 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand3R: Online 4D Hand-Scene Reconstruction in the Wild
Feb 03, 2026For Embodied AI, jointly reconstructing dynamic hands and the dense scene context is crucial for understanding physical interaction. However, most existing methods recover isolated hands in local coordinates, overlooking the surrounding 3D environment. To address this, we present Hand3R, the first online framework for joint 4D hand-scene reconstruction from monocular video. Hand3R synergizes a pre-trained hand expert with a 4D scene foundation model via a scene-aware visual prompting mechanism. By injecting high-fidelity hand priors into a persistent scene memory, our approach enables simultaneous reconstruction of accurate hand meshes and dense metric-scale scene geometry in a single forward pass. Experiments demonstrate that Hand3R bypasses the reliance on offline optimization and delivers competitive performance in both local hand reconstruction and global positioning.
$M^3-Verse$: A "Spot the Difference" Challenge for Large Multimodal Models
Dec 21, 2025Modern Large Multimodal Models (LMMs) have demonstrated extraordinary ability in static image and single-state spatial-temporal understanding. However, their capacity to comprehend the dynamic changes of objects within a shared spatial context between two distinct video observations, remains largely unexplored. This ability to reason about transformations within a consistent environment is particularly crucial for advancements in the field of spatial intelligence. In this paper, we introduce $M^3-Verse$, a Multi-Modal, Multi-State, Multi-Dimensional benchmark, to formally evaluate this capability. It is built upon paired videos that provide multi-perspective observations of an indoor scene before and after a state change. The benchmark contains a total of 270 scenes and 2,932 questions, which are categorized into over 50 subtasks that probe 4 core capabilities. We evaluate 16 state-of-the-art LMMs and observe their limitations in tracking state transitions. To address these challenges, we further propose a simple yet effective baseline that achieves significant performance improvements in multi-state perception. $M^3-Verse$ thus provides a challenging new testbed to catalyze the development of next-generation models with a more holistic understanding of our dynamic visual world. You can get the construction pipeline from https://github.com/Wal-K-aWay/M3-Verse_pipeline and full benchmark data from https://www.modelscope.cn/datasets/WalKaWay/M3-Verse.
RecurGS: Interactive Scene Modeling via Discrete-State Recurrent Gaussian Fusion
Dec 20, 2025Recent advances in 3D scene representations have enabled high-fidelity novel view synthesis, yet adapting to discrete scene changes and constructing interactive 3D environments remain open challenges in vision and robotics. Existing approaches focus solely on updating a single scene without supporting novel-state synthesis. Others rely on diffusion-based object-background decoupling that works on one state at a time and cannot fuse information across multiple observations. To address these limitations, we introduce RecurGS, a recurrent fusion framework that incrementally integrates discrete Gaussian scene states into a single evolving representation capable of interaction. RecurGS detects object-level changes across consecutive states, aligns their geometric motion using semantic correspondence and Lie-algebra based SE(3) refinement, and performs recurrent updates that preserve historical structures through replay supervision. A voxelized, visibility-aware fusion module selectively incorporates newly observed regions while keeping stable areas fixed, mitigating catastrophic forgetting and enabling efficient long-horizon updates. RecurGS supports object-level manipulation, synthesizes novel scene states without requiring additional scans, and maintains photorealistic fidelity across evolving environments. Extensive experiments across synthetic and real-world datasets demonstrate that our framework delivers high-quality reconstructions with substantially improved update efficiency, providing a scalable step toward continuously interactive Gaussian worlds.
CORE: Compact Object-centric REpresentations as a New Paradigm for Token Merging in LVLMs
Nov 18, 2025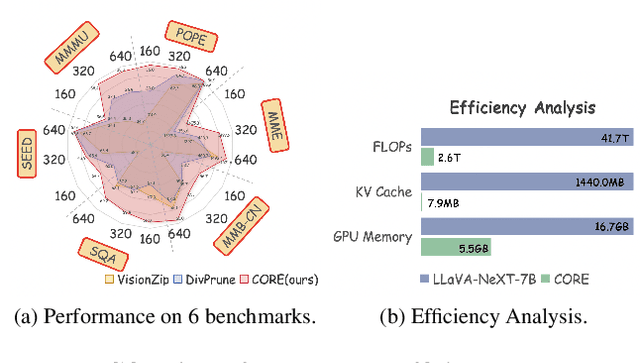
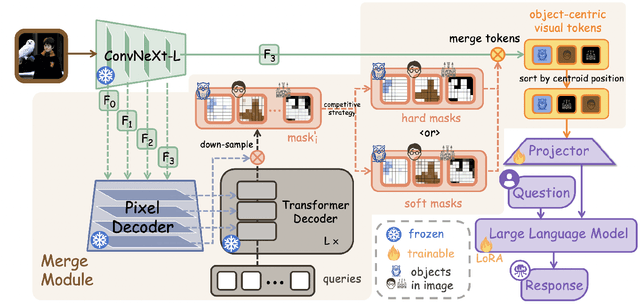
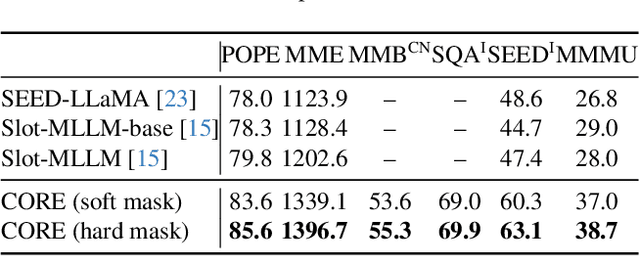
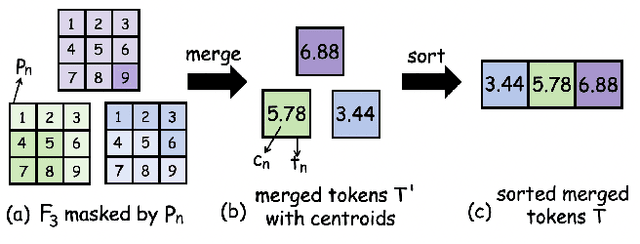
Large Vision-Language Models (LVLMs) usually suffer from prohibitive computational and memory costs due to the quadratic growth of visual tokens with image resolution. Existing token compression methods, while varied, often lack a high-level semantic understanding, leading to suboptimal merges, information redundancy, or context loss. To address these limitations, we introduce CORE (Compact Object-centric REpresentations), a new paradigm for visual token compression. CORE leverages an efficient segmentation decoder to generate object masks, which serve as a high-level semantic prior to guide the merging of visual tokens into a compact set of object-centric representations. Furthermore, a novel centroid-guided sorting mechanism restores a coherent spatial order to the merged tokens, preserving vital positional information. Extensive experiments show that CORE not only establishes a new state-of-the-art on six authoritative benchmarks for fixed-rate compression, but also achieves dramatic efficiency gains in adaptive-rate settings. Even under extreme compression, after aggressively retaining with only 2.2% of all visual tokens, CORE still maintains 97.4% of baseline performance. Our work demonstrates the superiority of object-centric representations for efficient and effective LVLM processing.
IGFuse: Interactive 3D Gaussian Scene Reconstruction via Multi-Scans Fusion
Aug 18, 2025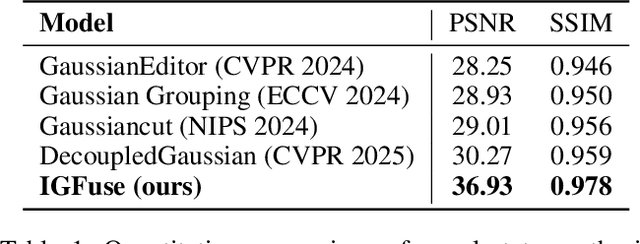
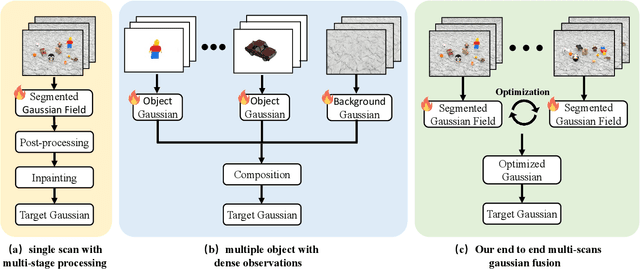
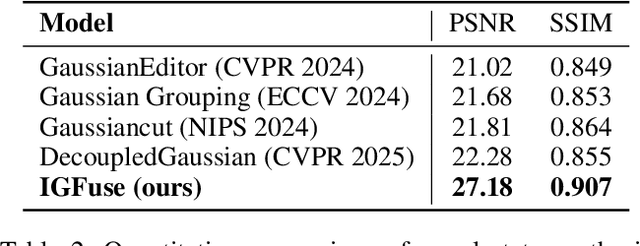
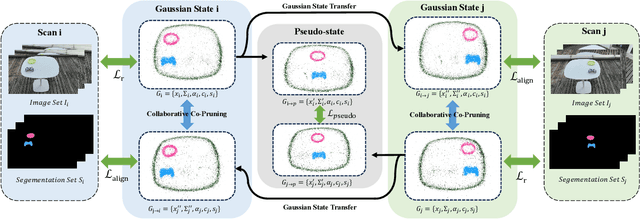
Reconstructing complete and interactive 3D scenes remains a fundamental challenge in computer vision and robotics, particularly due to persistent object occlusions and limited sensor coverage. Multiview observations from a single scene scan often fail to capture the full structural details. Existing approaches typically rely on multi stage pipelines, such as segmentation, background completion, and inpainting or require per-object dense scanning, both of which are error-prone, and not easily scalable. We propose IGFuse, a novel framework that reconstructs interactive Gaussian scene by fusing observations from multiple scans, where natural object rearrangement between captures reveal previously occluded regions. Our method constructs segmentation aware Gaussian fields and enforces bi-directional photometric and semantic consistency across scans. To handle spatial misalignments, we introduce a pseudo-intermediate scene state for unified alignment, alongside collaborative co-pruning strategies to refine geometry. IGFuse enables high fidelity rendering and object level scene manipulation without dense observations or complex pipelines. Extensive experiments validate the framework's strong generalization to novel scene configurations, demonstrating its effectiveness for real world 3D reconstruction and real-to-simulation transfer. Our project page is available online.
Understanding Dynamic Scenes in Ego Centric 4D Point Clouds
Aug 12, 2025Understanding dynamic 4D scenes from an egocentric perspective-modeling changes in 3D spatial structure over time-is crucial for human-machine interaction, autonomous navigation, and embodied intelligence. While existing egocentric datasets contain dynamic scenes, they lack unified 4D annotations and task-driven evaluation protocols for fine-grained spatio-temporal reasoning, especially on motion of objects and human, together with their interactions. To address this gap, we introduce EgoDynamic4D, a novel QA benchmark on highly dynamic scenes, comprising RGB-D video, camera poses, globally unique instance masks, and 4D bounding boxes. We construct 927K QA pairs accompanied by explicit Chain-of-Thought (CoT), enabling verifiable, step-by-step spatio-temporal reasoning. We design 12 dynamic QA tasks covering agent motion, human-object interaction, trajectory prediction, relation understanding, and temporal-causal reasoning, with fine-grained, multidimensional metrics. To tackle these tasks, we propose an end-to-end spatio-temporal reasoning framework that unifies dynamic and static scene information, using instance-aware feature encoding, time and camera encoding, and spatially adaptive down-sampling to compress large 4D scenes into token sequences manageable by LLMs. Experiments on EgoDynamic4D show that our method consistently outperforms baselines, validating the effectiveness of multimodal temporal modeling for egocentric dynamic scene understanding.
X-MoGen: Unified Motion Generation across Humans and Animals
Aug 07, 2025Text-driven motion generation has attracted increasing attention due to its broad applications in virtual reality, animation, and robotics. While existing methods typically model human and animal motion separately, a joint cross-species approach offers key advantages, such as a unified representation and improved generalization. However, morphological differences across species remain a key challenge, often compromising motion plausibility. To address this, we propose \textbf{X-MoGen}, the first unified framework for cross-species text-driven motion generation covering both humans and animals. X-MoGen adopts a two-stage architecture. First, a conditional graph variational autoencoder learns canonical T-pose priors, while an autoencoder encodes motion into a shared latent space regularized by morphological loss. In the second stage, we perform masked motion modeling to generate motion embeddings conditioned on textual descriptions. During training, a morphological consistency module is employed to promote skeletal plausibility across species. To support unified modeling, we construct \textbf{UniMo4D}, a large-scale dataset of 115 species and 119k motion sequences, which integrates human and animal motions under a shared skeletal topology for joint training. Extensive experiments on UniMo4D demonstrate that X-MoGen outperforms state-of-the-art methods on both seen and unseen species.
AuroraLong: Bringing RNNs Back to Efficient Open-Ended Video Understanding
Jul 03, 2025The challenge of long video understanding lies in its high computational complexity and prohibitive memory cost, since the memory and computation required by transformer-based LLMs scale quadratically with input sequence length. We propose AuroraLong to address this challenge by replacing the LLM component in MLLMs with a linear RNN language model that handles input sequence of arbitrary length with constant-size hidden states. To further increase throughput and efficiency, we combine visual token merge with linear RNN models by reordering the visual tokens by their sizes in ascending order. Despite having only 2B parameters and being trained exclusively on public data, AuroraLong achieves performance comparable to Transformer-based models of similar size trained on private datasets across multiple video benchmarks. This demonstrates the potential of efficient, linear RNNs to democratize long video understanding by lowering its computational entry barrier. To our best knowledge, we are the first to use a linear RNN based LLM backbone in a LLaVA-like model for open-ended video understanding.
FreeQ-Graph: Free-form Querying with Semantic Consistent Scene Graph for 3D Scene Understanding
Jun 16, 2025Semantic querying in complex 3D scenes through free-form language presents a significant challenge. Existing 3D scene understanding methods use large-scale training data and CLIP to align text queries with 3D semantic features. However, their reliance on predefined vocabulary priors from training data hinders free-form semantic querying. Besides, recent advanced methods rely on LLMs for scene understanding but lack comprehensive 3D scene-level information and often overlook the potential inconsistencies in LLM-generated outputs. In our paper, we propose FreeQ-Graph, which enables Free-form Querying with a semantic consistent scene Graph for 3D scene understanding. The core idea is to encode free-form queries from a complete and accurate 3D scene graph without predefined vocabularies, and to align them with 3D consistent semantic labels, which accomplished through three key steps. We initiate by constructing a complete and accurate 3D scene graph that maps free-form objects and their relations through LLM and LVLM guidance, entirely free from training data or predefined priors. Most importantly, we align graph nodes with accurate semantic labels by leveraging 3D semantic aligned features from merged superpoints, enhancing 3D semantic consistency. To enable free-form semantic querying, we then design an LLM-based reasoning algorithm that combines scene-level and object-level information to intricate reasoning. We conducted extensive experiments on 3D semantic grounding, segmentation, and complex querying tasks, while also validating the accuracy of graph generation. Experiments on 6 datasets show that our model excels in both complex free-form semantic queries and intricate relational reasoning.
Hi-LSplat: Hierarchical 3D Language Gaussian Splatting
Jun 07, 2025



Modeling 3D language fields with Gaussian Splatting for open-ended language queries has recently garnered increasing attention. However, recent 3DGS-based models leverage view-dependent 2D foundation models to refine 3D semantics but lack a unified 3D representation, leading to view inconsistencies. Additionally, inherent open-vocabulary challenges cause inconsistencies in object and relational descriptions, impeding hierarchical semantic understanding. In this paper, we propose Hi-LSplat, a view-consistent Hierarchical Language Gaussian Splatting work for 3D open-vocabulary querying. To achieve view-consistent 3D hierarchical semantics, we first lift 2D features to 3D features by constructing a 3D hierarchical semantic tree with layered instance clustering, which addresses the view inconsistency issue caused by 2D semantic features. Besides, we introduce instance-wise and part-wise contrastive losses to capture all-sided hierarchical semantic representations. Notably, we construct two hierarchical semantic datasets to better assess the model's ability to distinguish different semantic levels. Extensive experiments highlight our method's superiority in 3D open-vocabulary segmentation and localization. Its strong performance on hierarchical semantic datasets underscores its ability to capture complex hierarchical semantics within 3D scenes.