 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
May 03, 2022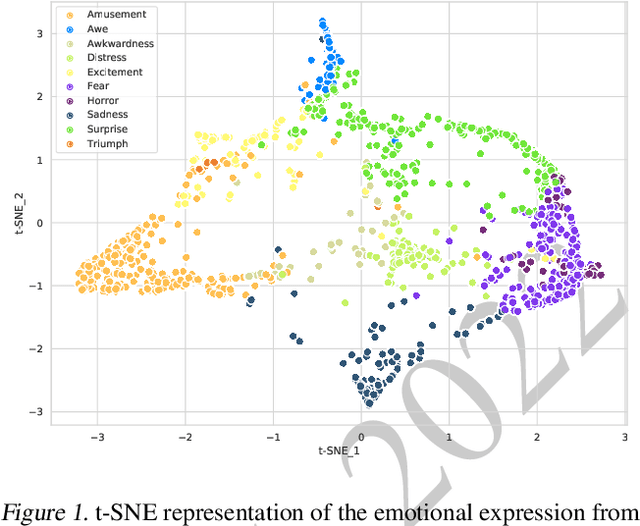
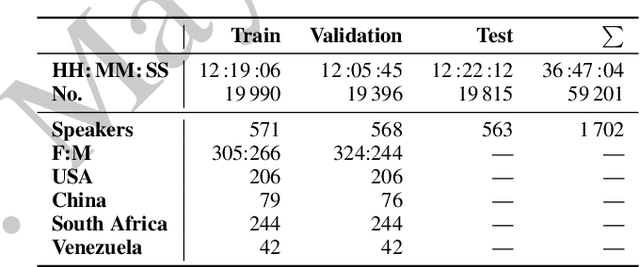
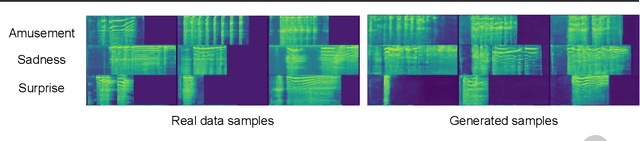
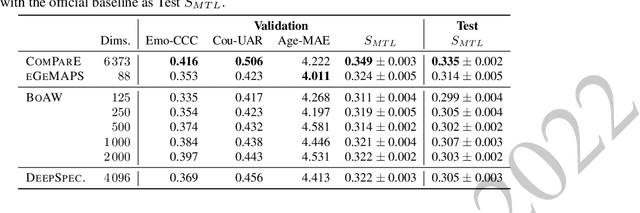
The ICML Expressive Vocalization (ExVo) Competition is focused on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, includes three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts. This paper describes the three tracks and provides performance measures for baseline models using state-of-the-art machine learning strategies. The baseline for each track is as follows, for ExVo-MultiTask, a combined score, computing the harmonic mean of Concordance Correlation Coefficient (CCC), Unweighted Average Recall (UAR), and inverted Mean Absolute Error (MAE) ($S_{MTL}$) is at best, 0.335 $S_{MTL}$; for ExVo-Generate, we report Fr\'echet inception distance (FID) scores ranging from 4.81 to 8.27 (depending on the emotion) between the training set and generated samples. We then combine the inverted FID with perceptual ratings of the generated samples ($S_{Gen}$) and obtain 0.174 $S_{Gen}$; and for ExVo-FewShot, a mean CCC of 0.444 is obtained.
Beyond L1: Faster and Better Sparse Models with skglm
Apr 16, 2022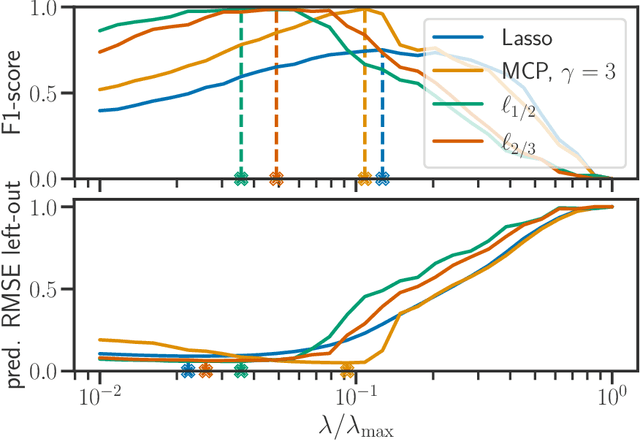
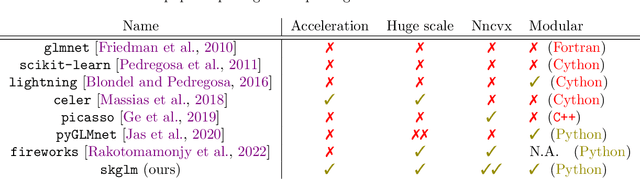
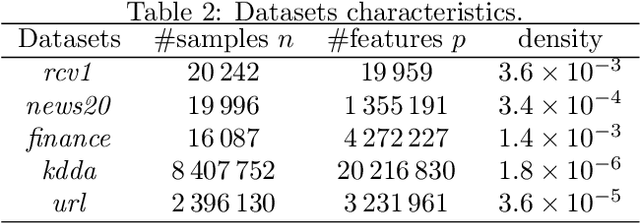
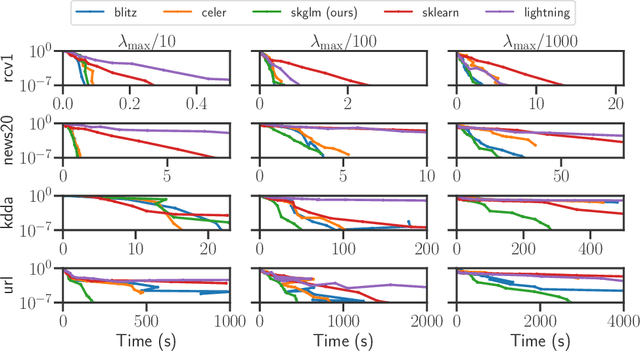
We propose a new fast algorithm to estimate any sparse generalized linear model with convex or non-convex separable penalties. Our algorithm is able to solve problems with millions of samples and features in seconds, by relying on coordinate descent, working sets and Anderson acceleration. It handles previously unaddressed models, and is extensively shown to improve state-of-art algorithms. We provide a flexible, scikit-learn compatible package, which easily handles customized datafits and penalties.
Stochastic Extragradient: General Analysis and Improved Rates
Nov 16, 2021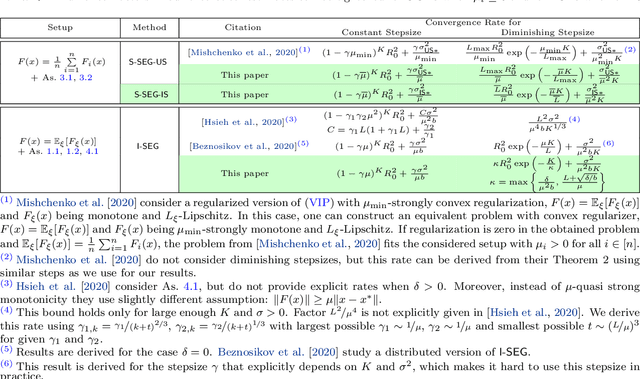
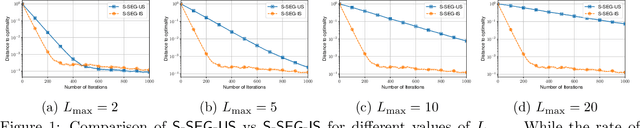
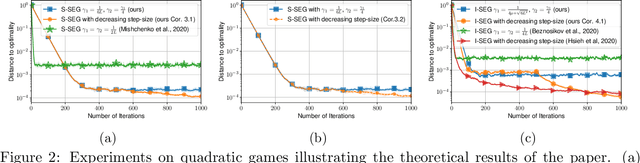

The Stochastic Extragradient (SEG) method is one of the most popular algorithms for solving min-max optimization and variational inequalities problems (VIP) appearing in various machine learning tasks. However, several important questions regarding the convergence properties of SEG are still open, including the sampling of stochastic gradients, mini-batching, convergence guarantees for the monotone finite-sum variational inequalities with possibly non-monotone terms, and others. To address these questions, in this paper, we develop a novel theoretical framework that allows us to analyze several variants of SEG in a unified manner. Besides standard setups, like Same-Sample SEG under Lipschitzness and monotonicity or Independent-Samples SEG under uniformly bounded variance, our approach allows us to analyze variants of SEG that were never explicitly considered in the literature before. Notably, we analyze SEG with arbitrary sampling which includes importance sampling and various mini-batching strategies as special cases. Our rates for the new variants of SEG outperform the current state-of-the-art convergence guarantees and rely on less restrictive assumptions.
Generating Diverse Realistic Laughter for Interactive Art
Nov 04, 2021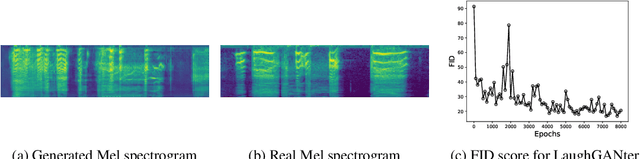
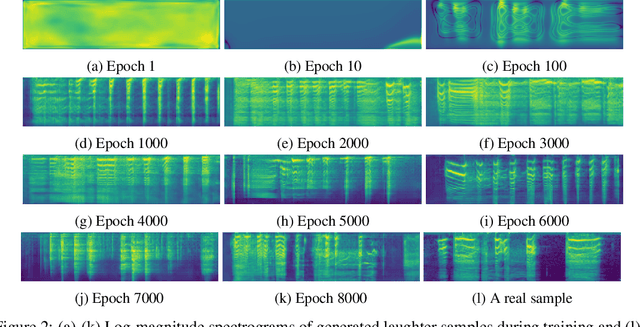
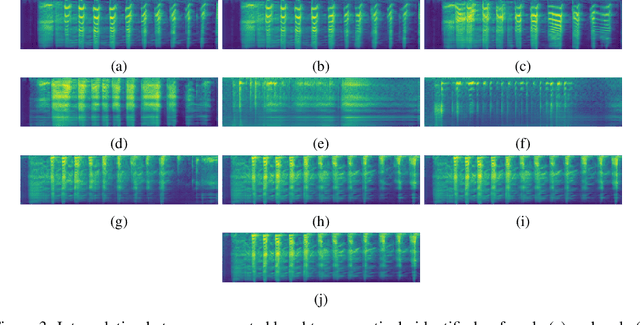
We propose an interactive art project to make those rendered invisible by the COVID-19 crisis and its concomitant solitude reappear through the welcome melody of laughter, and connections created and explored through advanced laughter synthesis approaches. However, the unconditional generation of the diversity of human emotional responses in high-quality auditory synthesis remains an open problem, with important implications for the application of these approaches in artistic settings. We developed LaughGANter, an approach to reproduce the diversity of human laughter using generative adversarial networks (GANs). When trained on a dataset of diverse laughter samples, LaughGANter generates diverse, high quality laughter samples, and learns a latent space suitable for emotional analysis and novel artistic applications such as latent mixing/interpolation and emotional transfer.
Convergence Analysis and Implicit Regularization of Feedback Alignment for Deep Linear Networks
Oct 20, 2021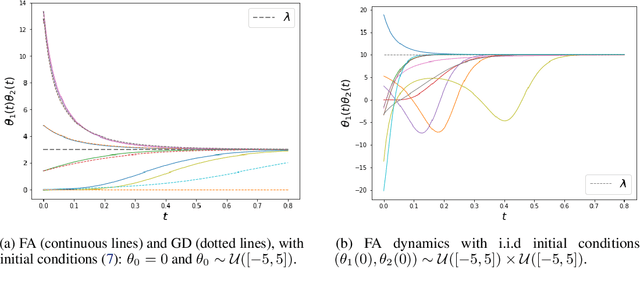
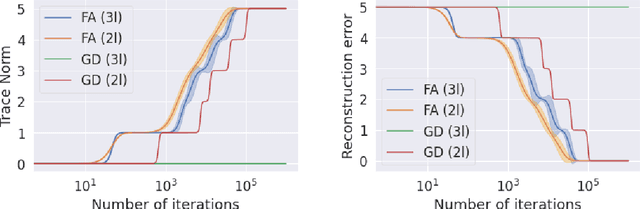
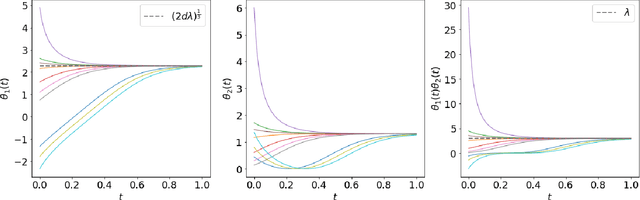
We theoretically analyze the Feedback Alignment (FA) algorithm, an efficient alternative to backpropagation for training neural networks. We provide convergence guarantees with rates for deep linear networks for both continuous and discrete dynamics. Additionally, we study incremental learning phenomena for shallow linear networks. Interestingly, certain specific initializations imply that negligible components are learned before the principal ones, thus potentially negatively affecting the effectiveness of such a learning algorithm; a phenomenon we classify as implicit anti-regularization. We also provide initialization schemes where the components of the problem are approximately learned by decreasing order of importance, thus providing a form of implicit regularization.
Extragradient Method: $O(1/K)$ Last-Iterate Convergence for Monotone Variational Inequalities and Connections With Cocoercivity
Oct 08, 2021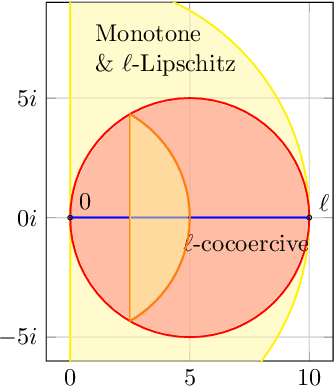
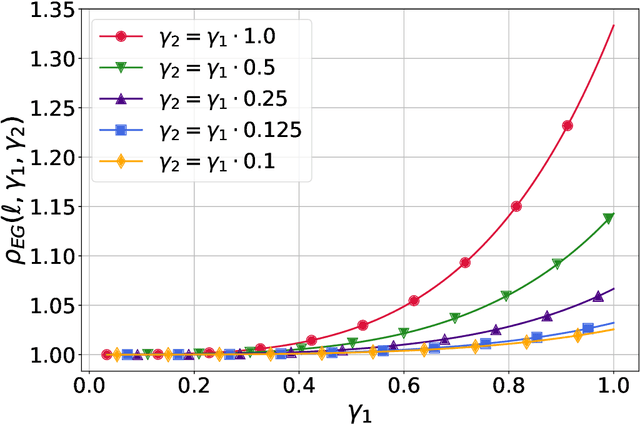
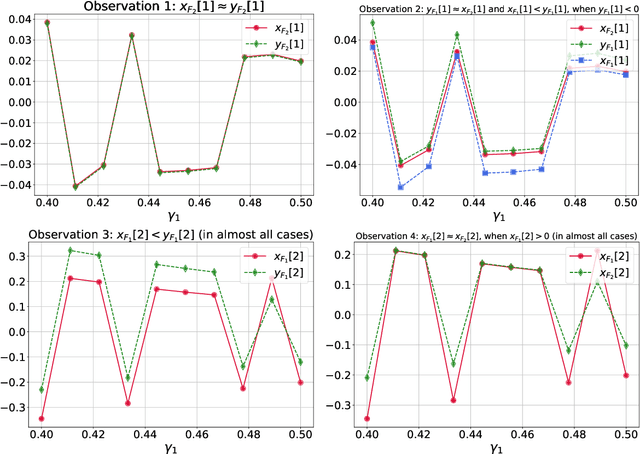
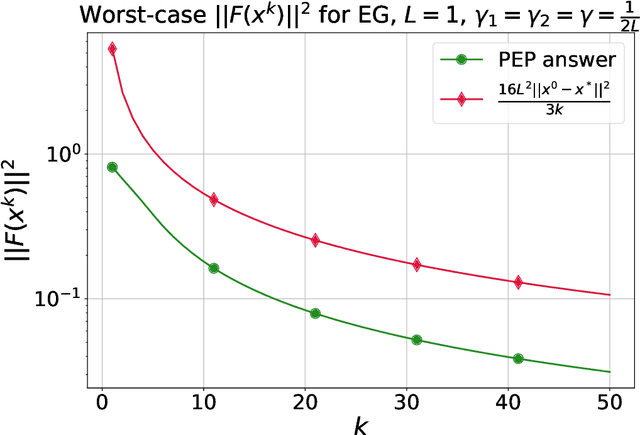
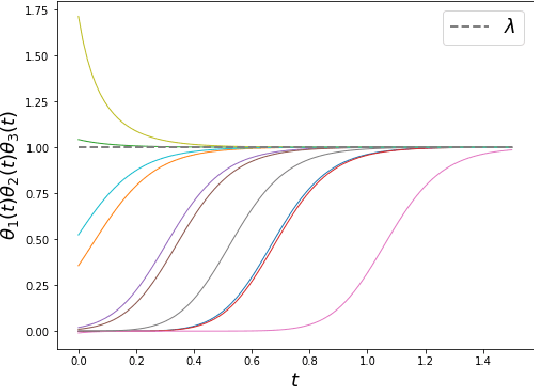
Extragradient method (EG) Korpelevich [1976] is one of the most popular methods for solving saddle point and variational inequalities problems (VIP). Despite its long history and significant attention in the optimization community, there remain important open questions about convergence of EG. In this paper, we resolve one of such questions and derive the first last-iterate $O(1/K)$ convergence rate for EG for monotone and Lipschitz VIP without any additional assumptions on the operator. The rate is given in terms of reducing the squared norm of the operator. Moreover, we establish several results on the (non-)cocoercivity of the update operators of EG, Optimistic Gradient Method, and Hamiltonian Gradient Method, when the original operator is monotone and Lipschitz.
Pick Your Battles: Interaction Graphs as Population-Level Objectives for Strategic Diversity
Oct 08, 2021Strategic diversity is often essential in games: in multi-player games, for example, evaluating a player against a diverse set of strategies will yield a more accurate estimate of its performance. Furthermore, in games with non-transitivities diversity allows a player to cover several winning strategies. However, despite the significance of strategic diversity, training agents that exhibit diverse behaviour remains a challenge. In this paper we study how to construct diverse populations of agents by carefully structuring how individuals within a population interact. Our approach is based on interaction graphs, which control the flow of information between agents during training and can encourage agents to specialise on different strategies, leading to improved overall performance. We provide evidence for the importance of diversity in multi-agent training and analyse the effect of applying different interaction graphs on the training trajectories, diversity and performance of populations in a range of games. This is an extended version of the long abstract published at AAMAS.
Stochastic Gradient Descent-Ascent and Consensus Optimization for Smooth Games: Convergence Analysis under Expected Co-coercivity
Jun 30, 2021
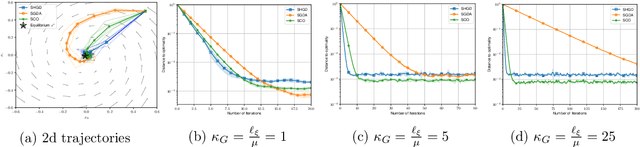
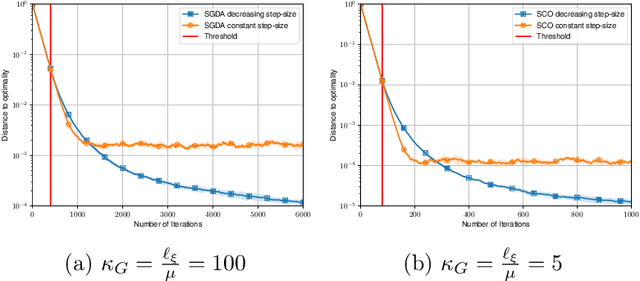
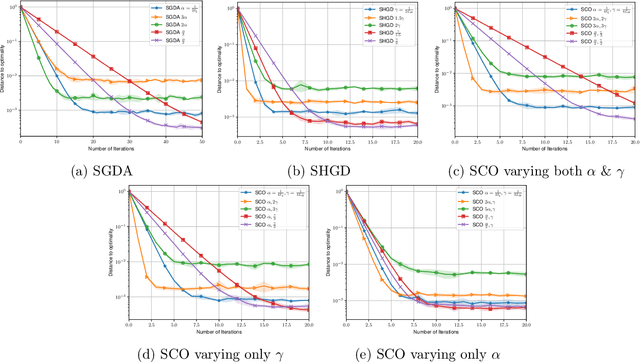
Two of the most prominent algorithms for solving unconstrained smooth games are the classical stochastic gradient descent-ascent (SGDA) and the recently introduced stochastic consensus optimization (SCO) (Mescheder et al., 2017). SGDA is known to converge to a stationary point for specific classes of games, but current convergence analyses require a bounded variance assumption. SCO is used successfully for solving large-scale adversarial problems, but its convergence guarantees are limited to its deterministic variant. In this work, we introduce the expected co-coercivity condition, explain its benefits, and provide the first last-iterate convergence guarantees of SGDA and SCO under this condition for solving a class of stochastic variational inequality problems that are potentially non-monotone. We prove linear convergence of both methods to a neighborhood of the solution when they use constant step-size, and we propose insightful stepsize-switching rules to guarantee convergence to the exact solution. In addition, our convergence guarantees hold under the arbitrary sampling paradigm, and as such, we give insights into the complexity of minibatching.
On the Convergence of Stochastic Extragradient for Bilinear Games with Restarted Iteration Averaging
Jun 30, 2021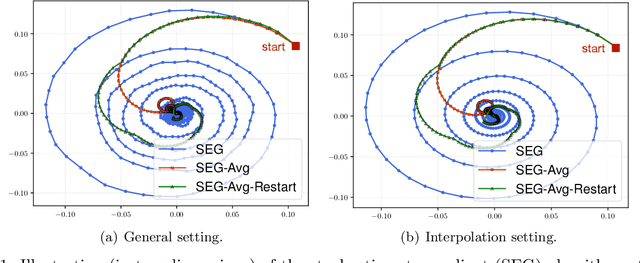
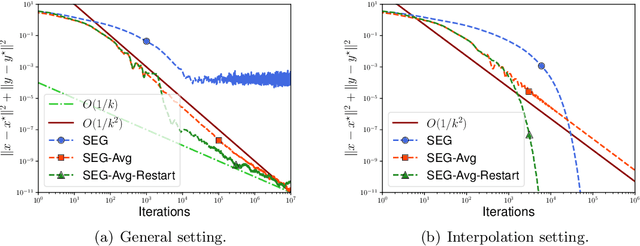
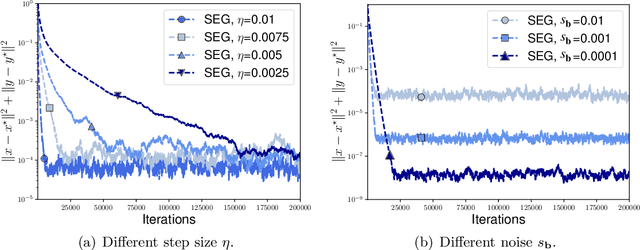
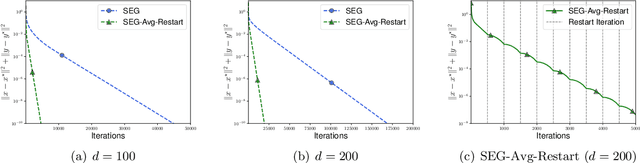
We study the stochastic bilinear minimax optimization problem, presenting an analysis of the Stochastic ExtraGradient (SEG) method with constant step size, and presenting variations of the method that yield favorable convergence. We first note that the last iterate of the basic SEG method only contracts to a fixed neighborhood of the Nash equilibrium, independent of the step size. This contrasts sharply with the standard setting of minimization where standard stochastic algorithms converge to a neighborhood that vanishes in proportion to the square-root (constant) step size. Under the same setting, however, we prove that when augmented with iteration averaging, SEG provably converges to the Nash equilibrium, and such a rate is provably accelerated by incorporating a scheduled restarting procedure. In the interpolation setting, we achieve an optimal convergence rate up to tight constants. We present numerical experiments that validate our theoretical findings and demonstrate the effectiveness of the SEG method when equipped with iteration averaging and restarting.
A single gradient step finds adversarial examples on random two-layers neural networks
Apr 09, 2021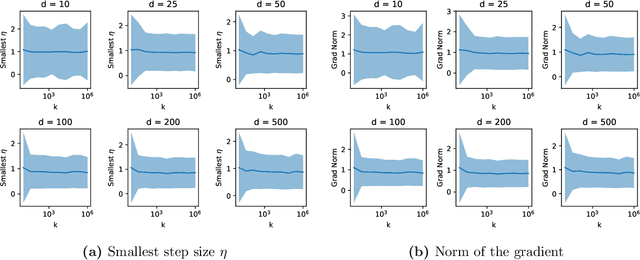
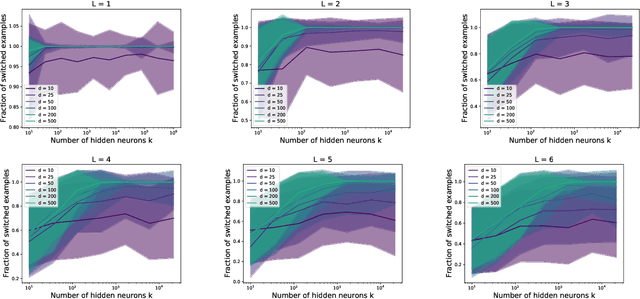
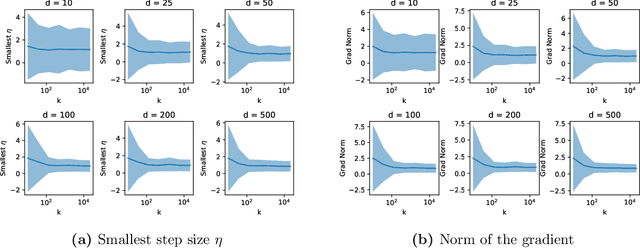
Daniely and Schacham recently showed that gradient descent finds adversarial examples on random undercomplete two-layers ReLU neural networks. The term "undercomplete" refers to the fact that their proof only holds when the number of neurons is a vanishing fraction of the ambient dimension. We extend their result to the overcomplete case, where the number of neurons is larger than the dimension (yet also subexponential in the dimension). In fact we prove that a single step of gradient descent suffices. We also show this result for any subexponential width random neural network with smooth activation function.