 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Predictive Memory in a Goal-Directed Agent
Mar 28, 2018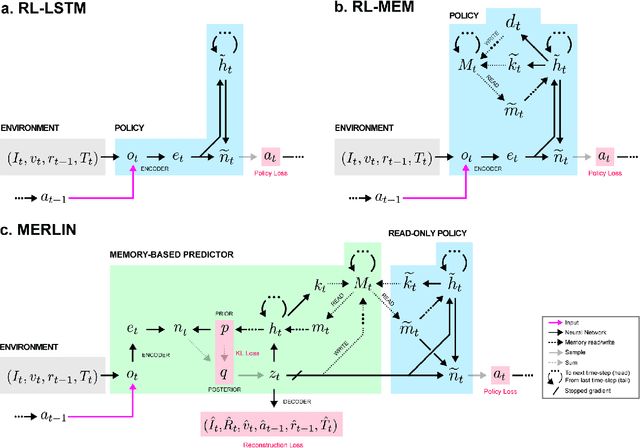
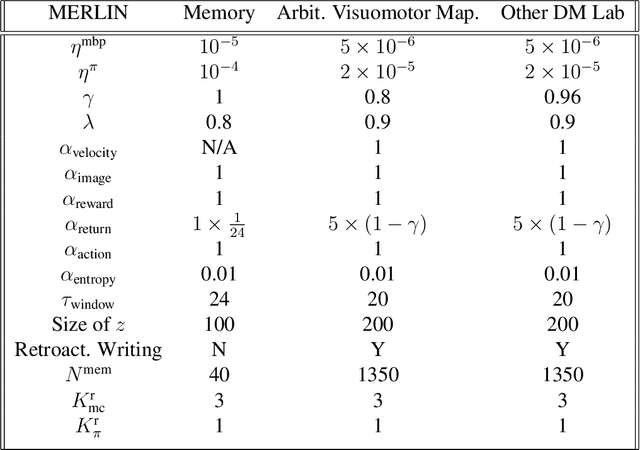
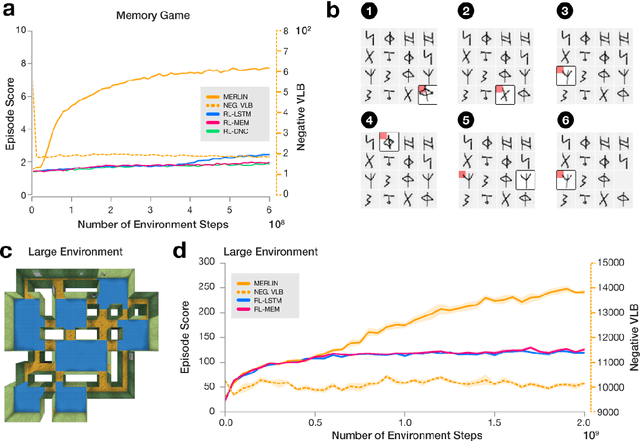

Animals execute goal-directed behaviours despite the limited range and scope of their sensors. To cope, they explore environments and store memories maintaining estimates of important information that is not presently available. Recently, progress has been made with artificial intelligence (AI) agents that learn to perform tasks from sensory input, even at a human level, by merging reinforcement learning (RL) algorithms with deep neural networks, and the excitement surrounding these results has led to the pursuit of related ideas as explanations of non-human animal learning. However, we demonstrate that contemporary RL algorithms struggle to solve simple tasks when enough information is concealed from the sensors of the agent, a property called "partial observability". An obvious requirement for handling partially observed tasks is access to extensive memory, but we show memory is not enough; it is critical that the right information be stored in the right format. We develop a model, the Memory, RL, and Inference Network (MERLIN), in which memory formation is guided by a process of predictive modeling. MERLIN facilitates the solution of tasks in 3D virtual reality environments for which partial observability is severe and memories must be maintained over long durations. Our model demonstrates a single learning agent architecture that can solve canonical behavioural tasks in psychology and neurobiology without strong simplifying assumptions about the dimensionality of sensory input or the duration of experiences.
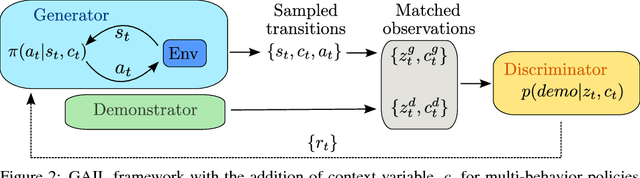
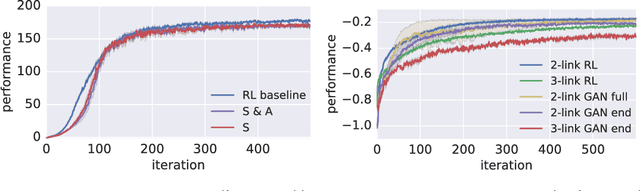
Robust Imitation of Diverse Behaviors
Jul 14, 2017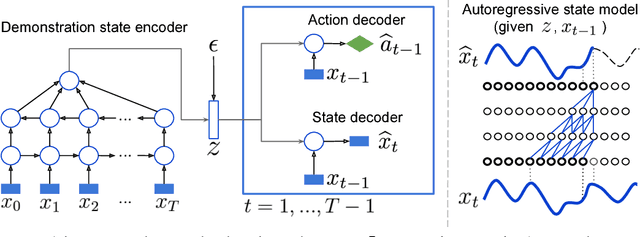
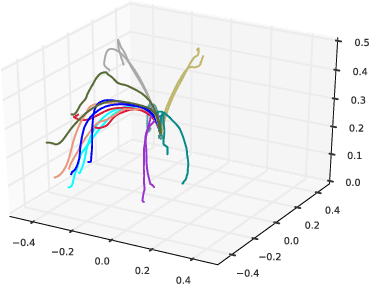
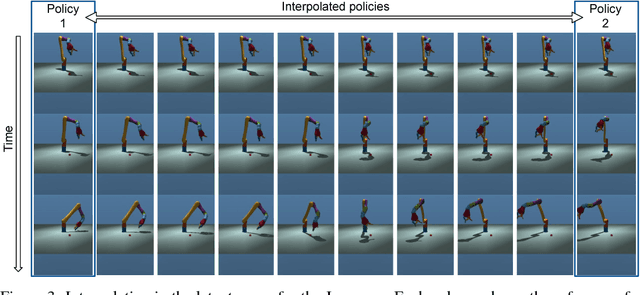
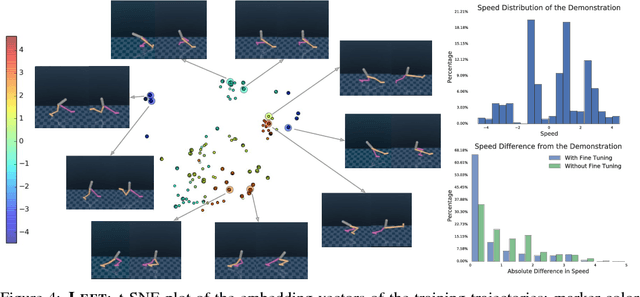
Deep generative models have recently shown great promise in imitation learning for motor control. Given enough data, even supervised approaches can do one-shot imitation learning; however, they are vulnerable to cascading failures when the agent trajectory diverges from the demonstrations. Compared to purely supervised methods, Generative Adversarial Imitation Learning (GAIL) can learn more robust controllers from fewer demonstrations, but is inherently mode-seeking and more difficult to train. In this paper, we show how to combine the favourable aspects of these two approaches. The base of our model is a new type of variational autoencoder on demonstration trajectories that learns semantic policy embeddings. We show that these embeddings can be learned on a 9 DoF Jaco robot arm in reaching tasks, and then smoothly interpolated with a resulting smooth interpolation of reaching behavior. Leveraging these policy representations, we develop a new version of GAIL that (1) is much more robust than the purely-supervised controller, especially with few demonstrations, and (2) avoids mode collapse, capturing many diverse behaviors when GAIL on its own does not. We demonstrate our approach on learning diverse gaits from demonstration on a 2D biped and a 62 DoF 3D humanoid in the MuJoCo physics environment.
Emergence of Locomotion Behaviours in Rich Environments
Jul 10, 2017
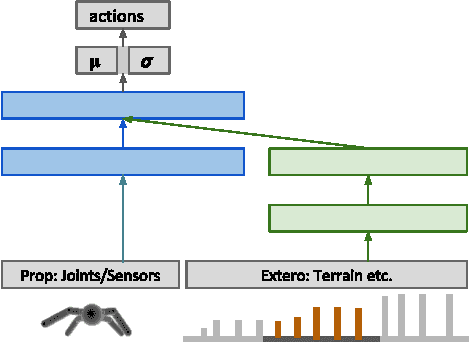


The reinforcement learning paradigm allows, in principle, for complex behaviours to be learned directly from simple reward signals. In practice, however, it is common to carefully hand-design the reward function to encourage a particular solution, or to derive it from demonstration data. In this paper explore how a rich environment can help to promote the learning of complex behavior. Specifically, we train agents in diverse environmental contexts, and find that this encourages the emergence of robust behaviours that perform well across a suite of tasks. We demonstrate this principle for locomotion -- behaviours that are known for their sensitivity to the choice of reward. We train several simulated bodies on a diverse set of challenging terrains and obstacles, using a simple reward function based on forward progress. Using a novel scalable variant of policy gradient reinforcement learning, our agents learn to run, jump, crouch and turn as required by the environment without explicit reward-based guidance. A visual depiction of highlights of the learned behavior can be viewed following https://youtu.be/hx_bgoTF7bs .
Learning human behaviors from motion capture by adversarial imitation
Jul 10, 2017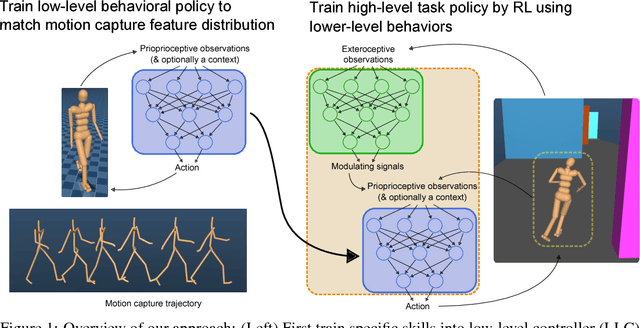
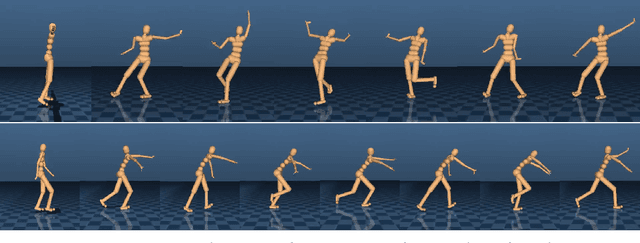
Rapid progress in deep reinforcement learning has made it increasingly feasible to train controllers for high-dimensional humanoid bodies. However, methods that use pure reinforcement learning with simple reward functions tend to produce non-humanlike and overly stereotyped movement behaviors. In this work, we extend generative adversarial imitation learning to enable training of generic neural network policies to produce humanlike movement patterns from limited demonstrations consisting only of partially observed state features, without access to actions, even when the demonstrations come from a body with different and unknown physical parameters. We leverage this approach to build sub-skill policies from motion capture data and show that they can be reused to solve tasks when controlled by a higher level controller.
Generative Temporal Models with Memory
Feb 21, 2017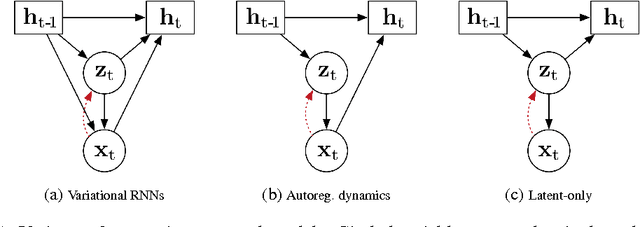

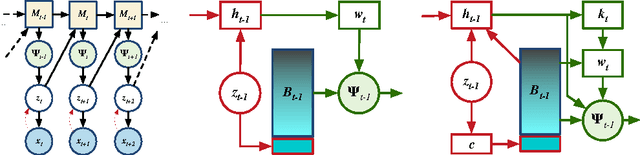

We consider the general problem of modeling temporal data with long-range dependencies, wherein new observations are fully or partially predictable based on temporally-distant, past observations. A sufficiently powerful temporal model should separate predictable elements of the sequence from unpredictable elements, express uncertainty about those unpredictable elements, and rapidly identify novel elements that may help to predict the future. To create such models, we introduce Generative Temporal Models augmented with external memory systems. They are developed within the variational inference framework, which provides both a practical training methodology and methods to gain insight into the models' operation. We show, on a range of problems with sparse, long-term temporal dependencies, that these models store information from early in a sequence, and reuse this stored information efficiently. This allows them to perform substantially better than existing models based on well-known recurrent neural networks, like LSTMs.
Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes
Oct 27, 2016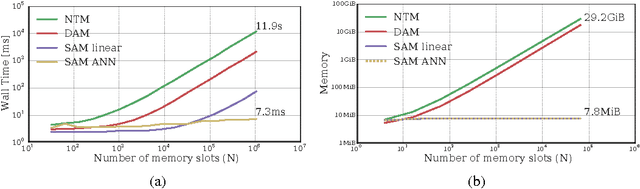
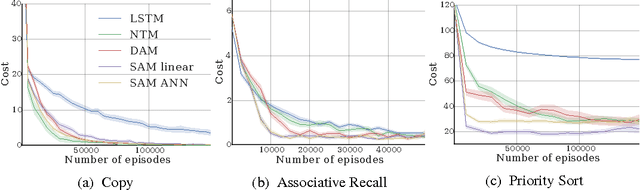
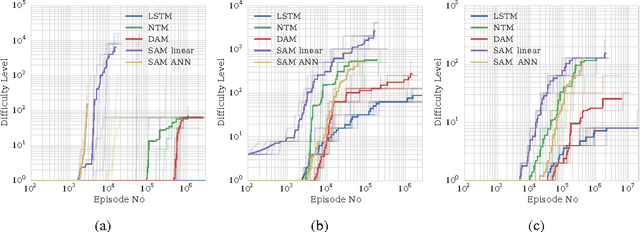
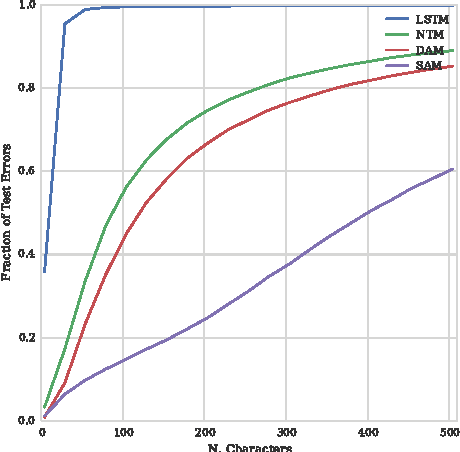
Neural networks augmented with external memory have the ability to learn algorithmic solutions to complex tasks. These models appear promising for applications such as language modeling and machine translation. However, they scale poorly in both space and time as the amount of memory grows --- limiting their applicability to real-world domains. Here, we present an end-to-end differentiable memory access scheme, which we call Sparse Access Memory (SAM), that retains the representational power of the original approaches whilst training efficiently with very large memories. We show that SAM achieves asymptotic lower bounds in space and time complexity, and find that an implementation runs $1,\!000\times$ faster and with $3,\!000\times$ less physical memory than non-sparse models. SAM learns with comparable data efficiency to existing models on a range of synthetic tasks and one-shot Omniglot character recognition, and can scale to tasks requiring $100,\!000$s of time steps and memories. As well, we show how our approach can be adapted for models that maintain temporal associations between memories, as with the recently introduced Differentiable Neural Computer.
Learning and Transfer of Modulated Locomotor Controllers
Oct 17, 2016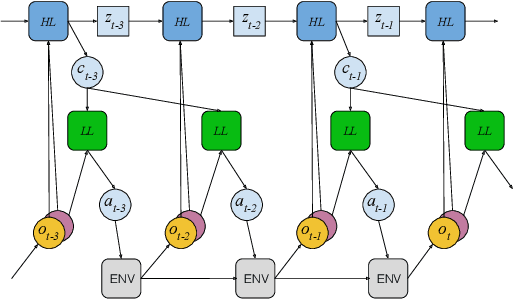


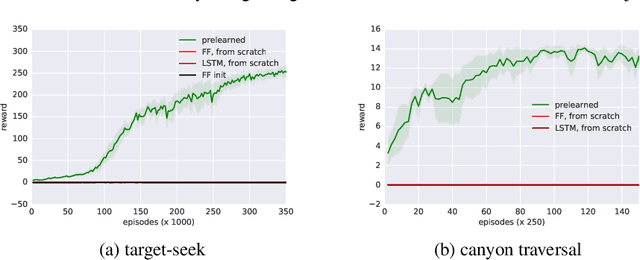
We study a novel architecture and training procedure for locomotion tasks. A high-frequency, low-level "spinal" network with access to proprioceptive sensors learns sensorimotor primitives by training on simple tasks. This pre-trained module is fixed and connected to a low-frequency, high-level "cortical" network, with access to all sensors, which drives behavior by modulating the inputs to the spinal network. Where a monolithic end-to-end architecture fails completely, learning with a pre-trained spinal module succeeds at multiple high-level tasks, and enables the effective exploration required to learn from sparse rewards. We test our proposed architecture on three simulated bodies: a 16-dimensional swimming snake, a 20-dimensional quadruped, and a 54-dimensional humanoid. Our results are illustrated in the accompanying video at https://youtu.be/sboPYvhpraQ
Associative Long Short-Term Memory
May 19, 2016
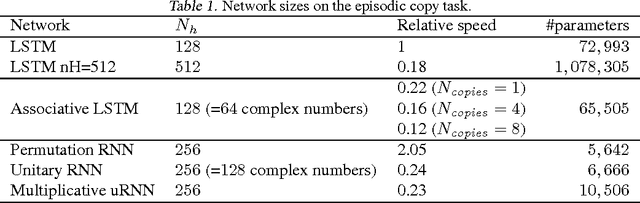


We investigate a new method to augment recurrent neural networks with extra memory without increasing the number of network parameters. The system has an associative memory based on complex-valued vectors and is closely related to Holographic Reduced Representations and Long Short-Term Memory networks. Holographic Reduced Representations have limited capacity: as they store more information, each retrieval becomes noisier due to interference. Our system in contrast creates redundant copies of stored information, which enables retrieval with reduced noise. Experiments demonstrate faster learning on multiple memorization tasks.
Learning Continuous Control Policies by Stochastic Value Gradients
Oct 30, 2015
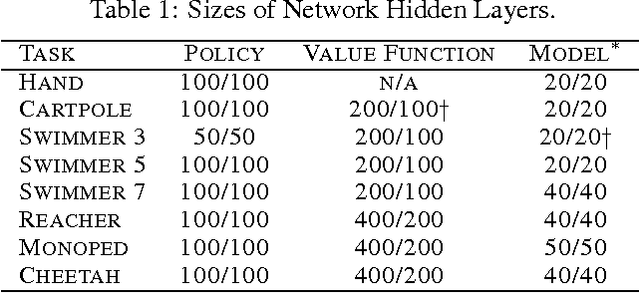
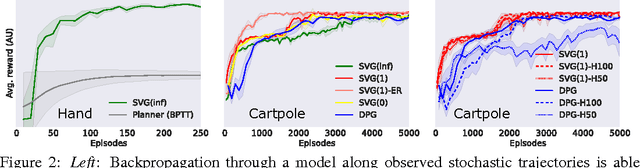
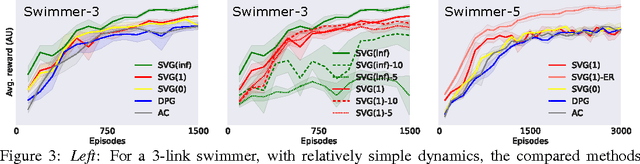
We present a unified framework for learning continuous control policies using backpropagation. It supports stochastic control by treating stochasticity in the Bellman equation as a deterministic function of exogenous noise. The product is a spectrum of general policy gradient algorithms that range from model-free methods with value functions to model-based methods without value functions. We use learned models but only require observations from the environment in- stead of observations from model-predicted trajectories, minimizing the impact of compounded model errors. We apply these algorithms first to a toy stochastic control problem and then to several physics-based control problems in simulation. One of these variants, SVG(1), shows the effectiveness of learning models, value functions, and policies simultaneously in continuous domains.
Neural Turing Machines
Dec 10, 2014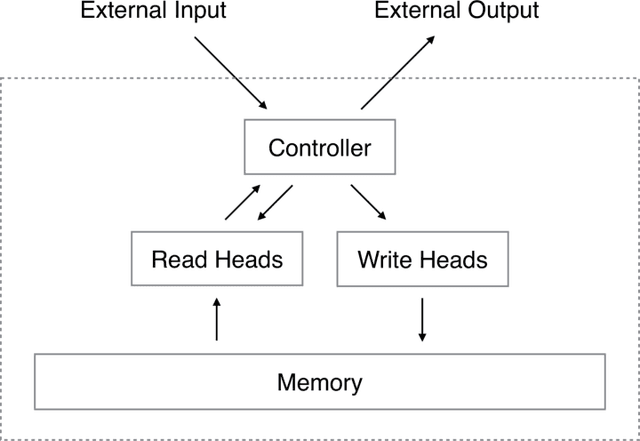
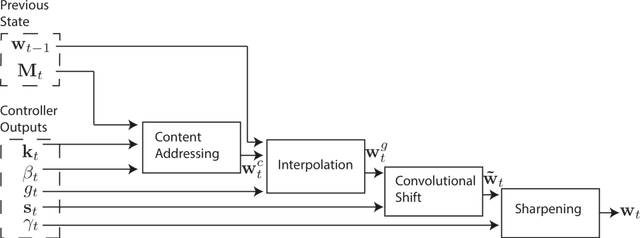
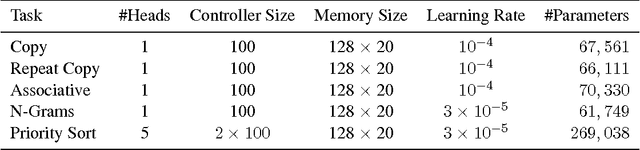
We extend the capabilities of neural networks by coupling them to external memory resources, which they can interact with by attentional processes. The combined system is analogous to a Turing Machine or Von Neumann architecture but is differentiable end-to-end, allowing it to be efficiently trained with gradient descent. Preliminary results demonstrate that Neural Turing Machines can infer simple algorithms such as copying, sorting, and associative recall from input and output examples.