 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAXenstein: Accelerated Benchmarking for First-Person Environments
May 19, 2026The progression of reinforcement learning algorithms have been driven by challenging benchmarks. The rate in which a researcher can iterate on a problem setting directly impacts the speed of algorithm development. Modern machine learning has produced tools that allow for fast and scalable algorithm development like the JAX library. With the availability of these tools, a serious bottleneck in algorithm development is the availability of large and complex domains for experimentation. Most notably, the JAX reinforcement learning ecosystem does not have any benchmarks that test visual first-person tasks; these domains are crucial for testing both exploration and an agent's ability to overcome partial observability. We introduce JAXenstein: an open-source JAX-based benchmark that implements the Wolfenstein 3D rendering engine for fast and scalable experimentation in visual first-person tasks. JAXenstein is several times faster than comparable vision-based benchmarks, and is easily extensible to more complex first-person domains.
Spectral Collapse Drives Loss of Plasticity in Deep Continual Learning
Sep 26, 2025

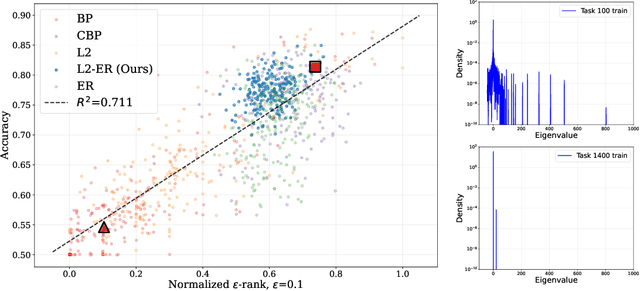

We investigate why deep neural networks suffer from \emph{loss of plasticity} in deep continual learning, failing to learn new tasks without reinitializing parameters. We show that this failure is preceded by Hessian spectral collapse at new-task initialization, where meaningful curvature directions vanish and gradient descent becomes ineffective. To characterize the necessary condition for successful training, we introduce the notion of $\tau$-trainability and show that current plasticity preserving algorithms can be unified under this framework. Targeting spectral collapse directly, we then discuss the Kronecker factored approximation of the Hessian, which motivates two regularization enhancements: maintaining high effective feature rank and applying $L2$ penalties. Experiments on continual supervised and reinforcement learning tasks confirm that combining these two regularizers effectively preserves plasticity.
Benchmarking Partial Observability in Reinforcement Learning with a Suite of Memory-Improvable Domains
Jul 31, 2025Mitigating partial observability is a necessary but challenging task for general reinforcement learning algorithms. To improve an algorithm's ability to mitigate partial observability, researchers need comprehensive benchmarks to gauge progress. Most algorithms tackling partial observability are only evaluated on benchmarks with simple forms of state aliasing, such as feature masking and Gaussian noise. Such benchmarks do not represent the many forms of partial observability seen in real domains, like visual occlusion or unknown opponent intent. We argue that a partially observable benchmark should have two key properties. The first is coverage in its forms of partial observability, to ensure an algorithm's generalizability. The second is a large gap between the performance of a agents with more or less state information, all other factors roughly equal. This gap implies that an environment is memory improvable: where performance gains in a domain are from an algorithm's ability to cope with partial observability as opposed to other factors. We introduce best-practice guidelines for empirically benchmarking reinforcement learning under partial observability, as well as the open-source library POBAX: Partially Observable Benchmarks in JAX. We characterize the types of partial observability present in various environments and select representative environments for our benchmark. These environments include localization and mapping, visual control, games, and more. Additionally, we show that these tasks are all memory improvable and require hard-to-learn memory functions, providing a concrete signal for partial observability research. This framework includes recommended hyperparameters as well as algorithm implementations for fast, out-of-the-box evaluation, as well as highly performant environments implemented in JAX for GPU-scalable experimentation.
Mitigating Partial Observability in Sequential Decision Processes via the Lambda Discrepancy
Jul 10, 2024



Reinforcement learning algorithms typically rely on the assumption that the environment dynamics and value function can be expressed in terms of a Markovian state representation. However, when state information is only partially observable, how can an agent learn such a state representation, and how can it detect when it has found one? We introduce a metric that can accomplish both objectives, without requiring access to--or knowledge of--an underlying, unobservable state space. Our metric, the $\lambda$-discrepancy, is the difference between two distinct temporal difference (TD) value estimates, each computed using TD($\lambda$) with a different value of $\lambda$. Since TD($\lambda$=0) makes an implicit Markov assumption and TD($\lambda$=1) does not, a discrepancy between these estimates is a potential indicator of a non-Markovian state representation. Indeed, we prove that the $\lambda$-discrepancy is exactly zero for all Markov decision processes and almost always non-zero for a broad class of partially observable environments. We also demonstrate empirically that, once detected, minimizing the $\lambda$-discrepancy can help with learning a memory function to mitigate the corresponding partial observability. We then train a reinforcement learning agent that simultaneously constructs two recurrent value networks with different $\lambda$ parameters and minimizes the difference between them as an auxiliary loss. The approach scales to challenging partially observable domains, where the resulting agent frequently performs significantly better (and never performs worse) than a baseline recurrent agent with only a single value network.
Measuring and Mitigating Interference in Reinforcement Learning
Jul 10, 2023



Catastrophic interference is common in many network-based learning systems, and many proposals exist for mitigating it. Before overcoming interference we must understand it better. In this work, we provide a definition and novel measure of interference for value-based reinforcement learning methods such as Fitted Q-Iteration and DQN. We systematically evaluate our measure of interference, showing that it correlates with instability in control performance, across a variety of network architectures. Our new interference measure allows us to ask novel scientific questions about commonly used deep learning architectures and study learning algorithms which mitigate interference. Lastly, we outline a class of algorithms which we call online-aware that are designed to mitigate interference, and show they do reduce interference according to our measure and that they improve stability and performance in several classic control environments.
Agent-State Construction with Auxiliary Inputs
Nov 16, 2022
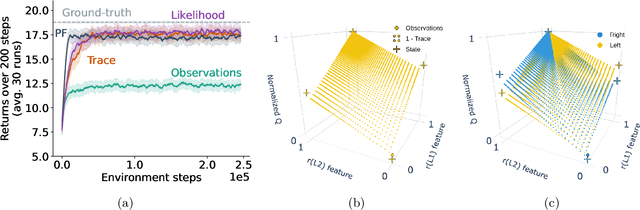
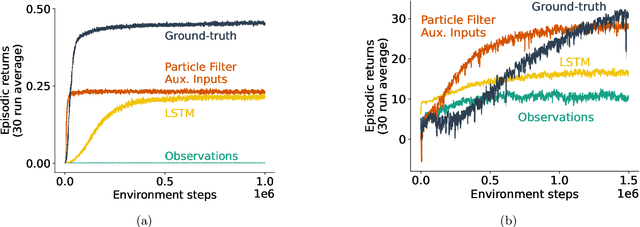
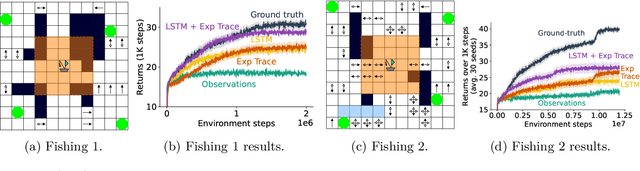
In many, if not every realistic sequential decision-making task, the decision-making agent is not able to model the full complexity of the world. The environment is often much larger and more complex than the agent, a setting also known as partial observability. In such settings, the agent must leverage more than just the current sensory inputs; it must construct an agent state that summarizes previous interactions with the world. Currently, a popular approach for tackling this problem is to learn the agent-state function via a recurrent network from the agent's sensory stream as input. Many impressive reinforcement learning applications have instead relied on environment-specific functions to aid the agent's inputs for history summarization. These augmentations are done in multiple ways, from simple approaches like concatenating observations to more complex ones such as uncertainty estimates. Although ubiquitous in the field, these additional inputs, which we term auxiliary inputs, are rarely emphasized, and it is not clear what their role or impact is. In this work we explore this idea further, and relate these auxiliary inputs to prior classic approaches to state construction. We present a series of examples illustrating the different ways of using auxiliary inputs for reinforcement learning. We show that these auxiliary inputs can be used to discriminate between observations that would otherwise be aliased, leading to more expressive features that smoothly interpolate between different states. Finally, we show that this approach is complementary to state-of-the-art methods such as recurrent neural networks and truncated back-propagation through time, and acts as a heuristic that facilitates longer temporal credit assignment, leading to better performance.
Novelty Search in Representational Space for Sample Efficient Exploration
Oct 21, 2020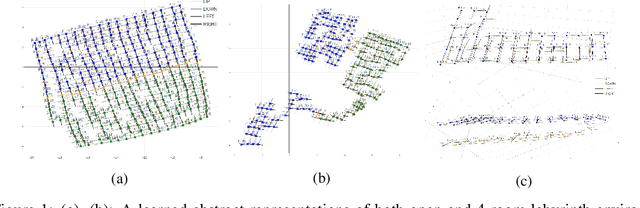
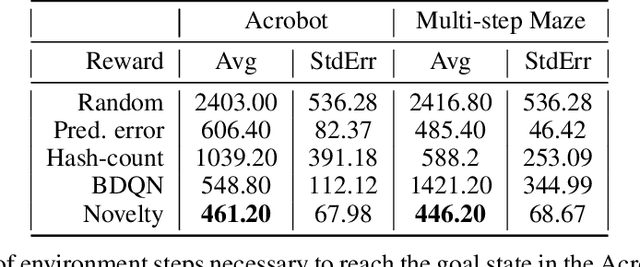
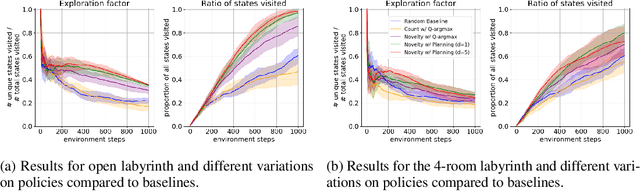
We present a new approach for efficient exploration which leverages a low-dimensional encoding of the environment learned with a combination of model-based and model-free objectives. Our approach uses intrinsic rewards that are based on the distance of nearest neighbors in the low dimensional representational space to gauge novelty. We then leverage these intrinsic rewards for sample-efficient exploration with planning routines in representational space for hard exploration tasks with sparse rewards. One key element of our approach is the use of information theoretic principles to shape our representations in a way so that our novelty reward goes beyond pixel similarity. We test our approach on a number of maze tasks, as well as a control problem and show that our exploration approach is more sample-efficient compared to strong baselines.
Towards Solving Text-based Games by Producing Adaptive Action Spaces
Dec 03, 2018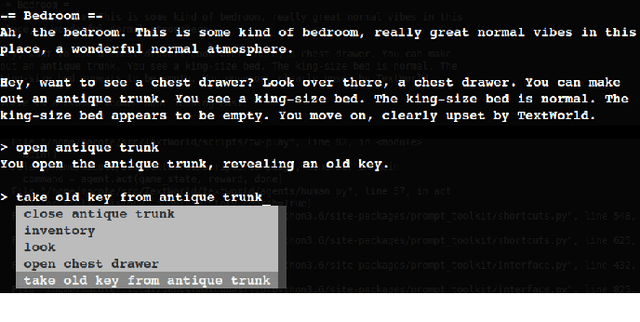

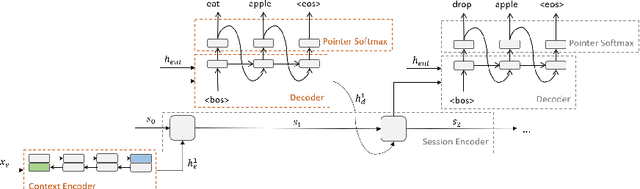
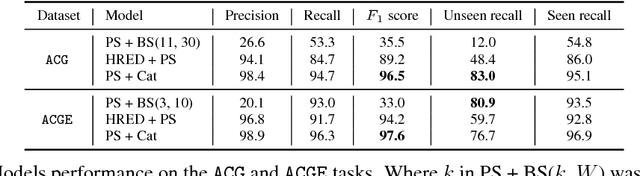
To solve a text-based game, an agent needs to formulate valid text commands for a given context and find the ones that lead to success. Recent attempts at solving text-based games with deep reinforcement learning have focused on the latter, i.e., learning to act optimally when valid actions are known in advance. In this work, we propose to tackle the first task and train a model that generates the set of all valid commands for a given context. We try three generative models on a dataset generated with Textworld. The best model can generate valid commands which were unseen at training and achieve high $F_1$ score on the test set.