 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWell-classified Examples are Underestimated in Classification with Deep Neural Networks
Oct 15, 2021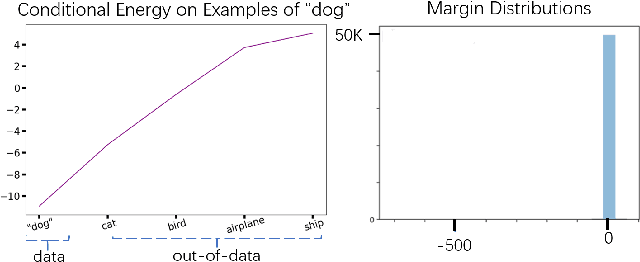
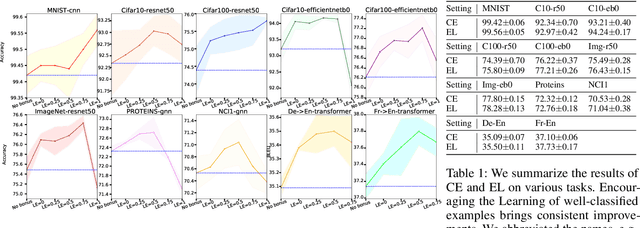
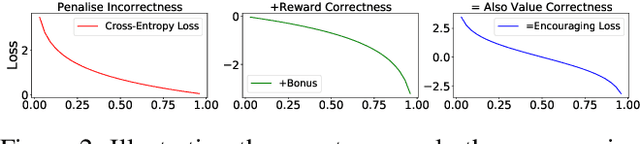

The conventional wisdom behind learning deep classification models is to focus on bad-classified examples and ignore well-classified examples that are far from the decision boundary. For instance, when training with cross-entropy loss, examples with higher likelihoods (i.e., well-classified examples) contribute smaller gradients in back-propagation. However, we theoretically show that this common practice hinders representation learning, energy optimization, and the growth of margin. To counteract this deficiency, we propose to reward well-classified examples with additive bonuses to revive their contribution to learning. This counterexample theoretically addresses these three issues. We empirically support this claim by directly verify the theoretical results or through the significant performance improvement with our counterexample on diverse tasks, including image classification, graph classification, and machine translation. Furthermore, this paper shows that because our idea can solve these three issues, we can deal with complex scenarios, such as imbalanced classification, OOD detection, and applications under adversarial attacks. Code is available at: https://github.com/lancopku/well-classified-examples-are-underestimated.
Topology-Imbalance Learning for Semi-Supervised Node Classification
Oct 08, 2021



The class imbalance problem, as an important issue in learning node representations, has drawn increasing attention from the community. Although the imbalance considered by existing studies roots from the unequal quantity of labeled examples in different classes (quantity imbalance), we argue that graph data expose a unique source of imbalance from the asymmetric topological properties of the labeled nodes, i.e., labeled nodes are not equal in terms of their structural role in the graph (topology imbalance). In this work, we first probe the previously unknown topology-imbalance issue, including its characteristics, causes, and threats to semi-supervised node classification learning. We then provide a unified view to jointly analyzing the quantity- and topology- imbalance issues by considering the node influence shift phenomenon with the Label Propagation algorithm. In light of our analysis, we devise an influence conflict detection -- based metric Totoro to measure the degree of graph topology imbalance and propose a model-agnostic method ReNode to address the topology-imbalance issue by re-weighting the influence of labeled nodes adaptively based on their relative positions to class boundaries. Systematic experiments demonstrate the effectiveness and generalizability of our method in relieving topology-imbalance issue and promoting semi-supervised node classification. The further analysis unveils varied sensitivity of different graph neural networks (GNNs) to topology imbalance, which may serve as a new perspective in evaluating GNN architectures.
Learning Relation Alignment for Calibrated Cross-modal Retrieval
Jun 01, 2021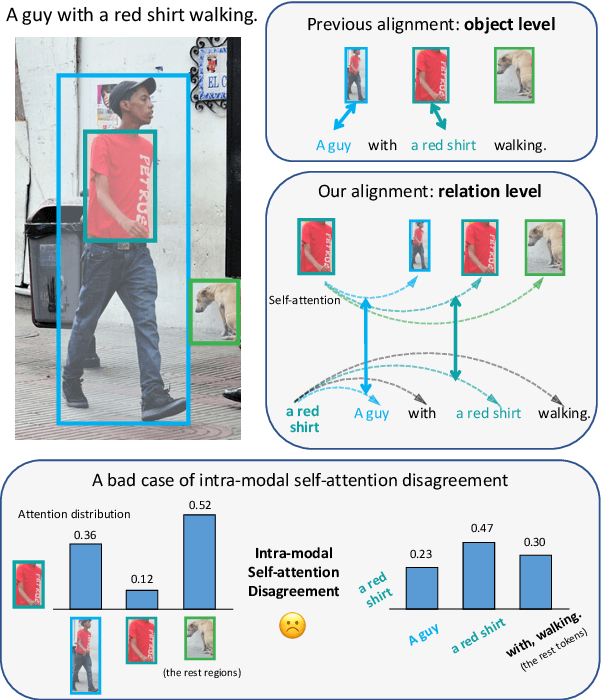
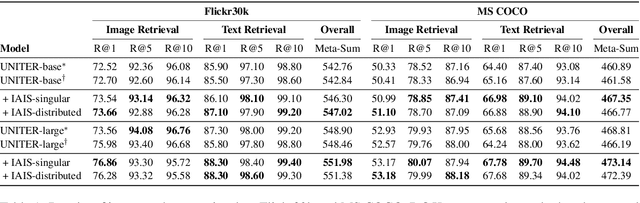
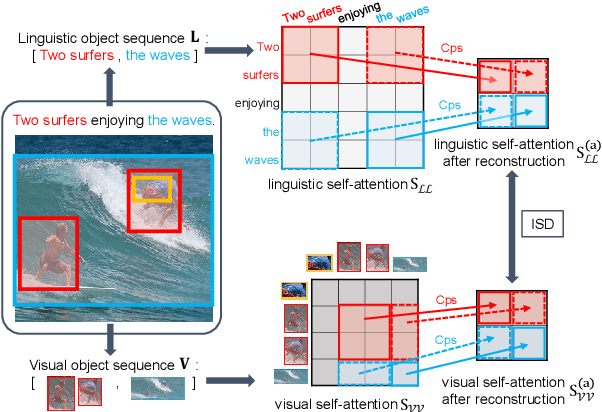
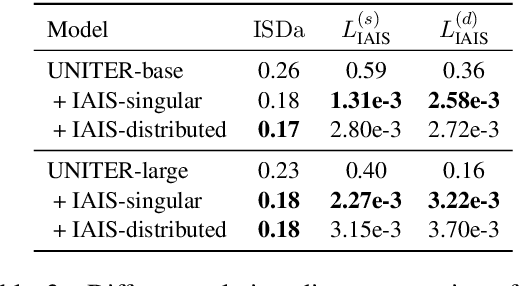
Despite the achievements of large-scale multimodal pre-training approaches, cross-modal retrieval, e.g., image-text retrieval, remains a challenging task. To bridge the semantic gap between the two modalities, previous studies mainly focus on word-region alignment at the object level, lacking the matching between the linguistic relation among the words and the visual relation among the regions. The neglect of such relation consistency impairs the contextualized representation of image-text pairs and hinders the model performance and the interpretability. In this paper, we first propose a novel metric, Intra-modal Self-attention Distance (ISD), to quantify the relation consistency by measuring the semantic distance between linguistic and visual relations. In response, we present Inter-modal Alignment on Intra-modal Self-attentions (IAIS), a regularized training method to optimize the ISD and calibrate intra-modal self-attentions from the two modalities mutually via inter-modal alignment. The IAIS regularizer boosts the performance of prevailing models on Flickr30k and MS COCO datasets by a considerable margin, which demonstrates the superiority of our approach.
Layer-Wise Cross-View Decoding for Sequence-to-Sequence Learning
Jun 03, 2020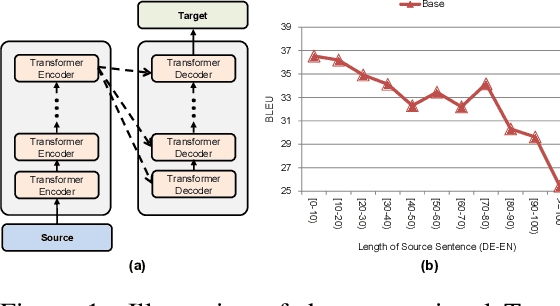
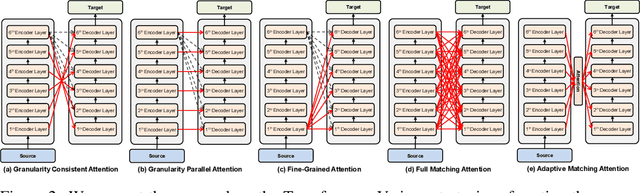
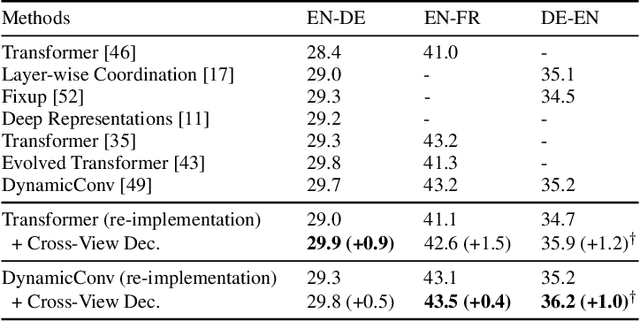
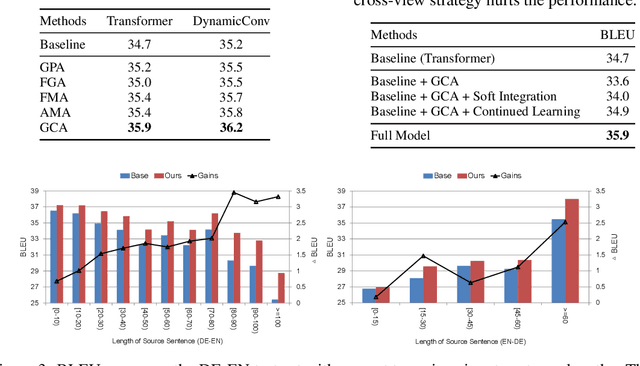
In sequence-to-sequence learning, the attention mechanism has been a great success in bridging the information between the encoder and the decoder. However, it is often overlooked that the decoder obtains only a single view of the source sequences, i.e., the representations generated by the last encoder layer. Although those representations are supposed to be a comprehensive, global view of source sequences, such practice keeps the decoders from concrete, fine-grained source information generated by other encoder layers. In this work, we propose to encourage the decoder to take the full advantage of the multi-level source representations for layer-wise cross-view decoding. Concretely, different views of the source sequences are presented to different decoder layers and multiple strategies are explored to route the source representations. In particular, the granularity consistent attention (GCA) strategy proves the most efficient and effective in the experiments on the neural machine translation task, surpassing the previous state-of-the-art architecture on three benchmark datasets.
Explicit Sparse Transformer: Concentrated Attention Through Explicit Selection
Dec 25, 2019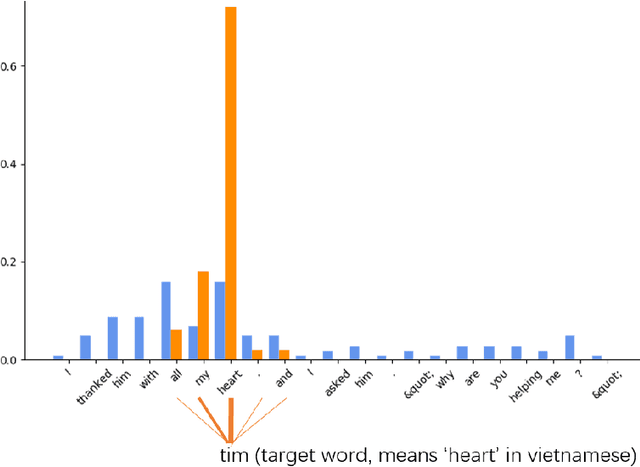
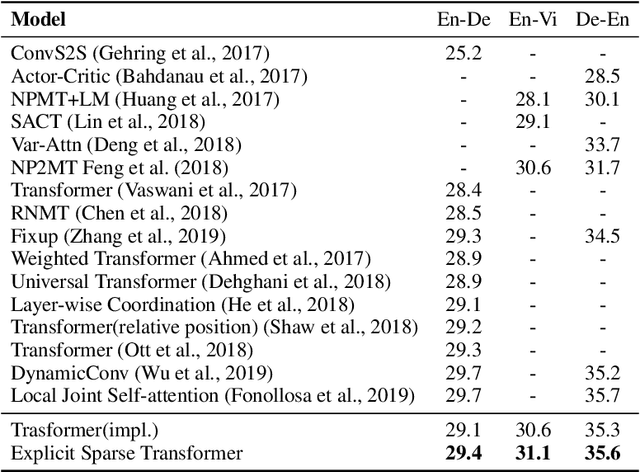
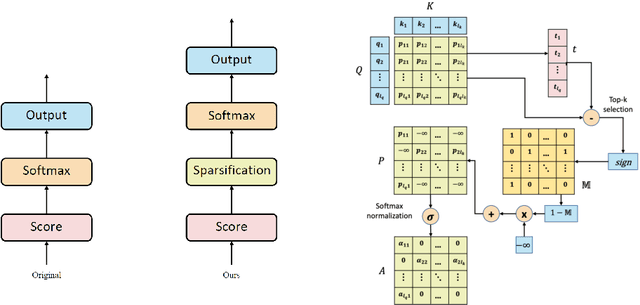
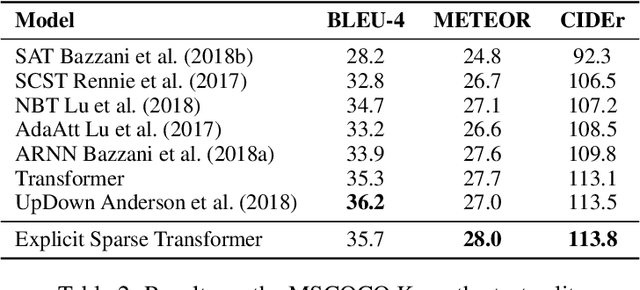
Self-attention based Transformer has demonstrated the state-of-the-art performances in a number of natural language processing tasks. Self-attention is able to model long-term dependencies, but it may suffer from the extraction of irrelevant information in the context. To tackle the problem, we propose a novel model called \textbf{Explicit Sparse Transformer}. Explicit Sparse Transformer is able to improve the concentration of attention on the global context through an explicit selection of the most relevant segments. Extensive experimental results on a series of natural language processing and computer vision tasks, including neural machine translation, image captioning, and language modeling, all demonstrate the advantages of Explicit Sparse Transformer in model performance. We also show that our proposed sparse attention method achieves comparable or better results than the previous sparse attention method, but significantly reduces training and testing time. For example, the inference speed is twice that of sparsemax in Transformer model. Code will be available at \url{https://github.com/lancopku/Explicit-Sparse-Transformer}
MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning
Nov 17, 2019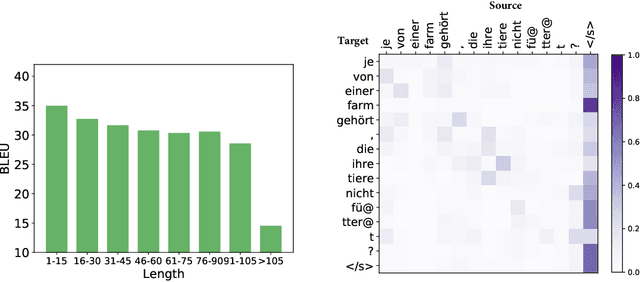
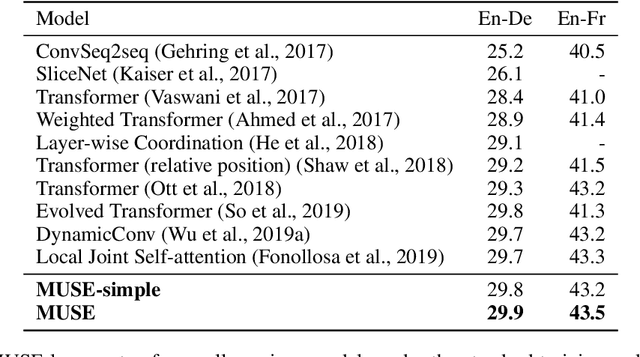
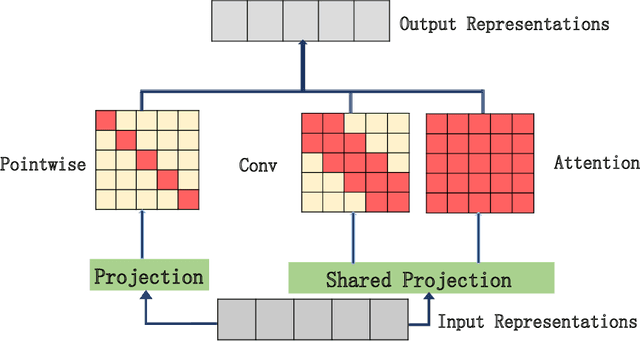
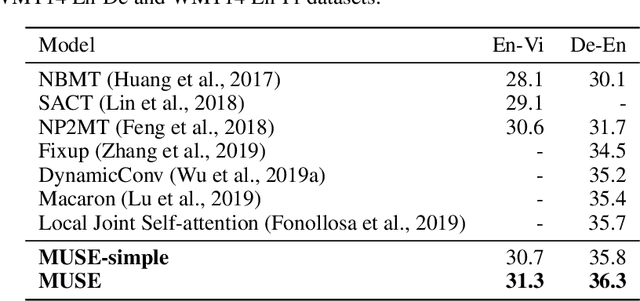
In sequence to sequence learning, the self-attention mechanism proves to be highly effective, and achieves significant improvements in many tasks. However, the self-attention mechanism is not without its own flaws. Although self-attention can model extremely long dependencies, the attention in deep layers tends to overconcentrate on a single token, leading to insufficient use of local information and difficultly in representing long sequences. In this work, we explore parallel multi-scale representation learning on sequence data, striving to capture both long-range and short-range language structures. To this end, we propose the Parallel MUlti-Scale attEntion (MUSE) and MUSE-simple. MUSE-simple contains the basic idea of parallel multi-scale sequence representation learning, and it encodes the sequence in parallel, in terms of different scales with the help from self-attention, and pointwise transformation. MUSE builds on MUSE-simple and explores combining convolution and self-attention for learning sequence representations from more different scales. We focus on machine translation and the proposed approach achieves substantial performance improvements over Transformer, especially on long sequences. More importantly, we find that although conceptually simple, its success in practice requires intricate considerations, and the multi-scale attention must build on unified semantic space. Under common setting, the proposed model achieves substantial performance and outperforms all previous models on three main machine translation tasks. In addition, MUSE has potential for accelerating inference due to its parallelism. Code will be available at https://github.com/lancopku/MUSE
Understanding and Improving Layer Normalization
Nov 16, 2019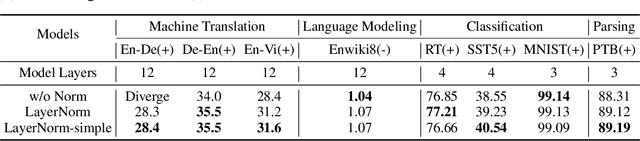
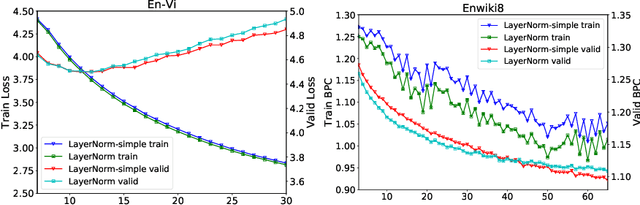
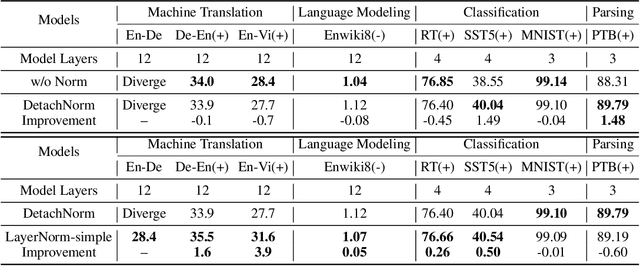
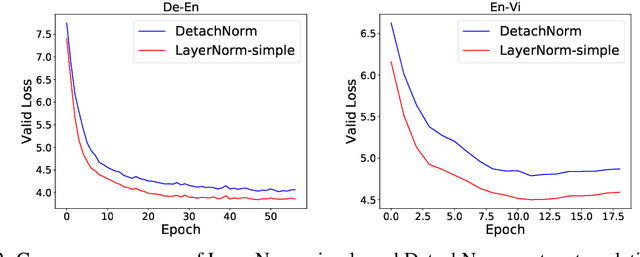
Layer normalization (LayerNorm) is a technique to normalize the distributions of intermediate layers. It enables smoother gradients, faster training, and better generalization accuracy. However, it is still unclear where the effectiveness stems from. In this paper, our main contribution is to take a step further in understanding LayerNorm. Many of previous studies believe that the success of LayerNorm comes from forward normalization. Unlike them, we find that the derivatives of the mean and variance are more important than forward normalization by re-centering and re-scaling backward gradients. Furthermore, we find that the parameters of LayerNorm, including the bias and gain, increase the risk of over-fitting and do not work in most cases. Experiments show that a simple version of LayerNorm (LayerNorm-simple) without the bias and gain outperforms LayerNorm on four datasets. It obtains the state-of-the-art performance on En-Vi machine translation. To address the over-fitting problem, we propose a new normalization method, Adaptive Normalization (AdaNorm), by replacing the bias and gain with a new transformation function. Experiments show that AdaNorm demonstrates better results than LayerNorm on seven out of eight datasets.
Review-Driven Multi-Label Music Style Classification by Exploiting Style Correlations
Aug 23, 2018
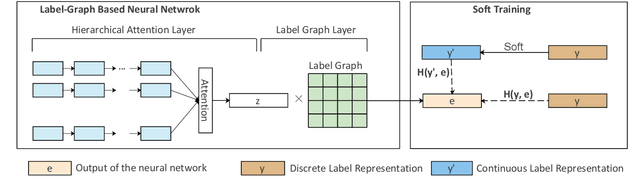
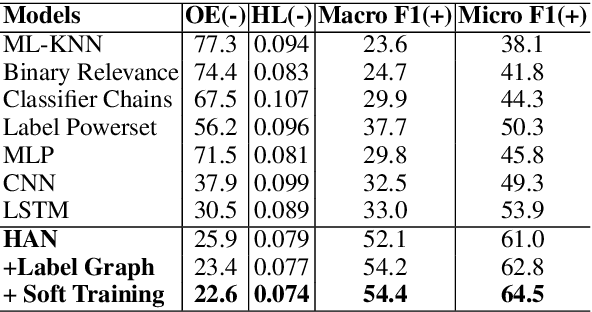
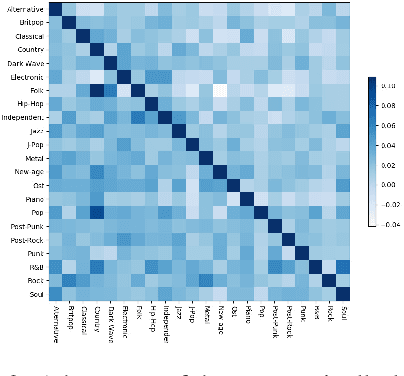
This paper explores a new natural language processing task, review-driven multi-label music style classification. This task requires the system to identify multiple styles of music based on its reviews on websites. The biggest challenge lies in the complicated relations of music styles. It has brought failure to many multi-label classification methods. To tackle this problem, we propose a novel deep learning approach to automatically learn and exploit style correlations. The proposed method consists of two parts: a label-graph based neural network, and a soft training mechanism with correlation-based continuous label representation. Experimental results show that our approach achieves large improvements over the baselines on the proposed dataset. Especially, the micro F1 is improved from 53.9 to 64.5, and the one-error is reduced from 30.5 to 22.6. Furthermore, the visualized analysis shows that our approach performs well in capturing style correlations.