 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraverseNet: Unifying Space and Time in Message Passing
Aug 25, 2021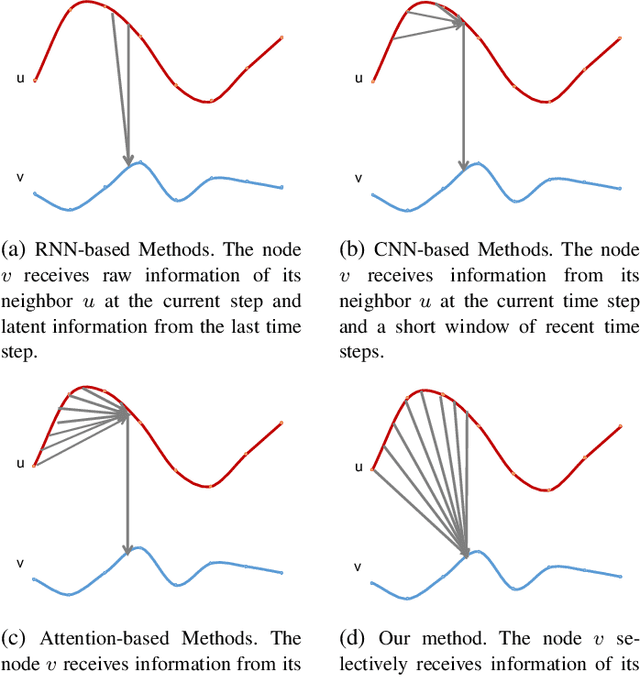
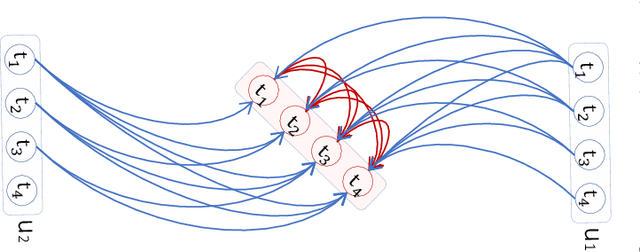
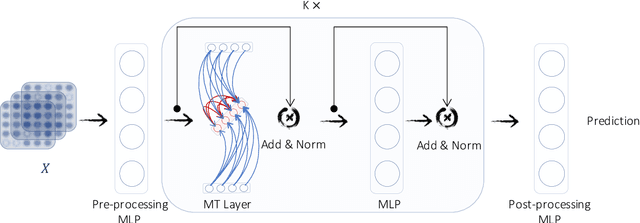

This paper aims to unify spatial dependency and temporal dependency in a non-Euclidean space while capturing the inner spatial-temporal dependencies for spatial-temporal graph data. For spatial-temporal attribute entities with topological structure, the space-time is consecutive and unified while each node's current status is influenced by its neighbors' past states over variant periods of each neighbor. Most spatial-temporal neural networks study spatial dependency and temporal correlation separately in processing, gravely impaired the space-time continuum, and ignore the fact that the neighbors' temporal dependency period for a node can be delayed and dynamic. To model this actual condition, we propose TraverseNet, a novel spatial-temporal graph neural network, viewing space and time as an inseparable whole, to mine spatial-temporal graphs while exploiting the evolving spatial-temporal dependencies for each node via message traverse mechanisms. Experiments with ablation and parameter studies have validated the effectiveness of the proposed TraverseNets, and the detailed implementation can be found from https://github.com/nnzhan/TraverseNet.
Federated Learning for Privacy-Preserving Open Innovation Future on Digital Health
Aug 24, 2021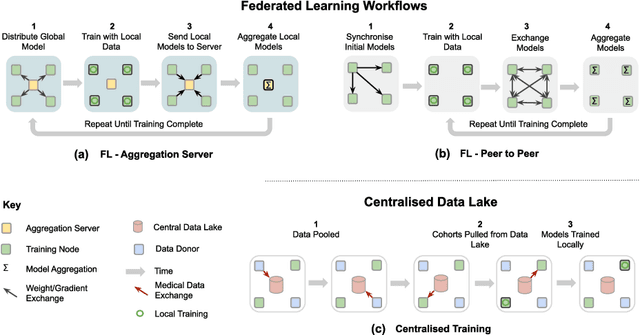


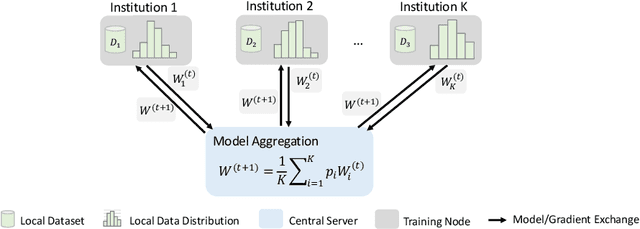
Privacy protection is an ethical issue with broad concern in Artificial Intelligence (AI). Federated learning is a new machine learning paradigm to learn a shared model across users or organisations without direct access to the data. It has great potential to be the next-general AI model training framework that offers privacy protection and therefore has broad implications for the future of digital health and healthcare informatics. Implementing an open innovation framework in the healthcare industry, namely open health, is to enhance innovation and creative capability of health-related organisations by building a next-generation collaborative framework with partner organisations and the research community. In particular, this game-changing collaborative framework offers knowledge sharing from diverse data with a privacy-preserving. This chapter will discuss how federated learning can enable the development of an open health ecosystem with the support of AI. Existing challenges and solutions for federated learning will be discussed.
Federated Learning for Open Banking
Aug 24, 2021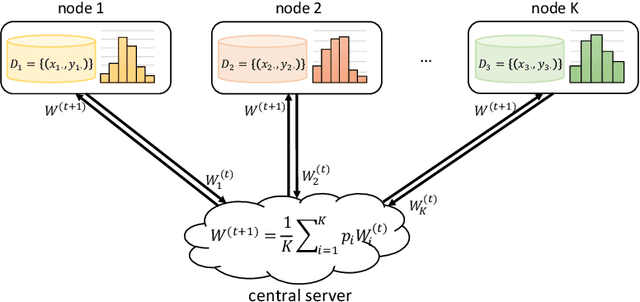
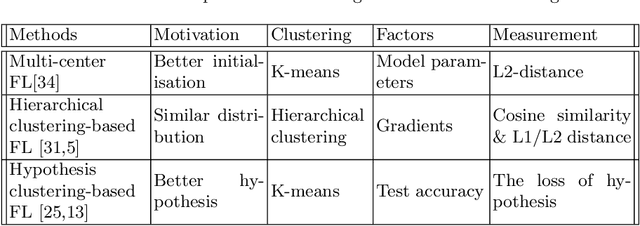
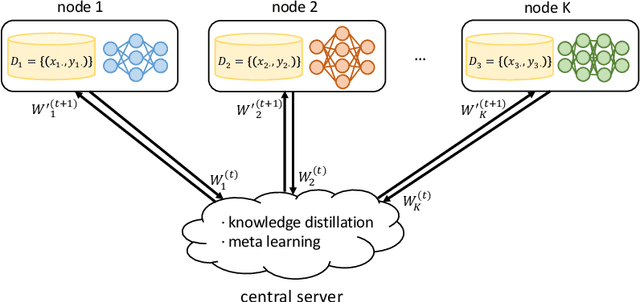
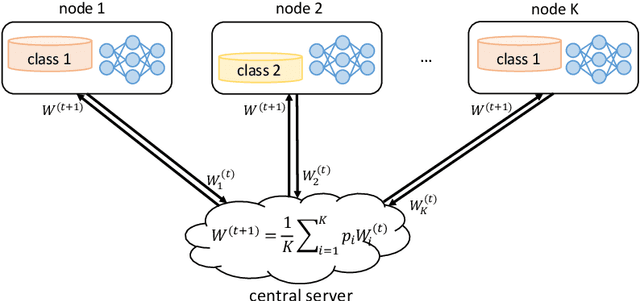
Open banking enables individual customers to own their banking data, which provides fundamental support for the boosting of a new ecosystem of data marketplaces and financial services. In the near future, it is foreseeable to have decentralized data ownership in the finance sector using federated learning. This is a just-in-time technology that can learn intelligent models in a decentralized training manner. The most attractive aspect of federated learning is its ability to decompose model training into a centralized server and distributed nodes without collecting private data. This kind of decomposed learning framework has great potential to protect users' privacy and sensitive data. Therefore, federated learning combines naturally with an open banking data marketplaces. This chapter will discuss the possible challenges for applying federated learning in the context of open banking, and the corresponding solutions have been explored as well.
Multi-Center Federated Learning
Aug 21, 2021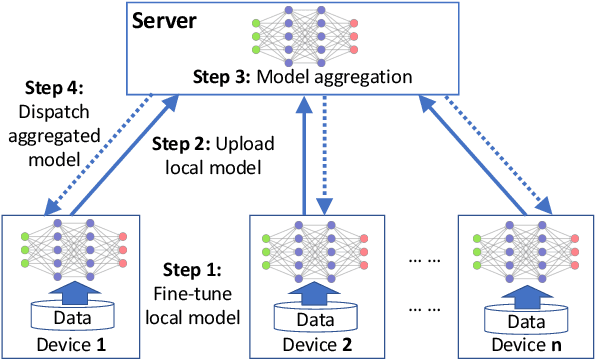

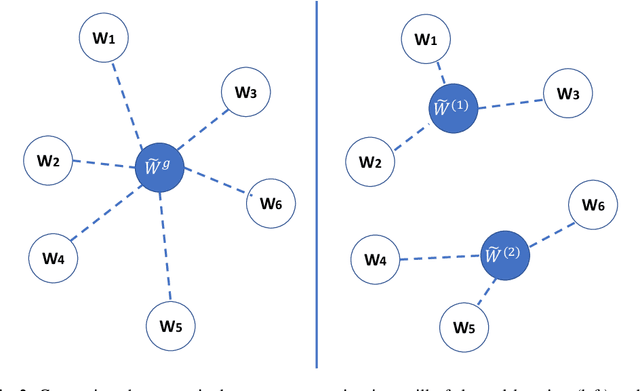
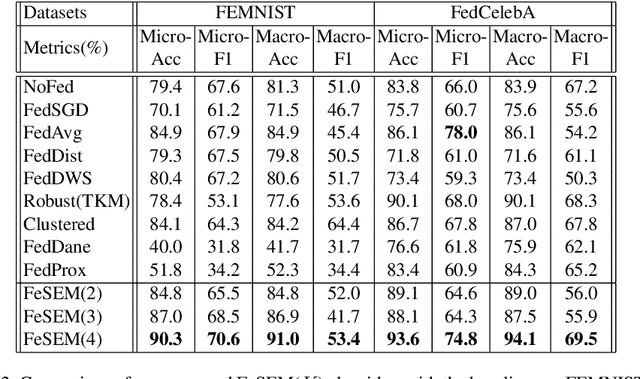
Federated learning (FL) can protect data privacy in distributed learning since it merely collects local gradients from users without access to their data. However, FL is fragile in the presence of heterogeneity that is commonly encountered in practical settings, e.g., non-IID data over different users. Existing FL approaches usually update a single global model to capture the shared knowledge of all users by aggregating their gradients, regardless of the discrepancy between their data distributions. By comparison, a mixture of multiple global models could capture the heterogeneity across various users if assigning the users to different global models (i.e., centers) in FL. To this end, we propose a novel multi-center aggregation mechanism . It learns multiple global models from data, and simultaneously derives the optimal matching between users and centers. We then formulate it as a bi-level optimization problem that can be efficiently solved by a stochastic expectation maximization (EM) algorithm. Experiments on multiple benchmark datasets of FL show that our method outperforms several popular FL competitors. The source code are open source on Github.
MIMO: Mutual Integration of Patient Journey and Medical Ontology for Healthcare Representation Learning
Jul 23, 2021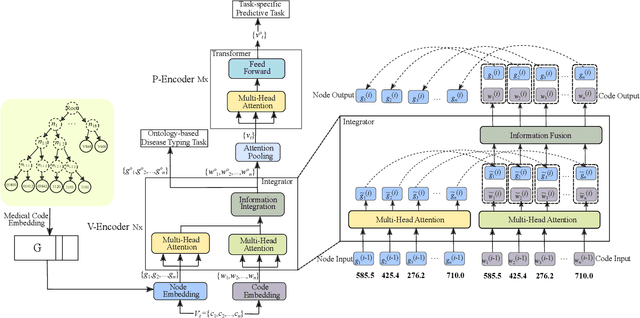
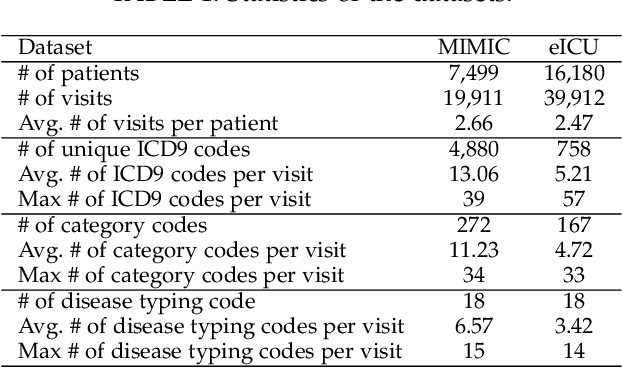
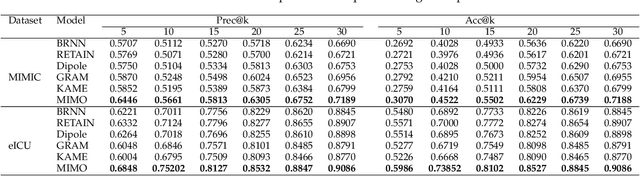
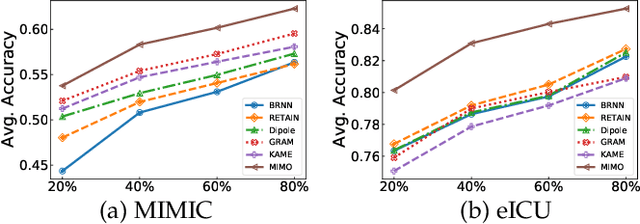
Healthcare representation learning on the Electronic Health Record (EHR) is seen as crucial for predictive analytics in the medical field. Many natural language processing techniques, such as word2vec, RNN and self-attention, have been adapted for use in hierarchical and time stamped EHR data, but fail when they lack either general or task-specific data. Hence, some recent works train healthcare representations by incorporating medical ontology (a.k.a. knowledge graph), by self-supervised tasks like diagnosis prediction, but (1) the small-scale, monotonous ontology is insufficient for robust learning, and (2) critical contexts or dependencies underlying patient journeys are never exploited to enhance ontology learning. To address this, we propose an end-to-end robust Transformer-based solution, Mutual Integration of patient journey and Medical Ontology (MIMO) for healthcare representation learning and predictive analytics. Specifically, it consists of task-specific representation learning and graph-embedding modules to learn both patient journey and medical ontology interactively. Consequently, this creates a mutual integration to benefit both healthcare representation learning and medical ontology embedding. Moreover, such integration is achieved by a joint training of both task-specific predictive and ontology-based disease typing tasks based on fused embeddings of the two modules. Experiments conducted on two real-world diagnosis prediction datasets show that, our healthcare representation model MIMO not only achieves better predictive results than previous state-of-the-art approaches regardless of sufficient or insufficient training data, but also derives more interpretable embeddings of diagnoses.
Beyond Low-pass Filtering: Graph Convolutional Networks with Automatic Filtering
Jul 10, 2021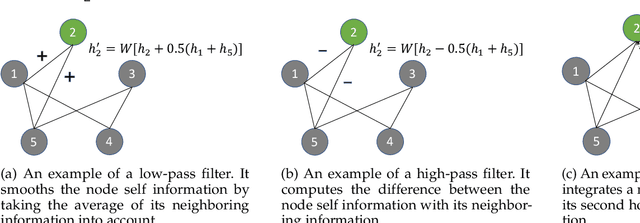

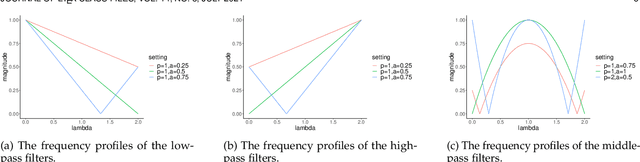
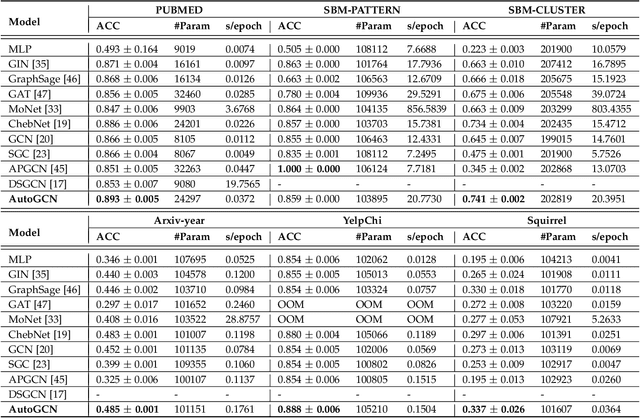
Graph convolutional networks are becoming indispensable for deep learning from graph-structured data. Most of the existing graph convolutional networks share two big shortcomings. First, they are essentially low-pass filters, thus the potentially useful middle and high frequency band of graph signals are ignored. Second, the bandwidth of existing graph convolutional filters is fixed. Parameters of a graph convolutional filter only transform the graph inputs without changing the curvature of a graph convolutional filter function. In reality, we are uncertain about whether we should retain or cut off the frequency at a certain point unless we have expert domain knowledge. In this paper, we propose Automatic Graph Convolutional Networks (AutoGCN) to capture the full spectrum of graph signals and automatically update the bandwidth of graph convolutional filters. While it is based on graph spectral theory, our AutoGCN is also localized in space and has a spatial form. Experimental results show that AutoGCN achieves significant improvement over baseline methods which only work as low-pass filters.
FedProto: Federated Prototype Learning over Heterogeneous Devices
May 01, 2021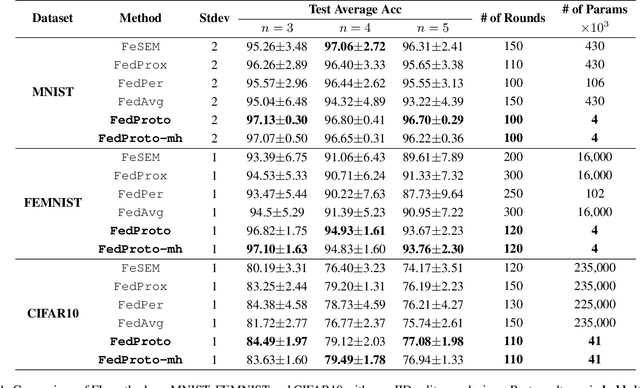
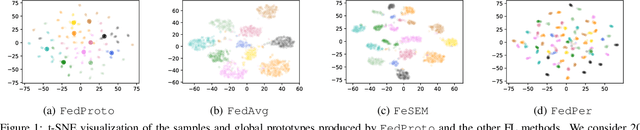
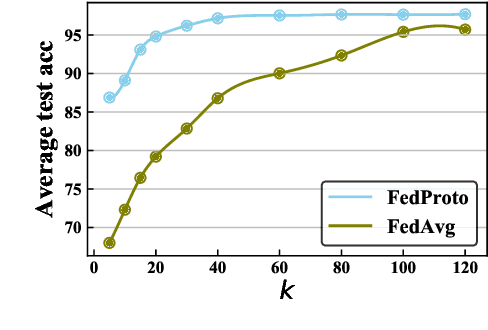
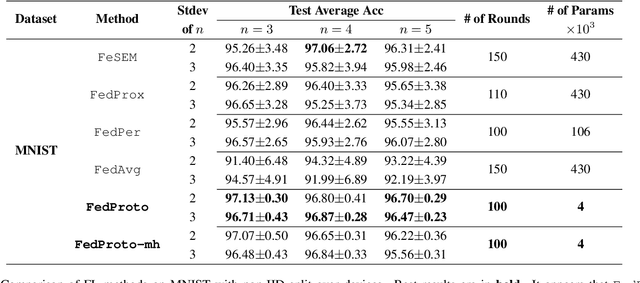
The heterogeneity across devices usually hinders the optimization convergence and generalization performance of federated learning (FL) when the aggregation of devices' knowledge occurs in the gradient space. For example, devices may differ in terms of data distribution, network latency, input/output space, and/or model architecture, which can easily lead to the misalignment of their local gradients. To improve the tolerance to heterogeneity, we propose a novel federated prototype learning (FedProto) framework in which the devices and server communicate the class prototypes instead of the gradients. FedProto aggregates the local prototypes collected from different devices, and then sends the global prototypes back to all devices to regularize the training of local models. The training on each device aims to minimize the classification error on the local data while keeping the resulting local prototypes sufficiently close to the corresponding global ones. Through experiments, we propose a benchmark setting tailored for heterogeneous FL, with FedProto outperforming several recent FL approaches on multiple datasets.
Task Aligned Generative Meta-learning for Zero-shot Learning
Mar 03, 2021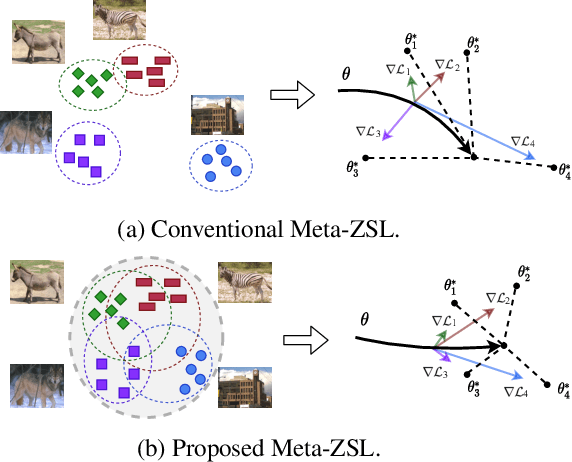

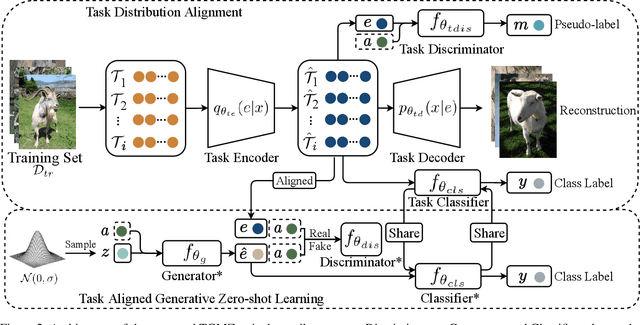
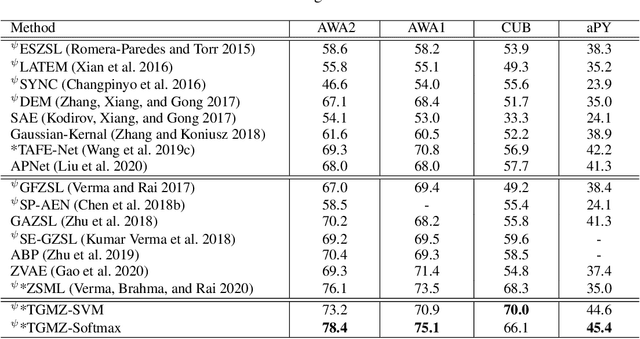
Zero-shot learning (ZSL) refers to the problem of learning to classify instances from the novel classes (unseen) that are absent in the training set (seen). Most ZSL methods infer the correlation between visual features and attributes to train the classifier for unseen classes. However, such models may have a strong bias towards seen classes during training. Meta-learning has been introduced to mitigate the basis, but meta-ZSL methods are inapplicable when tasks used for training are sampled from diverse distributions. In this regard, we propose a novel Task-aligned Generative Meta-learning model for Zero-shot learning (TGMZ). TGMZ mitigates the potentially biased training and enables meta-ZSL to accommodate real-world datasets containing diverse distributions. TGMZ incorporates an attribute-conditioned task-wise distribution alignment network that projects tasks into a unified distribution to deliver an unbiased model. Our comparisons with state-of-the-art algorithms show the improvements of 2.1%, 3.0%, 2.5%, and 7.6% achieved by TGMZ on AWA1, AWA2, CUB, and aPY datasets, respectively. TGMZ also outperforms competitors by 3.6% in generalized zero-shot learning (GZSL) setting and 7.9% in our proposed fusion-ZSL setting.
Emerging Trends in Federated Learning: From Model Fusion to Federated X Learning
Feb 25, 2021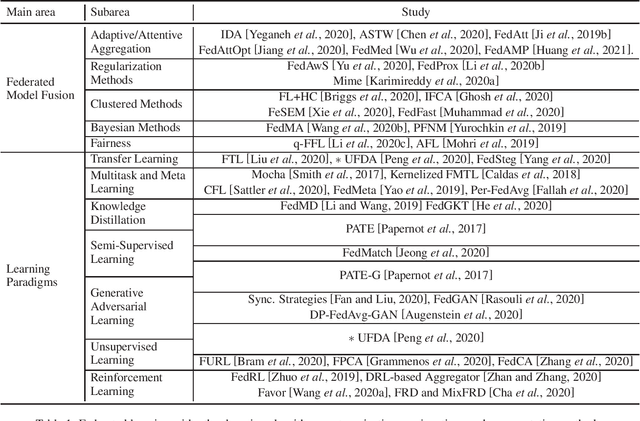
Federated learning is a new learning paradigm that decouples data collection and model training via multi-party computation and model aggregation. As a flexible learning setting, federated learning has the potential to integrate with other learning frameworks. We conduct a focused survey of federated learning in conjunction with other learning algorithms. Specifically, we explore various learning algorithms to improve the vanilla federated averaging algorithm and review model fusion methods such as adaptive aggregation, regularization, clustered methods, and Bayesian methods. Following the emerging trends, we also discuss federated learning in the intersection with other learning paradigms, termed as federated x learning, where x includes multitask learning, meta-learning, transfer learning, unsupervised learning, and reinforcement learning. This survey reviews the state of the art, challenges, and future directions.
Isometric Propagation Network for Generalized Zero-shot Learning
Feb 03, 2021
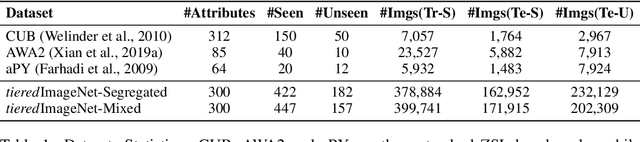
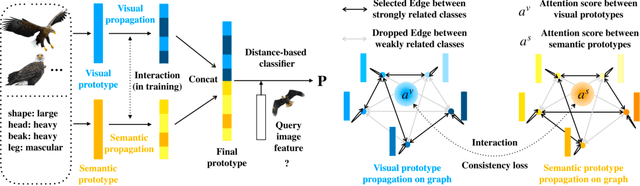
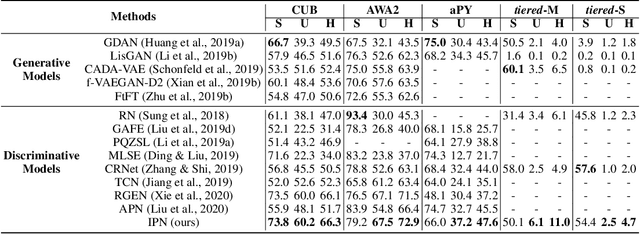
Zero-shot learning (ZSL) aims to classify images of an unseen class only based on a few attributes describing that class but no access to any training sample. A popular strategy is to learn a mapping between the semantic space of class attributes and the visual space of images based on the seen classes and their data. Thus, an unseen class image can be ideally mapped to its corresponding class attributes. The key challenge is how to align the representations in the two spaces. For most ZSL settings, the attributes for each seen/unseen class are only represented by a vector while the seen-class data provide much more information. Thus, the imbalanced supervision from the semantic and the visual space can make the learned mapping easily overfitting to the seen classes. To resolve this problem, we propose Isometric Propagation Network (IPN), which learns to strengthen the relation between classes within each space and align the class dependency in the two spaces. Specifically, IPN learns to propagate the class representations on an auto-generated graph within each space. In contrast to only aligning the resulted static representation, we regularize the two dynamic propagation procedures to be isometric in terms of the two graphs' edge weights per step by minimizing a consistency loss between them. IPN achieves state-of-the-art performance on three popular ZSL benchmarks. To evaluate the generalization capability of IPN, we further build two larger benchmarks with more diverse unseen classes and demonstrate the advantages of IPN on them.