 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Dependent Local Entropy Models for Learned Image Compression
May 31, 2018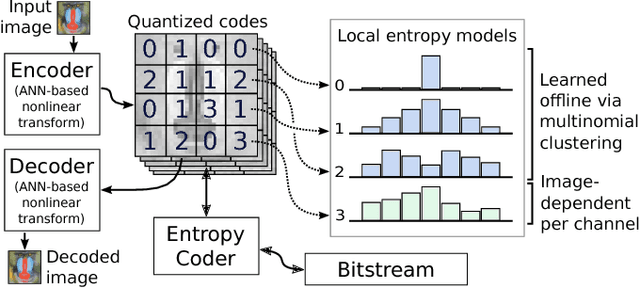

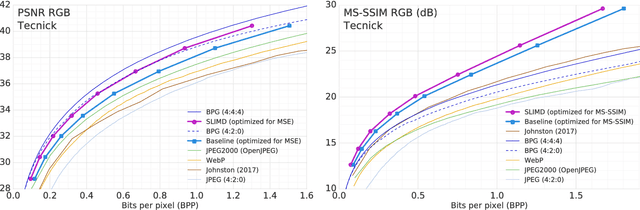
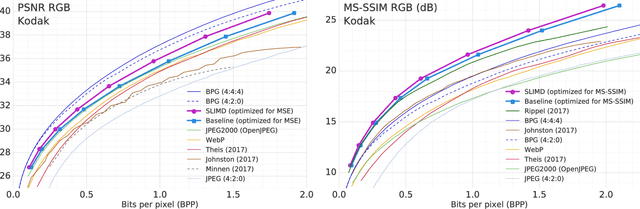
The leading approach for image compression with artificial neural networks (ANNs) is to learn a nonlinear transform and a fixed entropy model that are optimized for rate-distortion performance. We show that this approach can be significantly improved by incorporating spatially local, image-dependent entropy models. The key insight is that existing ANN-based methods learn an entropy model that is shared between the encoder and decoder, but they do not transmit any side information that would allow the model to adapt to the structure of a specific image. We present a method for augmenting ANN-based image coders with image-dependent side information that leads to a 17.8% rate reduction over a state-of-the-art ANN-based baseline model on a standard evaluation set, and 70-98% reductions on images with low visual complexity that are poorly captured by a fixed, global entropy model.
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Apr 30, 2018


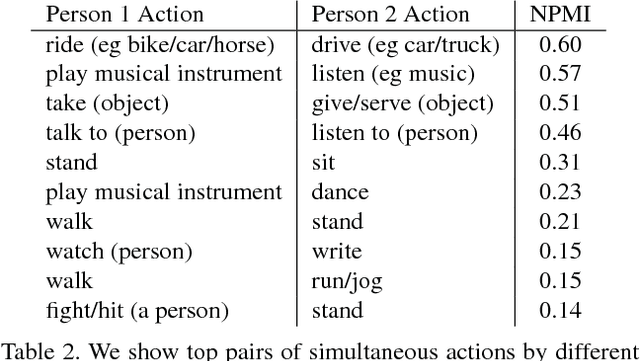
This paper introduces a video dataset of spatio-temporally localized Atomic Visual Actions (AVA). The AVA dataset densely annotates 80 atomic visual actions in 430 15-minute video clips, where actions are localized in space and time, resulting in 1.58M action labels with multiple labels per person occurring frequently. The key characteristics of our dataset are: (1) the definition of atomic visual actions, rather than composite actions; (2) precise spatio-temporal annotations with possibly multiple annotations for each person; (3) exhaustive annotation of these atomic actions over 15-minute video clips; (4) people temporally linked across consecutive segments; and (5) using movies to gather a varied set of action representations. This departs from existing datasets for spatio-temporal action recognition, which typically provide sparse annotations for composite actions in short video clips. We will release the dataset publicly. AVA, with its realistic scene and action complexity, exposes the intrinsic difficulty of action recognition. To benchmark this, we present a novel approach for action localization that builds upon the current state-of-the-art methods, and demonstrates better performance on JHMDB and UCF101-24 categories. While setting a new state of the art on existing datasets, the overall results on AVA are low at 15.6% mAP, underscoring the need for developing new approaches for video understanding.
Spatially adaptive image compression using a tiled deep network
Feb 07, 2018
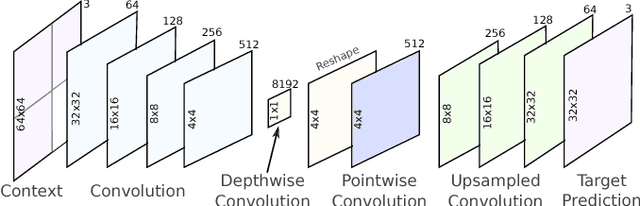

Deep neural networks represent a powerful class of function approximators that can learn to compress and reconstruct images. Existing image compression algorithms based on neural networks learn quantized representations with a constant spatial bit rate across each image. While entropy coding introduces some spatial variation, traditional codecs have benefited significantly by explicitly adapting the bit rate based on local image complexity and visual saliency. This paper introduces an algorithm that combines deep neural networks with quality-sensitive bit rate adaptation using a tiled network. We demonstrate the importance of spatial context prediction and show improved quantitative (PSNR) and qualitative (subjective rater assessment) results compared to a non-adaptive baseline and a recently published image compression model based on fully-convolutional neural networks.
Full Resolution Image Compression with Recurrent Neural Networks
Jul 07, 2017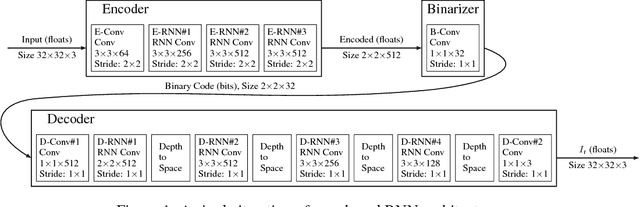
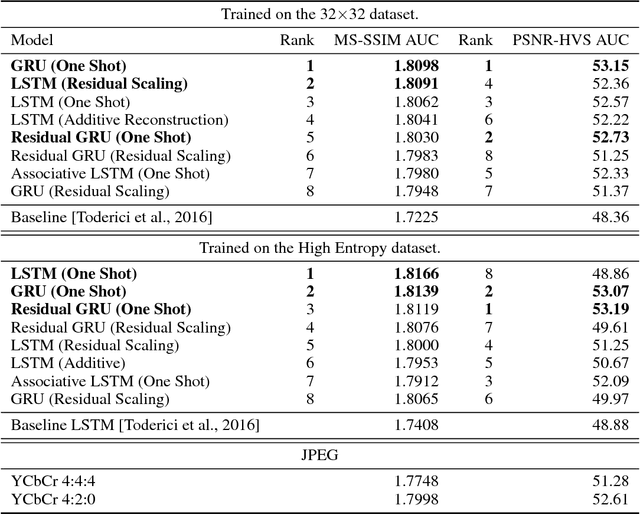
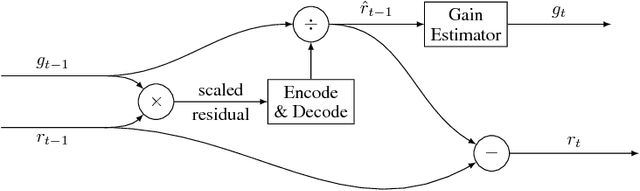
This paper presents a set of full-resolution lossy image compression methods based on neural networks. Each of the architectures we describe can provide variable compression rates during deployment without requiring retraining of the network: each network need only be trained once. All of our architectures consist of a recurrent neural network (RNN)-based encoder and decoder, a binarizer, and a neural network for entropy coding. We compare RNN types (LSTM, associative LSTM) and introduce a new hybrid of GRU and ResNet. We also study "one-shot" versus additive reconstruction architectures and introduce a new scaled-additive framework. We compare to previous work, showing improvements of 4.3%-8.8% AUC (area under the rate-distortion curve), depending on the perceptual metric used. As far as we know, this is the first neural network architecture that is able to outperform JPEG at image compression across most bitrates on the rate-distortion curve on the Kodak dataset images, with and without the aid of entropy coding.
Target-Quality Image Compression with Recurrent, Convolutional Neural Networks
May 18, 2017
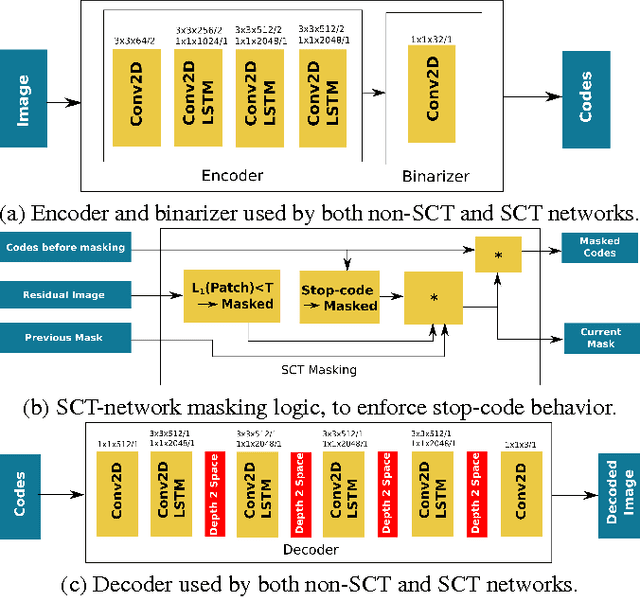
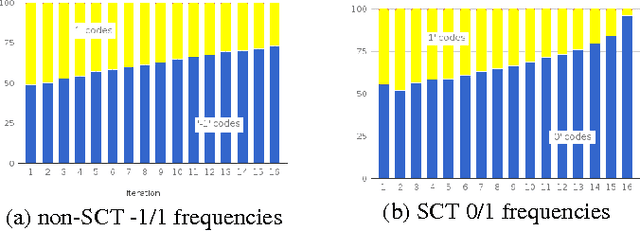

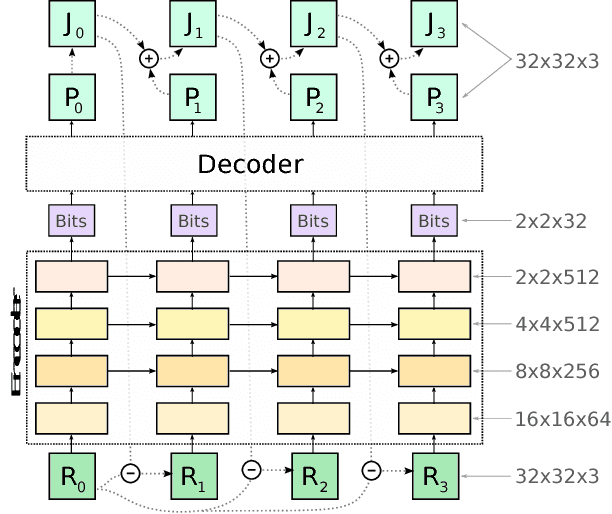
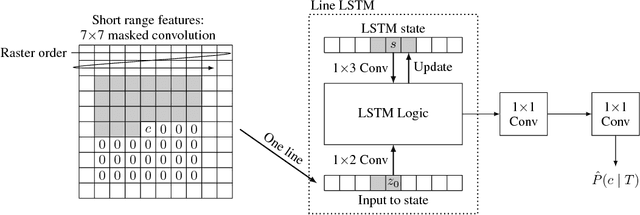
We introduce a stop-code tolerant (SCT) approach to training recurrent convolutional neural networks for lossy image compression. Our methods introduce a multi-pass training method to combine the training goals of high-quality reconstructions in areas around stop-code masking as well as in highly-detailed areas. These methods lead to lower true bitrates for a given recursion count, both pre- and post-entropy coding, even using unstructured LZ77 code compression. The pre-LZ77 gains are achieved by trimming stop codes. The post-LZ77 gains are due to the highly unequal distributions of 0/1 codes from the SCT architectures. With these code compressions, the SCT architecture maintains or exceeds the image quality at all compression rates compared to JPEG and to RNN auto-encoders across the Kodak dataset. In addition, the SCT coding results in lower variance in image quality across the extent of the image, a characteristic that has been shown to be important in human ratings of image quality
Improved Lossy Image Compression with Priming and Spatially Adaptive Bit Rates for Recurrent Networks
Mar 29, 2017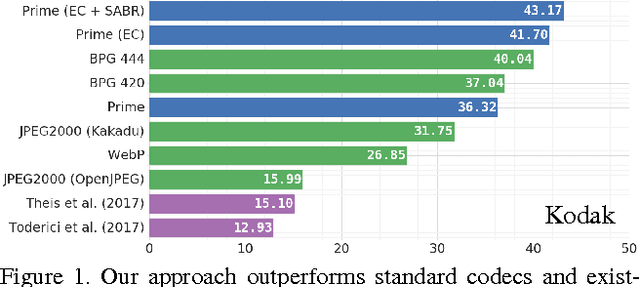

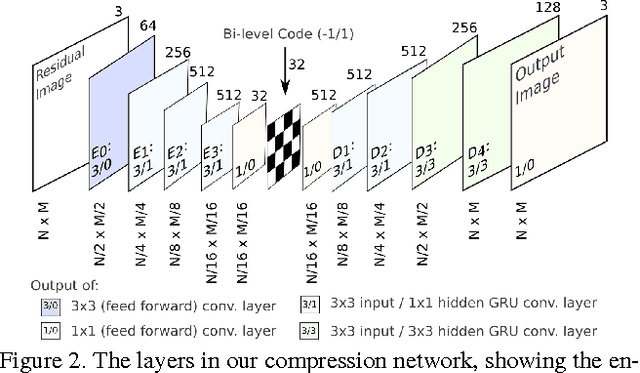
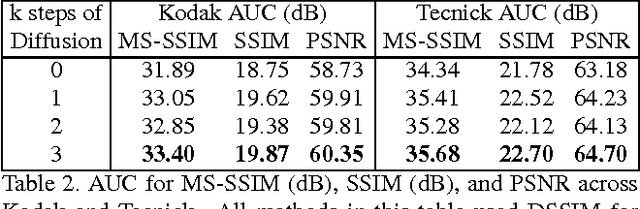
We propose a method for lossy image compression based on recurrent, convolutional neural networks that outperforms BPG (4:2:0 ), WebP, JPEG2000, and JPEG as measured by MS-SSIM. We introduce three improvements over previous research that lead to this state-of-the-art result. First, we show that training with a pixel-wise loss weighted by SSIM increases reconstruction quality according to several metrics. Second, we modify the recurrent architecture to improve spatial diffusion, which allows the network to more effectively capture and propagate image information through the network's hidden state. Finally, in addition to lossless entropy coding, we use a spatially adaptive bit allocation algorithm to more efficiently use the limited number of bits to encode visually complex image regions. We evaluate our method on the Kodak and Tecnick image sets and compare against standard codecs as well recently published methods based on deep neural networks.
YouTube-8M: A Large-Scale Video Classification Benchmark
Sep 27, 2016
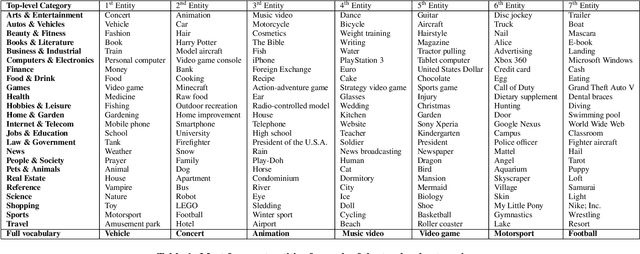
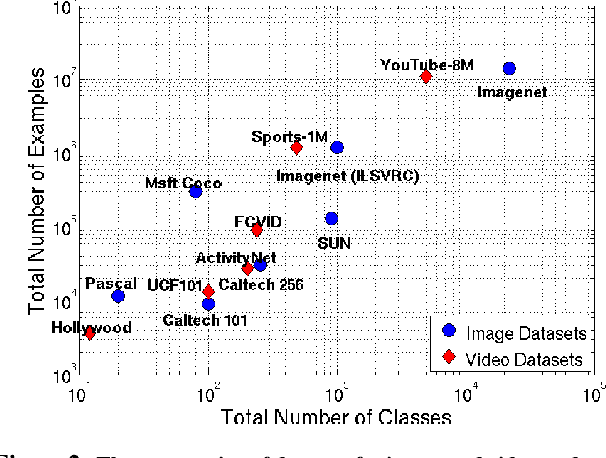

Many recent advancements in Computer Vision are attributed to large datasets. Open-source software packages for Machine Learning and inexpensive commodity hardware have reduced the barrier of entry for exploring novel approaches at scale. It is possible to train models over millions of examples within a few days. Although large-scale datasets exist for image understanding, such as ImageNet, there are no comparable size video classification datasets. In this paper, we introduce YouTube-8M, the largest multi-label video classification dataset, composed of ~8 million videos (500K hours of video), annotated with a vocabulary of 4800 visual entities. To get the videos and their labels, we used a YouTube video annotation system, which labels videos with their main topics. While the labels are machine-generated, they have high-precision and are derived from a variety of human-based signals including metadata and query click signals. We filtered the video labels (Knowledge Graph entities) using both automated and manual curation strategies, including asking human raters if the labels are visually recognizable. Then, we decoded each video at one-frame-per-second, and used a Deep CNN pre-trained on ImageNet to extract the hidden representation immediately prior to the classification layer. Finally, we compressed the frame features and make both the features and video-level labels available for download. We trained various (modest) classification models on the dataset, evaluated them using popular evaluation metrics, and report them as baselines. Despite the size of the dataset, some of our models train to convergence in less than a day on a single machine using TensorFlow. We plan to release code for training a TensorFlow model and for computing metrics.
Variable Rate Image Compression with Recurrent Neural Networks
Mar 01, 2016
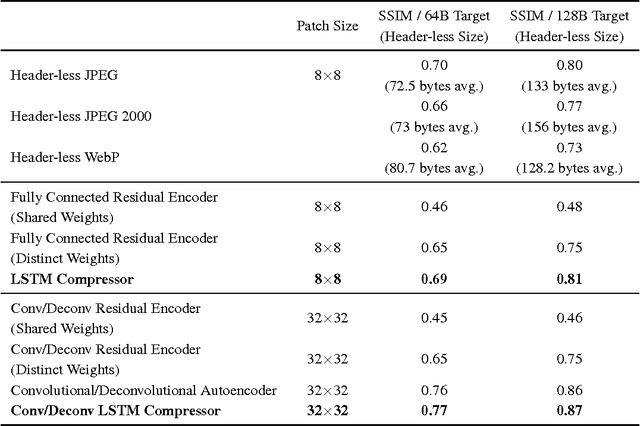
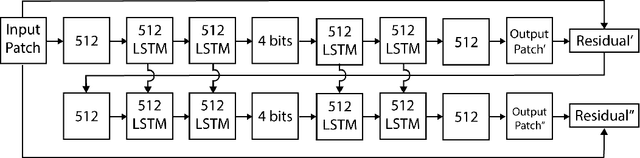

A large fraction of Internet traffic is now driven by requests from mobile devices with relatively small screens and often stringent bandwidth requirements. Due to these factors, it has become the norm for modern graphics-heavy websites to transmit low-resolution, low-bytecount image previews (thumbnails) as part of the initial page load process to improve apparent page responsiveness. Increasing thumbnail compression beyond the capabilities of existing codecs is therefore a current research focus, as any byte savings will significantly enhance the experience of mobile device users. Toward this end, we propose a general framework for variable-rate image compression and a novel architecture based on convolutional and deconvolutional LSTM recurrent networks. Our models address the main issues that have prevented autoencoder neural networks from competing with existing image compression algorithms: (1) our networks only need to be trained once (not per-image), regardless of input image dimensions and the desired compression rate; (2) our networks are progressive, meaning that the more bits are sent, the more accurate the image reconstruction; and (3) the proposed architecture is at least as efficient as a standard purpose-trained autoencoder for a given number of bits. On a large-scale benchmark of 32$\times$32 thumbnails, our LSTM-based approaches provide better visual quality than (headerless) JPEG, JPEG2000 and WebP, with a storage size that is reduced by 10% or more.
Pose Embeddings: A Deep Architecture for Learning to Match Human Poses
Jul 01, 2015


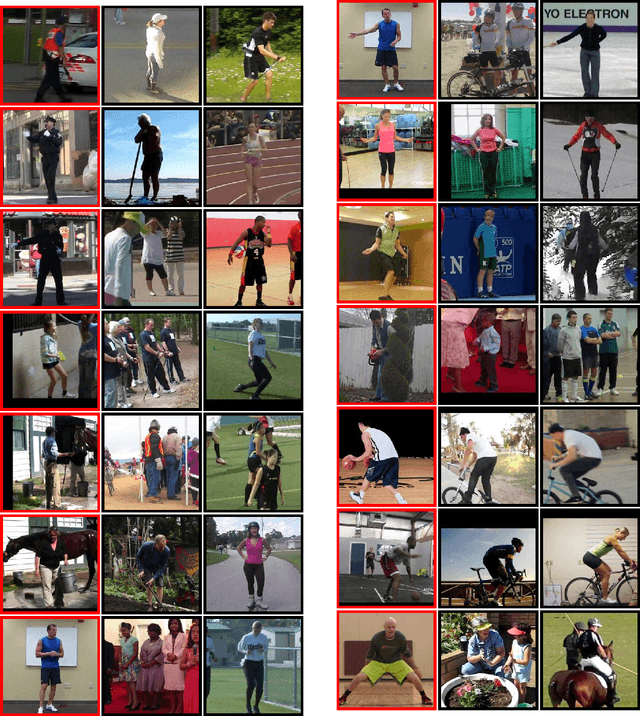
We present a method for learning an embedding that places images of humans in similar poses nearby. This embedding can be used as a direct method of comparing images based on human pose, avoiding potential challenges of estimating body joint positions. Pose embedding learning is formulated under a triplet-based distance criterion. A deep architecture is used to allow learning of a representation capable of making distinctions between different poses. Experiments on human pose matching and retrieval from video data demonstrate the potential of the method.
Efficient Large Scale Video Classification
May 22, 2015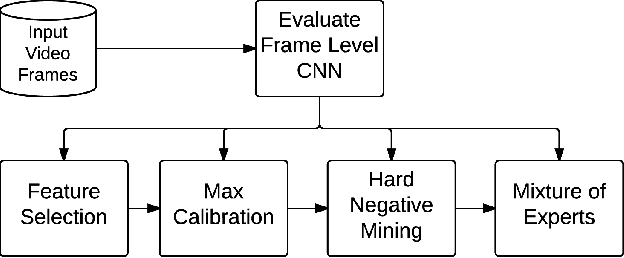

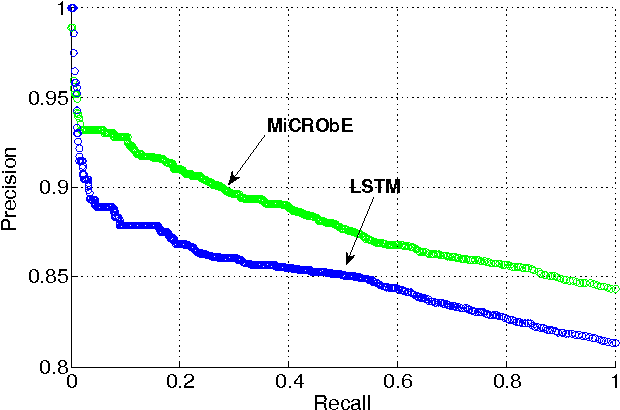
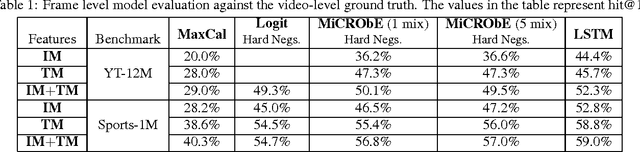
Video classification has advanced tremendously over the recent years. A large part of the improvements in video classification had to do with the work done by the image classification community and the use of deep convolutional networks (CNNs) which produce competitive results with hand- crafted motion features. These networks were adapted to use video frames in various ways and have yielded state of the art classification results. We present two methods that build on this work, and scale it up to work with millions of videos and hundreds of thousands of classes while maintaining a low computational cost. In the context of large scale video processing, training CNNs on video frames is extremely time consuming, due to the large number of frames involved. We propose to avoid this problem by training CNNs on either YouTube thumbnails or Flickr images, and then using these networks' outputs as features for other higher level classifiers. We discuss the challenges of achieving this and propose two models for frame-level and video-level classification. The first is a highly efficient mixture of experts while the latter is based on long short term memory neural networks. We present results on the Sports-1M video dataset (1 million videos, 487 classes) and on a new dataset which has 12 million videos and 150,000 labels.