 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Differential Privacy for Federated Learning in Wireless Systems with Multiple Base Stations
Aug 25, 2022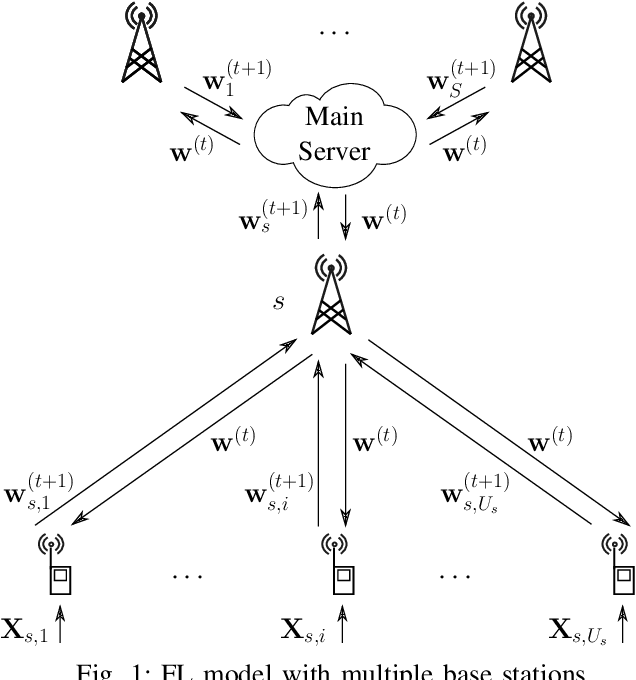
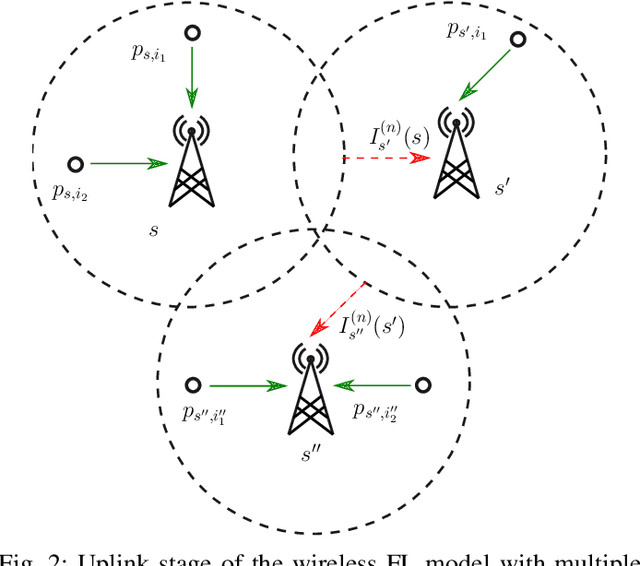
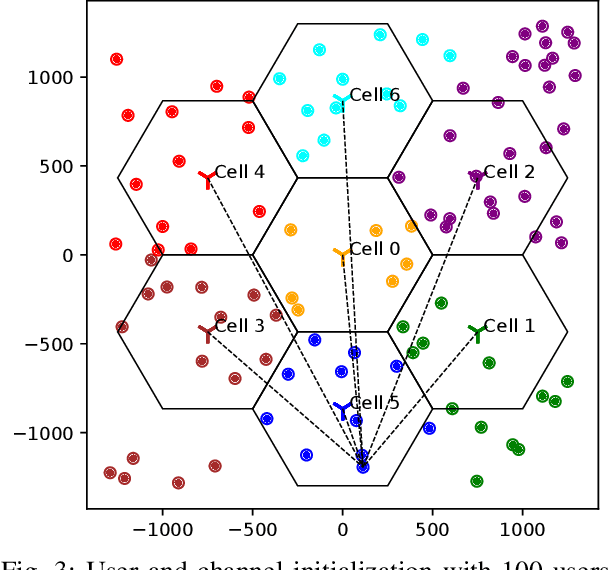
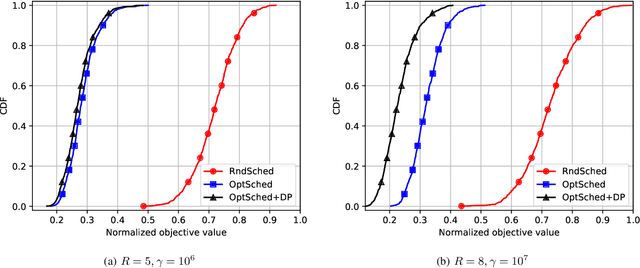
In this work, we consider a federated learning model in a wireless system with multiple base stations and inter-cell interference. We apply a differential private scheme to transmit information from users to their corresponding base station during the learning phase. We show the convergence behavior of the learning process by deriving an upper bound on its optimality gap. Furthermore, we define an optimization problem to reduce this upper bound and the total privacy leakage. To find the locally optimal solutions of this problem, we first propose an algorithm that schedules the resource blocks and users. We then extend this scheme to reduce the total privacy leakage by optimizing the differential privacy artificial noise. We apply the solutions of these two procedures as parameters of a federated learning system. In this setting, we assume that each user is equipped with a classifier. Moreover, the communication cells are assumed to have mostly fewer resource blocks than numbers of users. The simulation results show that our proposed scheduler improves the average accuracy of the predictions compared with a random scheduler. Furthermore, its extended version with noise optimizer significantly reduces the amount of privacy leakage.
Semi-Data-Aided Channel Estimation for MIMO Systems via Reinforcement Learning
Apr 03, 2022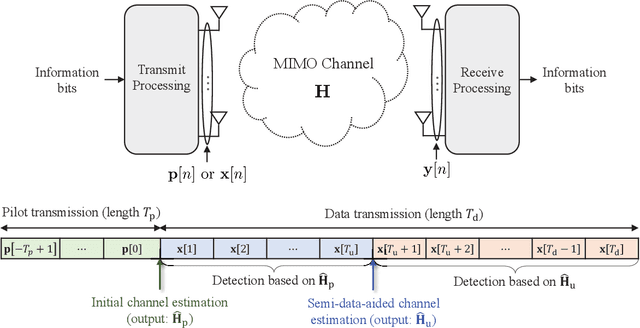
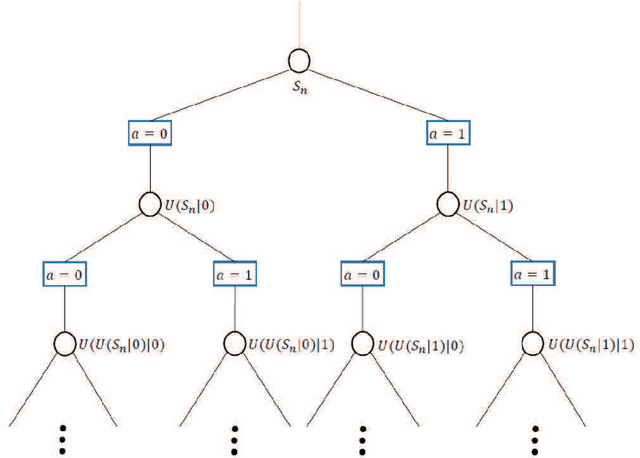
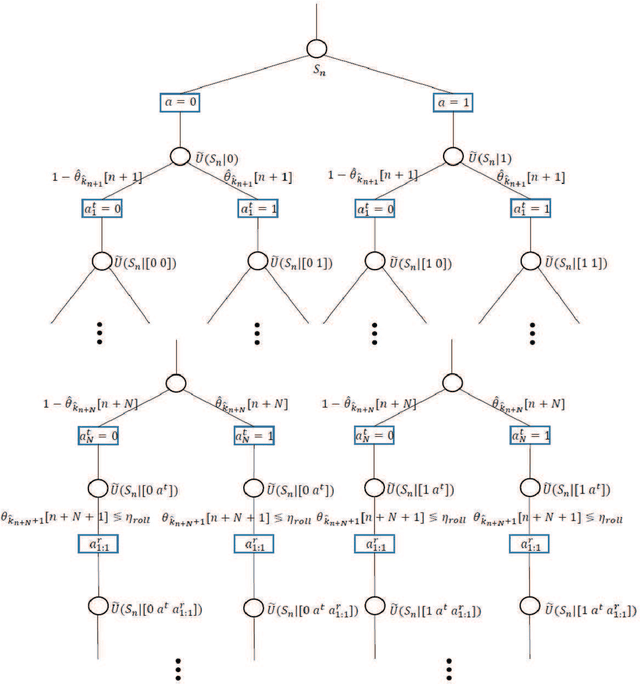
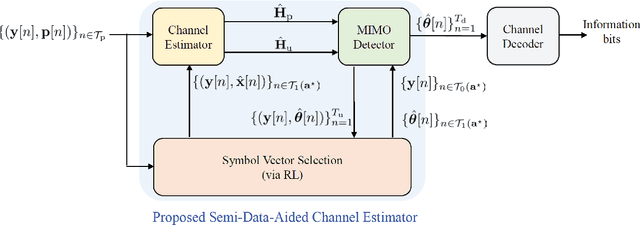
Data-aided channel estimation is a promising solution to improve channel estimation accuracy by exploiting data symbols as pilot signals for updating an initial channel estimate. In this paper, we propose a semi-data-aided channel estimator for multiple-input multiple-output communication systems. Our strategy is to leverage reinforcement learning (RL) for selecting reliable detected symbols among the symbols in the first part of transmitted data block. This strategy facilitates an update of the channel estimate before the end of data block transmission and therefore achieves a significant reduction in communication latency compared to conventional data-aided channel estimation approaches. Towards this end, we first define a Markov decision process (MDP) which sequentially decides whether to use each detected symbol as an additional pilot signal. We then develop an RL algorithm to efficiently find the best policy of the MDP based on a Monte Carlo tree search approach. In this algorithm, we exploit the a-posteriori probability for approximating both the optimal future actions and the corresponding state transitions of the MDP and derive a closed-form expression for the best policy. Simulation results demonstrate that the proposed channel estimator effectively mitigates both channel estimation error and detection performance loss caused by insufficient pilot signals.