 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterval timing in deep reinforcement learning agents
May 31, 2019
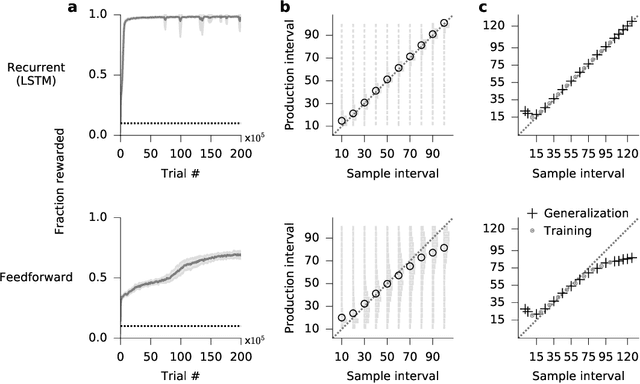
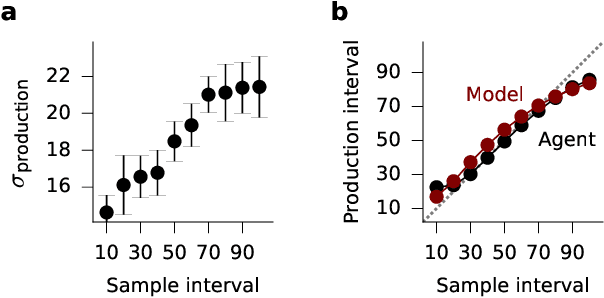
The measurement of time is central to intelligent behavior. We know that both animals and artificial agents can successfully use temporal dependencies to select actions. In artificial agents, little work has directly addressed (1) which architectural components are necessary for successful development of this ability, (2) how this timing ability comes to be represented in the units and actions of the agent, and (3) whether the resulting behavior of the system converges on solutions similar to those of biology. Here we studied interval timing abilities in deep reinforcement learning agents trained end-to-end on an interval reproduction paradigm inspired by experimental literature on mechanisms of timing. We characterize the strategies developed by recurrent and feedforward agents, which both succeed at temporal reproduction using distinct mechanisms, some of which bear specific and intriguing similarities to biological systems. These findings advance our understanding of how agents come to represent time, and they highlight the value of experimentally inspired approaches to characterizing agent abilities.
Exploiting Hierarchy for Learning and Transfer in KL-regularized RL
Mar 18, 2019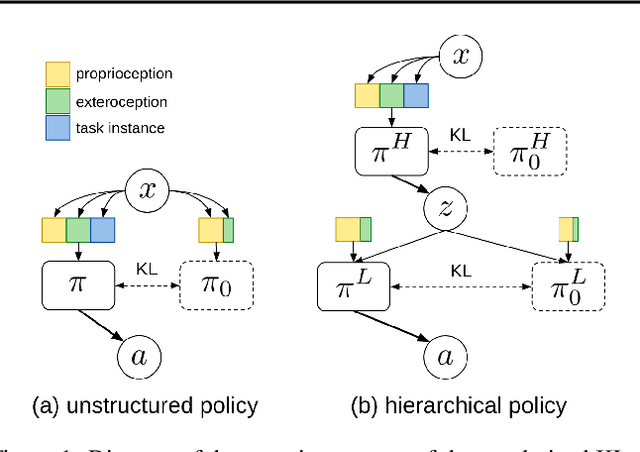

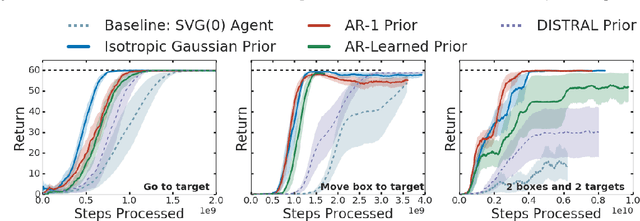
As reinforcement learning agents are tasked with solving more challenging and diverse tasks, the ability to incorporate prior knowledge into the learning system and to exploit reusable structure in solution space is likely to become increasingly important. The KL-regularized expected reward objective constitutes one possible tool to this end. It introduces an additional component, a default or prior behavior, which can be learned alongside the policy and as such partially transforms the reinforcement learning problem into one of behavior modelling. In this work we consider the implications of this framework in cases where both the policy and default behavior are augmented with latent variables. We discuss how the resulting hierarchical structures can be used to implement different inductive biases and how their modularity can benefit transfer. Empirically we find that they can lead to faster learning and transfer on a range of continuous control tasks.
Neural probabilistic motor primitives for humanoid control
Jan 15, 2019
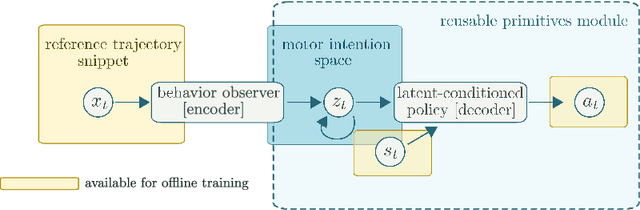
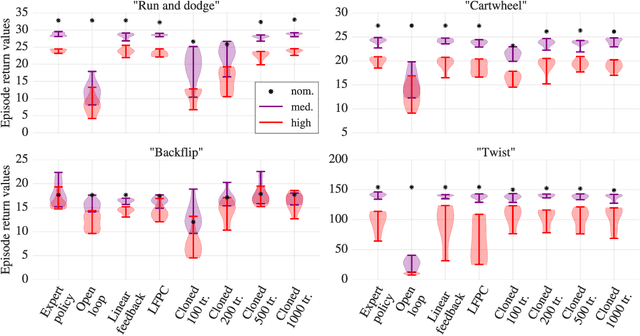
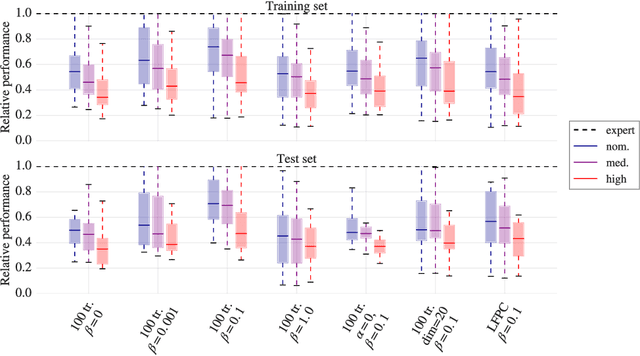
We focus on the problem of learning a single motor module that can flexibly express a range of behaviors for the control of high-dimensional physically simulated humanoids. To do this, we propose a motor architecture that has the general structure of an inverse model with a latent-variable bottleneck. We show that it is possible to train this model entirely offline to compress thousands of expert policies and learn a motor primitive embedding space. The trained neural probabilistic motor primitive system can perform one-shot imitation of whole-body humanoid behaviors, robustly mimicking unseen trajectories. Additionally, we demonstrate that it is also straightforward to train controllers to reuse the learned motor primitive space to solve tasks, and the resulting movements are relatively naturalistic. To support the training of our model, we compare two approaches for offline policy cloning, including an experience efficient method which we call linear feedback policy cloning. We encourage readers to view a supplementary video ( https://youtu.be/CaDEf-QcKwA ) summarizing our results.
Hierarchical visuomotor control of humanoids
Jan 15, 2019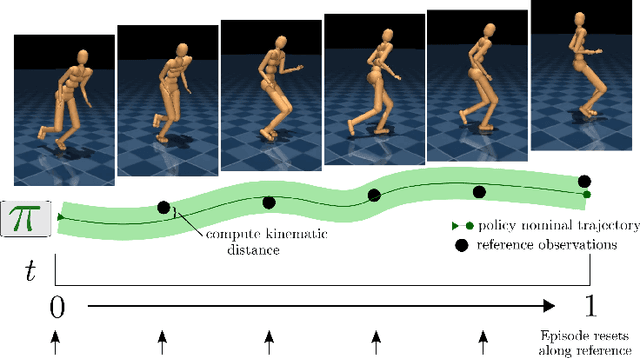

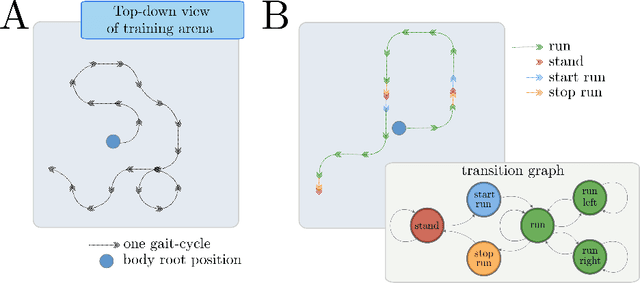

We aim to build complex humanoid agents that integrate perception, motor control, and memory. In this work, we partly factor this problem into low-level motor control from proprioception and high-level coordination of the low-level skills informed by vision. We develop an architecture capable of surprisingly flexible, task-directed motor control of a relatively high-DoF humanoid body by combining pre-training of low-level motor controllers with a high-level, task-focused controller that switches among low-level sub-policies. The resulting system is able to control a physically-simulated humanoid body to solve tasks that require coupling visual perception from an unstabilized egocentric RGB camera during locomotion in the environment. For a supplementary video link, see https://youtu.be/7GISvfbykLE .
An investigation of model-free planning
Jan 11, 2019
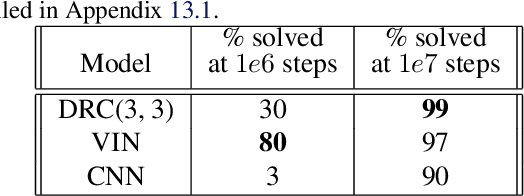
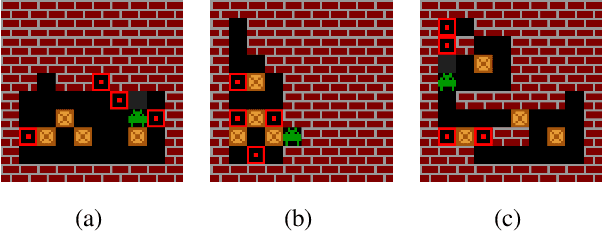
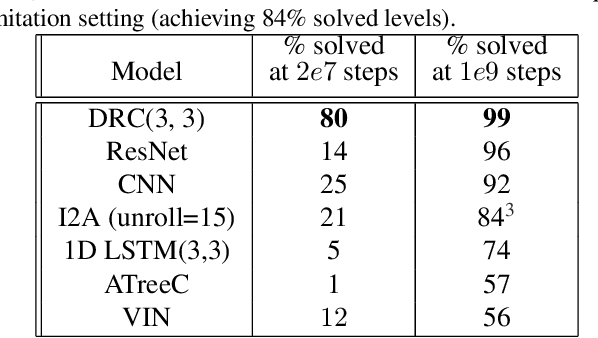
The field of reinforcement learning (RL) is facing increasingly challenging domains with combinatorial complexity. For an RL agent to address these challenges, it is essential that it can plan effectively. Prior work has typically utilized an explicit model of the environment, combined with a specific planning algorithm (such as tree search). More recently, a new family of methods have been proposed that learn how to plan, by providing the structure for planning via an inductive bias in the function approximator (such as a tree structured neural network), trained end-to-end by a model-free RL algorithm. In this paper, we go even further, and demonstrate empirically that an entirely model-free approach, without special structure beyond standard neural network components such as convolutional networks and LSTMs, can learn to exhibit many of the characteristics typically associated with a model-based planner. We measure our agent's effectiveness at planning in terms of its ability to generalize across a combinatorial and irreversible state space, its data efficiency, and its ability to utilize additional thinking time. We find that our agent has many of the characteristics that one might expect to find in a planning algorithm. Furthermore, it exceeds the state-of-the-art in challenging combinatorial domains such as Sokoban and outperforms other model-free approaches that utilize strong inductive biases toward planning.
Experience Replay for Continual Learning
Nov 28, 2018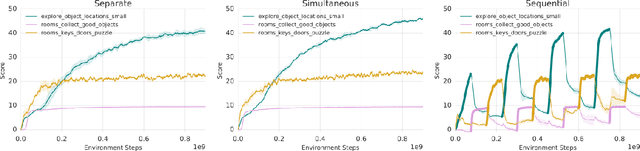
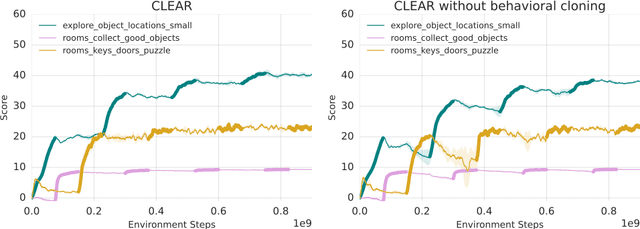
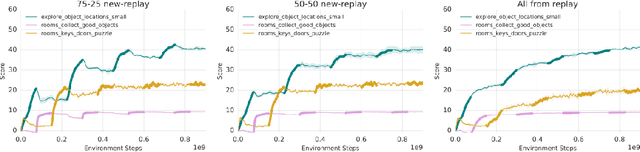
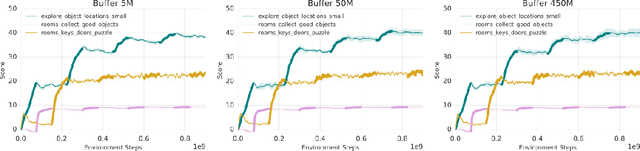
Continual learning is the problem of learning new tasks or knowledge while protecting old knowledge and ideally generalizing from old experience to learn new tasks faster. Neural networks trained by stochastic gradient descent often degrade on old tasks when trained successively on new tasks with different data distributions. This phenomenon, referred to as catastrophic forgetting, is considered a major hurdle to learning with non-stationary data or sequences of new tasks, and prevents networks from continually accumulating knowledge and skills. We examine this issue in the context of reinforcement learning, in a setting where an agent is exposed to tasks in a sequence. Unlike most other work, we do not provide an explicit indication to the model of task boundaries, which is the most general circumstance for a learning agent exposed to continuous experience. While various methods to counteract catastrophic forgetting have recently been proposed, we explore a straightforward, general, and seemingly overlooked solution - that of using experience replay buffers for all past events - with a mixture of on- and off-policy learning, leveraging behavioral cloning. We show that this strategy can still learn new tasks quickly yet can substantially reduce catastrophic forgetting in both Atari and DMLab domains, even matching the performance of methods that require task identities. When buffer storage is constrained, we confirm that a simple mechanism for randomly discarding data allows a limited size buffer to perform almost as well as an unbounded one.
Learning Attractor Dynamics for Generative Memory
Nov 23, 2018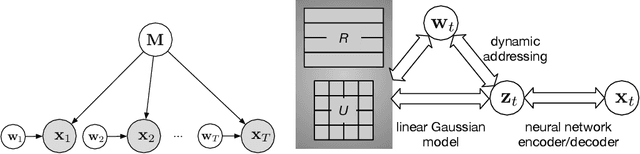
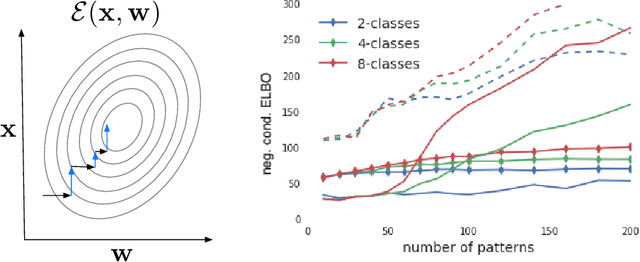


A central challenge faced by memory systems is the robust retrieval of a stored pattern in the presence of interference due to other stored patterns and noise. A theoretically well-founded solution to robust retrieval is given by attractor dynamics, which iteratively clean up patterns during recall. However, incorporating attractor dynamics into modern deep learning systems poses difficulties: attractor basins are characterised by vanishing gradients, which are known to make training neural networks difficult. In this work, we avoid the vanishing gradient problem by training a generative distributed memory without simulating the attractor dynamics. Based on the idea of memory writing as inference, as proposed in the Kanerva Machine, we show that a likelihood-based Lyapunov function emerges from maximising the variational lower-bound of a generative memory. Experiments shows it converges to correct patterns upon iterative retrieval and achieves competitive performance as both a memory model and a generative model.
Optimizing Agent Behavior over Long Time Scales by Transporting Value
Oct 15, 2018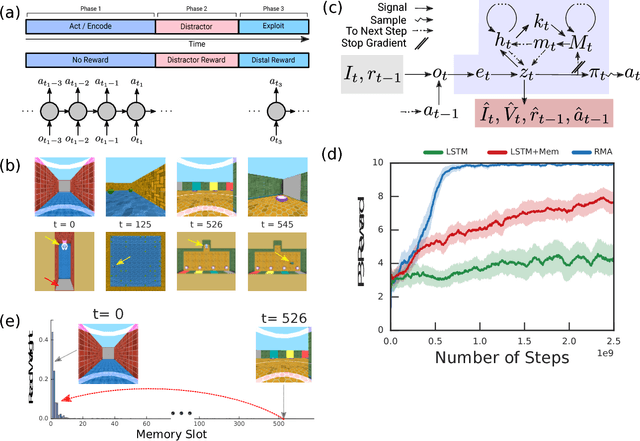
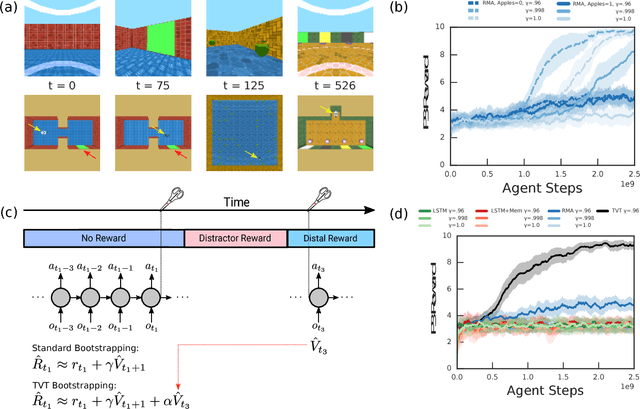
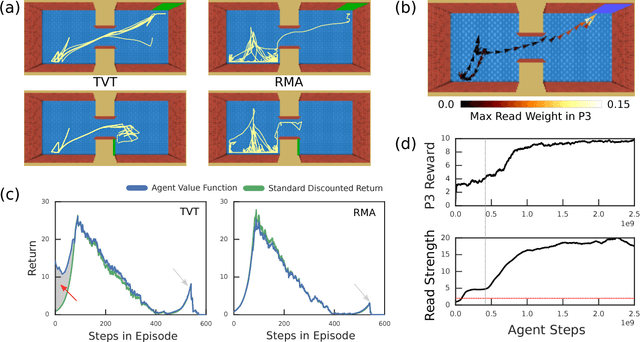
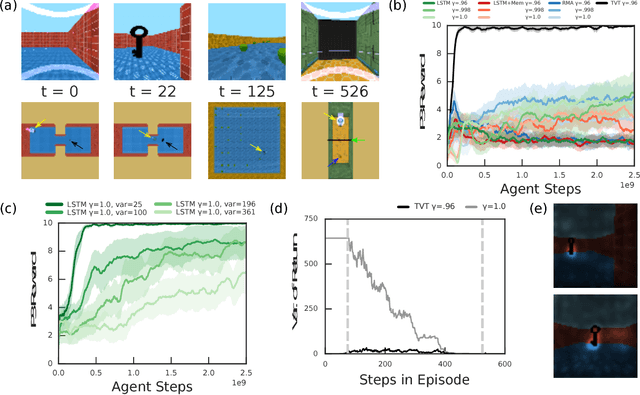
Humans spend a remarkable fraction of waking life engaged in acts of "mental time travel". We dwell on our actions in the past and experience satisfaction or regret. More than merely autobiographical storytelling, we use these event recollections to change how we will act in similar scenarios in the future. This process endows us with a computationally important ability to link actions and consequences across long spans of time, which figures prominently in addressing the problem of long-term temporal credit assignment; in artificial intelligence (AI) this is the question of how to evaluate the utility of the actions within a long-duration behavioral sequence leading to success or failure in a task. Existing approaches to shorter-term credit assignment in AI cannot solve tasks with long delays between actions and consequences. Here, we introduce a new paradigm for reinforcement learning where agents use recall of specific memories to credit actions from the past, allowing them to solve problems that are intractable for existing algorithms. This paradigm broadens the scope of problems that can be investigated in AI and offers a mechanistic account of behaviors that may inspire computational models in neuroscience, psychology, and behavioral economics.
The Kanerva Machine: A Generative Distributed Memory
Jun 18, 2018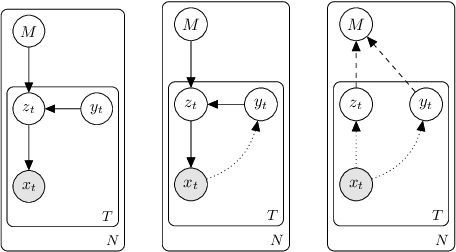
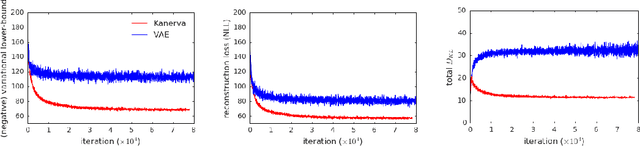

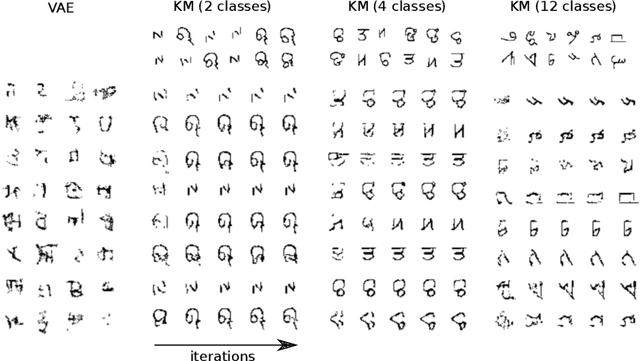
We present an end-to-end trained memory system that quickly adapts to new data and generates samples like them. Inspired by Kanerva's sparse distributed memory, it has a robust distributed reading and writing mechanism. The memory is analytically tractable, which enables optimal on-line compression via a Bayesian update-rule. We formulate it as a hierarchical conditional generative model, where memory provides a rich data-dependent prior distribution. Consequently, the top-down memory and bottom-up perception are combined to produce the code representing an observation. Empirically, we demonstrate that the adaptive memory significantly improves generative models trained on both the Omniglot and CIFAR datasets. Compared with the Differentiable Neural Computer (DNC) and its variants, our memory model has greater capacity and is significantly easier to train.
Probing Physics Knowledge Using Tools from Developmental Psychology
Apr 03, 2018


In order to build agents with a rich understanding of their environment, one key objective is to endow them with a grasp of intuitive physics; an ability to reason about three-dimensional objects, their dynamic interactions, and responses to forces. While some work on this problem has taken the approach of building in components such as ready-made physics engines, other research aims to extract general physical concepts directly from sensory data. In the latter case, one challenge that arises is evaluating the learning system. Research on intuitive physics knowledge in children has long employed a violation of expectations (VOE) method to assess children's mastery of specific physical concepts. We take the novel step of applying this method to artificial learning systems. In addition to introducing the VOE technique, we describe a set of probe datasets inspired by classic test stimuli from developmental psychology. We test a baseline deep learning system on this battery, as well as on a physics learning dataset ("IntPhys") recently posed by another research group. Our results show how the VOE technique may provide a useful tool for tracking physics knowledge in future research.