 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Adversarial Robustness of Large-scale Audio Visual Learning
Mar 23, 2022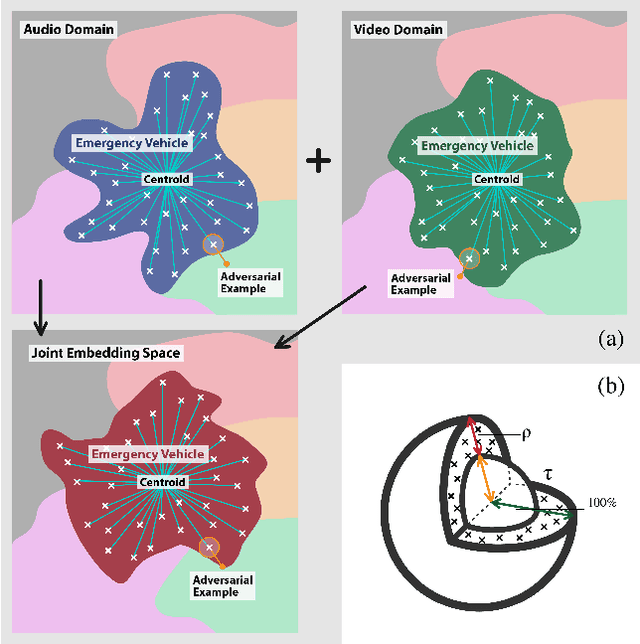
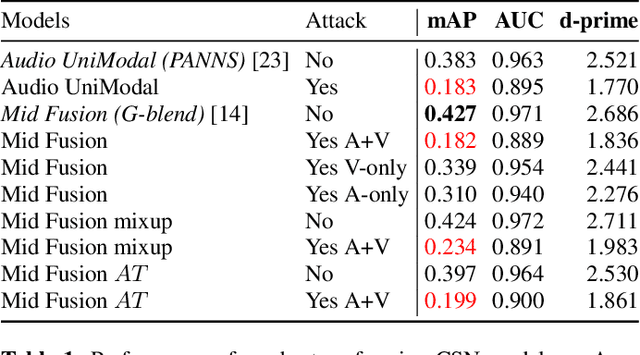
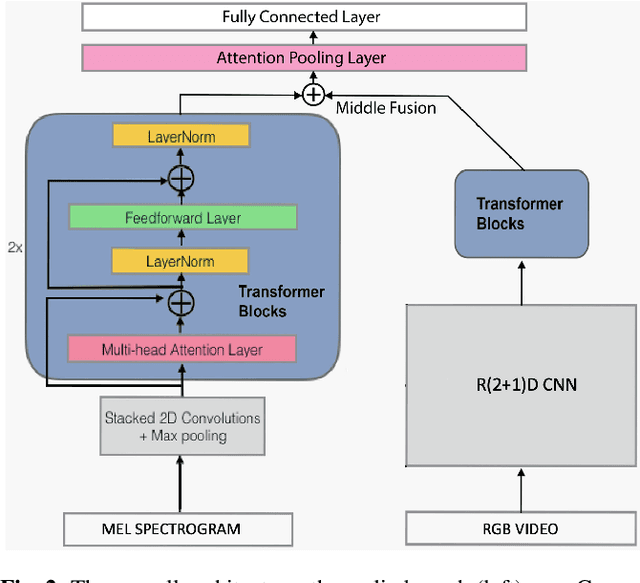
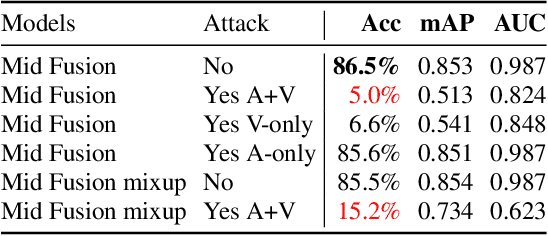
As audio-visual systems are being deployed for safety-critical tasks such as surveillance and malicious content filtering, their robustness remains an under-studied area. Existing published work on robustness either does not scale to large-scale dataset, or does not deal with multiple modalities. This work aims to study several key questions related to multi-modal learning through the lens of robustness: 1) Are multi-modal models necessarily more robust than uni-modal models? 2) How to efficiently measure the robustness of multi-modal learning? 3) How to fuse different modalities to achieve a more robust multi-modal model? To understand the robustness of the multi-modal model in a large-scale setting, we propose a density-based metric, and a convexity metric to efficiently measure the distribution of each modality in high-dimensional latent space. Our work provides a theoretical intuition together with empirical evidence showing how multi-modal fusion affects adversarial robustness through these metrics. We further devise a mix-up strategy based on our metrics to improve the robustness of the trained model. Our experiments on AudioSet and Kinetics-Sounds verify our hypothesis that multi-modal models are not necessarily more robust than their uni-modal counterparts in the face of adversarial examples. We also observe our mix-up trained method could achieve as much protection as traditional adversarial training, offering a computationally cheap alternative. Implementation: https://github.com/lijuncheng16/AudioSetDoneRight
Speech Summarization using Restricted Self-Attention
Oct 12, 2021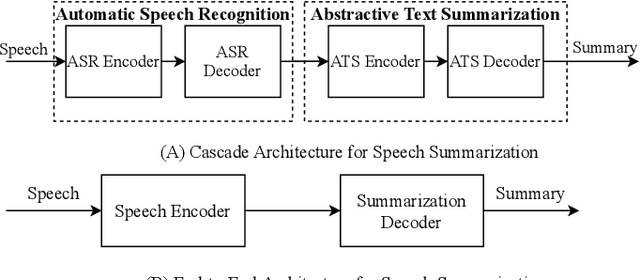
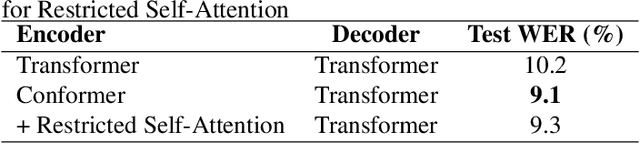
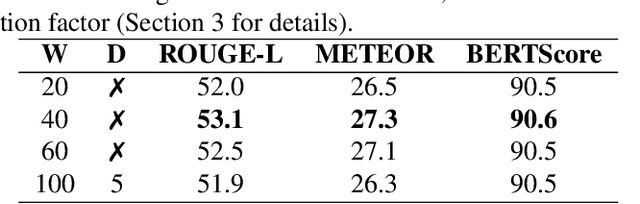
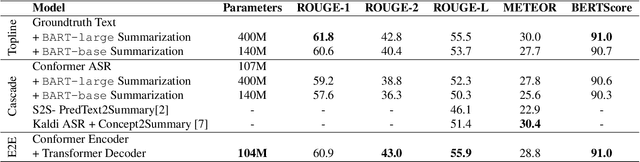
Speech summarization is typically performed by using a cascade of speech recognition and text summarization models. End-to-end modeling of speech summarization models is challenging due to memory and compute constraints arising from long input audio sequences. Recent work in document summarization has inspired methods to reduce the complexity of self-attentions, which enables transformer models to handle long sequences. In this work, we introduce a single model optimized end-to-end for speech summarization. We apply the restricted self-attention technique from text-based models to speech models to address the memory and compute constraints. We demonstrate that the proposed model learns to directly summarize speech for the How-2 corpus of instructional videos. The proposed end-to-end model outperforms the previously proposed cascaded model by 3 points absolute on ROUGE. Further, we consider the spoken language understanding task of predicting concepts from speech inputs and show that the proposed end-to-end model outperforms the cascade model by 4 points absolute F-1.
VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
Oct 01, 2021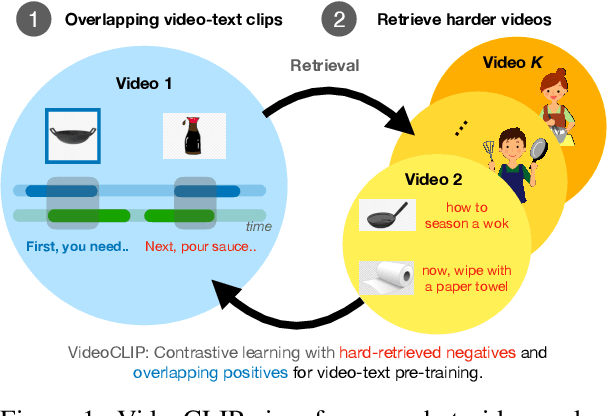
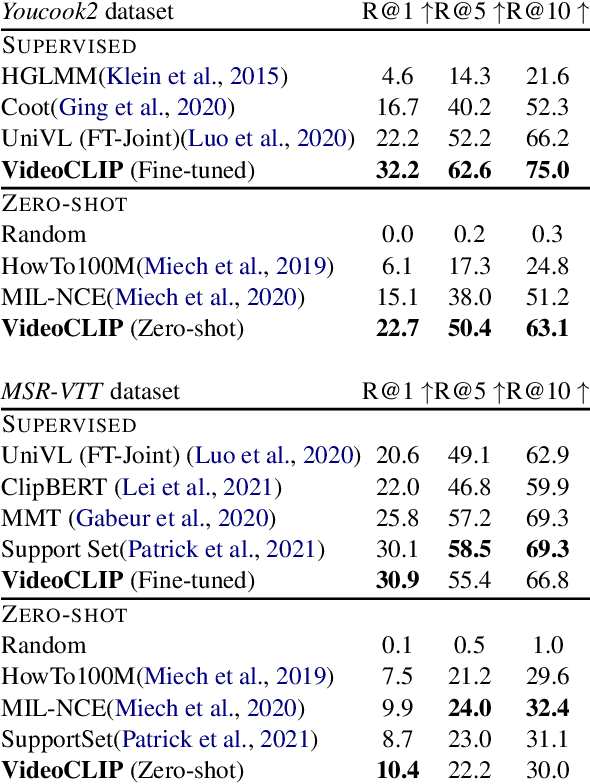
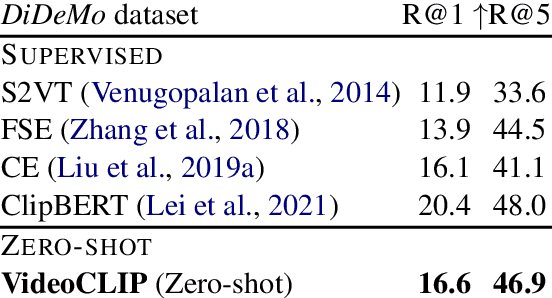
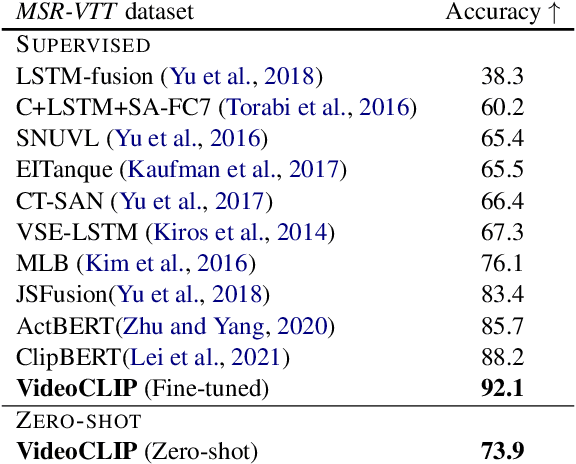
We present VideoCLIP, a contrastive approach to pre-train a unified model for zero-shot video and text understanding, without using any labels on downstream tasks. VideoCLIP trains a transformer for video and text by contrasting temporally overlapping positive video-text pairs with hard negatives from nearest neighbor retrieval. Our experiments on a diverse series of downstream tasks, including sequence-level text-video retrieval, VideoQA, token-level action localization, and action segmentation reveal state-of-the-art performance, surpassing prior work, and in some cases even outperforming supervised approaches. Code is made available at https://github.com/pytorch/fairseq/tree/main/examples/MMPT.
Differentiable Allophone Graphs for Language-Universal Speech Recognition
Jul 24, 2021

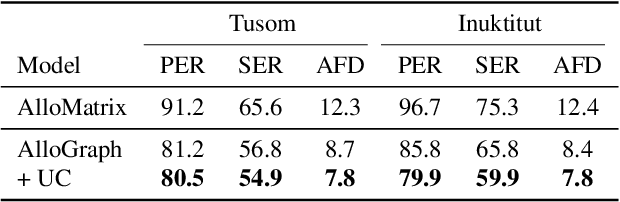
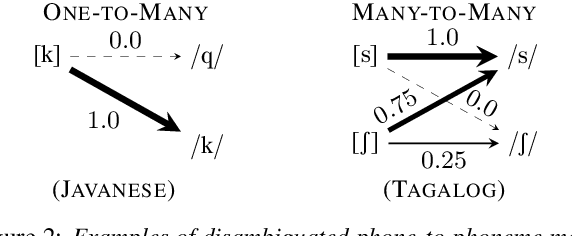
Building language-universal speech recognition systems entails producing phonological units of spoken sound that can be shared across languages. While speech annotations at the language-specific phoneme or surface levels are readily available, annotations at a universal phone level are relatively rare and difficult to produce. In this work, we present a general framework to derive phone-level supervision from only phonemic transcriptions and phone-to-phoneme mappings with learnable weights represented using weighted finite-state transducers, which we call differentiable allophone graphs. By training multilingually, we build a universal phone-based speech recognition model with interpretable probabilistic phone-to-phoneme mappings for each language. These phone-based systems with learned allophone graphs can be used by linguists to document new languages, build phone-based lexicons that capture rich pronunciation variations, and re-evaluate the allophone mappings of seen language. We demonstrate the aforementioned benefits of our proposed framework with a system trained on 7 diverse languages.
Rethinking End-to-End Evaluation of Decomposable Tasks: A Case Study on Spoken Language Understanding
Jun 29, 2021
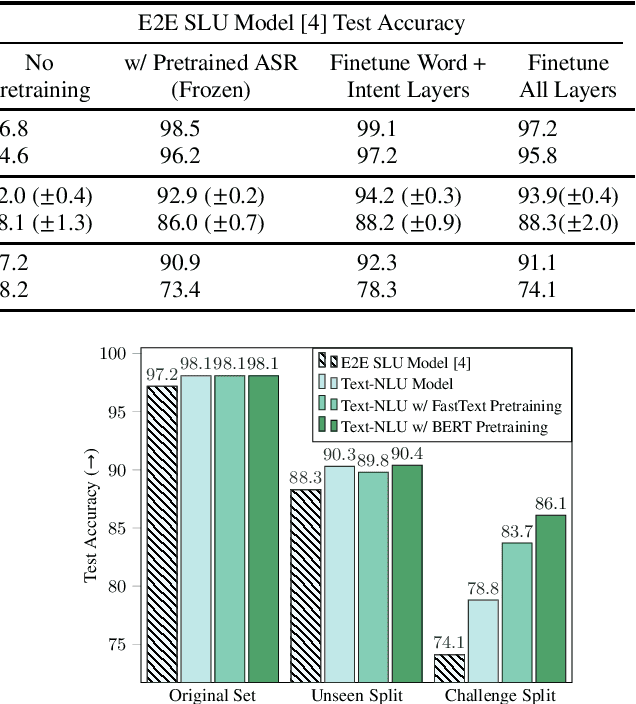
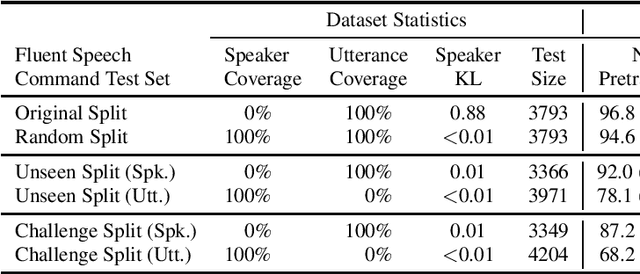

Decomposable tasks are complex and comprise of a hierarchy of sub-tasks. Spoken intent prediction, for example, combines automatic speech recognition and natural language understanding. Existing benchmarks, however, typically hold out examples for only the surface-level sub-task. As a result, models with similar performance on these benchmarks may have unobserved performance differences on the other sub-tasks. To allow insightful comparisons between competitive end-to-end architectures, we propose a framework to construct robust test sets using coordinate ascent over sub-task specific utility functions. Given a dataset for a decomposable task, our method optimally creates a test set for each sub-task to individually assess sub-components of the end-to-end model. Using spoken language understanding as a case study, we generate new splits for the Fluent Speech Commands and Snips SmartLights datasets. Each split has two test sets: one with held-out utterances assessing natural language understanding abilities, and one with held-out speakers to test speech processing skills. Our splits identify performance gaps up to 10% between end-to-end systems that were within 1% of each other on the original test sets. These performance gaps allow more realistic and actionable comparisons between different architectures, driving future model development. We release our splits and tools for the community.
VLM: Task-agnostic Video-Language Model Pre-training for Video Understanding
May 20, 2021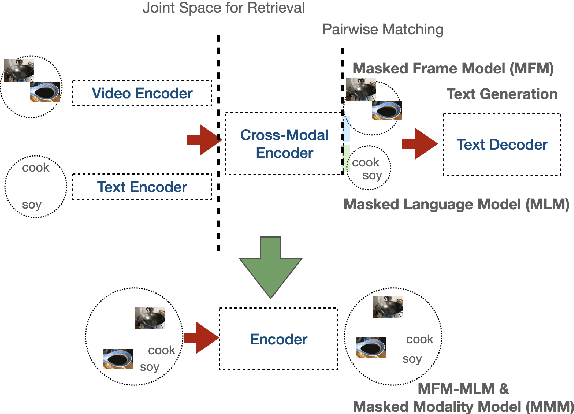

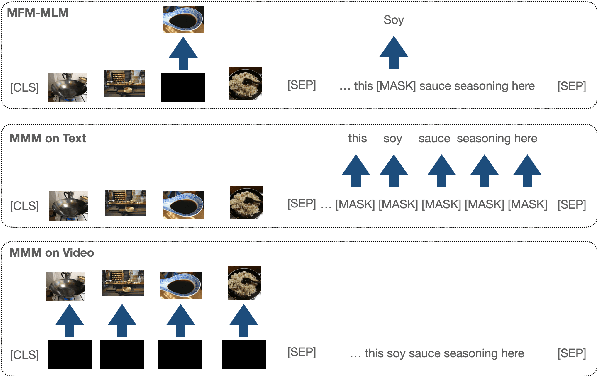
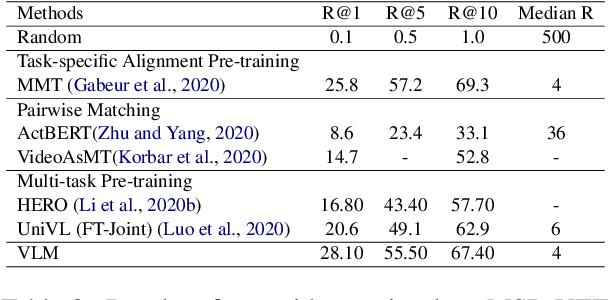
We present a simplified, task-agnostic multi-modal pre-training approach that can accept either video or text input, or both for a variety of end tasks. Existing pre-training are task-specific by adopting either a single cross-modal encoder that requires both modalities, limiting their use for retrieval-style end tasks or more complex multitask learning with two unimodal encoders, limiting early cross-modal fusion. We instead introduce new pretraining masking schemes that better mix across modalities (e.g. by forcing masks for text to predict the closest video embeddings) while also maintaining separability (e.g. unimodal predictions are sometimes required, without using all the input). Experimental results show strong performance across a wider range of tasks than any previous methods, often outperforming task-specific pre-training.
Searchable Hidden Intermediates for End-to-End Models of Decomposable Sequence Tasks
May 02, 2021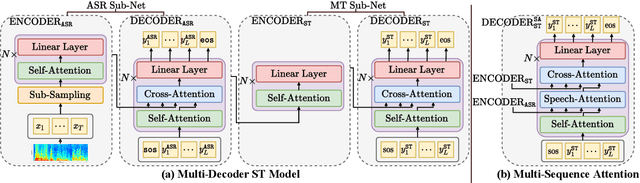
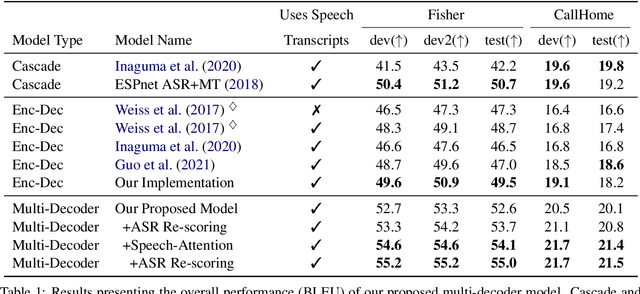
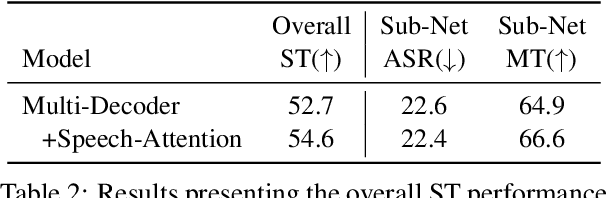
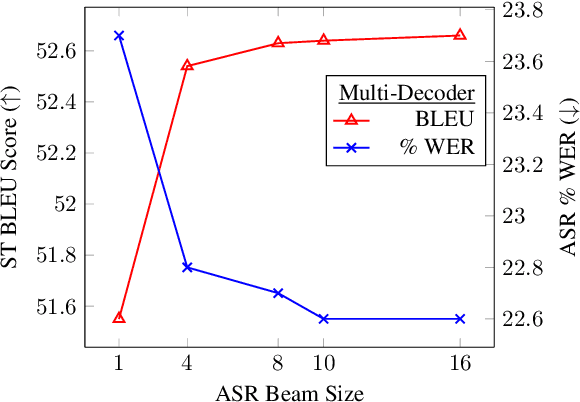
End-to-end approaches for sequence tasks are becoming increasingly popular. Yet for complex sequence tasks, like speech translation, systems that cascade several models trained on sub-tasks have shown to be superior, suggesting that the compositionality of cascaded systems simplifies learning and enables sophisticated search capabilities. In this work, we present an end-to-end framework that exploits compositionality to learn searchable hidden representations at intermediate stages of a sequence model using decomposed sub-tasks. These hidden intermediates can be improved using beam search to enhance the overall performance and can also incorporate external models at intermediate stages of the network to re-score or adapt towards out-of-domain data. One instance of the proposed framework is a Multi-Decoder model for speech translation that extracts the searchable hidden intermediates from a speech recognition sub-task. The model demonstrates the aforementioned benefits and outperforms the previous state-of-the-art by around +6 and +3 BLEU on the two test sets of Fisher-CallHome and by around +3 and +4 BLEU on the English-German and English-French test sets of MuST-C.
Multilingual Multimodal Pre-training for Zero-Shot Cross-Lingual Transfer of Vision-Language Models
Apr 15, 2021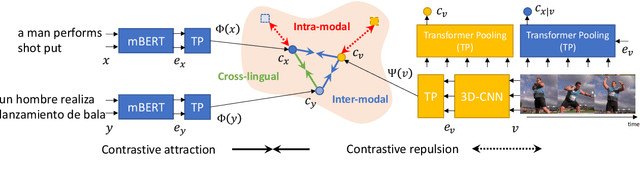

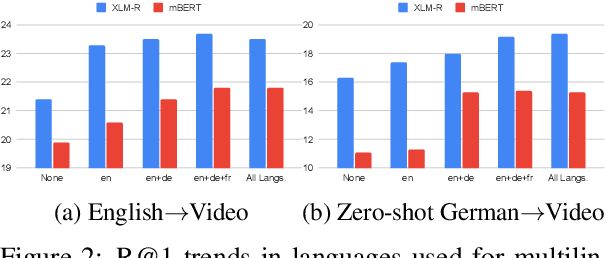
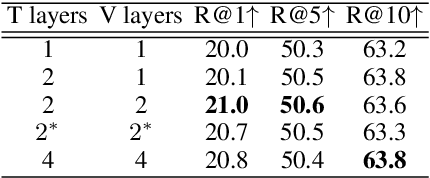
This paper studies zero-shot cross-lingual transfer of vision-language models. Specifically, we focus on multilingual text-to-video search and propose a Transformer-based model that learns contextualized multilingual multimodal embeddings. Under a zero-shot setting, we empirically demonstrate that performance degrades significantly when we query the multilingual text-video model with non-English sentences. To address this problem, we introduce a multilingual multimodal pre-training strategy, and collect a new multilingual instructional video dataset (MultiHowTo100M) for pre-training. Experiments on VTT show that our method significantly improves video search in non-English languages without additional annotations. Furthermore, when multilingual annotations are available, our method outperforms recent baselines by a large margin in multilingual text-to-video search on VTT and VATEX; as well as in multilingual text-to-image search on Multi30K. Our model and Multi-HowTo100M is available at http://github.com/berniebear/Multi-HT100M.
Self-supervised object detection from audio-visual correspondence
Apr 13, 2021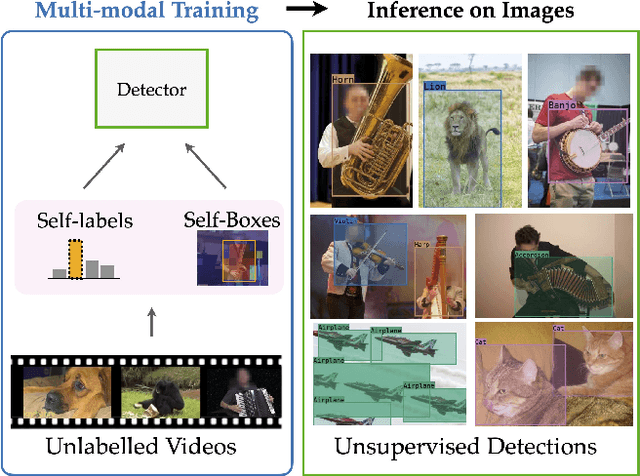
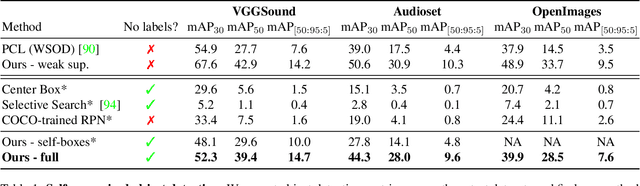
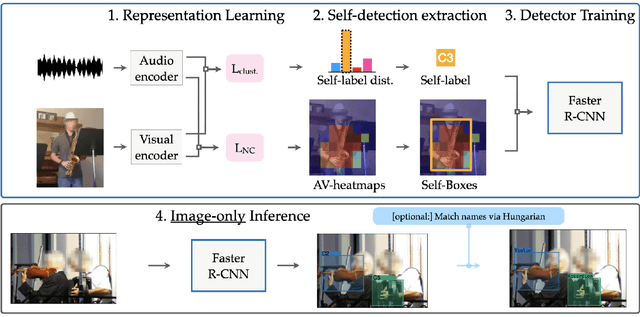
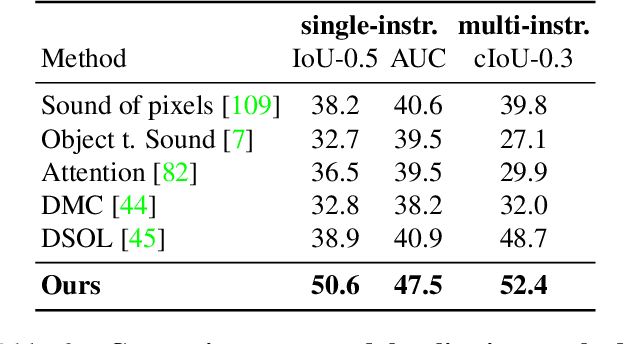
We tackle the problem of learning object detectors without supervision. Differently from weakly-supervised object detection, we do not assume image-level class labels. Instead, we extract a supervisory signal from audio-visual data, using the audio component to "teach" the object detector. While this problem is related to sound source localisation, it is considerably harder because the detector must classify the objects by type, enumerate each instance of the object, and do so even when the object is silent. We tackle this problem by first designing a self-supervised framework with a contrastive objective that jointly learns to classify and localise objects. Then, without using any supervision, we simply use these self-supervised labels and boxes to train an image-based object detector. With this, we outperform previous unsupervised and weakly-supervised detectors for the task of object detection and sound source localization. We also show that we can align this detector to ground-truth classes with as little as one label per pseudo-class, and show how our method can learn to detect generic objects that go beyond instruments, such as airplanes and cats.
Space-Time Crop & Attend: Improving Cross-modal Video Representation Learning
Mar 18, 2021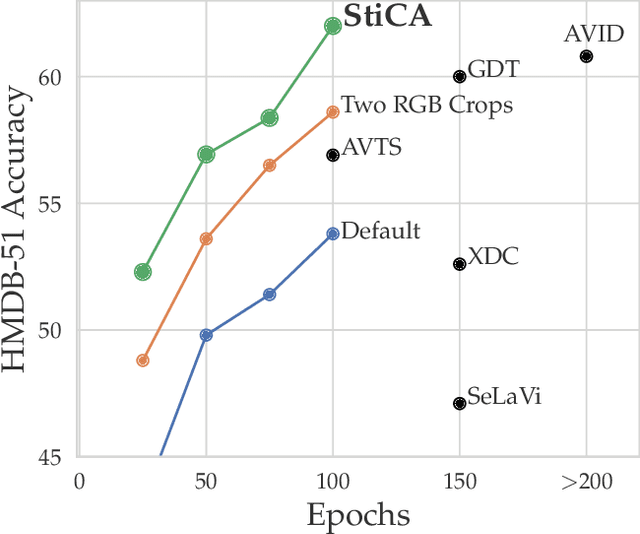
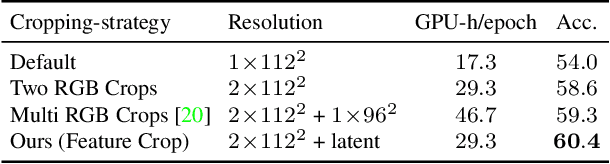
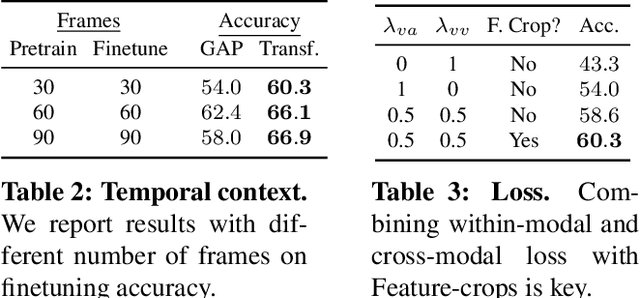
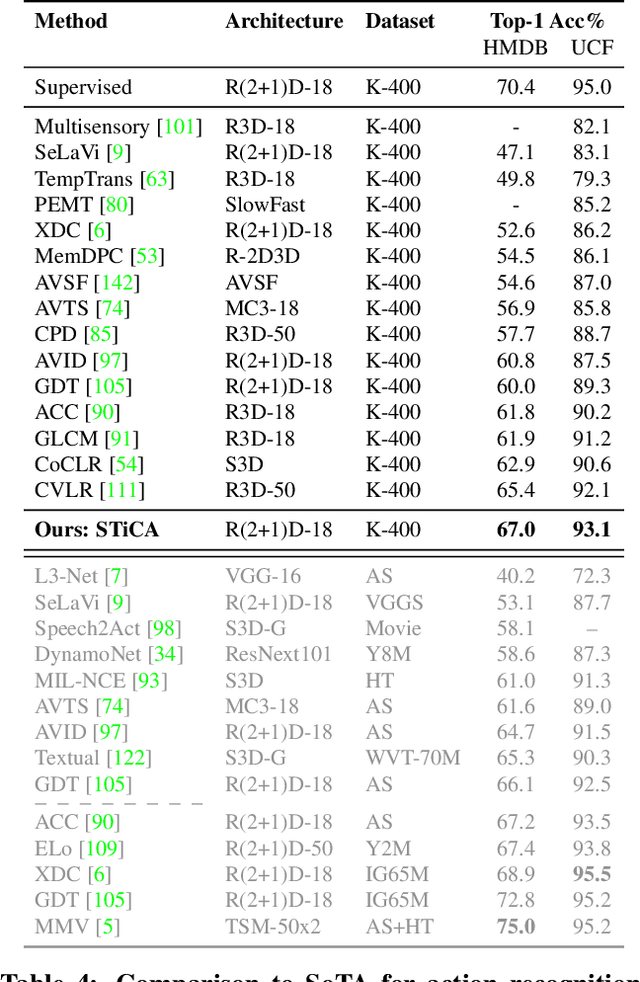
The quality of the image representations obtained from self-supervised learning depends strongly on the type of data augmentations used in the learning formulation. Recent papers have ported these methods from still images to videos and found that leveraging both audio and video signals yields strong gains; however, they did not find that spatial augmentations such as cropping, which are very important for still images, work as well for videos. In this paper, we improve these formulations in two ways unique to the spatio-temporal aspect of videos. First, for space, we show that spatial augmentations such as cropping do work well for videos too, but that previous implementations, due to the high processing and memory cost, could not do this at a scale sufficient for it to work well. To address this issue, we first introduce Feature Crop, a method to simulate such augmentations much more efficiently directly in feature space. Second, we show that as opposed to naive average pooling, the use of transformer-based attention improves performance significantly, and is well suited for processing feature crops. Combining both of our discoveries into a new method, Space-time Crop & Attend (STiCA) we achieve state-of-the-art performance across multiple video-representation learning benchmarks. In particular, we achieve new state-of-the-art accuracies of 67.0% on HMDB-51 and 93.1% on UCF-101 when pre-training on Kinetics-400.