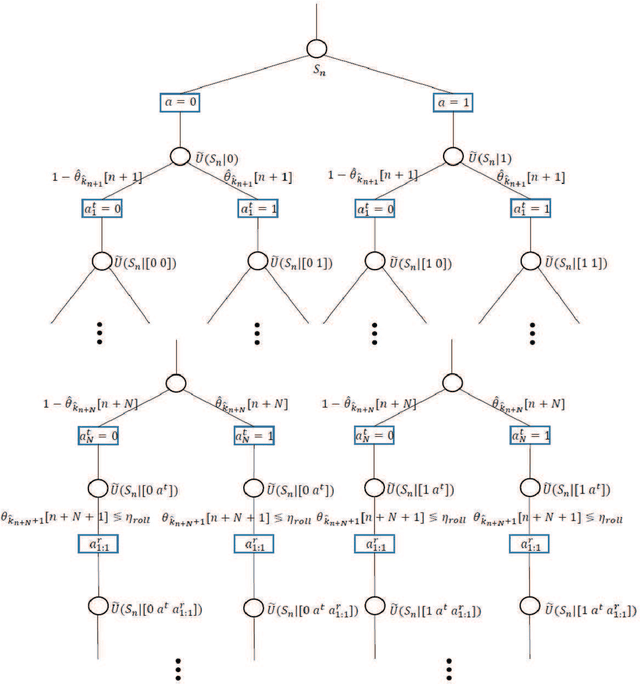
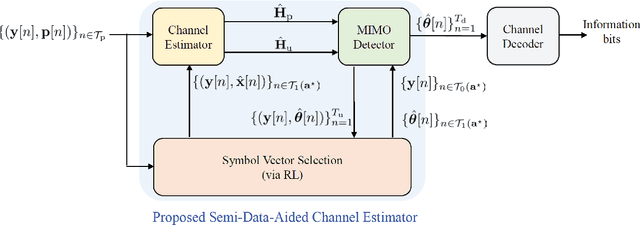
Data-aided channel estimation is a promising solution to improve channel estimation accuracy by exploiting data symbols as pilot signals for updating an initial channel estimate. In this paper, we propose a semi-data-aided channel estimator for multiple-input multiple-output communication systems. Our strategy is to leverage reinforcement learning (RL) for selecting reliable detected symbols among the symbols in the first part of transmitted data block. This strategy facilitates an update of the channel estimate before the end of data block transmission and therefore achieves a significant reduction in communication latency compared to conventional data-aided channel estimation approaches. Towards this end, we first define a Markov decision process (MDP) which sequentially decides whether to use each detected symbol as an additional pilot signal. We then develop an RL algorithm to efficiently find the best policy of the MDP based on a Monte Carlo tree search approach. In this algorithm, we exploit the a-posteriori probability for approximating both the optimal future actions and the corresponding state transitions of the MDP and derive a closed-form expression for the best policy. Simulation results demonstrate that the proposed channel estimator effectively mitigates both channel estimation error and detection performance loss caused by insufficient pilot signals.
Contextual Model Aggregation for Fast and Robust Federated Learning in Edge Computing
Mar 23, 2022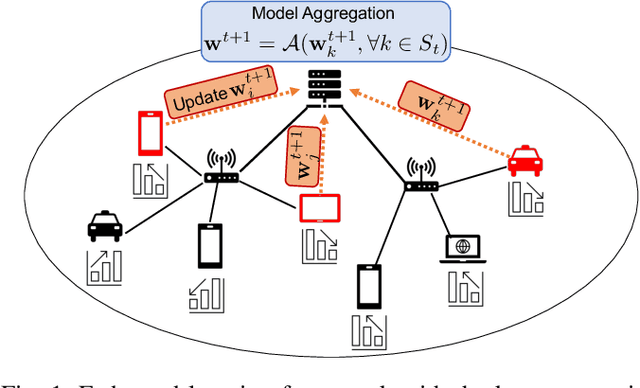
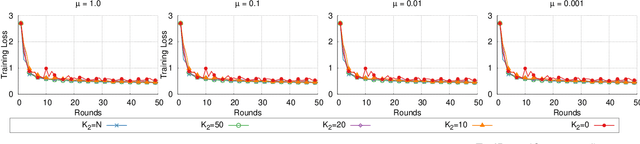
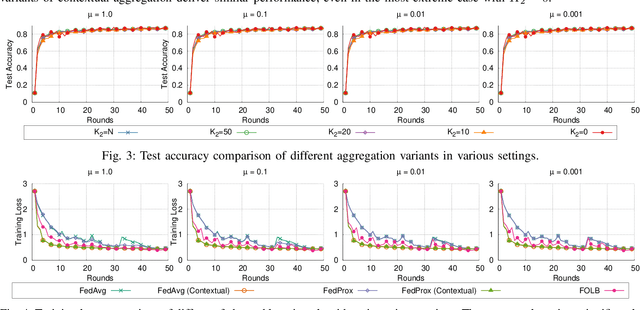
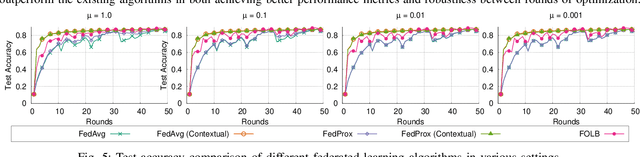
Federated learning is a prime candidate for distributed machine learning at the network edge due to the low communication complexity and privacy protection among other attractive properties. However, existing algorithms face issues with slow convergence and/or robustness of performance due to the considerable heterogeneity of data distribution, computation and communication capability at the edge. In this work, we tackle both of these issues by focusing on the key component of model aggregation in federated learning systems and studying optimal algorithms to perform this task. Particularly, we propose a contextual aggregation scheme that achieves the optimal context-dependent bound on loss reduction in each round of optimization. The aforementioned context-dependent bound is derived from the particular participating devices in that round and an assumption on smoothness of the overall loss function. We show that this aggregation leads to a definite reduction of loss function at every round. Furthermore, we can integrate our aggregation with many existing algorithms to obtain the contextual versions. Our experimental results demonstrate significant improvements in convergence speed and robustness of the contextual versions compared to the original algorithms. We also consider different variants of the contextual aggregation and show robust performance even in the most extreme settings.
Proximal Policy Optimization-based Transmit Beamforming and Phase-shift Design in an IRS-aided ISAC System for the THz Band
Mar 21, 2022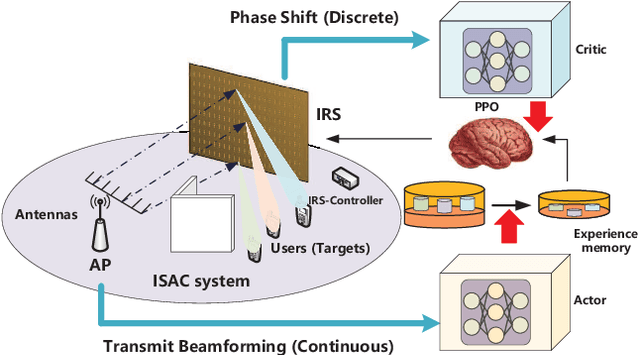
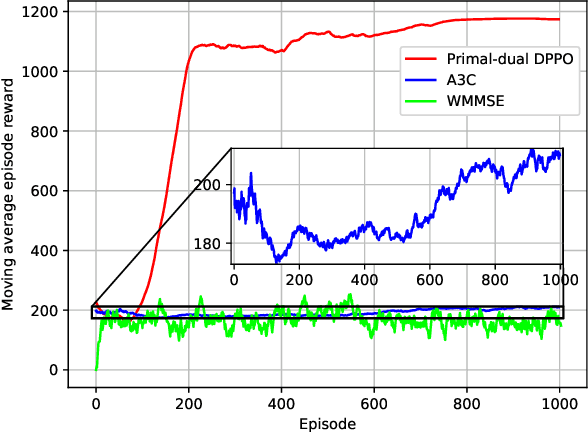
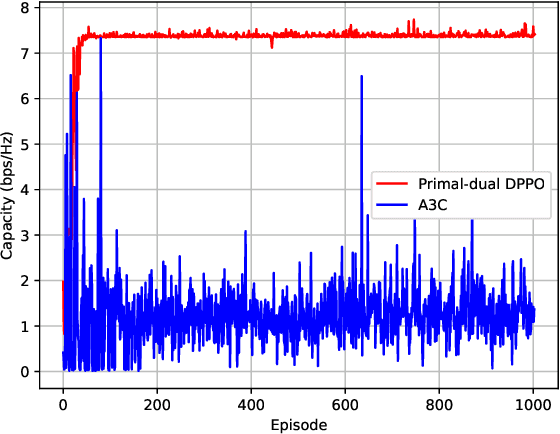
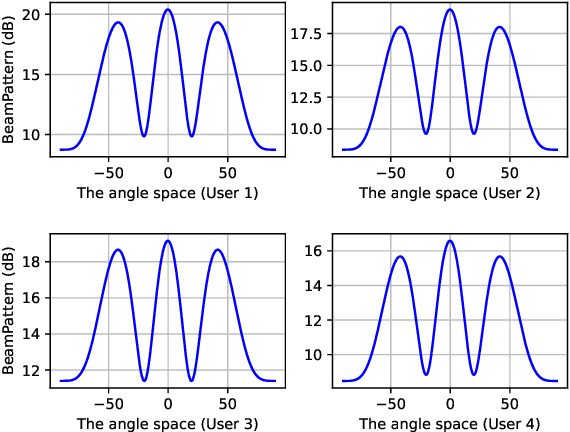
In this paper, an IRS-aided integrated sensing and communications (ISAC) system operating in the terahertz (THz) band is proposed to maximize the system capacity. Transmit beamforming and phase-shift design are transformed into a universal optimization problem with ergodic constraints. Then the joint optimization of transmit beamforming and phase-shift design is achieved by gradient-based, primal-dual proximal policy optimization (PPO) in the multi-user multiple-input single-output (MISO) scenario. Specifically, the actor part generates continuous transmit beamforming and the critic part takes charge of discrete phase shift design. Based on the MISO scenario, we investigate a distributed PPO (DPPO) framework with the concept of multi-threading learning in the multi-user multiple-input multiple-output (MIMO) scenario. Simulation results demonstrate the effectiveness of the primal-dual PPO algorithm and its multi-threading version in terms of transmit beamforming and phase-shift design.
A Dimensionality Reduction Method for Finding Least Favorable Priors with a Focus on Bregman Divergence
Feb 23, 2022



A common way of characterizing minimax estimators in point estimation is by moving the problem into the Bayesian estimation domain and finding a least favorable prior distribution. The Bayesian estimator induced by a least favorable prior, under mild conditions, is then known to be minimax. However, finding least favorable distributions can be challenging due to inherent optimization over the space of probability distributions, which is infinite-dimensional. This paper develops a dimensionality reduction method that allows us to move the optimization to a finite-dimensional setting with an explicit bound on the dimension. The benefit of this dimensionality reduction is that it permits the use of popular algorithms such as projected gradient ascent to find least favorable priors. Throughout the paper, in order to make progress on the problem, we restrict ourselves to Bayesian risks induced by a relatively large class of loss functions, namely Bregman divergences.
Federated Stochastic Gradient Descent Begets Self-Induced Momentum
Feb 17, 2022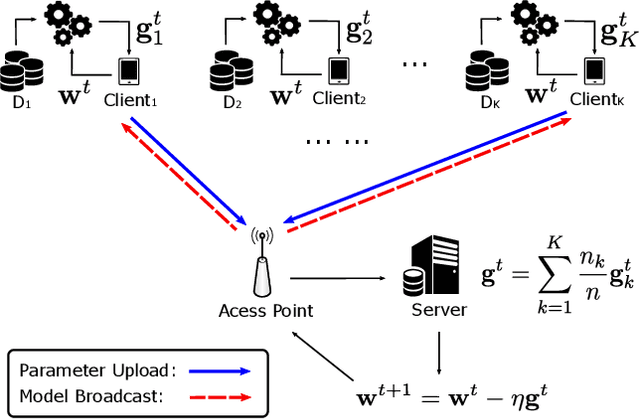
Federated learning (FL) is an emerging machine learning method that can be applied in mobile edge systems, in which a server and a host of clients collaboratively train a statistical model utilizing the data and computation resources of the clients without directly exposing their privacy-sensitive data. We show that running stochastic gradient descent (SGD) in such a setting can be viewed as adding a momentum-like term to the global aggregation process. Based on this finding, we further analyze the convergence rate of a federated learning system by accounting for the effects of parameter staleness and communication resources. These results advance the understanding of the Federated SGD algorithm, and also forges a link between staleness analysis and federated computing systems, which can be useful for systems designers.