 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Ellipse Fitting Based on Maximum Correntropy Criterion With Variable Center
Oct 24, 2022The presence of outliers can significantly degrade the performance of ellipse fitting methods. We develop an ellipse fitting method that is robust to outliers based on the maximum correntropy criterion with variable center (MCC-VC), where a Laplacian kernel is used. For single ellipse fitting, we formulate a non-convex optimization problem to estimate the kernel bandwidth and center and divide it into two subproblems, each estimating one parameter. We design sufficiently accurate convex approximation to each subproblem such that computationally efficient closed-form solutions are obtained. The two subproblems are solved in an alternate manner until convergence is reached. We also investigate coupled ellipses fitting. While there exist multiple ellipses fitting methods that can be used for coupled ellipses fitting, we develop a couple ellipses fitting method by exploiting the special structure. Having unknown association between data points and ellipses, we introduce an association vector for each data point and formulate a non-convex mixed-integer optimization problem to estimate the data associations, which is approximately solved by relaxing it into a second-order cone program. Using the estimated data associations, we extend the proposed method to achieve the final coupled ellipses fitting. The proposed method is shown to have significantly better performance over the existing methods in both simulated data and real images.
Multi-scale Attention Network for Single Image Super-Resolution
Sep 29, 2022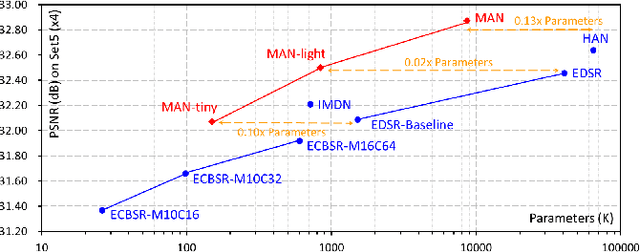
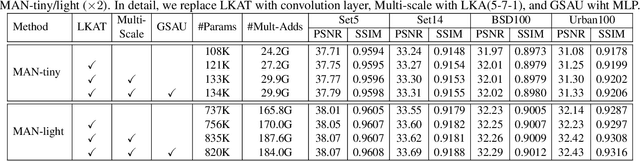

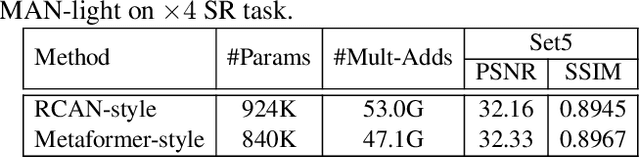
By exploiting large kernel decomposition and attention mechanisms, convolutional neural networks (CNN) can compete with transformer-based methods in many high-level computer vision tasks. However, due to the advantage of long-range modeling, the transformers with self-attention still dominate the low-level vision, including the super-resolution task. In this paper, we propose a CNN-based multi-scale attention network (MAN), which consists of multi-scale large kernel attention (MLKA) and a gated spatial attention unit (GSAU), to improve the performance of convolutional SR networks. Within our MLKA, we rectify LKA with multi-scale and gate schemes to obtain the abundant attention map at various granularity levels, therefore jointly aggregating global and local information and avoiding the potential blocking artifacts. In GSAU, we integrate gate mechanism and spatial attention to remove the unnecessary linear layer and aggregate informative spatial context. To confirm the effectiveness of our designs, we evaluate MAN with multiple complexities by simply stacking different numbers of MLKA and GSAU. Experimental results illustrate that our MAN can achieve varied trade-offs between state-of-the-art performance and computations. Code is available at https://github.com/icandle/MAN.
Acoustic SLAM based on the Direction-of-Arrival and the Direct-to-Reverberant Energy Ratio
Sep 22, 2022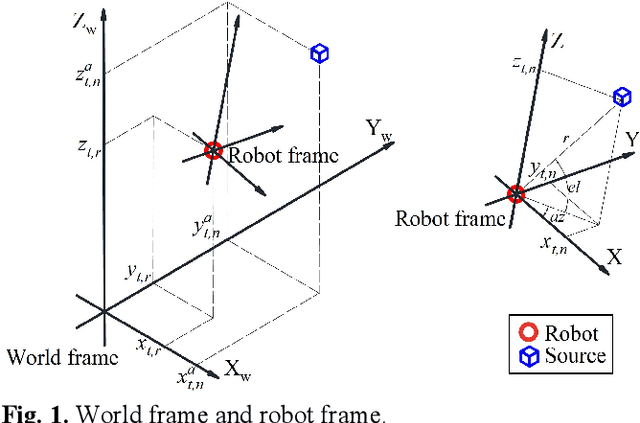
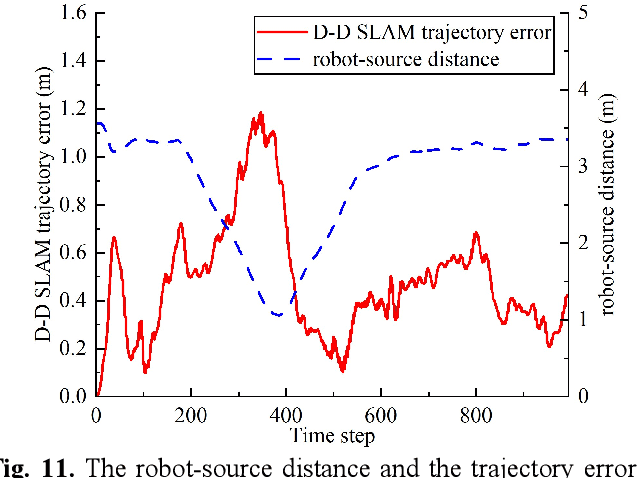
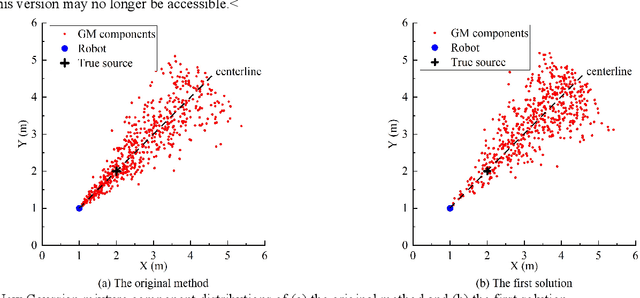
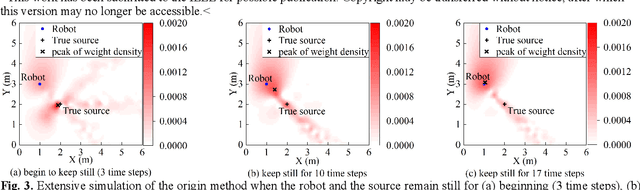
This paper proposes a new method that fuses acoustic measurements in the reverberation field and low-accuracy inertial measurement unit (IMU) motion reports for simultaneous localization and mapping (SLAM). Different from existing studies that only use acoustic data for direction-of-arrival (DoA) estimates, the source's distance from sensors is calculated with the direct-to-reverberant energy ratio (DRR) and applied as a new constraint to eliminate the nonlinear noise from motion reports. A particle filter is applied to estimate the critical distance, which is key for associating the source's distance with the DRR. A keyframe method is used to eliminate the deviation of the source position estimation toward the robot. The proposed DoA-DRR acoustic SLAM (D-D SLAM) is designed for three-dimensional motion and is suitable for most robots. The method is the first acoustic SLAM algorithm that has been validated on a real-world indoor scene dataset that contains only acoustic data and IMU measurements. Compared with previous methods, D-D SLAM has acceptable performance in locating the robot and building a source map from a real-world indoor dataset. The average location accuracy is 0.48 m, while the source position error converges to less than 0.25 m within 2.8 s. These results prove the effectiveness of D-D SLAM in real-world indoor scenes, which may be especially useful in search and rescue missions after disasters where the environment is foggy, i.e., unsuitable for light or laser irradiation.
Deep learning-based Crop Row Following for Infield Navigation of Agri-Robots
Sep 09, 2022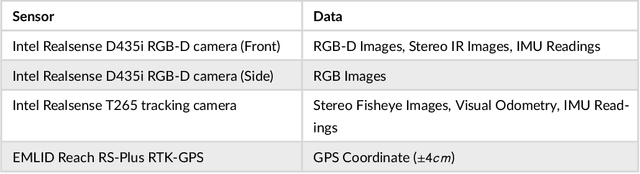
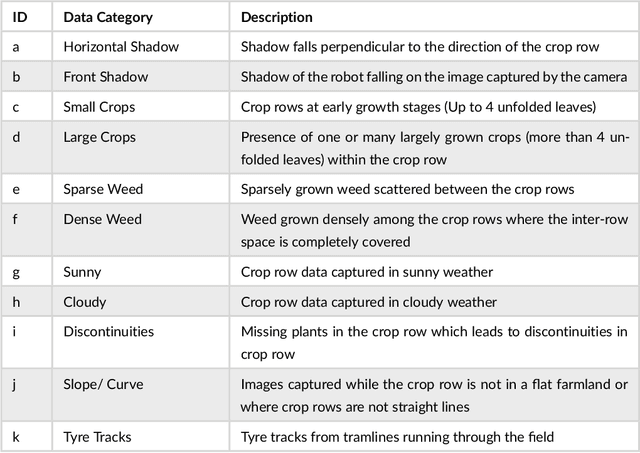
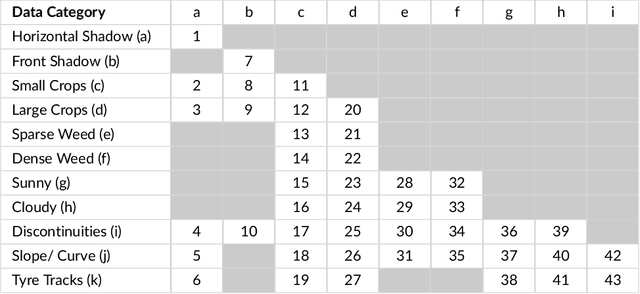
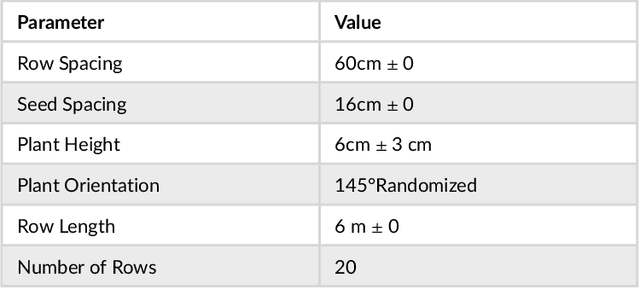
Autonomous navigation in agricultural environments is often challenged by varying field conditions that may arise in arable fields. The state-of-the-art solutions for autonomous navigation in these agricultural environments will require expensive hardware such as RTK-GPS. This paper presents a robust crop row detection algorithm that can withstand those variations while detecting crop rows for visual servoing. A dataset of sugar beet images was created with 43 combinations of 11 field variations found in arable fields. The novel crop row detection algorithm is tested both for the crop row detection performance and also the capability of visual servoing along a crop row. The algorithm only uses RGB images as input and a convolutional neural network was used to predict crop row masks. Our algorithm outperformed the baseline method which uses colour-based segmentation for all the combinations of field variations. We use a combined performance indicator that accounts for the angular and displacement errors of the crop row detection. Our algorithm exhibited the worst performance during the early growth stages of the crop.
Knowledge Distillation via the Target-aware Transformer
May 22, 2022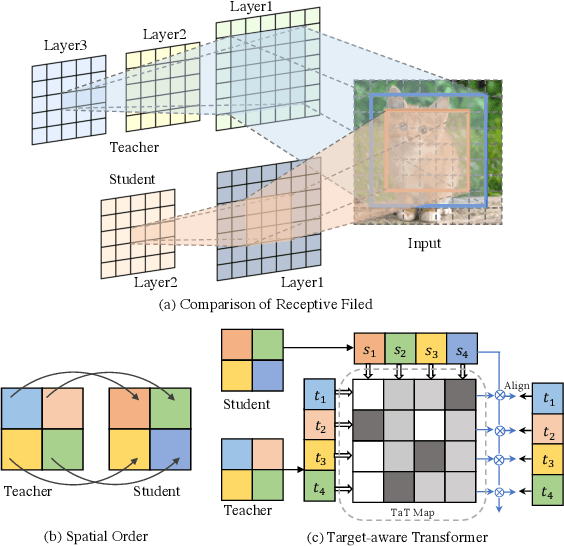
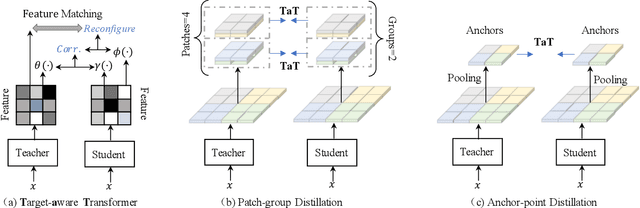

Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code will be released soon.
A Spatial-Temporal Attention Multi-Graph Convolution Network for Ride-Hailing Demand Prediction Based on Periodicity with Offset
Apr 08, 2022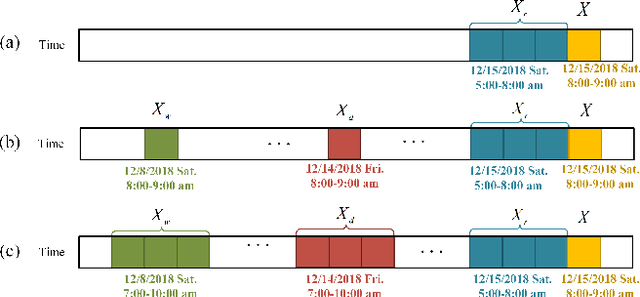
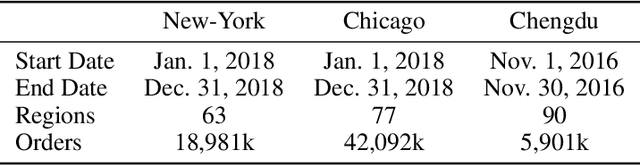
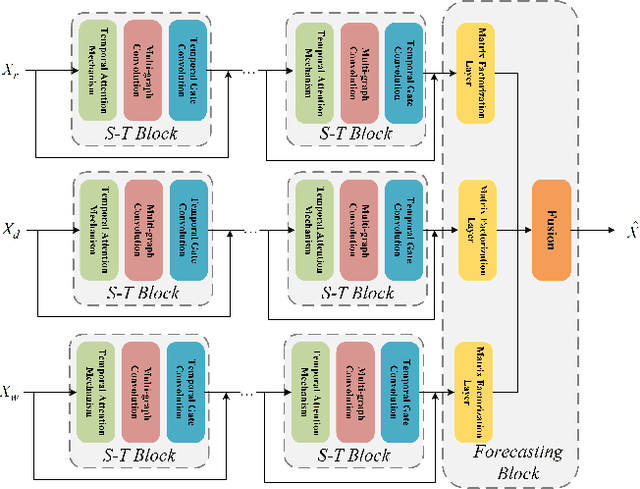
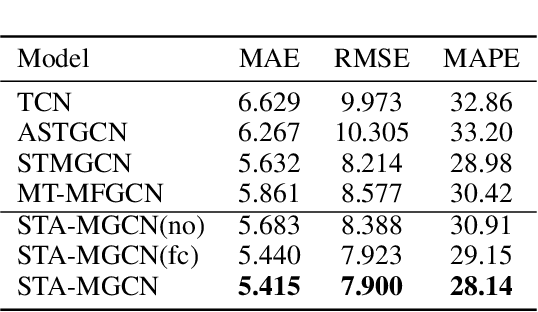
Ride-hailing service is becoming a leading part in urban transportation. To improve the efficiency of ride-hailing service, accurate prediction of transportation demand is a fundamental challenge. In this paper, we tackle this problem from both aspects of network structure and data-set formulation. For network design, we propose a spatial-temporal attention multi-graph convolution network (STA-MGCN). A spatial-temporal layer in STA-MGCN is developed to capture the temporal correlations by temporal attention mechanism and temporal gate convolution, and the spatial correlations by multigraph convolution. A feature cluster layer is introduced to learn latent regional functions and to reduce the computation burden. For the data-set formulation, we develop a novel approach which considers the transportation feature of periodicity with offset. Instead of only using history data during the same time period, the history order demand in forward and backward neighboring time periods from yesterday and last week are also included. Extensive experiments on the three real-world datasets of New-York, Chicago and Chengdu show that the proposed algorithm achieves the state-of-the-art performance for ride-hailing demand prediction.
Mixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech
Mar 31, 2022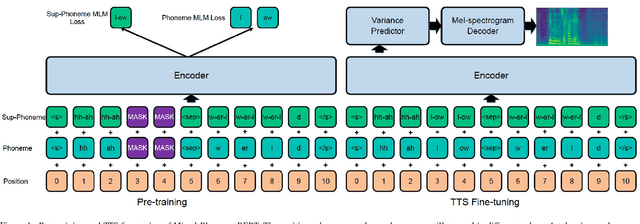
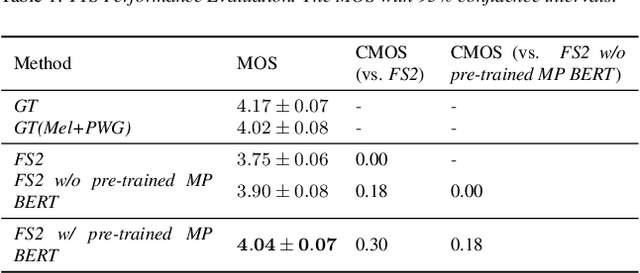

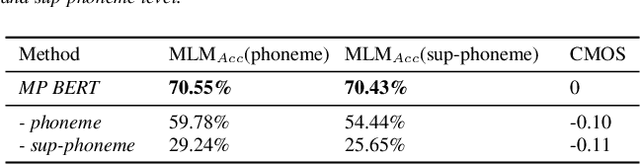
Recently, leveraging BERT pre-training to improve the phoneme encoder in text to speech (TTS) has drawn increasing attention. However, the works apply pre-training with character-based units to enhance the TTS phoneme encoder, which is inconsistent with the TTS fine-tuning that takes phonemes as input. Pre-training only with phonemes as input can alleviate the input mismatch but lack the ability to model rich representations and semantic information due to limited phoneme vocabulary. In this paper, we propose MixedPhoneme BERT, a novel variant of the BERT model that uses mixed phoneme and sup-phoneme representations to enhance the learning capability. Specifically, we merge the adjacent phonemes into sup-phonemes and combine the phoneme sequence and the merged sup-phoneme sequence as the model input, which can enhance the model capacity to learn rich contextual representations. Experiment results demonstrate that our proposed Mixed-Phoneme BERT significantly improves the TTS performance with 0.30 CMOS gain compared with the FastSpeech 2 baseline. The Mixed-Phoneme BERT achieves 3x inference speedup and similar voice quality to the previous TTS pre-trained model PnG BERT
Boosting Black-Box Adversarial Attacks with Meta Learning
Mar 28, 2022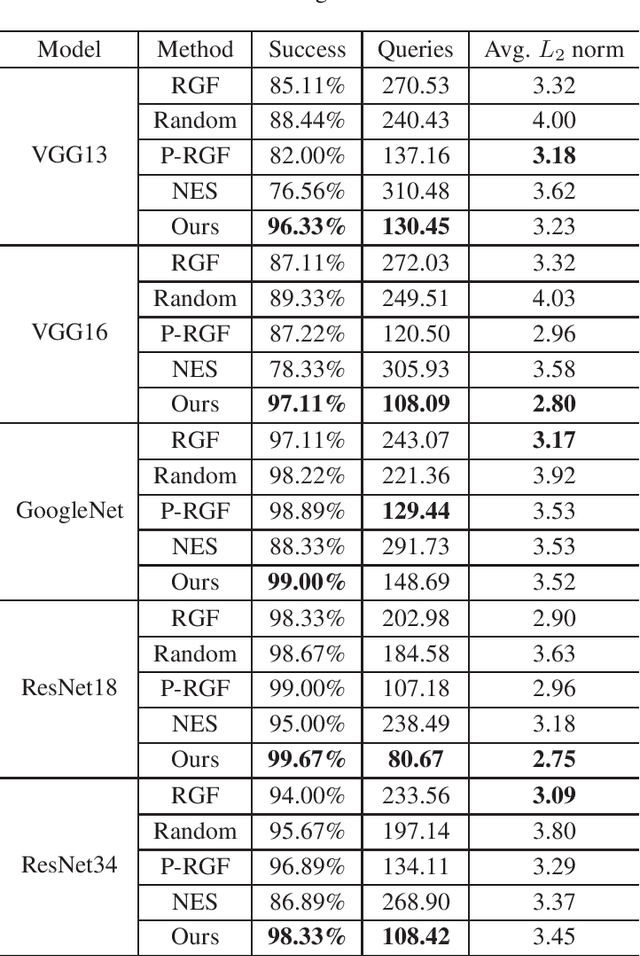

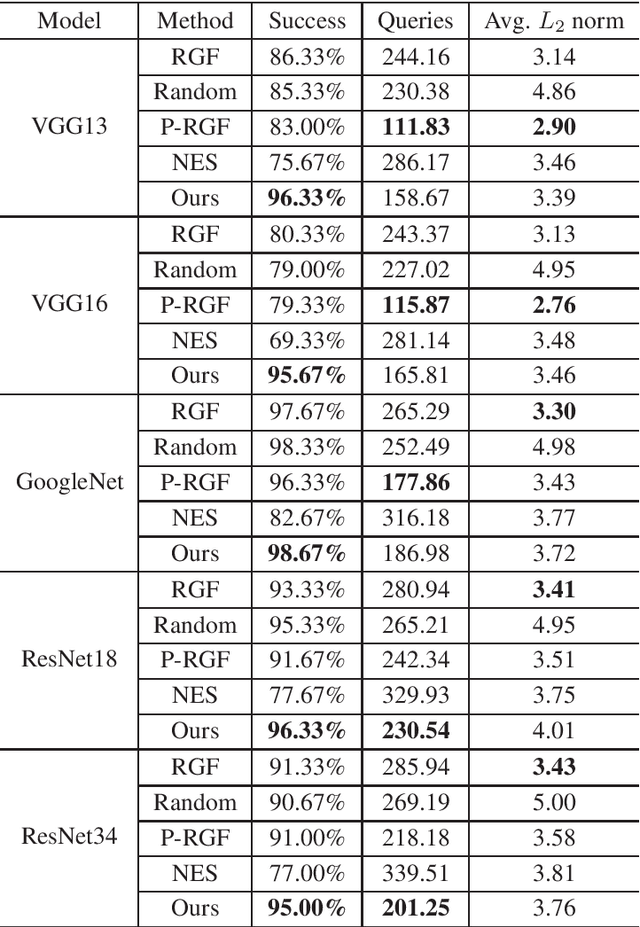
Deep neural networks (DNNs) have achieved remarkable success in diverse fields. However, it has been demonstrated that DNNs are very vulnerable to adversarial examples even in black-box settings. A large number of black-box attack methods have been proposed to in the literature. However, those methods usually suffer from low success rates and large query counts, which cannot fully satisfy practical purposes. In this paper, we propose a hybrid attack method which trains meta adversarial perturbations (MAPs) on surrogate models and performs black-box attacks by estimating gradients of the models. Our method uses the meta adversarial perturbation as an initialization and subsequently trains any black-box attack method for several epochs. Furthermore, the MAPs enjoy favorable transferability and universality, in the sense that they can be employed to boost performance of other black-box adversarial attack methods. Extensive experiments demonstrate that our method can not only improve the attack success rates, but also reduces the number of queries compared to other methods.
Jigsaw Puzzle: Selective Backdoor Attack to Subvert Malware Classifiers
Feb 11, 2022



Malware classifiers are subject to training-time exploitation due to the need to regularly retrain using samples collected from the wild. Recent work has demonstrated the feasibility of backdoor attacks against malware classifiers, and yet the stealthiness of such attacks is not well understood. In this paper, we investigate this phenomenon under the clean-label setting (i.e., attackers do not have complete control over the training or labeling process). Empirically, we show that existing backdoor attacks in malware classifiers are still detectable by recent defenses such as MNTD. To improve stealthiness, we propose a new attack, Jigsaw Puzzle (JP), based on the key observation that malware authors have little to no incentive to protect any other authors' malware but their own. As such, Jigsaw Puzzle learns a trigger to complement the latent patterns of the malware author's samples, and activates the backdoor only when the trigger and the latent pattern are pieced together in a sample. We further focus on realizable triggers in the problem space (e.g., software code) using bytecode gadgets broadly harvested from benign software. Our evaluation confirms that Jigsaw Puzzle is effective as a backdoor, remains stealthy against state-of-the-art defenses, and is a threat in realistic settings that depart from reasoning about feature-space only attacks. We conclude by exploring promising approaches to improve backdoor defenses.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Nov 19, 2021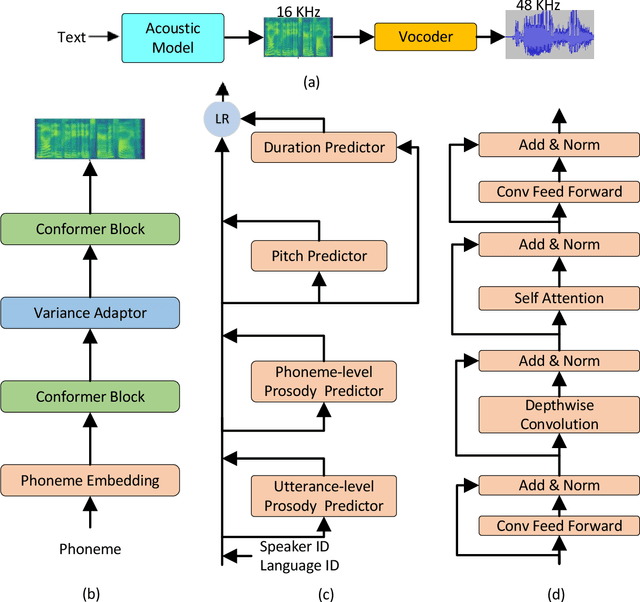
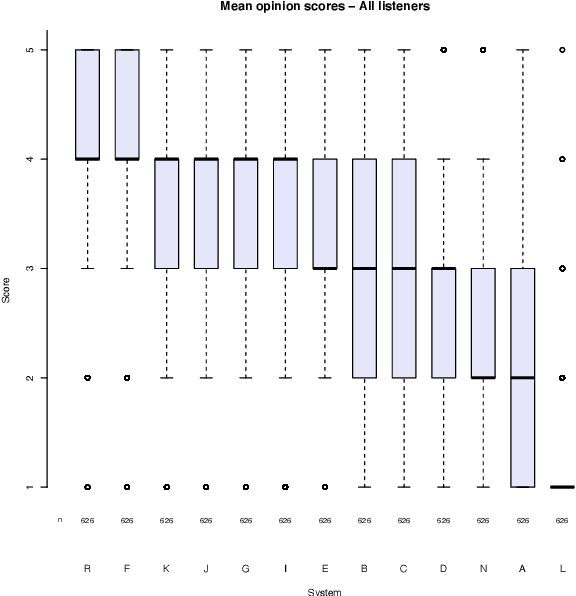
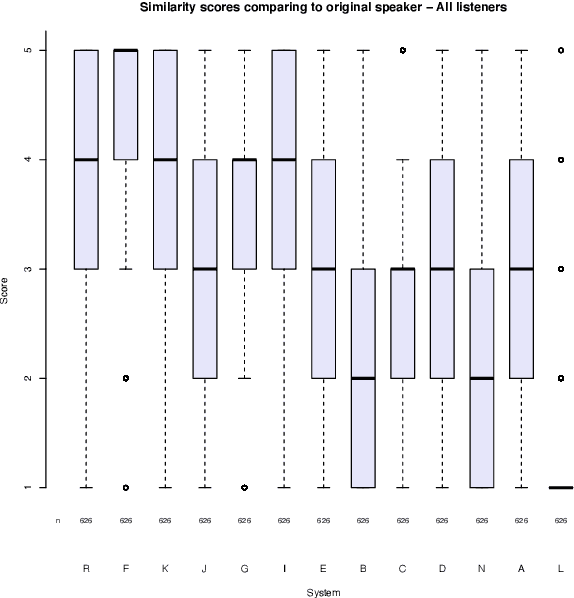
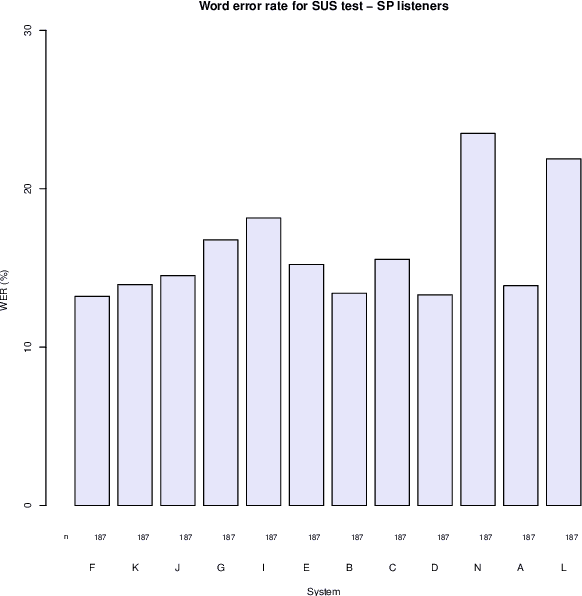
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system