 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr$^2$Net: Dynamic Reversible Dual-Residual Networks for Memory-Efficient Finetuning
Jan 08, 2024



Large pretrained models are increasingly crucial in modern computer vision tasks. These models are typically used in downstream tasks by end-to-end finetuning, which is highly memory-intensive for tasks with high-resolution data, e.g., video understanding, small object detection, and point cloud analysis. In this paper, we propose Dynamic Reversible Dual-Residual Networks, or Dr$^2$Net, a novel family of network architectures that acts as a surrogate network to finetune a pretrained model with substantially reduced memory consumption. Dr$^2$Net contains two types of residual connections, one maintaining the residual structure in the pretrained models, and the other making the network reversible. Due to its reversibility, intermediate activations, which can be reconstructed from output, are cleared from memory during training. We use two coefficients on either type of residual connections respectively, and introduce a dynamic training strategy that seamlessly transitions the pretrained model to a reversible network with much higher numerical precision. We evaluate Dr$^2$Net on various pretrained models and various tasks, and show that it can reach comparable performance to conventional finetuning but with significantly less memory usage.
Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
Jun 30, 2023



We present Magic123, a two-stage coarse-to-fine approach for high-quality, textured 3D meshes generation from a single unposed image in the wild using both2D and 3D priors. In the first stage, we optimize a neural radiance field to produce a coarse geometry. In the second stage, we adopt a memory-efficient differentiable mesh representation to yield a high-resolution mesh with a visually appealing texture. In both stages, the 3D content is learned through reference view supervision and novel views guided by a combination of 2D and 3D diffusion priors. We introduce a single trade-off parameter between the 2D and 3D priors to control exploration (more imaginative) and exploitation (more precise) of the generated geometry. Additionally, we employ textual inversion and monocular depth regularization to encourage consistent appearances across views and to prevent degenerate solutions, respectively. Magic123 demonstrates a significant improvement over previous image-to-3D techniques, as validated through extensive experiments on synthetic benchmarks and diverse real-world images. Our code, models, and generated 3D assets are available at https://github.com/guochengqian/Magic123.
Exploring Open-Vocabulary Semantic Segmentation without Human Labels
Jun 01, 2023Semantic segmentation is a crucial task in computer vision that involves segmenting images into semantically meaningful regions at the pixel level. However, existing approaches often rely on expensive human annotations as supervision for model training, limiting their scalability to large, unlabeled datasets. To address this challenge, we present ZeroSeg, a novel method that leverages the existing pretrained vision-language (VL) model (e.g. CLIP) to train open-vocabulary zero-shot semantic segmentation models. Although acquired extensive knowledge of visual concepts, it is non-trivial to exploit knowledge from these VL models to the task of semantic segmentation, as they are usually trained at an image level. ZeroSeg overcomes this by distilling the visual concepts learned by VL models into a set of segment tokens, each summarizing a localized region of the target image. We evaluate ZeroSeg on multiple popular segmentation benchmarks, including PASCAL VOC 2012, PASCAL Context, and COCO, in a zero-shot manner (i.e., no training or adaption on target segmentation datasets). Our approach achieves state-of-the-art performance when compared to other zero-shot segmentation methods under the same training data, while also performing competitively compared to strongly supervised methods. Finally, we also demonstrated the effectiveness of ZeroSeg on open-vocabulary segmentation, through both human studies and qualitative visualizations.
LLM as A Robotic Brain: Unifying Egocentric Memory and Control
Apr 27, 2023



Embodied AI focuses on the study and development of intelligent systems that possess a physical or virtual embodiment (i.e. robots) and are able to dynamically interact with their environment. Memory and control are the two essential parts of an embodied system and usually require separate frameworks to model each of them. In this paper, we propose a novel and generalizable framework called LLM-Brain: using Large-scale Language Model as a robotic brain to unify egocentric memory and control. The LLM-Brain framework integrates multiple multimodal language models for robotic tasks, utilizing a zero-shot learning approach. All components within LLM-Brain communicate using natural language in closed-loop multi-round dialogues that encompass perception, planning, control, and memory. The core of the system is an embodied LLM to maintain egocentric memory and control the robot. We demonstrate LLM-Brain by examining two downstream tasks: active exploration and embodied question answering. The active exploration tasks require the robot to extensively explore an unknown environment within a limited number of actions. Meanwhile, the embodied question answering tasks necessitate that the robot answers questions based on observations acquired during prior explorations.
Pix4Point: Image Pretrained Transformers for 3D Point Cloud Understanding
Aug 25, 2022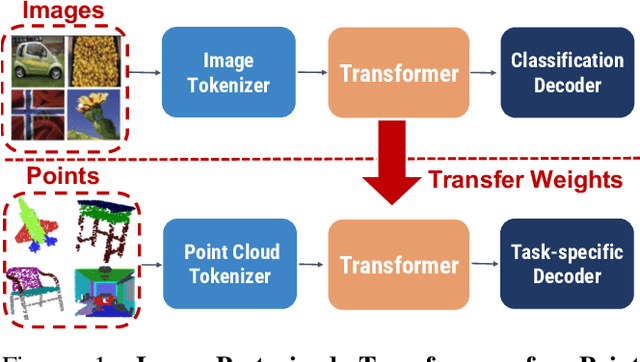
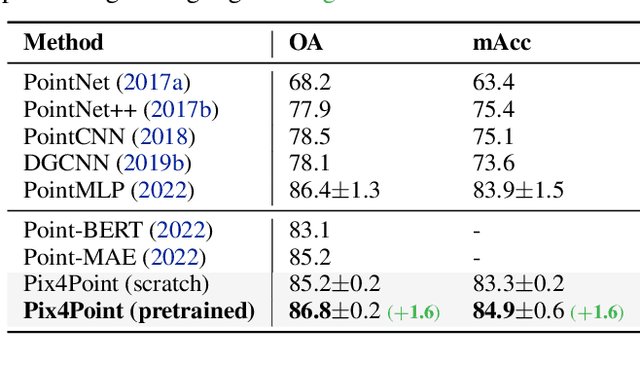
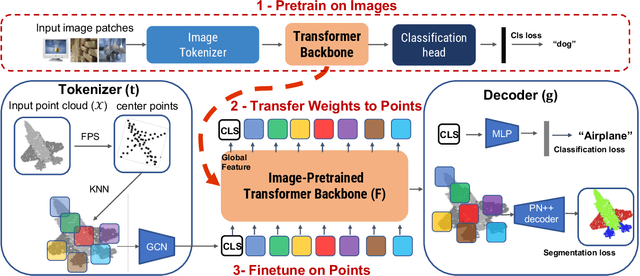
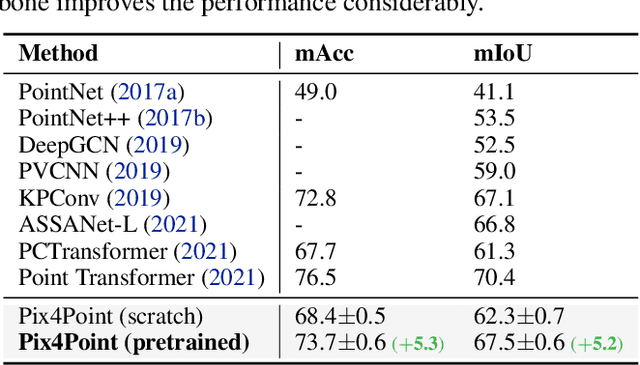
Pure Transformer models have achieved impressive success in natural language processing and computer vision. However, one limitation with Transformers is their need for large training data. In the realm of 3D point clouds, the availability of large datasets is a challenge, which exacerbates the issue of training Transformers for 3D tasks. In this work, we empirically study and investigate the effect of utilizing knowledge from a large number of images for point cloud understanding. We formulate a pipeline dubbed \textit{Pix4Point} that allows harnessing pretrained Transformers in the image domain to improve downstream point cloud tasks. This is achieved by a modality-agnostic pure Transformer backbone with the help of tokenizer and decoder layers specialized in the 3D domain. Using image-pretrained Transformers, we observe significant performance gains of Pix4Point on the tasks of 3D point cloud classification, part segmentation, and semantic segmentation on ScanObjectNN, ShapeNetPart, and S3DIS benchmarks, respectively. Our code and models are available at: \url{https://github.com/guochengqian/Pix4Point}.
PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies
Jun 09, 2022
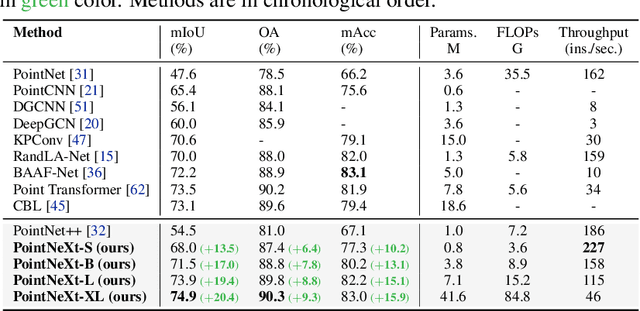
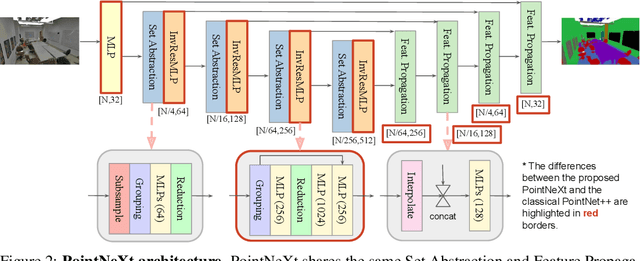
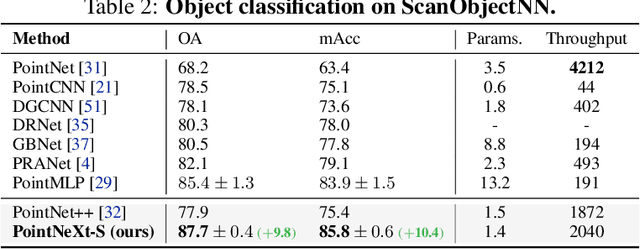
PointNet++ is one of the most influential neural architectures for point cloud understanding. Although the accuracy of PointNet++ has been largely surpassed by recent networks such as PointMLP and Point Transformer, we find that a large portion of the performance gain is due to improved training strategies, i.e. data augmentation and optimization techniques, and increased model sizes rather than architectural innovations. Thus, the full potential of PointNet++ has yet to be explored. In this work, we revisit the classical PointNet++ through a systematic study of model training and scaling strategies, and offer two major contributions. First, we propose a set of improved training strategies that significantly improve PointNet++ performance. For example, we show that, without any change in architecture, the overall accuracy (OA) of PointNet++ on ScanObjectNN object classification can be raised from 77.9\% to 86.1\%, even outperforming state-of-the-art PointMLP. Second, we introduce an inverted residual bottleneck design and separable MLPs into PointNet++ to enable efficient and effective model scaling and propose PointNeXt, the next version of PointNets. PointNeXt can be flexibly scaled up and outperforms state-of-the-art methods on both 3D classification and segmentation tasks. For classification, PointNeXt reaches an overall accuracy of $87.7\%$ on ScanObjectNN, surpassing PointMLP by $2.3\%$, while being $10 \times$ faster in inference. For semantic segmentation, PointNeXt establishes a new state-of-the-art performance with $74.9\%$ mean IoU on S3DIS (6-fold cross-validation), being superior to the recent Point Transformer. The code and models are available at https://github.com/guochengqian/pointnext.
When NAS Meets Trees: An Efficient Algorithm for Neural Architecture Search
Apr 11, 2022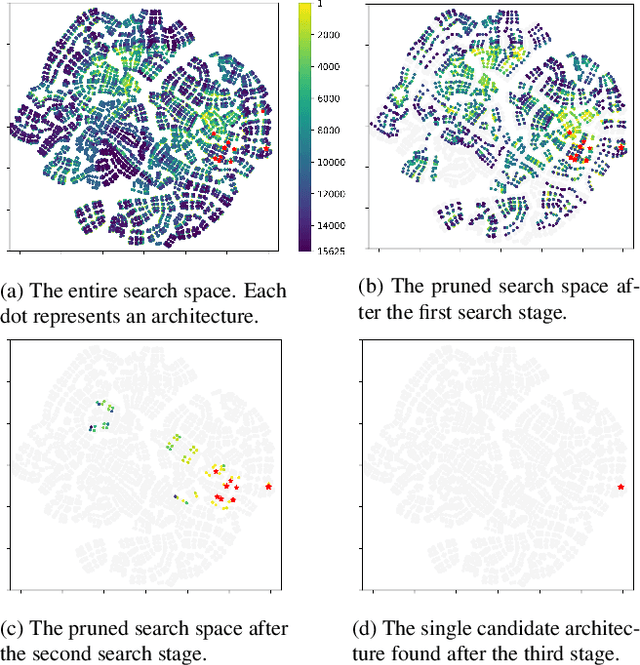
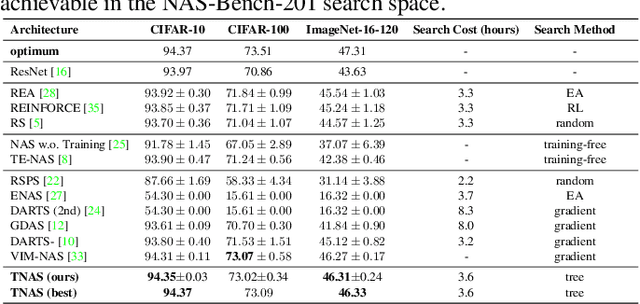
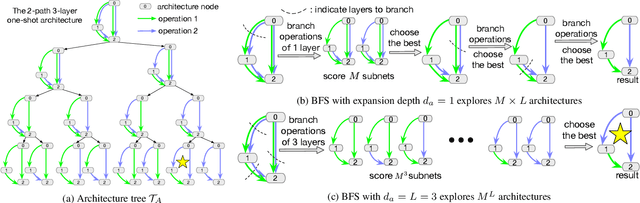
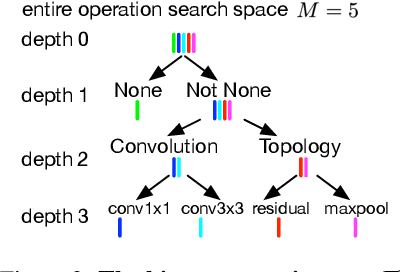
The key challenge in neural architecture search (NAS) is designing how to explore wisely in the huge search space. We propose a new NAS method called TNAS (NAS with trees), which improves search efficiency by exploring only a small number of architectures while also achieving a higher search accuracy. TNAS introduces an architecture tree and a binary operation tree, to factorize the search space and substantially reduce the exploration size. TNAS performs a modified bi-level Breadth-First Search in the proposed trees to discover a high-performance architecture. Impressively, TNAS finds the global optimal architecture on CIFAR-10 with test accuracy of 94.37\% in four GPU hours in NAS-Bench-201. The average test accuracy is 94.35\%, which outperforms the state-of-the-art. Code is available at: \url{https://github.com/guochengqian/TNAS}.
ASSANet: An Anisotropic Separable Set Abstraction for Efficient Point Cloud Representation Learning
Oct 24, 2021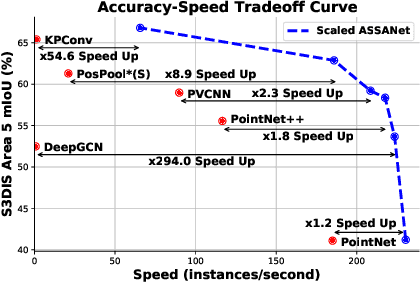
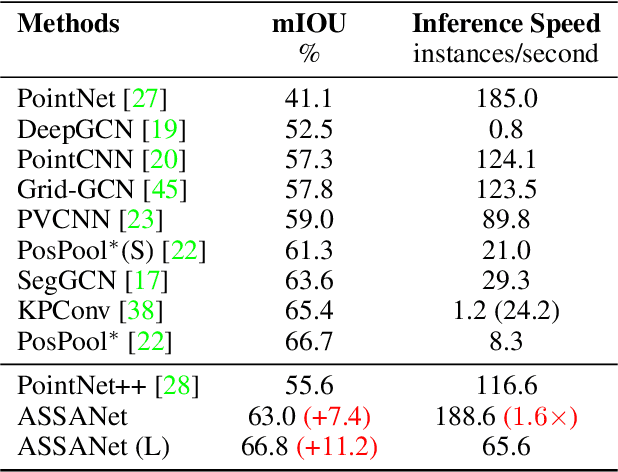

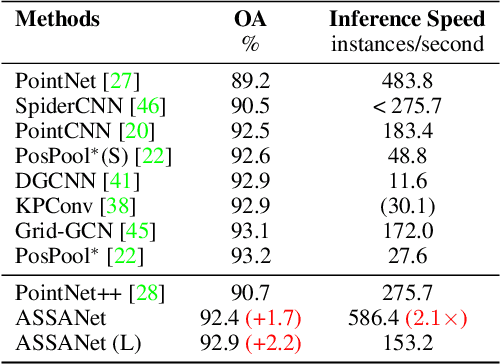
Access to 3D point cloud representations has been widely facilitated by LiDAR sensors embedded in various mobile devices. This has led to an emerging need for fast and accurate point cloud processing techniques. In this paper, we revisit and dive deeper into PointNet++, one of the most influential yet under-explored networks, and develop faster and more accurate variants of the model. We first present a novel Separable Set Abstraction (SA) module that disentangles the vanilla SA module used in PointNet++ into two separate learning stages: (1) learning channel correlation and (2) learning spatial correlation. The Separable SA module is significantly faster than the vanilla version, yet it achieves comparable performance. We then introduce a new Anisotropic Reduction function into our Separable SA module and propose an Anisotropic Separable SA (ASSA) module that substantially increases the network's accuracy. We later replace the vanilla SA modules in PointNet++ with the proposed ASSA module, and denote the modified network as ASSANet. Extensive experiments on point cloud classification, semantic segmentation, and part segmentation show that ASSANet outperforms PointNet++ and other methods, achieving much higher accuracy and faster speeds. In particular, ASSANet outperforms PointNet++ by $7.4$ mIoU on S3DIS Area 5, while maintaining $1.6 \times $ faster inference speed on a single NVIDIA 2080Ti GPU. Our scaled ASSANet variant achieves $66.8$ mIoU and outperforms KPConv, while being more than $54 \times$ faster.
PU-GCN: Point Cloud Upsampling using Graph Convolutional Networks
Nov 30, 2019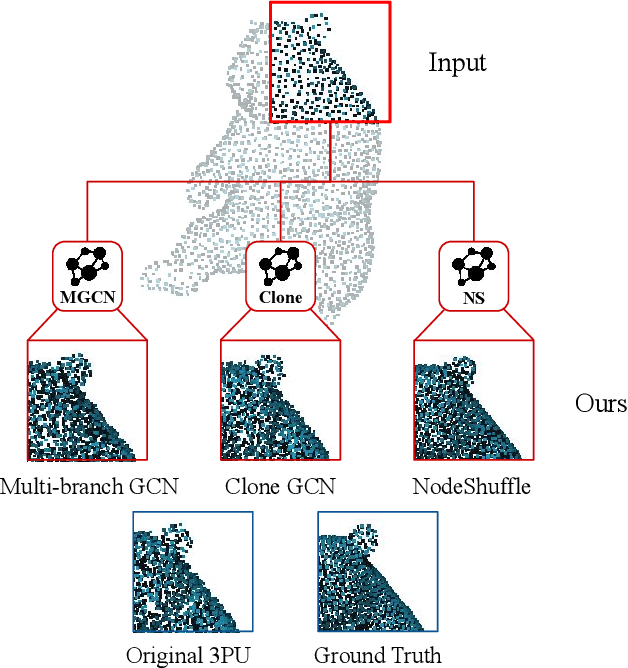
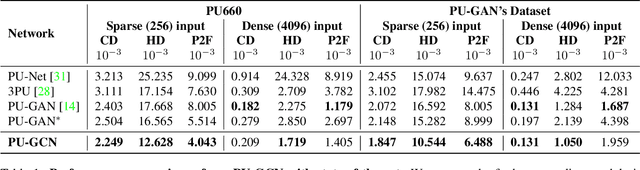
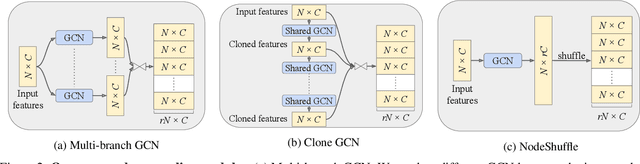
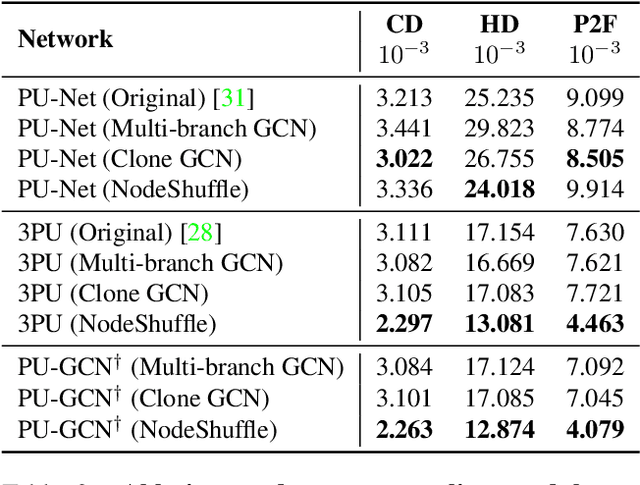
Upsampling sparse, noisy, and non-uniform point clouds is a challenging task. In this paper, we propose 3 novel point upsampling modules: Multi-branch GCN, Clone GCN, and NodeShuffle. Our modules use Graph Convolutional Networks (GCNs) to better encode local point information. Our upsampling modules are versatile and can be incorporated into any point cloud upsampling pipeline. We show how our 3 modules consistently improve state-of-the-art methods in all point upsampling metrics. We also propose a new multi-scale point feature extractor, called Inception DenseGCN. We modify current Inception GCN algorithms by introducing DenseGCN blocks. By aggregating data at multiple scales, our new feature extractor is more resilient to density changes along point cloud surfaces. We combine Inception DenseGCN with one of our upsampling modules (NodeShuffle) into a new point upsampling pipeline: PU-GCN. We show both qualitatively and quantitatively the advantages of PU-GCN against the state-of-the-art in terms of fine-grained upsampling quality and point cloud uniformity. The website and source code of this work is available at https://sites.google.com/kaust.edu.sa/pugcn and https://github.com/guochengqian/PU-GCN respectively.
SGAS: Sequential Greedy Architecture Search
Nov 30, 2019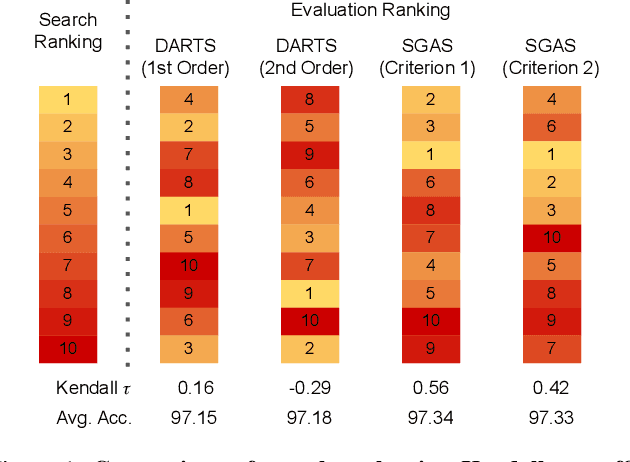
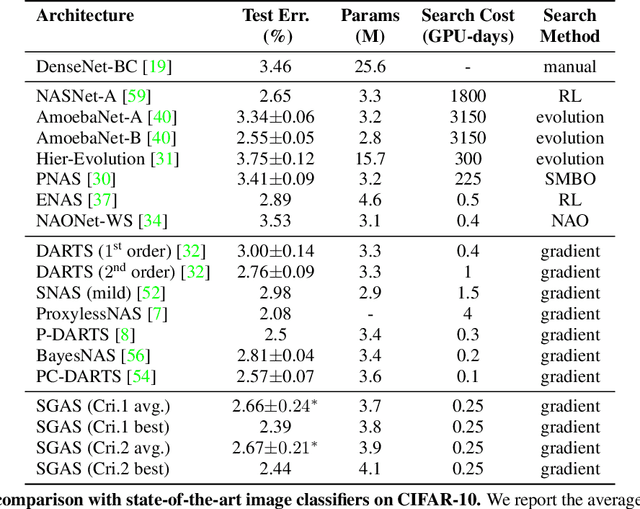
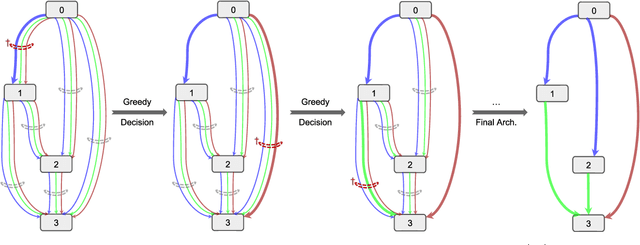
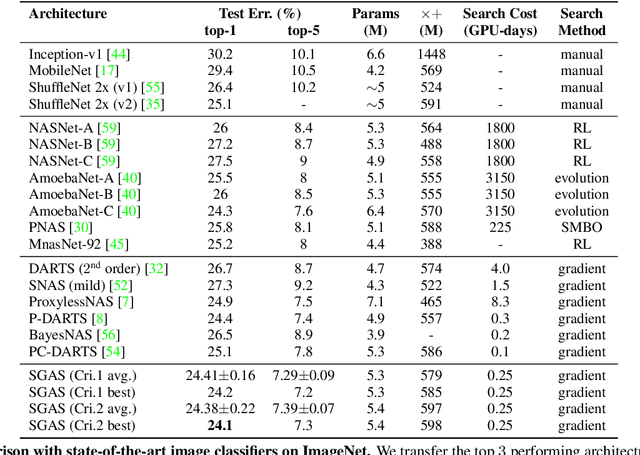
Architecture design has become a crucial component of successful deep learning. Recent progress in automatic neural architecture search (NAS) shows a lot of promise. However, discovered architectures often fail to generalize in the final evaluation. Architectures with a higher validation accuracy during the search phase may perform worse in the evaluation. Aiming to alleviate this common issue, we introduce sequential greedy architecture search (SGAS), an efficient method for neural architecture search. By dividing the search procedure into sub-problems, SGAS chooses and prunes candidate operations in a greedy fashion. We apply SGAS to search architectures for Convolutional Neural Networks (CNN) and Graph Convolutional Networks (GCN). Extensive experiments show that SGAS is able to find state-of-the-art architectures for tasks such as image classification, point cloud classification and node classification in protein-protein interaction graphs with minimal computational cost. Please visit https://sites.google.com/kaust.edu.sa/sgas for more information about SGAS.