 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Deep Learning Framework for Global High-Resolution Land Use Reconstruction
Jun 11, 2026Uncertainty in the terrestrial carbon cycle remains a major constraint in climate projections, partly driven by the uncertainties affecting the land surface representation and variability in Earth system models. To address this limitation, we present a data-driven framework AI4Land, for generating high-resolution historical reconstructions and future projections of key land surface variables. The framework follows a two-phase approach using a U-Net architecture. In the first phase, which is the focus of this work, it reconstructs annual land use and land cover by integrating coarse-resolution scenario data with static geophysical features. In a planned second phase, the resulting high-resolution maps will be used to predict dynamic biophysical variables, particularly leaf area index, at finer temporal scales. Trained on Earth observation data, the models learn to reproduce spatially explicit and physically consistent land surface patterns, extending temporal coverage to periods lacking direct observations. AI4Land was developed and trained on MareNostrum5, demonstrating how GPU-accelerated HPC infrastructure enables global-scale climate AI pipelines. The final product is a suite of open-source emulators designed for real-time coupling with digital twin platforms, such as those developed under the Destination Earth initiative. By delivering realistic and evolving land surface conditions on demand, this work aims to reduce critical uncertainties and improve the predictive power of next-generation climate simulations.
Data-driven Seasonal Climate Predictions via Variational Inference and Transformers
Mar 26, 2025Most operational climate services providers base their seasonal predictions on initialised general circulation models (GCMs) or statistical techniques that fit past observations. GCMs require substantial computational resources, which limits their capacity. In contrast, statistical methods often lack robustness due to short historical records. Recent works propose machine learning methods trained on climate model output, leveraging larger sample sizes and simulated scenarios. Yet, many of these studies focus on prediction tasks that might be restricted in spatial extent or temporal coverage, opening a gap with existing operational predictions. Thus, the present study evaluates the effectiveness of a methodology that combines variational inference with transformer models to predict fields of seasonal anomalies. The predictions cover all four seasons and are initialised one month before the start of each season. The model was trained on climate model output from CMIP6 and tested using ERA5 reanalysis data. We analyse the method's performance in predicting interannual anomalies beyond the climate change-induced trend. We also test the proposed methodology in a regional context with a use case focused on Europe. While climate change trends dominate the skill of temperature predictions, the method presents additional skill over the climatological forecast in regions influenced by known teleconnections. We reach similar conclusions based on the validation of precipitation predictions. Despite underperforming SEAS5 in most tropics, our model offers added value in numerous extratropical inland regions. This work demonstrates the effectiveness of training generative models on climate model output for seasonal predictions, providing skilful predictions beyond the induced climate change trend at time scales and lead times relevant for user applications.
Sign Language Translation from Instructional Videos
Apr 14, 2023



The advances in automatic sign language translation (SLT) to spoken languages have been mostly benchmarked with datasets of limited size and restricted domains. Our work advances the state of the art by providing the first baseline results on How2Sign, a large and broad dataset. We train a Transformer over I3D video features, using the reduced BLEU as a reference metric for validation, instead of the widely used BLEU score. We report a result of 8.03 on the BLEU score, and publish the first open-source implementation of its kind to promote further advances.
Sign Language Video Retrieval with Free-Form Textual Queries
Jan 07, 2022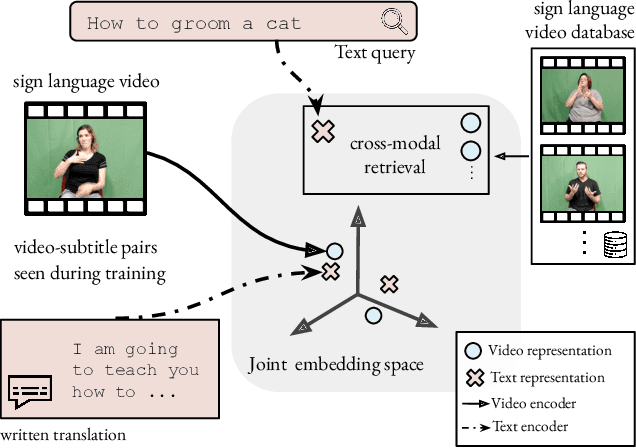
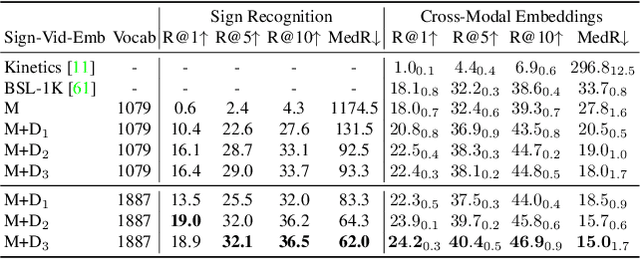
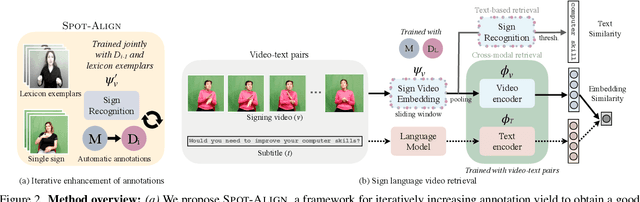

Systems that can efficiently search collections of sign language videos have been highlighted as a useful application of sign language technology. However, the problem of searching videos beyond individual keywords has received limited attention in the literature. To address this gap, in this work we introduce the task of sign language retrieval with free-form textual queries: given a written query (e.g., a sentence) and a large collection of sign language videos, the objective is to find the signing video in the collection that best matches the written query. We propose to tackle this task by learning cross-modal embeddings on the recently introduced large-scale How2Sign dataset of American Sign Language (ASL). We identify that a key bottleneck in the performance of the system is the quality of the sign video embedding which suffers from a scarcity of labeled training data. We, therefore, propose SPOT-ALIGN, a framework for interleaving iterative rounds of sign spotting and feature alignment to expand the scope and scale of available training data. We validate the effectiveness of SPOT-ALIGN for learning a robust sign video embedding through improvements in both sign recognition and the proposed video retrieval task.
Can Everybody Sign Now? Exploring Sign Language Video Generation from 2D Poses
Jan 04, 2021



Recent work have addressed the generation of human poses represented by 2D/3D coordinates of human joints for sign language. We use the state of the art in Deep Learning for motion transfer and evaluate them on How2Sign, an American Sign Language dataset, to generate videos of signers performing sign language given a 2D pose skeleton. We evaluate the generated videos quantitatively and qualitatively showing that the current models are not enough to generated adequate videos for Sign Language due to lack of detail in hands.
How2Sign: A Large-scale Multimodal Dataset for Continuous American Sign Language
Aug 18, 2020
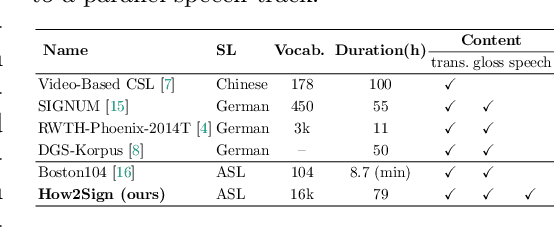
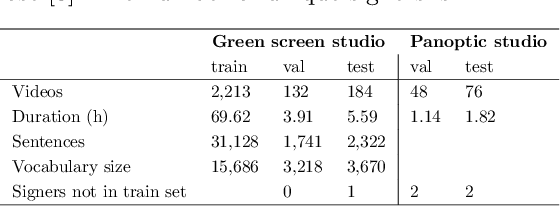
Sign Language is the primary means of communication for the majority of the Deaf community. One of the factors that has hindered the progress in the areas of automatic sign language recognition, generation, and translation is the absence of large annotated datasets, especially continuous sign language datasets, i.e. datasets that are annotated and segmented at the sentence or utterance level. Towards this end, in this work we introduce How2Sign, a work-in-progress dataset collection. How2Sign consists of a parallel corpus of 80 hours of sign language videos (collected with multi-view RGB and depth sensor data) with corresponding speech transcriptions and gloss annotations. In addition, a three-hour subset was further recorded in a geodesic dome setup using hundreds of cameras and sensors, which enables detailed 3D reconstruction and pose estimation and paves the way for vision systems to understand the 3D geometry of sign language.
Wav2Pix: Speech-conditioned Face Generation using Generative Adversarial Networks
Mar 25, 2019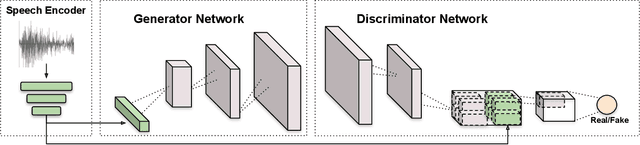
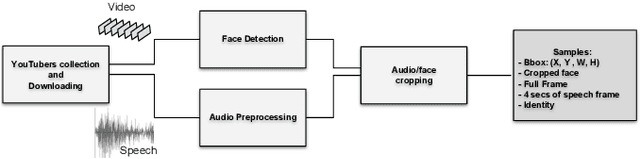


Speech is a rich biometric signal that contains information about the identity, gender and emotional state of the speaker. In this work, we explore its potential to generate face images of a speaker by conditioning a Generative Adversarial Network (GAN) with raw speech input. We propose a deep neural network that is trained from scratch in an end-to-end fashion, generating a face directly from the raw speech waveform without any additional identity information (e.g reference image or one-hot encoding). Our model is trained in a self-supervised approach by exploiting the audio and visual signals naturally aligned in videos. With the purpose of training from video data, we present a novel dataset collected for this work, with high-quality videos of youtubers with notable expressiveness in both the speech and visual signals.
Cross-modal Embeddings for Video and Audio Retrieval
Jan 07, 2018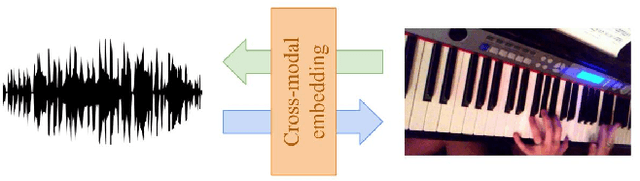
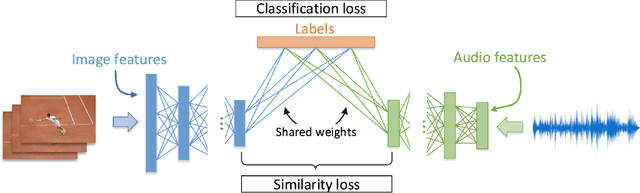
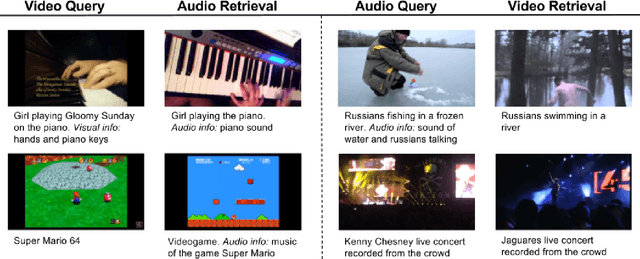
The increasing amount of online videos brings several opportunities for training self-supervised neural networks. The creation of large scale datasets of videos such as the YouTube-8M allows us to deal with this large amount of data in manageable way. In this work, we find new ways of exploiting this dataset by taking advantage of the multi-modal information it provides. By means of a neural network, we are able to create links between audio and visual documents, by projecting them into a common region of the feature space, obtaining joint audio-visual embeddings. These links are used to retrieve audio samples that fit well to a given silent video, and also to retrieve images that match a given a query audio. The results in terms of Recall@K obtained over a subset of YouTube-8M videos show the potential of this unsupervised approach for cross-modal feature learning. We train embeddings for both scales and assess their quality in a retrieval problem, formulated as using the feature extracted from one modality to retrieve the most similar videos based on the features computed in the other modality.