 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonnet: Spectral Operator Neural Network for Multivariable Time Series Forecasting
May 21, 2025Multivariable time series forecasting methods can integrate information from exogenous variables, leading to significant prediction accuracy gains. Transformer architecture has been widely applied in various time series forecasting models due to its ability to capture long-range sequential dependencies. However, a na\"ive application of transformers often struggles to effectively model complex relationships among variables over time. To mitigate against this, we propose a novel architecture, namely the Spectral Operator Neural Network (Sonnet). Sonnet applies learnable wavelet transformations to the input and incorporates spectral analysis using the Koopman operator. Its predictive skill relies on the Multivariable Coherence Attention (MVCA), an operation that leverages spectral coherence to model variable dependencies. Our empirical analysis shows that Sonnet yields the best performance on $34$ out of $47$ forecasting tasks with an average mean absolute error (MAE) reduction of $1.1\%$ against the most competitive baseline (different per task). We further show that MVCA -- when put in place of the na\"ive attention used in various deep learning models -- can remedy its deficiencies, reducing MAE by $10.7\%$ on average in the most challenging forecasting tasks.
DeformTime: Capturing Variable Dependencies with Deformable Attention for Time Series Forecasting
Jun 11, 2024



In multivariate time series (MTS) forecasting, existing state-of-the-art deep learning approaches tend to focus on autoregressive formulations and overlook the information within exogenous indicators. To address this limitation, we present DeformTime, a neural network architecture that attempts to capture correlated temporal patterns from the input space, and hence, improve forecasting accuracy. It deploys two core operations performed by deformable attention blocks (DABs): learning dependencies across variables from different time steps (variable DAB), and preserving temporal dependencies in data from previous time steps (temporal DAB). Input data transformation is explicitly designed to enhance learning from the deformed series of information while passing through a DAB. We conduct extensive experiments on 6 MTS data sets, using previously established benchmarks as well as challenging infectious disease modelling tasks with more exogenous variables. The results demonstrate that DeformTime improves accuracy against previous competitive methods across the vast majority of MTS forecasting tasks, reducing the mean absolute error by 10% on average. Notably, performance gains remain consistent across longer forecasting horizons.
Unsupervised hard Negative Augmentation for contrastive learning
Jan 05, 2024


We present Unsupervised hard Negative Augmentation (UNA), a method that generates synthetic negative instances based on the term frequency-inverse document frequency (TF-IDF) retrieval model. UNA uses TF-IDF scores to ascertain the perceived importance of terms in a sentence and then produces negative samples by replacing terms with respect to that. Our experiments demonstrate that models trained with UNA improve the overall performance in semantic textual similarity tasks. Additional performance gains are obtained when combining UNA with the paraphrasing augmentation. Further results show that our method is compatible with different backbone models. Ablation studies also support the choice of having a TF-IDF-driven control on negative augmentation.
Revisiting Self-Supervised Contrastive Learning for Facial Expression Recognition
Oct 08, 2022
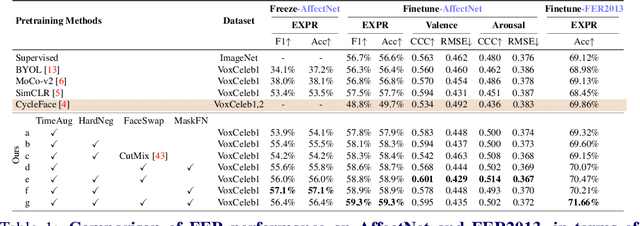


The success of most advanced facial expression recognition works relies heavily on large-scale annotated datasets. However, it poses great challenges in acquiring clean and consistent annotations for facial expression datasets. On the other hand, self-supervised contrastive learning has gained great popularity due to its simple yet effective instance discrimination training strategy, which can potentially circumvent the annotation issue. Nevertheless, there remain inherent disadvantages of instance-level discrimination, which are even more challenging when faced with complicated facial representations. In this paper, we revisit the use of self-supervised contrastive learning and explore three core strategies to enforce expression-specific representations and to minimize the interference from other facial attributes, such as identity and face styling. Experimental results show that our proposed method outperforms the current state-of-the-art self-supervised learning methods, in terms of both categorical and dimensional facial expression recognition tasks.