 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Errors: Leveraging Large Language Models for Fine-grained Machine Translation Evaluation
Aug 14, 2023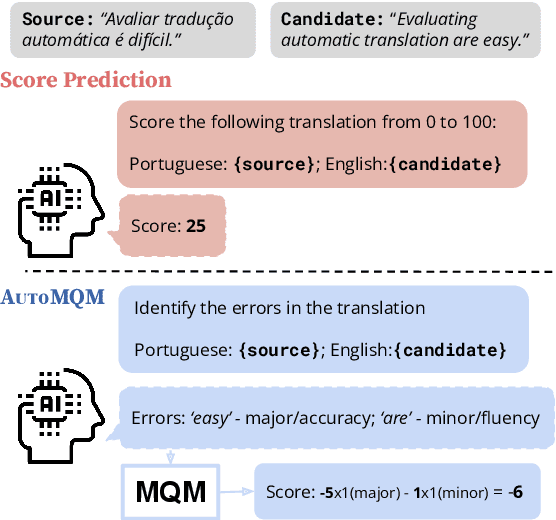

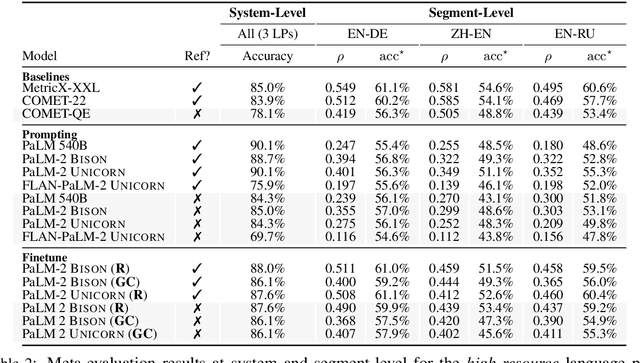
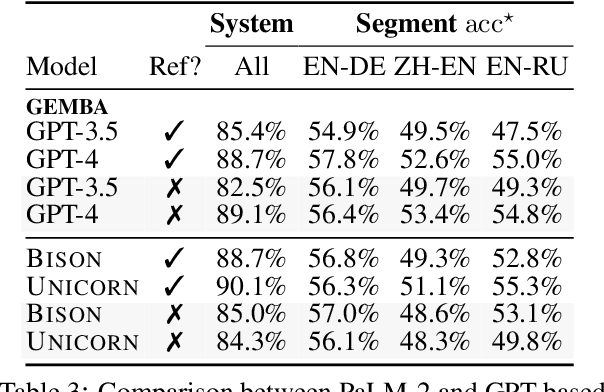
Automatic evaluation of machine translation (MT) is a critical tool driving the rapid iterative development of MT systems. While considerable progress has been made on estimating a single scalar quality score, current metrics lack the informativeness of more detailed schemes that annotate individual errors, such as Multidimensional Quality Metrics (MQM). In this paper, we help fill this gap by proposing AutoMQM, a prompting technique which leverages the reasoning and in-context learning capabilities of large language models (LLMs) and asks them to identify and categorize errors in translations. We start by evaluating recent LLMs, such as PaLM and PaLM-2, through simple score prediction prompting, and we study the impact of labeled data through in-context learning and finetuning. We then evaluate AutoMQM with PaLM-2 models, and we find that it improves performance compared to just prompting for scores (with particularly large gains for larger models) while providing interpretability through error spans that align with human annotations.
FacTool: Factuality Detection in Generative AI -- A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios
Jul 26, 2023



The emergence of generative pre-trained models has facilitated the synthesis of high-quality text, but it has also posed challenges in identifying factual errors in the generated text. In particular: (1) A wider range of tasks now face an increasing risk of containing factual errors when handled by generative models. (2) Generated texts tend to be lengthy and lack a clearly defined granularity for individual facts. (3) There is a scarcity of explicit evidence available during the process of fact checking. With the above challenges in mind, in this paper, we propose FacTool, a task and domain agnostic framework for detecting factual errors of texts generated by large language models (e.g., ChatGPT). Experiments on four different tasks (knowledge-based QA, code generation, mathematical reasoning, and scientific literature review) show the efficacy of the proposed method. We release the code of FacTool associated with ChatGPT plugin interface at https://github.com/GAIR-NLP/factool .
WebArena: A Realistic Web Environment for Building Autonomous Agents
Jul 25, 2023



With generative AI advances, the exciting potential for autonomous agents to manage daily tasks via natural language commands has emerged. However, cur rent agents are primarily created and tested in simplified synthetic environments, substantially limiting real-world scenario representation. In this paper, we build an environment for agent command and control that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on websites, and we create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and are designed to emulate tasks that humans routinely perform on the internet. We design and implement several autonomous agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 10.59%. These results highlight the need for further development of robust agents, that current state-of-the-art LMs are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress. Our code, data, environment reproduction resources, and video demonstrations are publicly available at https://webarena.dev/.
Improving Factuality of Abstractive Summarization via Contrastive Reward Learning
Jul 10, 2023Modern abstractive summarization models often generate summaries that contain hallucinated or contradictory information. In this paper, we propose a simple but effective contrastive learning framework that incorporates recent developments in reward learning and factuality metrics. Empirical studies demonstrate that the proposed framework enables summarization models to learn from feedback of factuality metrics using contrastive reward learning, leading to more factual summaries by human evaluations. This suggests that further advances in learning and evaluation algorithms can feed directly into providing more factual summaries.
Large Language Models Enable Few-Shot Clustering
Jul 02, 2023Unlike traditional unsupervised clustering, semi-supervised clustering allows users to provide meaningful structure to the data, which helps the clustering algorithm to match the user's intent. Existing approaches to semi-supervised clustering require a significant amount of feedback from an expert to improve the clusters. In this paper, we ask whether a large language model can amplify an expert's guidance to enable query-efficient, few-shot semi-supervised text clustering. We show that LLMs are surprisingly effective at improving clustering. We explore three stages where LLMs can be incorporated into clustering: before clustering (improving input features), during clustering (by providing constraints to the clusterer), and after clustering (using LLMs post-correction). We find incorporating LLMs in the first two stages can routinely provide significant improvements in cluster quality, and that LLMs enable a user to make trade-offs between cost and accuracy to produce desired clusters. We release our code and LLM prompts for the public to use.
Neural Machine Translation for the Indigenous Languages of the Americas: An Introduction
Jun 11, 2023Neural models have drastically advanced state of the art for machine translation (MT) between high-resource languages. Traditionally, these models rely on large amounts of training data, but many language pairs lack these resources. However, an important part of the languages in the world do not have this amount of data. Most languages from the Americas are among them, having a limited amount of parallel and monolingual data, if any. Here, we present an introduction to the interested reader to the basic challenges, concepts, and techniques that involve the creation of MT systems for these languages. Finally, we discuss the recent advances and findings and open questions, product of an increased interest of the NLP community in these languages.
DataFinder: Scientific Dataset Recommendation from Natural Language Descriptions
Jun 07, 2023



Modern machine learning relies on datasets to develop and validate research ideas. Given the growth of publicly available data, finding the right dataset to use is increasingly difficult. Any research question imposes explicit and implicit constraints on how well a given dataset will enable researchers to answer this question, such as dataset size, modality, and domain. We operationalize the task of recommending datasets given a short natural language description of a research idea, to help people find relevant datasets for their needs. Dataset recommendation poses unique challenges as an information retrieval problem; datasets are hard to directly index for search and there are no corpora readily available for this task. To facilitate this task, we build the DataFinder Dataset which consists of a larger automatically-constructed training set (17.5K queries) and a smaller expert-annotated evaluation set (392 queries). Using this data, we compare various information retrieval algorithms on our test set and present a superior bi-encoder retriever for text-based dataset recommendation. This system, trained on the DataFinder Dataset, finds more relevant search results than existing third-party dataset search engines. To encourage progress on dataset recommendation, we release our dataset and models to the public.
Multi-Dimensional Evaluation of Text Summarization with In-Context Learning
Jun 01, 2023



Evaluation of natural language generation (NLG) is complex and multi-dimensional. Generated text can be evaluated for fluency, coherence, factuality, or any other dimensions of interest. Most frameworks that perform such multi-dimensional evaluation require training on large manually or synthetically generated datasets. In this paper, we study the efficacy of large language models as multi-dimensional evaluators using in-context learning, obviating the need for large training datasets. Our experiments show that in-context learning-based evaluators are competitive with learned evaluation frameworks for the task of text summarization, establishing state-of-the-art on dimensions such as relevance and factual consistency. We then analyze the effects of factors such as the selection and number of in-context examples on performance. Finally, we study the efficacy of in-context learning based evaluators in evaluating zero-shot summaries written by large language models such as GPT-3.
Syntax and Semantics Meet in the "Middle": Probing the Syntax-Semantics Interface of LMs Through Agentivity
May 29, 2023



Recent advances in large language models have prompted researchers to examine their abilities across a variety of linguistic tasks, but little has been done to investigate how models handle the interactions in meaning across words and larger syntactic forms -- i.e. phenomena at the intersection of syntax and semantics. We present the semantic notion of agentivity as a case study for probing such interactions. We created a novel evaluation dataset by utilitizing the unique linguistic properties of a subset of optionally transitive English verbs. This dataset was used to prompt varying sizes of three model classes to see if they are sensitive to agentivity at the lexical level, and if they can appropriately employ these word-level priors given a specific syntactic context. Overall, GPT-3 text-davinci-003 performs extremely well across all experiments, outperforming all other models tested by far. In fact, the results are even better correlated with human judgements than both syntactic and semantic corpus statistics. This suggests that LMs may potentially serve as more useful tools for linguistic annotation, theory testing, and discovery than select corpora for certain tasks.
Multi-lingual and Multi-cultural Figurative Language Understanding
May 25, 2023Figurative language permeates human communication, but at the same time is relatively understudied in NLP. Datasets have been created in English to accelerate progress towards measuring and improving figurative language processing in language models (LMs). However, the use of figurative language is an expression of our cultural and societal experiences, making it difficult for these phrases to be universally applicable. In this work, we create a figurative language inference dataset, \datasetname, for seven diverse languages associated with a variety of cultures: Hindi, Indonesian, Javanese, Kannada, Sundanese, Swahili and Yoruba. Our dataset reveals that each language relies on cultural and regional concepts for figurative expressions, with the highest overlap between languages originating from the same region. We assess multilingual LMs' abilities to interpret figurative language in zero-shot and few-shot settings. All languages exhibit a significant deficiency compared to English, with variations in performance reflecting the availability of pre-training and fine-tuning data, emphasizing the need for LMs to be exposed to a broader range of linguistic and cultural variation during training.