 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022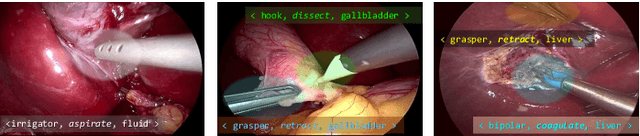

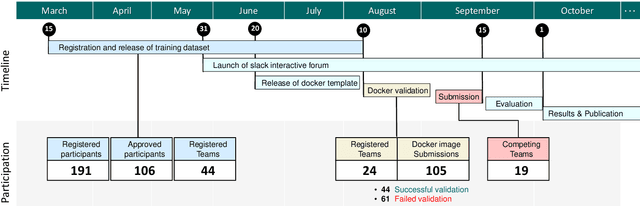
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Frequency-Supervised MR-to-CT Image Synthesis
Jul 19, 2021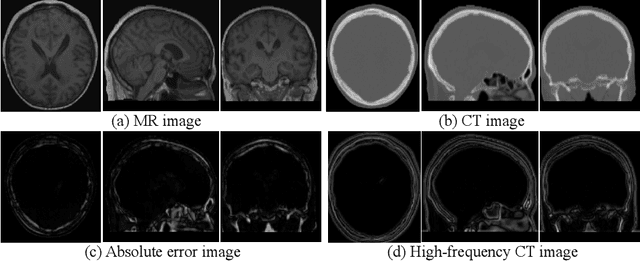

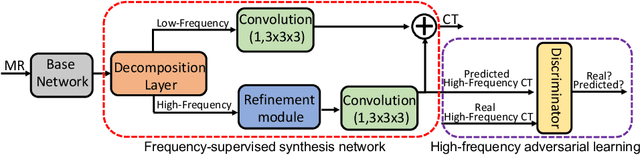

This paper strives to generate a synthetic computed tomography (CT) image from a magnetic resonance (MR) image. The synthetic CT image is valuable for radiotherapy planning when only an MR image is available. Recent approaches have made large strides in solving this challenging synthesis problem with convolutional neural networks that learn a mapping from MR inputs to CT outputs. In this paper, we find that all existing approaches share a common limitation: reconstruction breaks down in and around the high-frequency parts of CT images. To address this common limitation, we introduce frequency-supervised deep networks to explicitly enhance high-frequency MR-to-CT image reconstruction. We propose a frequency decomposition layer that learns to decompose predicted CT outputs into low- and high-frequency components, and we introduce a refinement module to improve high-frequency reconstruction through high-frequency adversarial learning. Experimental results on a new dataset with 45 pairs of 3D MR-CT brain images show the effectiveness and potential of the proposed approach. Code is available at \url{https://github.com/shizenglin/Frequency-Supervised-MR-to-CT-Image-Synthesis}.
ICMSC: Intra- and Cross-modality Semantic Consistency for Unsupervised Domain Adaptation on Hip Joint Bone Segmentation
Dec 23, 2020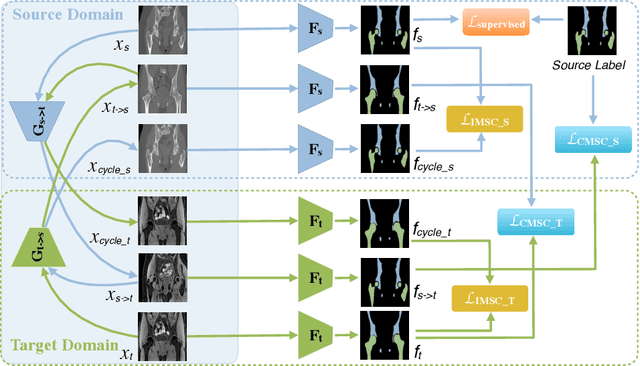
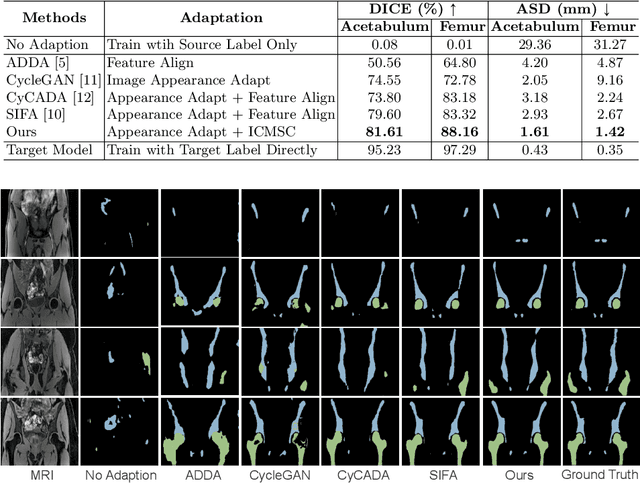
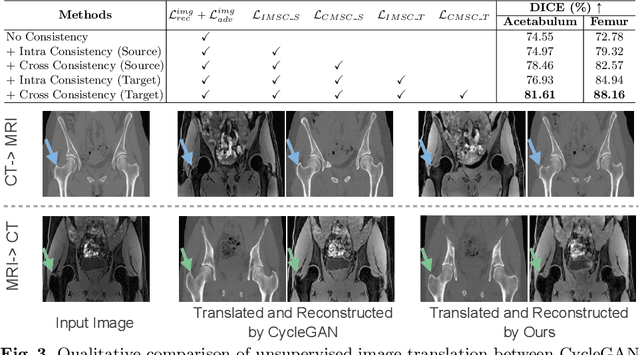
Unsupervised domain adaptation (UDA) for cross-modality medical image segmentation has shown great progress by domain-invariant feature learning or image appearance translation. Adapted feature learning usually cannot detect domain shifts at the pixel level and is not able to achieve good results in dense semantic segmentation tasks. Image appearance translation, e.g. CycleGAN, translates images into different styles with good appearance, despite its population, its semantic consistency is hardly to maintain and results in poor cross-modality segmentation. In this paper, we propose intra- and cross-modality semantic consistency (ICMSC) for UDA and our key insight is that the segmentation of synthesised images in different styles should be consistent. Specifically, our model consists of an image translation module and a domain-specific segmentation module. The image translation module is a standard CycleGAN, while the segmentation module contains two domain-specific segmentation networks. The intra-modality semantic consistency (IMSC) forces the reconstructed image after a cycle to be segmented in the same way as the original input image, while the cross-modality semantic consistency (CMSC) encourages the synthesized images after translation to be segmented exactly the same as before translation. Comprehensive experimental results on cross-modality hip joint bone segmentation show the effectiveness of our proposed method, which achieves an average DICE of 81.61% on the acetabulum and 88.16% on the proximal femur, outperforming other state-of-the-art methods. It is worth to note that without UDA, a model trained on CT for hip joint bone segmentation is non-transferable to MRI and has almost zero-DICE segmentation.
Robust Regression via Deep Negative Correlation Learning
Aug 24, 2019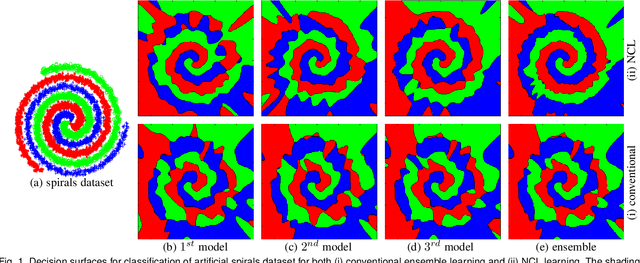
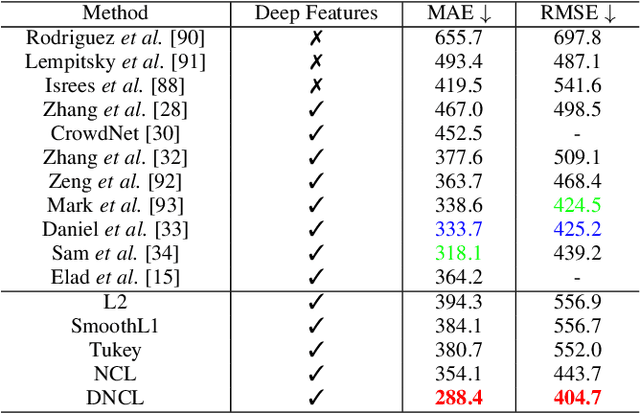
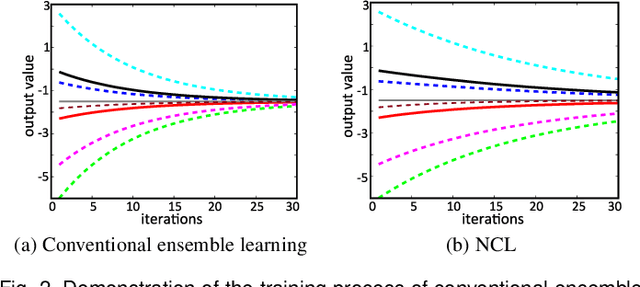
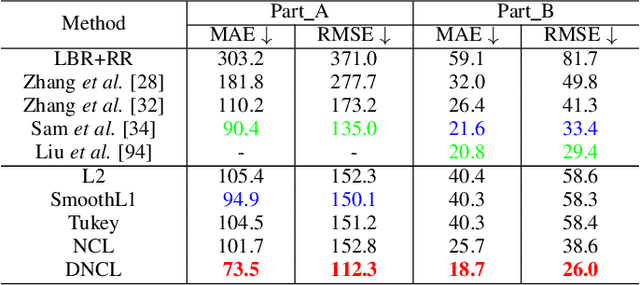
Nonlinear regression has been extensively employed in many computer vision problems (e.g., crowd counting, age estimation, affective computing). Under the umbrella of deep learning, two common solutions exist i) transforming nonlinear regression to a robust loss function which is jointly optimizable with the deep convolutional network, and ii) utilizing ensemble of deep networks. Although some improved performance is achieved, the former may be lacking due to the intrinsic limitation of choosing a single hypothesis and the latter usually suffers from much larger computational complexity. To cope with those issues, we propose to regress via an efficient "divide and conquer" manner. The core of our approach is the generalization of negative correlation learning that has been shown, both theoretically and empirically, to work well for non-deep regression problems. Without extra parameters, the proposed method controls the bias-variance-covariance trade-off systematically and usually yields a deep regression ensemble where each base model is both "accurate" and "diversified". Moreover, we show that each sub-problem in the proposed method has less Rademacher Complexity and thus is easier to optimize. Extensive experiments on several diverse and challenging tasks including crowd counting, personality analysis, age estimation, and image super-resolution demonstrate the superiority over challenging baselines as well as the versatility of the proposed method.
Standardized Assessment of Automatic Segmentation of White Matter Hyperintensities and Results of the WMH Segmentation Challenge
Apr 01, 2019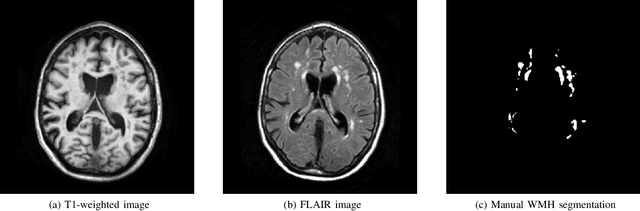
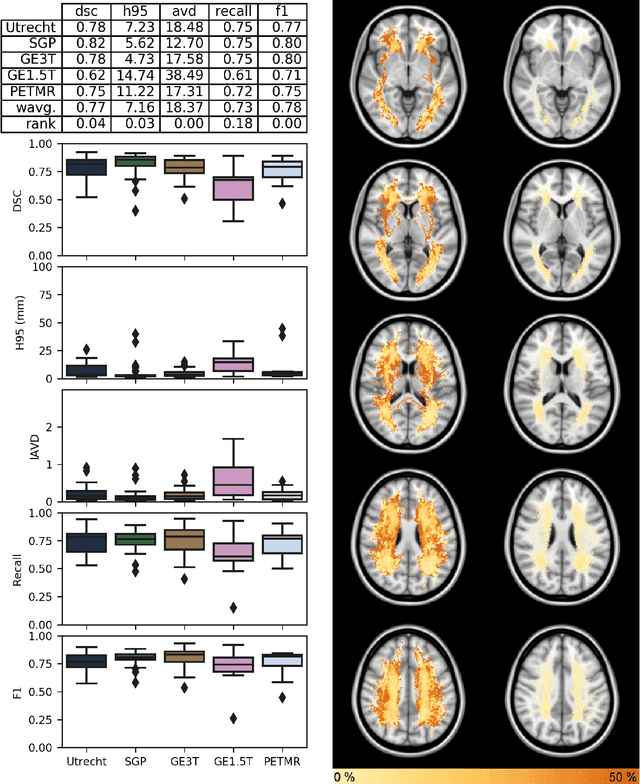
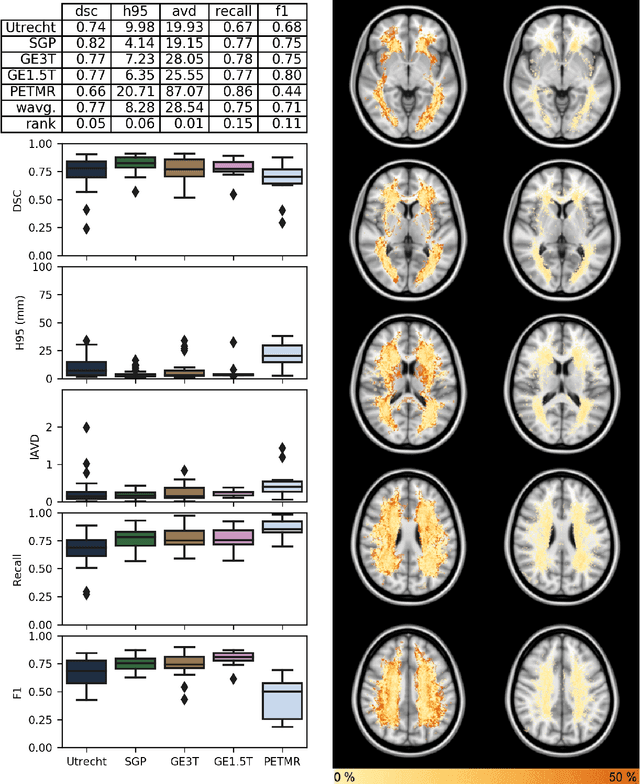
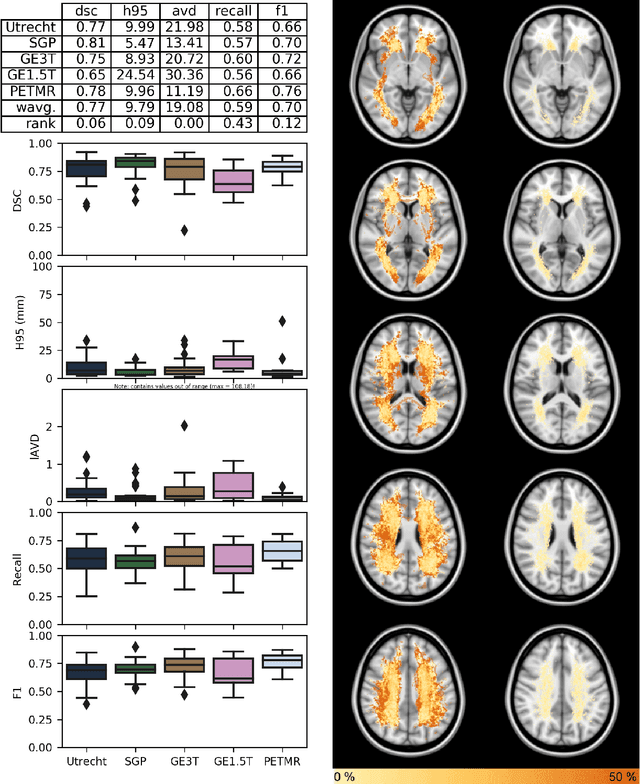
Quantification of cerebral white matter hyperintensities (WMH) of presumed vascular origin is of key importance in many neurological research studies. Currently, measurements are often still obtained from manual segmentations on brain MR images, which is a laborious procedure. Automatic WMH segmentation methods exist, but a standardized comparison of the performance of such methods is lacking. We organized a scientific challenge, in which developers could evaluate their method on a standardized multi-center/-scanner image dataset, giving an objective comparison: the WMH Segmentation Challenge (https://wmh.isi.uu.nl/). Sixty T1+FLAIR images from three MR scanners were released with manual WMH segmentations for training. A test set of 110 images from five MR scanners was used for evaluation. Segmentation methods had to be containerized and submitted to the challenge organizers. Five evaluation metrics were used to rank the methods: (1) Dice similarity coefficient, (2) modified Hausdorff distance (95th percentile), (3) absolute log-transformed volume difference, (4) sensitivity for detecting individual lesions, and (5) F1-score for individual lesions. Additionally, methods were ranked on their inter-scanner robustness. Twenty participants submitted their method for evaluation. This paper provides a detailed analysis of the results. In brief, there is a cluster of four methods that rank significantly better than the other methods, with one clear winner. The inter-scanner robustness ranking shows that not all methods generalize to unseen scanners. The challenge remains open for future submissions and provides a public platform for method evaluation.
Evaluation of Algorithms for Multi-Modality Whole Heart Segmentation: An Open-Access Grand Challenge
Feb 21, 2019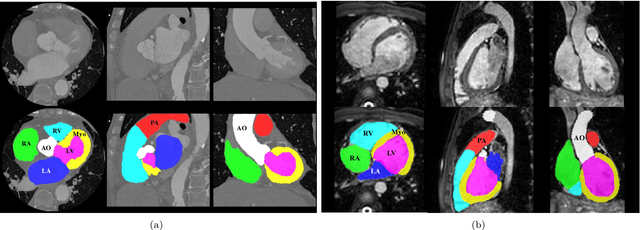

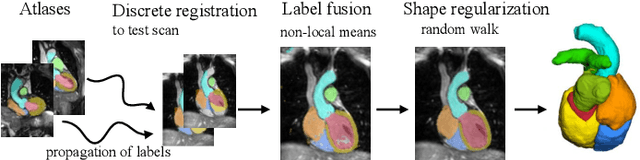
Knowledge of whole heart anatomy is a prerequisite for many clinical applications. Whole heart segmentation (WHS), which delineates substructures of the heart, can be very valuable for modeling and analysis of the anatomy and functions of the heart. However, automating this segmentation can be arduous due to the large variation of the heart shape, and different image qualities of the clinical data. To achieve this goal, a set of training data is generally needed for constructing priors or for training. In addition, it is difficult to perform comparisons between different methods, largely due to differences in the datasets and evaluation metrics used. This manuscript presents the methodologies and evaluation results for the WHS algorithms selected from the submissions to the Multi-Modality Whole Heart Segmentation (MM-WHS) challenge, in conjunction with MICCAI 2017. The challenge provides 120 three-dimensional cardiac images covering the whole heart, including 60 CT and 60 MRI volumes, all acquired in clinical environments with manual delineation. Ten algorithms for CT data and eleven algorithms for MRI data, submitted from twelve groups, have been evaluated. The results show that many of the deep learning (DL) based methods achieved high accuracy, even though the number of training datasets was limited. A number of them also reported poor results in the blinded evaluation, probably due to overfitting in their training. The conventional algorithms, mainly based on multi-atlas segmentation, demonstrated robust and stable performance, even though the accuracy is not as good as the best DL method in CT segmentation. The challenge, including the provision of the annotated training data and the blinded evaluation for submitted algorithms on the test data, continues as an ongoing benchmarking resource via its homepage (\url{www.sdspeople.fudan.edu.cn/zhuangxiahai/0/mmwhs/}).
Holistic Decomposition Convolution for Effective Semantic Segmentation of 3D MR Images
Dec 24, 2018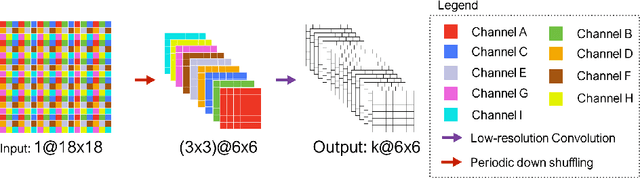
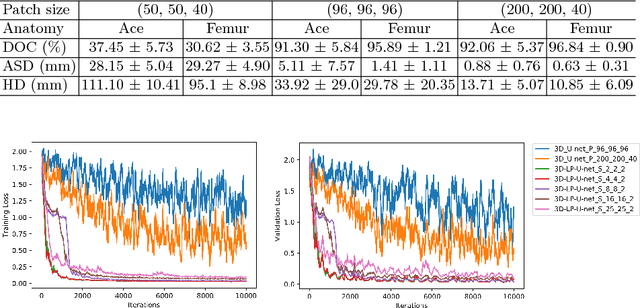


Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance in many different 2D medical image analysis tasks. In clinical practice, however, a large part of the medical imaging data available is in 3D. This has motivated the development of 3D CNNs for volumetric image segmentation in order to benefit from more spatial context. Due to GPU memory restrictions caused by moving to fully 3D, state-of-the-art methods depend on subvolume/patch processing and the size of the input patch is usually small, limiting the incorporation of larger context information for a better performance. In this paper, we propose a novel Holistic Decomposition Convolution (HDC), for an effective and efficient semantic segmentation of volumetric images. HDC consists of a periodic down-shuffling operation followed by a conventional 3D convolution. HDC has the advantage of significantly reducing the size of the data for sub-sequential processing while using all the information available in the input irrespective of the down-shuffling factors. Results obtained from comprehensive experiments conducted on hip T1 MR images and intervertebral disc T2 MR images demonstrate the efficacy of the present approach.
Is the winner really the best? A critical analysis of common research practice in biomedical image analysis competitions
Jun 06, 2018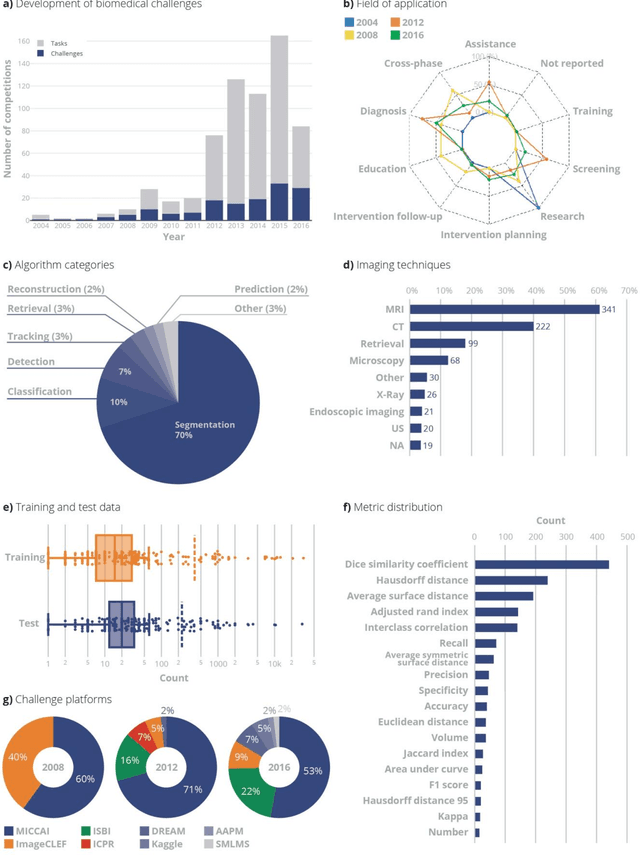
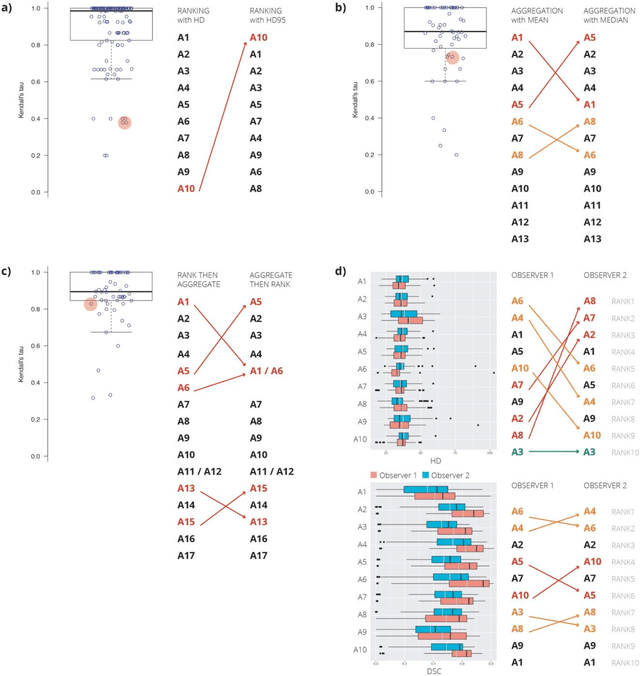
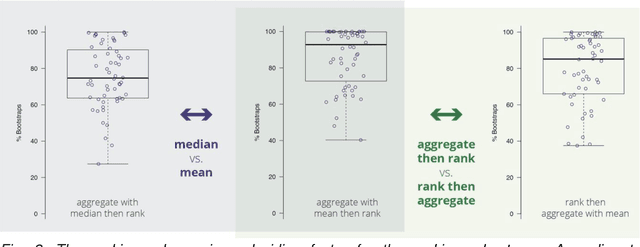
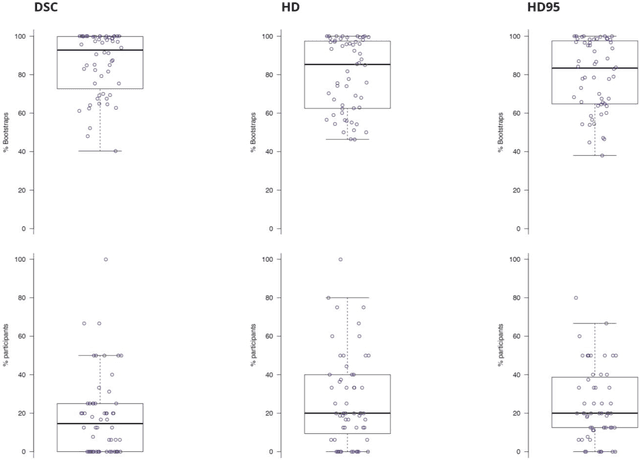
International challenges have become the standard for validation of biomedical image analysis methods. Given their scientific impact, it is surprising that a critical analysis of common practices related to the organization of challenges has not yet been performed. In this paper, we present a comprehensive analysis of biomedical image analysis challenges conducted up to now. We demonstrate the importance of challenges and show that the lack of quality control has critical consequences. First, reproducibility and interpretation of the results is often hampered as only a fraction of relevant information is typically provided. Second, the rank of an algorithm is generally not robust to a number of variables such as the test data used for validation, the ranking scheme applied and the observers that make the reference annotations. To overcome these problems, we recommend best practice guidelines and define open research questions to be addressed in the future.
Fully Automatic Segmentation of Lumbar Vertebrae from CT Images using Cascaded 3D Fully Convolutional Networks
Dec 05, 2017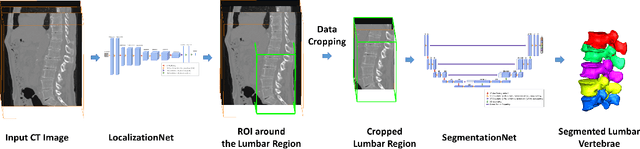
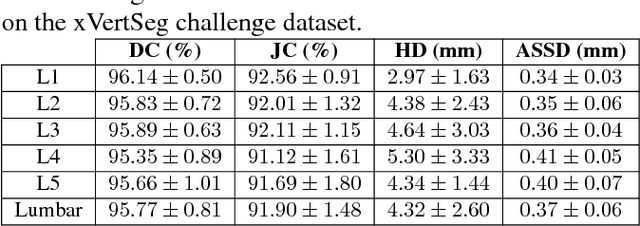
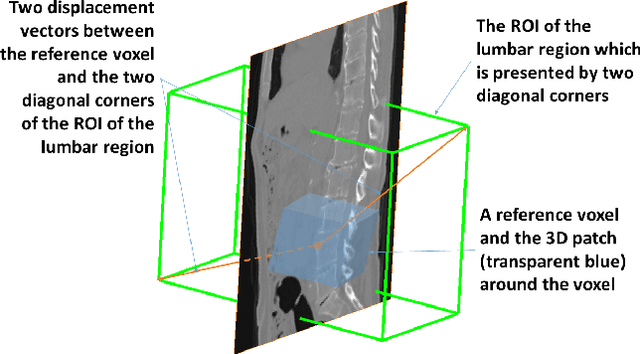
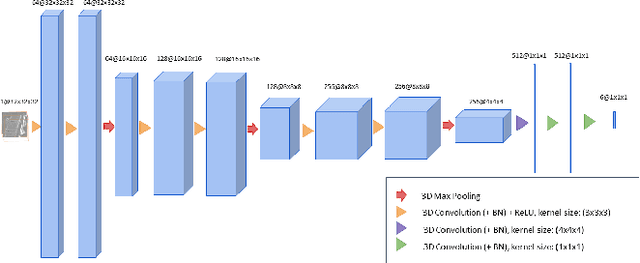
We present a method to address the challenging problem of segmentation of lumbar vertebrae from CT images acquired with varying fields of view. Our method is based on cascaded 3D Fully Convolutional Networks (FCNs) consisting of a localization FCN and a segmentation FCN. More specifically, in the first step we train a regression 3D FCN (we call it "LocalizationNet") to find the bounding box of the lumbar region. After that, a 3D U-net like FCN (we call it "SegmentationNet") is then developed, which after training, can perform a pixel-wise multi-class segmentation to map a cropped lumber region volumetric data to its volume-wise labels. Evaluated on publicly available datasets, our method achieved an average Dice coefficient of 95.77 $\pm$ 0.81% and an average symmetric surface distance of 0.37 $\pm$ 0.06 mm.
Multi-stream 3D FCN with Multi-scale Deep Supervision for Multi-modality Isointense Infant Brain MR Image Segmentation
Nov 28, 2017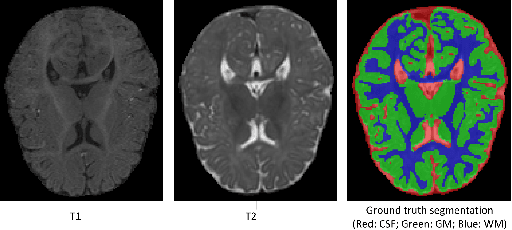
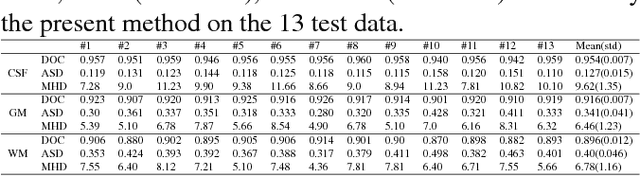
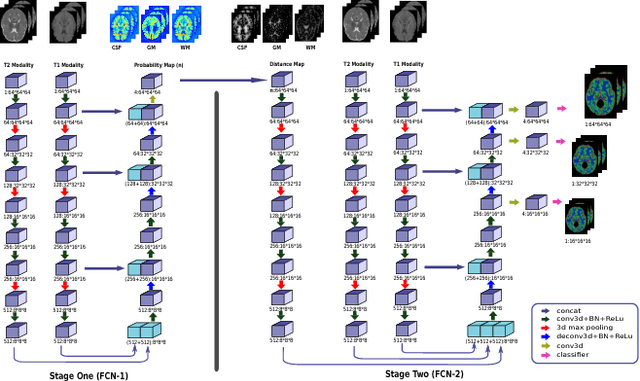
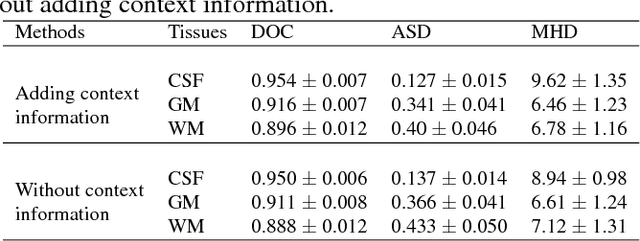
We present a method to address the challenging problem of segmentation of multi-modality isointense infant brain MR images into white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF). Our method is based on context-guided, multi-stream fully convolutional networks (FCN), which after training, can directly map a whole volumetric data to its volume-wise labels. In order to alleviate the poten-tial gradient vanishing problem during training, we designed multi-scale deep supervision. Furthermore, context infor-mation was used to further improve the performance of our method. Validated on the test data of the MICCAI 2017 Grand Challenge on 6-month infant brain MRI segmentation (iSeg-2017), our method achieved an average Dice Overlap Coefficient of 95.4%, 91.6% and 89.6% for CSF, GM and WM, respectively.