 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMAP Agentic Planning Technical Report
Dec 31, 2025We present STAgent, an agentic large language model tailored for spatio-temporal understanding, designed to solve complex tasks such as constrained point-of-interest discovery and itinerary planning. STAgent is a specialized model capable of interacting with ten distinct tools within spatio-temporal scenarios, enabling it to explore, verify, and refine intermediate steps during complex reasoning. Notably, STAgent effectively preserves its general capabilities. We empower STAgent with these capabilities through three key contributions: (1) a stable tool environment that supports over ten domain-specific tools, enabling asynchronous rollout and training; (2) a hierarchical data curation framework that identifies high-quality data like a needle in a haystack, curating high-quality queries with a filter ratio of 1:10,000, emphasizing both diversity and difficulty; and (3) a cascaded training recipe that starts with a seed SFT stage acting as a guardian to measure query difficulty, followed by a second SFT stage fine-tuned on queries with high certainty, and an ultimate RL stage that leverages data of low certainty. Initialized with Qwen3-30B-A3B to establish a strong SFT foundation and leverage insights into sample difficulty, STAgent yields promising performance on TravelBench while maintaining its general capabilities across a wide range of general benchmarks, thereby demonstrating the effectiveness of our proposed agentic model.
Deep Tensor Learning for Reliable Channel Charting from Incomplete and Noisy Measurements
Sep 16, 2025Channel charting has emerged as a powerful tool for user equipment localization and wireless environment sensing. Its efficacy lies in mapping high-dimensional channel data into low-dimensional features that preserve the relative similarities of the original data. However, existing channel charting methods are largely developed using simulated or indoor measurements, often assuming clean and complete channel data across all frequency bands. In contrast, real-world channels collected from base stations are typically incomplete due to frequency hopping and are significantly noisy, particularly at cell edges. These challenging conditions greatly degrade the performance of current methods. To address this, we propose a deep tensor learning method that leverages the inherent tensor structure of wireless channels to effectively extract informative while low-dimensional features (i.e., channel charts) from noisy and incomplete measurements. Experimental results demonstrate the reliability and effectiveness of the proposed approach in these challenging scenarios.
Towards Reward Fairness in RLHF: From a Resource Allocation Perspective
May 29, 2025Rewards serve as proxies for human preferences and play a crucial role in Reinforcement Learning from Human Feedback (RLHF). However, if these rewards are inherently imperfect, exhibiting various biases, they can adversely affect the alignment of large language models (LLMs). In this paper, we collectively define the various biases present in rewards as the problem of reward unfairness. We propose a bias-agnostic method to address the issue of reward fairness from a resource allocation perspective, without specifically designing for each type of bias, yet effectively mitigating them. Specifically, we model preference learning as a resource allocation problem, treating rewards as resources to be allocated while considering the trade-off between utility and fairness in their distribution. We propose two methods, Fairness Regularization and Fairness Coefficient, to achieve fairness in rewards. We apply our methods in both verification and reinforcement learning scenarios to obtain a fairness reward model and a policy model, respectively. Experiments conducted in these scenarios demonstrate that our approach aligns LLMs with human preferences in a more fair manner.
GUNDAM: Aligning Large Language Models with Graph Understanding
Sep 30, 2024



Large Language Models (LLMs) have achieved impressive results in processing text data, which has sparked interest in applying these models beyond textual data, such as graphs. In the field of graph learning, there is a growing interest in harnessing LLMs to comprehend and manipulate graph-structured data. Existing research predominantly focuses on graphs with rich textual features, such as knowledge graphs or text attribute graphs, leveraging LLMs' ability to process text but inadequately addressing graph structure. This work specifically aims to assess and enhance LLMs' abilities to comprehend and utilize the structural knowledge inherent in graph data itself, rather than focusing solely on graphs rich in textual content. To achieve this, we introduce the \textbf{G}raph \textbf{U}nderstanding for \textbf{N}atural Language \textbf{D}riven \textbf{A}nalytical \textbf{M}odel (\model). This model adapts LLMs to better understand and engage with the structure of graph data, enabling them to perform complex reasoning tasks by leveraging the graph's structure itself. Our experimental evaluations on graph reasoning benchmarks not only substantiate that \model~ outperforms the SOTA baselines for comparisons. But also reveals key factors affecting the graph reasoning capabilities of LLMs. Moreover, we provide a theoretical analysis illustrating how reasoning paths can enhance LLMs' reasoning capabilities.
Preserving Node Distinctness in Graph Autoencoders via Similarity Distillation
Jun 25, 2024



Graph autoencoders (GAEs), as a kind of generative self-supervised learning approach, have shown great potential in recent years. GAEs typically rely on distance-based criteria, such as mean-square-error (MSE), to reconstruct the input graph. However, relying solely on a single reconstruction criterion may lead to a loss of distinctiveness in the reconstructed graph, causing nodes to collapse into similar representations and resulting in sub-optimal performance. To address this issue, we have developed a simple yet effective strategy to preserve the necessary distinctness in the reconstructed graph. Inspired by the knowledge distillation technique, we found that the dual encoder-decoder architecture of GAEs can be viewed as a teacher-student relationship. Therefore, we propose transferring the knowledge of distinctness from the raw graph to the reconstructed graph, achieved through a simple KL constraint. Specifically, we compute pairwise node similarity scores in the raw graph and reconstructed graph. During the training process, the KL constraint is optimized alongside the reconstruction criterion. We conducted extensive experiments across three types of graph tasks, demonstrating the effectiveness and generality of our strategy. This indicates that the proposed approach can be employed as a plug-and-play method to avoid vague reconstructions and enhance overall performance.
Towards Comprehensive Preference Data Collection for Reward Modeling
Jun 24, 2024



Reinforcement Learning from Human Feedback (RLHF) facilitates the alignment of large language models (LLMs) with human preferences, thereby enhancing the quality of responses generated. A critical component of RLHF is the reward model, which is trained on preference data and outputs a scalar reward during the inference stage. However, the collection of preference data still lacks thorough investigation. Recent studies indicate that preference data is collected either by AI or humans, where chosen and rejected instances are identified among pairwise responses. We question whether this process effectively filters out noise and ensures sufficient diversity in collected data. To address these concerns, for the first time, we propose a comprehensive framework for preference data collection, decomposing the process into four incremental steps: Prompt Generation, Response Generation, Response Filtering, and Human Labeling. This structured approach ensures the collection of high-quality preferences while reducing reliance on human labor. We conducted comprehensive experiments based on the data collected at different stages, demonstrating the effectiveness of the proposed data collection method.
Exploring Task Unification in Graph Representation Learning via Generative Approach
Mar 21, 2024



Graphs are ubiquitous in real-world scenarios and encompass a diverse range of tasks, from node-, edge-, and graph-level tasks to transfer learning. However, designing specific tasks for each type of graph data is often costly and lacks generalizability. Recent endeavors under the "Pre-training + Fine-tuning" or "Pre-training + Prompt" paradigms aim to design a unified framework capable of generalizing across multiple graph tasks. Among these, graph autoencoders (GAEs), generative self-supervised models, have demonstrated their potential in effectively addressing various graph tasks. Nevertheless, these methods typically employ multi-stage training and require adaptive designs, which on one hand make it difficult to be seamlessly applied to diverse graph tasks and on the other hand overlook the negative impact caused by discrepancies in task objectives between the different stages. To address these challenges, we propose GA^2E, a unified adversarially masked autoencoder capable of addressing the above challenges seamlessly. Specifically, GA^2E proposes to use the subgraph as the meta-structure, which remains consistent across all graph tasks (ranging from node-, edge-, and graph-level to transfer learning) and all stages (both during training and inference). Further, GA^2E operates in a \textbf{"Generate then Discriminate"} manner. It leverages the masked GAE to reconstruct the input subgraph whilst treating it as a generator to compel the reconstructed graphs resemble the input subgraph. Furthermore, GA^2E introduces an auxiliary discriminator to discern the authenticity between the reconstructed (generated) subgraph and the input subgraph, thus ensuring the robustness of the graph representation through adversarial training mechanisms. We validate GA^2E's capabilities through extensive experiments on 21 datasets across four types of graph tasks.
Do We Really Need Contrastive Learning for Graph Representation?
Oct 23, 2023



In recent years, contrastive learning has emerged as a dominant self-supervised paradigm, attracting numerous research interests in the field of graph learning. Graph contrastive learning (GCL) aims to embed augmented anchor samples close to each other while pushing the embeddings of other samples (negative samples) apart. However, existing GCL methods require large and diverse negative samples to ensure the quality of embeddings, and recent studies typically leverage samples excluding the anchor and positive samples as negative samples, potentially introducing false negative samples (negatives that share the same class as the anchor). Additionally, this practice can result in heavy computational burden and high time complexity of $O(N^2)$, which is particularly unaffordable for large graphs. To address these deficiencies, we leverage rank learning and propose a simple yet effective model, GraphRank. Specifically, we first generate two graph views through corruption. Then, we compute the similarity of pairwise nodes (anchor node and positive node) in both views, an arbitrary node in the latter view is selected as a negative node, and its similarity with the anchor node is computed. Based on this, we introduce rank-based learning to measure similarity scores which successfully relieve the false negative provlem and decreases the time complexity from $O(N^2)$ to $O(N)$. Moreover, we conducted extensive experiments across multiple graph tasks, demonstrating that GraphRank performs favorably against other cutting-edge GCL methods in various tasks.
Learning Heatmap-Style Jigsaw Puzzles Provides Good Pretraining for 2D Human Pose Estimation
Dec 13, 2020
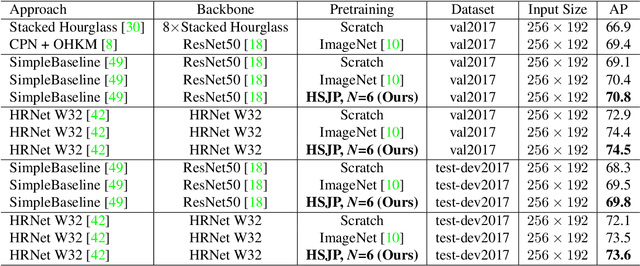

The target of 2D human pose estimation is to locate the keypoints of body parts from input 2D images. State-of-the-art methods for pose estimation usually construct pixel-wise heatmaps from keypoints as labels for learning convolution neural networks, which are usually initialized randomly or using classification models on ImageNet as their backbones. We note that 2D pose estimation task is highly dependent on the contextual relationship between image patches, thus we introduce a self-supervised method for pretraining 2D pose estimation networks. Specifically, we propose Heatmap-Style Jigsaw Puzzles (HSJP) problem as our pretext-task, whose target is to learn the location of each patch from an image composed of shuffled patches. During our pretraining process, we only use images of person instances in MS-COCO, rather than introducing extra and much larger ImageNet dataset. A heatmap-style label for patch location is designed and our learning process is in a non-contrastive way. The weights learned by HSJP pretext task are utilised as backbones of 2D human pose estimator, which are then finetuned on MS-COCO human keypoints dataset. With two popular and strong 2D human pose estimators, HRNet and SimpleBaseline, we evaluate mAP score on both MS-COCO validation and test-dev datasets. Our experiments show that downstream pose estimators with our self-supervised pretraining obtain much better performance than those trained from scratch, and are comparable to those using ImageNet classification models as their initial backbones.
DNANet: De-Normalized Attention Based Multi-Resolution Network for Human Pose Estimation
Oct 21, 2019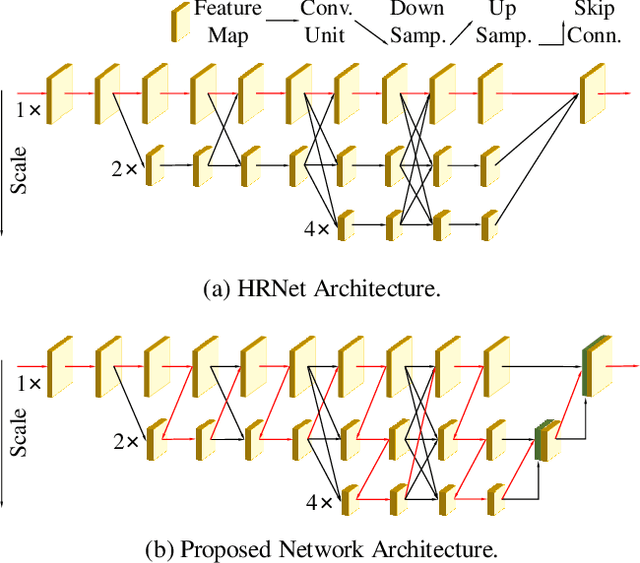
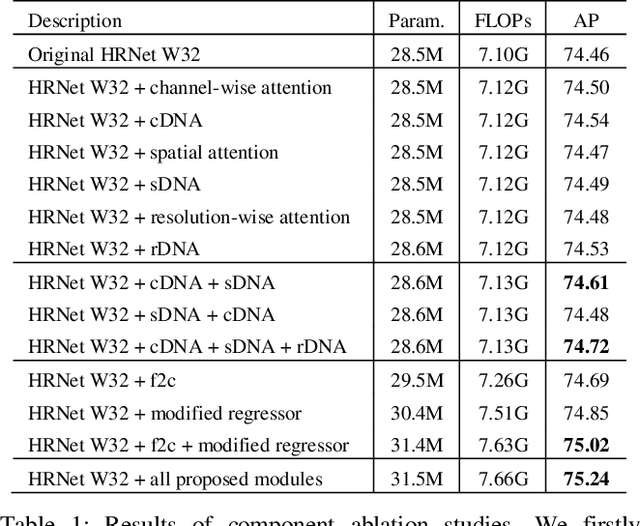
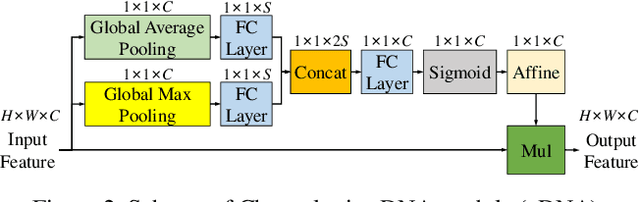
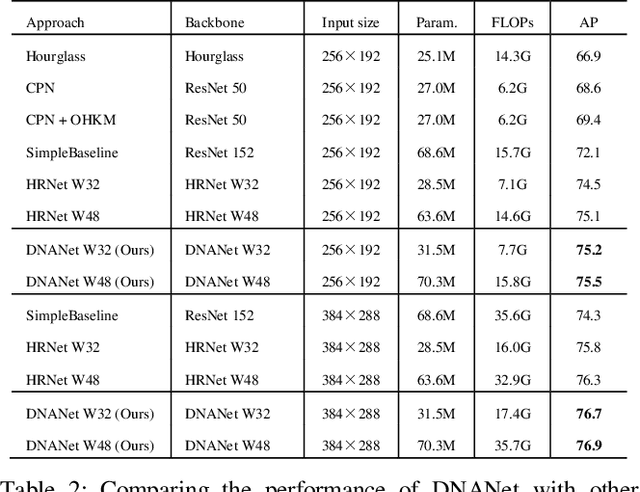
Recently, multi-resolution networks (such as Hourglass, CPN, HRNet, etc.) have achieved significant performance on the task of human pose estimation by combining features from various resolutions. In this paper, we propose a novel type of attention module, namely De-Normalized Attention (DNA) to deal with the feature attenuations of conventional attention modules. Our method extends the original HRNet with spatial, channel-wise and resolution-wise DNAs, which aims at evaluating the importance of features from different locations, channels and resolutions to enhance the network capability for feature representation. We also propose to add fine-to-coarse connections across high-to-low resolutions in-side each layer of HRNet to increase the maximum depth of network topology. In addition, we propose to modify the keypoint regressor at the end of HRNet for accurate keypoint heatmap prediction. The effectiveness of our proposed network is demonstrated on COCO keypoint detection dataset, achieving state-of-the-art performance at 77.6 AP score on COCO val2017 dataset without using extra keypoint training data. Our paper will be accompanied with publicly available codes at GitHub.