 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Preference Data Collection for Reward Modeling
Jun 24, 2024



Reinforcement Learning from Human Feedback (RLHF) facilitates the alignment of large language models (LLMs) with human preferences, thereby enhancing the quality of responses generated. A critical component of RLHF is the reward model, which is trained on preference data and outputs a scalar reward during the inference stage. However, the collection of preference data still lacks thorough investigation. Recent studies indicate that preference data is collected either by AI or humans, where chosen and rejected instances are identified among pairwise responses. We question whether this process effectively filters out noise and ensures sufficient diversity in collected data. To address these concerns, for the first time, we propose a comprehensive framework for preference data collection, decomposing the process into four incremental steps: Prompt Generation, Response Generation, Response Filtering, and Human Labeling. This structured approach ensures the collection of high-quality preferences while reducing reliance on human labor. We conducted comprehensive experiments based on the data collected at different stages, demonstrating the effectiveness of the proposed data collection method.
KwaiYiiMath: Technical Report
Oct 19, 2023



Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.
FedSkel: Efficient Federated Learning on Heterogeneous Systems with Skeleton Gradients Update
Aug 20, 2021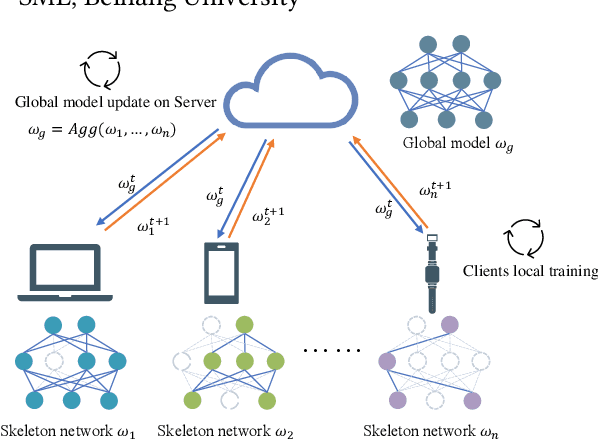
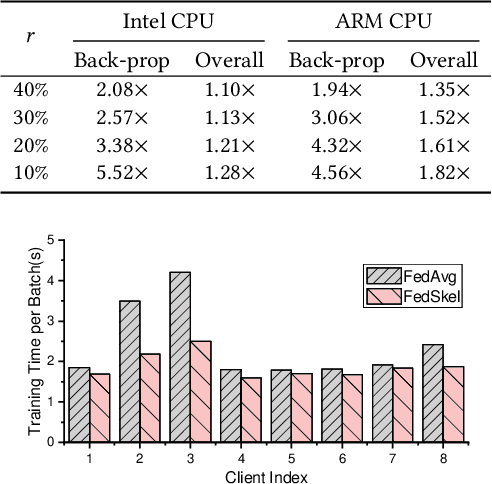
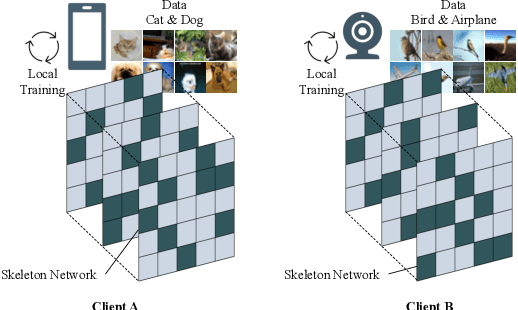

Federated learning aims to protect users' privacy while performing data analysis from different participants. However, it is challenging to guarantee the training efficiency on heterogeneous systems due to the various computational capabilities and communication bottlenecks. In this work, we propose FedSkel to enable computation-efficient and communication-efficient federated learning on edge devices by only updating the model's essential parts, named skeleton networks. FedSkel is evaluated on real edge devices with imbalanced datasets. Experimental results show that it could achieve up to 5.52$\times$ speedups for CONV layers' back-propagation, 1.82$\times$ speedups for the whole training process, and reduce 64.8% communication cost, with negligible accuracy loss.
S2Engine: A Novel Systolic Architecture for Sparse Convolutional Neural Networks
Jun 15, 2021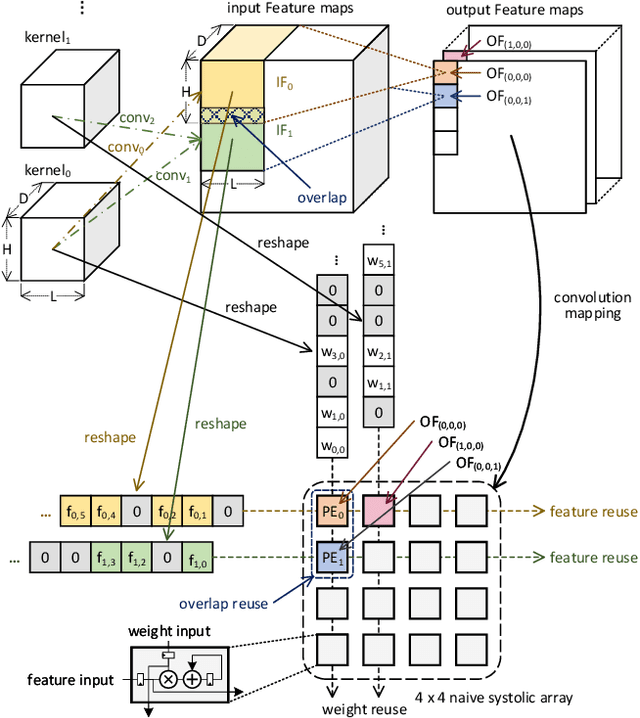
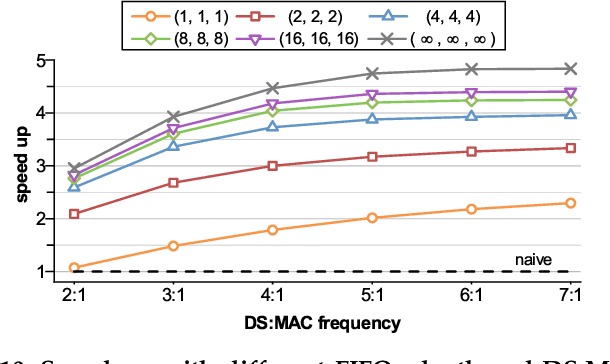
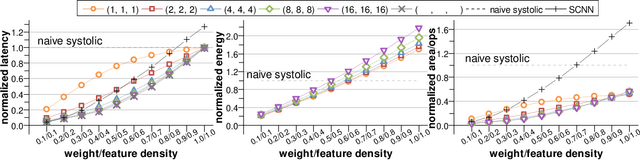
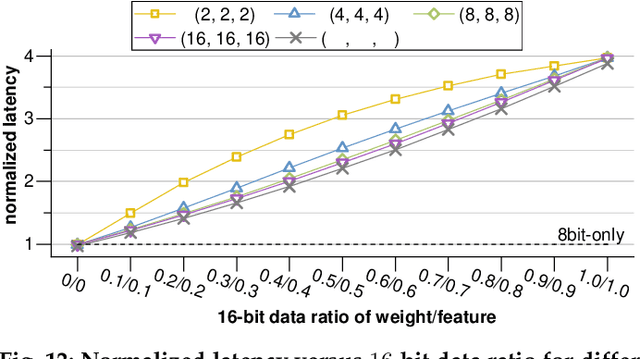
Convolutional neural networks (CNNs) have achieved great success in performing cognitive tasks. However, execution of CNNs requires a large amount of computing resources and generates heavy memory traffic, which imposes a severe challenge on computing system design. Through optimizing parallel executions and data reuse in convolution, systolic architecture demonstrates great advantages in accelerating CNN computations. However, regular internal data transmission path in traditional systolic architecture prevents the systolic architecture from completely leveraging the benefits introduced by neural network sparsity. Deployment of fine-grained sparsity on the existing systolic architectures is greatly hindered by the incurred computational overheads. In this work, we propose S2Engine $-$ a novel systolic architecture that can fully exploit the sparsity in CNNs with maximized data reuse. S2Engine transmits compressed data internally and allows each processing element to dynamically select an aligned data from the compressed dataflow in convolution. Compared to the naive systolic array, S2Engine achieves about $3.2\times$ and about $3.0\times$ improvements on speed and energy efficiency, respectively.
* 13 pages, 17 figures
RoSearch: Search for Robust Student Architectures When Distilling Pre-trained Language Models
Jun 07, 2021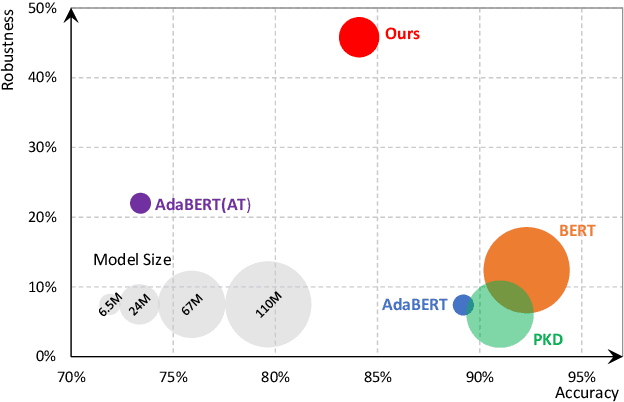
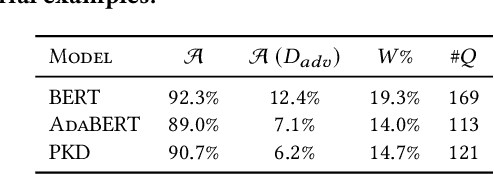
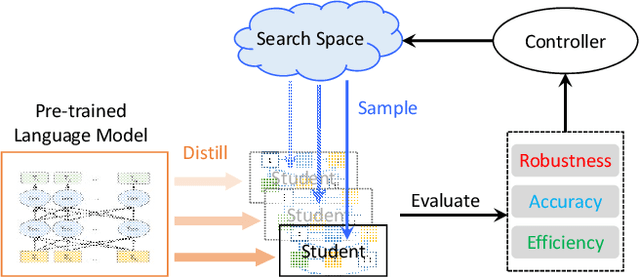
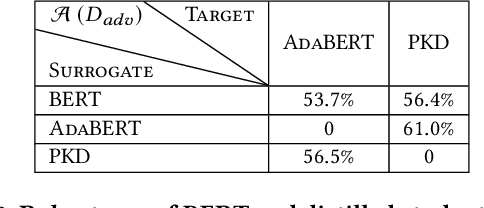
Pre-trained language models achieve outstanding performance in NLP tasks. Various knowledge distillation methods have been proposed to reduce the heavy computation and storage requirements of pre-trained language models. However, from our observations, student models acquired by knowledge distillation suffer from adversarial attacks, which limits their usage in security sensitive scenarios. In order to overcome these security problems, RoSearch is proposed as a comprehensive framework to search the student models with better adversarial robustness when performing knowledge distillation. A directed acyclic graph based search space is built and an evolutionary search strategy is utilized to guide the searching approach. Each searched architecture is trained by knowledge distillation on pre-trained language model and then evaluated under a robustness-, accuracy- and efficiency-aware metric as environmental fitness. Experimental results show that RoSearch can improve robustness of student models from 7%~18% up to 45.8%~47.8% on different datasets with comparable weight compression ratio to existing distillation methods (4.6$\times$~6.5$\times$ improvement from teacher model BERT_BASE) and low accuracy drop. In addition, we summarize the relationship between student architecture and robustness through statistics of searched models.
SparseTrain: Exploiting Dataflow Sparsity for Efficient Convolutional Neural Networks Training
Jul 21, 2020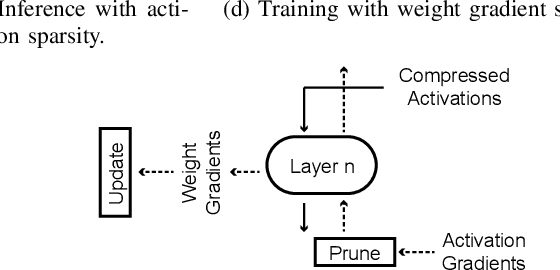
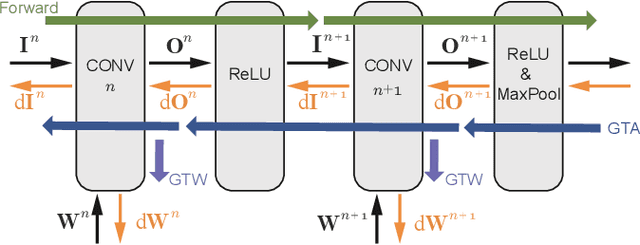
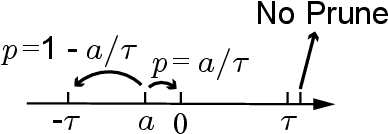
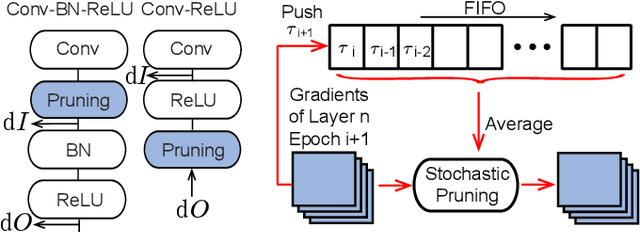
Training Convolutional Neural Networks (CNNs) usually requires a large number of computational resources. In this paper, \textit{SparseTrain} is proposed to accelerate CNN training by fully exploiting the sparsity. It mainly involves three levels of innovations: activation gradients pruning algorithm, sparse training dataflow, and accelerator architecture. By applying a stochastic pruning algorithm on each layer, the sparsity of back-propagation gradients can be increased dramatically without degrading training accuracy and convergence rate. Moreover, to utilize both \textit{natural sparsity} (resulted from ReLU or Pooling layers) and \textit{artificial sparsity} (brought by pruning algorithm), a sparse-aware architecture is proposed for training acceleration. This architecture supports forward and back-propagation of CNN by adopting 1-Dimensional convolution dataflow. We have built %a simple compiler to map CNNs topology onto \textit{SparseTrain}, and a cycle-accurate architecture simulator to evaluate the performance and efficiency based on the synthesized design with $14nm$ FinFET technologies. Evaluation results on AlexNet/ResNet show that \textit{SparseTrain} could achieve about $2.7 \times$ speedup and $2.2 \times$ energy efficiency improvement on average compared with the original training process.
Accelerating CNN Training by Sparsifying Activation Gradients
Aug 01, 2019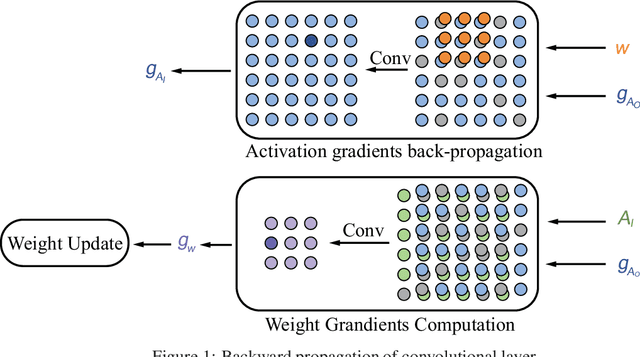
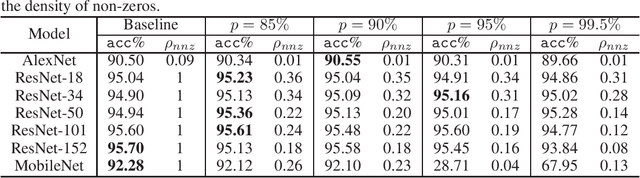
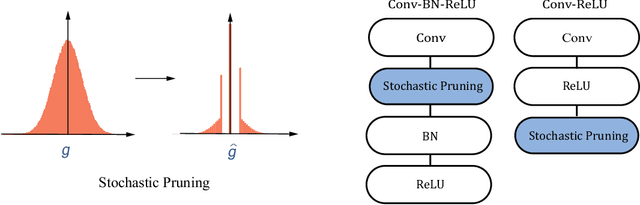
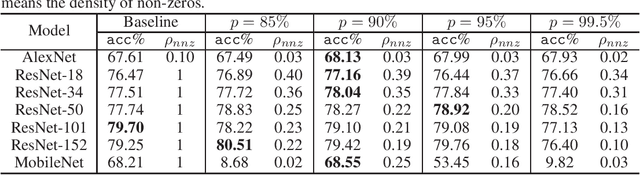
Gradients to activations get involved in most of the calculations during back propagation procedure of Convolution Neural Networks (CNNs) training. However, an important known observation is that the majority of these gradients are close to zero, imposing little impact on weights update. These gradients can be then pruned to achieve high gradient sparsity during CNNs training and reduce the computational cost. In particular, we randomly change a gradient to zero or a threshold value if the gradient is below the threshold which is determined by the statistical distribution of activation gradients. We also theoretically proved that the training convergence of the CNN model can be guaranteed when the above activation gradient sparsification method is applied. We evaluated our method on AlexNet, MobileNet, ResNet-{18, 34, 50, 101, 152} with CIFAR-{10, 100} and ImageNet datasets. Experimental results show that our method can substantially reduce the computational cost with negligible accuracy loss or even accuracy improvement. Finally, we analyzed the benefits that the sparsity of activation gradients introduced in detail.