 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness for Unsupervised Domain Adaptation
Sep 02, 2021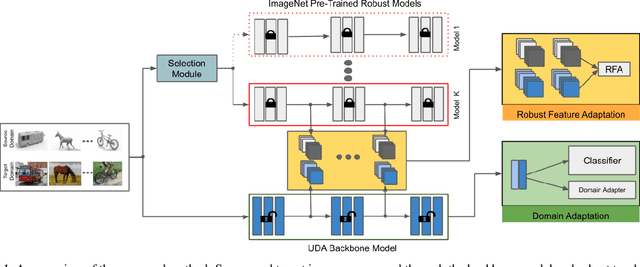
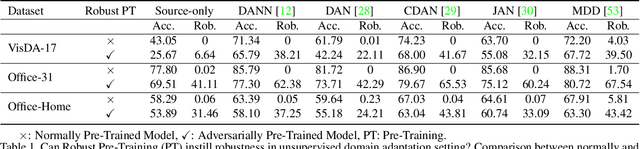
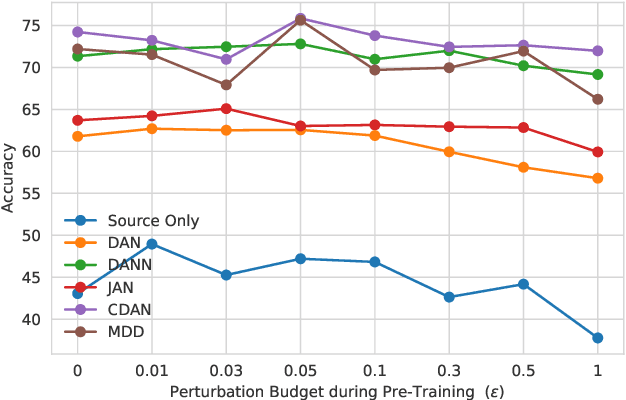
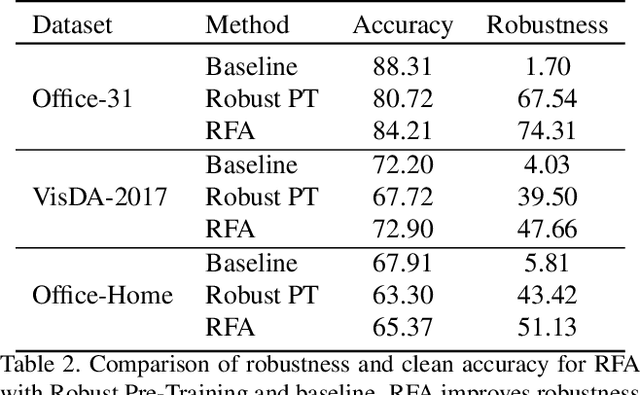
Extensive Unsupervised Domain Adaptation (UDA) studies have shown great success in practice by learning transferable representations across a labeled source domain and an unlabeled target domain with deep models. However, previous works focus on improving the generalization ability of UDA models on clean examples without considering the adversarial robustness, which is crucial in real-world applications. Conventional adversarial training methods are not suitable for the adversarial robustness on the unlabeled target domain of UDA since they train models with adversarial examples generated by the supervised loss function. In this work, we leverage intermediate representations learned by multiple robust ImageNet models to improve the robustness of UDA models. Our method works by aligning the features of the UDA model with the robust features learned by ImageNet pre-trained models along with domain adaptation training. It utilizes both labeled and unlabeled domains and instills robustness without any adversarial intervention or label requirement during domain adaptation training. Experimental results show that our method significantly improves adversarial robustness compared to the baseline while keeping clean accuracy on various UDA benchmarks.
OoD-Bench: Benchmarking and Understanding Out-of-Distribution Generalization Datasets and Algorithms
Jun 07, 2021
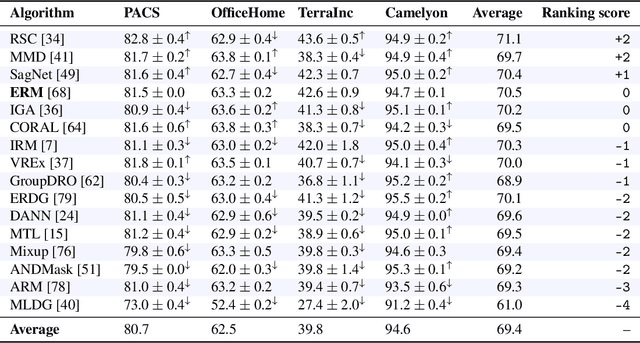
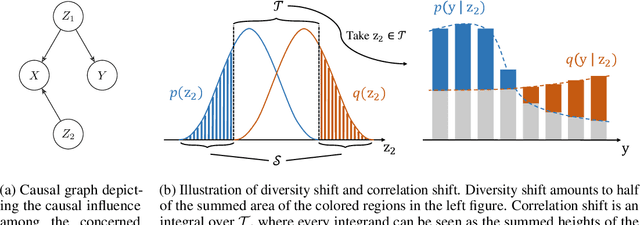
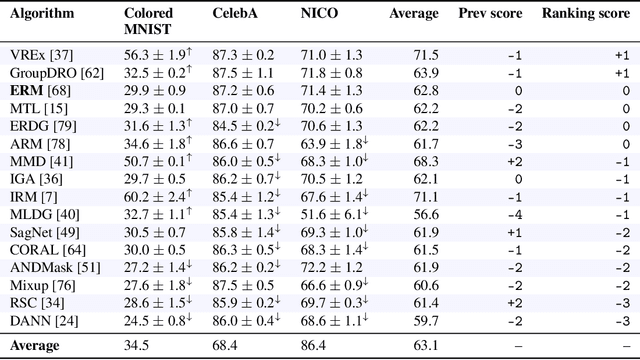
Deep learning has achieved tremendous success with independent and identically distributed (i.i.d.) data. However, the performance of neural networks often degenerates drastically when encountering out-of-distribution (OoD) data, i.e., training and test data are sampled from different distributions. While a plethora of algorithms has been proposed to deal with OoD generalization, our understanding of the data used to train and evaluate these algorithms remains stagnant. In this work, we position existing datasets and algorithms from various research areas (e.g., domain generalization, stable learning, invariant risk minimization) seemingly unconnected into the same coherent picture. First, we identify and measure two distinct kinds of distribution shifts that are ubiquitous in various datasets. Next, we compare various OoD generalization algorithms with a new benchmark dominated by the two distribution shifts. Through extensive experiments, we show that existing OoD algorithms that outperform empirical risk minimization on one distribution shift usually have limitations on the other distribution shift. The new benchmark may serve as a strong foothold that can be resorted to by future OoD generalization research.
Relaxed Conditional Image Transfer for Semi-supervised Domain Adaptation
Jan 05, 2021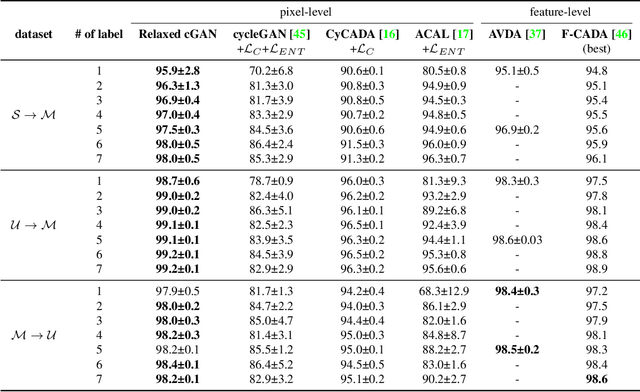
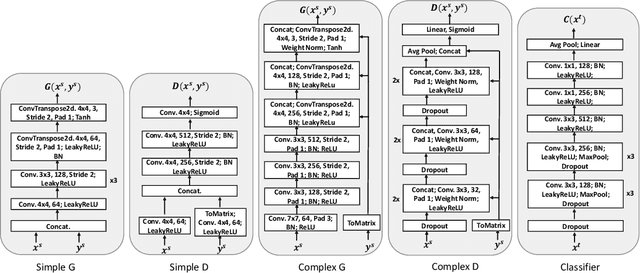
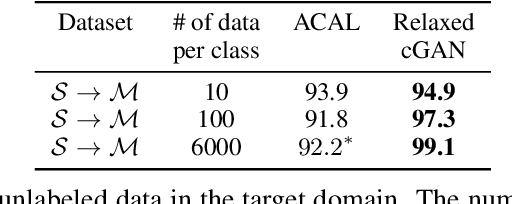
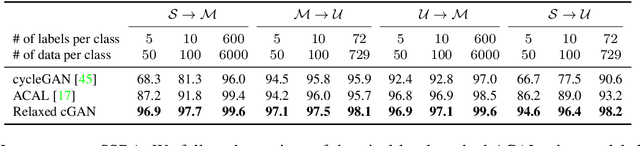
Semi-supervised domain adaptation (SSDA), which aims to learn models in a partially labeled target domain with the assistance of the fully labeled source domain, attracts increasing attention in recent years. To explicitly leverage the labeled data in both domains, we naturally introduce a conditional GAN framework to transfer images without changing the semantics in SSDA. However, we identify a label-domination problem in such an approach. In fact, the generator tends to overlook the input source image and only memorizes prototypes of each class, which results in unsatisfactory adaptation performance. To this end, we propose a simple yet effective Relaxed conditional GAN (Relaxed cGAN) framework. Specifically, we feed the image without its label to our generator. In this way, the generator has to infer the semantic information of input data. We formally prove that its equilibrium is desirable and empirically validate its practical convergence and effectiveness in image transfer. Additionally, we propose several techniques to make use of unlabeled data in the target domain, enhancing the model in SSDA settings. We validate our method on the well-adopted datasets: Digits, DomainNet, and Office-Home. We achieve state-of-the-art performance on DomainNet, Office-Home and most digit benchmarks in low-resource and high-resource settings.
MetaAugment: Sample-Aware Data Augmentation Policy Learning
Dec 22, 2020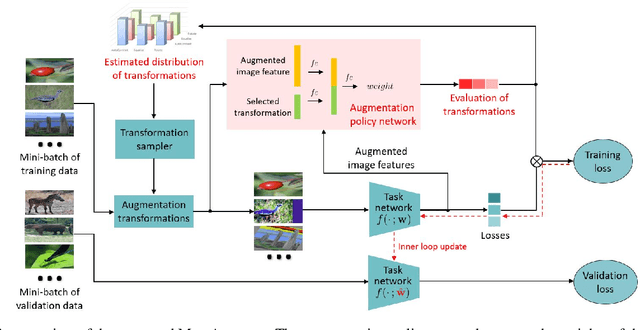
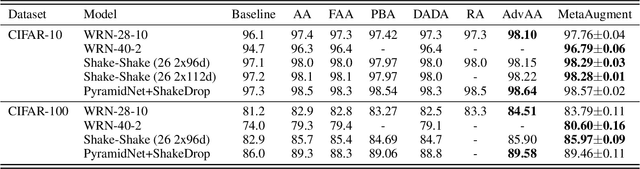
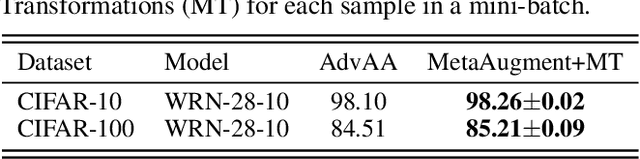
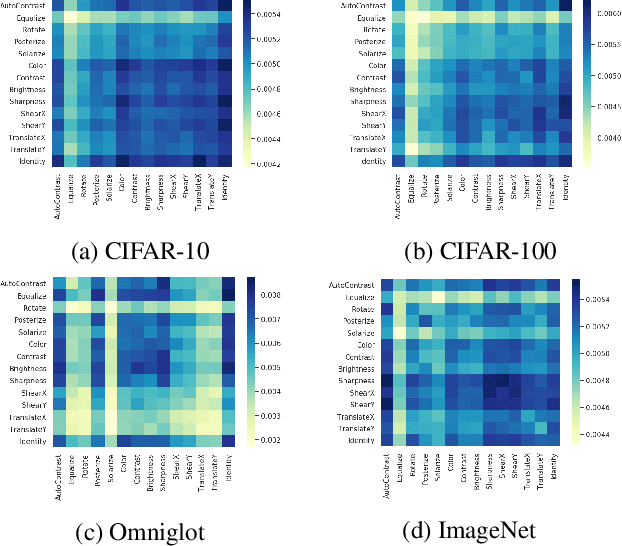
Automated data augmentation has shown superior performance in image recognition. Existing works search for dataset-level augmentation policies without considering individual sample variations, which are likely to be sub-optimal. On the other hand, learning different policies for different samples naively could greatly increase the computing cost. In this paper, we learn a sample-aware data augmentation policy efficiently by formulating it as a sample reweighting problem. Specifically, an augmentation policy network takes a transformation and the corresponding augmented image as inputs, and outputs a weight to adjust the augmented image loss computed by a task network. At training stage, the task network minimizes the weighted losses of augmented training images, while the policy network minimizes the loss of the task network on a validation set via meta-learning. We theoretically prove the convergence of the training procedure and further derive the exact convergence rate. Superior performance is achieved on widely-used benchmarks including CIFAR-10/100, Omniglot, and ImageNet.
DecAug: Out-of-Distribution Generalization via Decomposed Feature Representation and Semantic Augmentation
Dec 17, 2020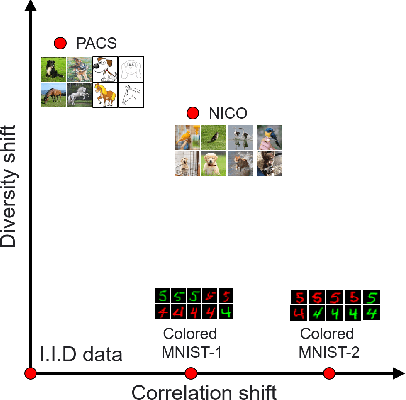
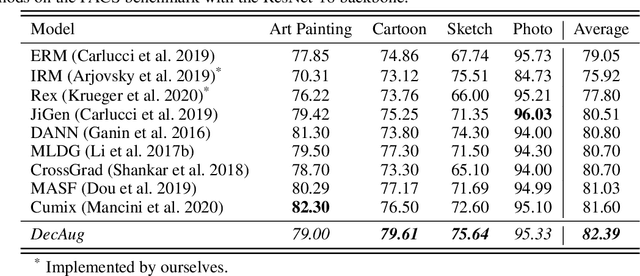

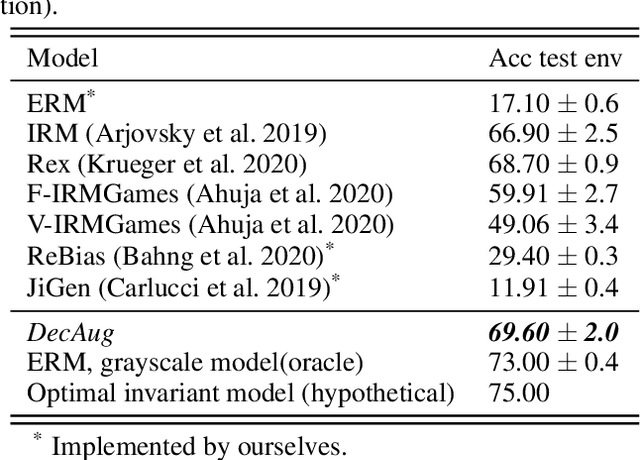
While deep learning demonstrates its strong ability to handle independent and identically distributed (IID) data, it often suffers from out-of-distribution (OoD) generalization, where the test data come from another distribution (w.r.t. the training one). Designing a general OoD generalization framework to a wide range of applications is challenging, mainly due to possible correlation shift and diversity shift in the real world. Most of the previous approaches can only solve one specific distribution shift, such as shift across domains or the extrapolation of correlation. To address that, we propose DecAug, a novel decomposed feature representation and semantic augmentation approach for OoD generalization. DecAug disentangles the category-related and context-related features. Category-related features contain causal information of the target object, while context-related features describe the attributes, styles, backgrounds, or scenes, causing distribution shifts between training and test data. The decomposition is achieved by orthogonalizing the two gradients (w.r.t. intermediate features) of losses for predicting category and context labels. Furthermore, we perform gradient-based augmentation on context-related features to improve the robustness of the learned representations. Experimental results show that DecAug outperforms other state-of-the-art methods on various OoD datasets, which is among the very few methods that can deal with different types of OoD generalization challenges.
Multi-objective Neural Architecture Search via Non-stationary Policy Gradient
Jan 31, 2020
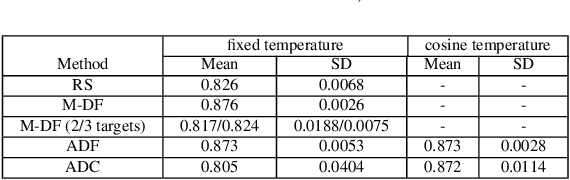
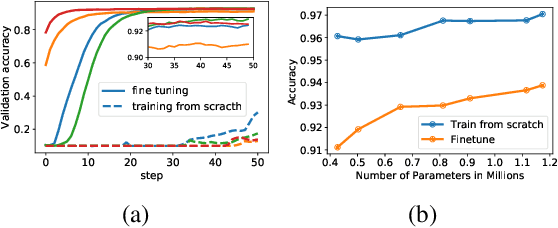
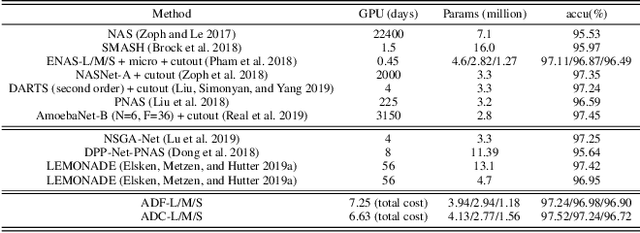
Multi-objective Neural Architecture Search (NAS) aims to discover novel architectures in the presence of multiple conflicting objectives. Despite recent progress, the problem of approximating the full Pareto front accurately and efficiently remains challenging. In this work, we explore the novel reinforcement learning (RL) based paradigm of non-stationary policy gradient (NPG). NPG utilizes a non-stationary reward function, and encourages a continuous adaptation of the policy to capture the entire Pareto front efficiently. We introduce two novel reward functions with elements from the dominant paradigms of scalarization and evolution. To handle non-stationarity, we propose a new exploration scheme using cosine temperature decay with warm restarts. For fast and accurate architecture evaluation, we introduce a novel pre-trained shared model that we continuously fine-tune throughout training. Our extensive experimental study with various datasets shows that our framework can approximate the full Pareto front well at fast speeds. Moreover, our discovered cells can achieve supreme predictive performance compared to other multi-objective NAS methods, and other single-objective NAS methods at similar network sizes. Our work demonstrates the potential of NPG as a simple, efficient, and effective paradigm for multi-objective NAS.
Deep Meta-Learning: Learning to Learn in the Concept Space
Feb 10, 2018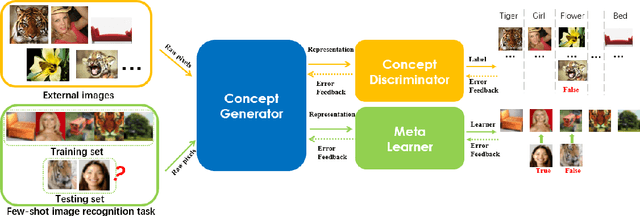
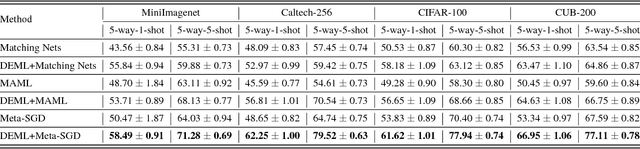
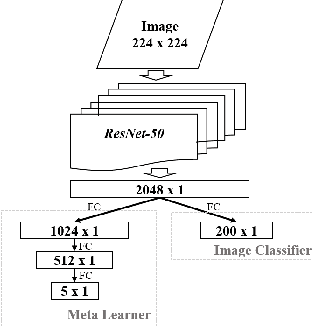
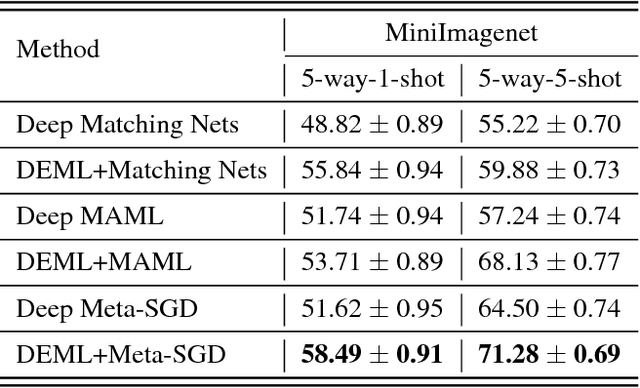
Few-shot learning remains challenging for meta-learning that learns a learning algorithm (meta-learner) from many related tasks. In this work, we argue that this is due to the lack of a good representation for meta-learning, and propose deep meta-learning to integrate the representation power of deep learning into meta-learning. The framework is composed of three modules, a concept generator, a meta-learner, and a concept discriminator, which are learned jointly. The concept generator, e.g. a deep residual net, extracts a representation for each instance that captures its high-level concept, on which the meta-learner performs few-shot learning, and the concept discriminator recognizes the concepts. By learning to learn in the concept space rather than in the complicated instance space, deep meta-learning can substantially improve vanilla meta-learning, which is demonstrated on various few-shot image recognition problems. For example, on 5-way-1-shot image recognition on CIFAR-100 and CUB-200, it improves Matching Nets from 50.53% and 56.53% to 58.18% and 63.47%, improves MAML from 49.28% and 50.45% to 56.65% and 64.63%, and improves Meta-SGD from 53.83% and 53.34% to 61.62% and 66.95%, respectively.
Meta-SGD: Learning to Learn Quickly for Few-Shot Learning
Sep 28, 2017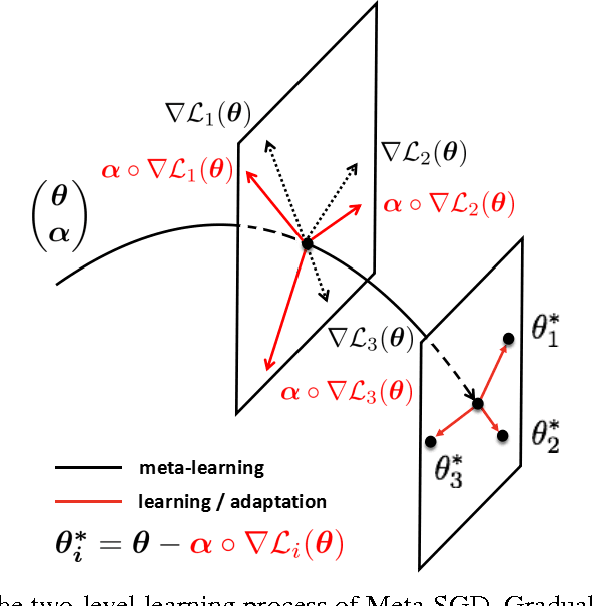
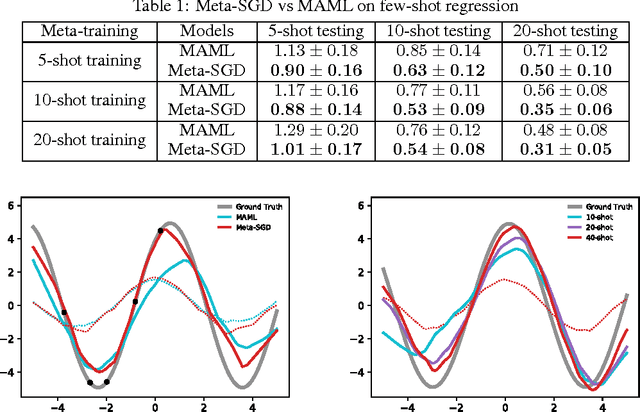
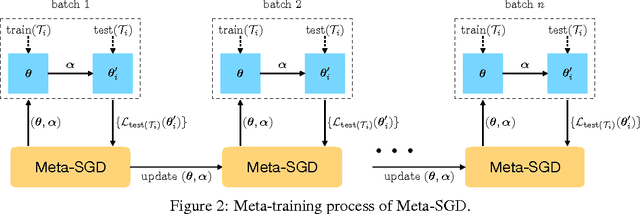
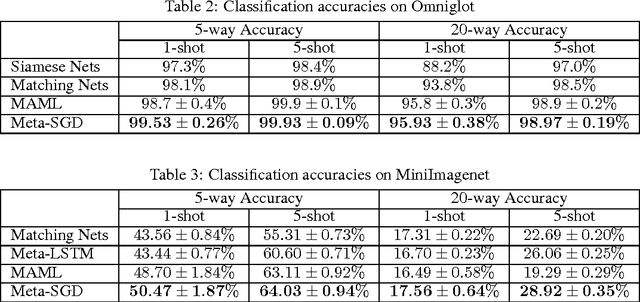
Few-shot learning is challenging for learning algorithms that learn each task in isolation and from scratch. In contrast, meta-learning learns from many related tasks a meta-learner that can learn a new task more accurately and faster with fewer examples, where the choice of meta-learners is crucial. In this paper, we develop Meta-SGD, an SGD-like, easily trainable meta-learner that can initialize and adapt any differentiable learner in just one step, on both supervised learning and reinforcement learning. Compared to the popular meta-learner LSTM, Meta-SGD is conceptually simpler, easier to implement, and can be learned more efficiently. Compared to the latest meta-learner MAML, Meta-SGD has a much higher capacity by learning to learn not just the learner initialization, but also the learner update direction and learning rate, all in a single meta-learning process. Meta-SGD shows highly competitive performance for few-shot learning on regression, classification, and reinforcement learning.