 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling
Apr 23, 2026Large token-indexed lookup tables provide a compute-decoupled scaling path, but their practical gains are often limited by poor parameter efficiency and rapid memory growth. We attribute these limitations to Zipfian under-training of the long tail, heterogeneous demand across layers, and "slot collapse" that produces redundant embeddings. To address this, we propose X-GRAM, a frequency-aware dynamic token-injection framework. X-GRAM employs hybrid hashing and alias mixing to compress the tail while preserving head capacity, and refines retrieved vectors via normalized SwiGLU ShortConv to extract diverse local n-gram features. These signals are integrated into attention value streams and inter-layer residuals using depth-aware gating, effectively aligning static memory with dynamic context. This design introduces a memory-centric scaling axis that decouples model capacity from FLOPs. Extensive evaluations at the 0.73B and 1.15B scales show that X-GRAM improves average accuracy by as much as 4.4 points over the vanilla backbone and 3.2 points over strong retrieval baselines, while using substantially smaller tables in the 50% configuration. Overall, by decoupling capacity from compute through efficient memory management, X-GRAM offers a scalable and practical paradigm for future memory-augmented architectures. Code aviliable in https://github.com/Longyichen/X-gram.
Learning Heatmap-Style Jigsaw Puzzles Provides Good Pretraining for 2D Human Pose Estimation
Dec 13, 2020
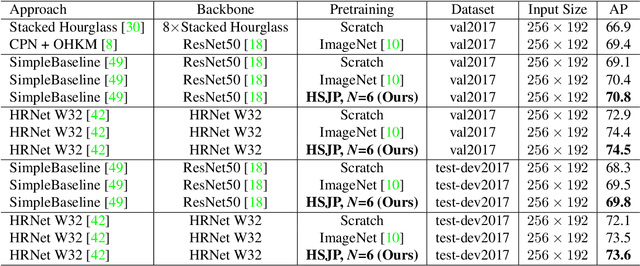

The target of 2D human pose estimation is to locate the keypoints of body parts from input 2D images. State-of-the-art methods for pose estimation usually construct pixel-wise heatmaps from keypoints as labels for learning convolution neural networks, which are usually initialized randomly or using classification models on ImageNet as their backbones. We note that 2D pose estimation task is highly dependent on the contextual relationship between image patches, thus we introduce a self-supervised method for pretraining 2D pose estimation networks. Specifically, we propose Heatmap-Style Jigsaw Puzzles (HSJP) problem as our pretext-task, whose target is to learn the location of each patch from an image composed of shuffled patches. During our pretraining process, we only use images of person instances in MS-COCO, rather than introducing extra and much larger ImageNet dataset. A heatmap-style label for patch location is designed and our learning process is in a non-contrastive way. The weights learned by HSJP pretext task are utilised as backbones of 2D human pose estimator, which are then finetuned on MS-COCO human keypoints dataset. With two popular and strong 2D human pose estimators, HRNet and SimpleBaseline, we evaluate mAP score on both MS-COCO validation and test-dev datasets. Our experiments show that downstream pose estimators with our self-supervised pretraining obtain much better performance than those trained from scratch, and are comparable to those using ImageNet classification models as their initial backbones.